

All successful companies do it: constantly collect data. They track people’s behavior on the Internet, initiate surveys, monitor feedback, listen to signals from smart devices, derive meaningful words from emails, and take other steps to amass facts and figures that will help them make business decisions. While today’s world abounds with data, gathering valuable information presents a lot of organizational and technical challenges, which we are going to address in this article. We’ll pay particular attention to data collection approaches and tools for analytics and machine learning projects.
What is data collection?
Data collection is a methodical practice aimed at acquiring meaningful information to build a consistent and complete dataset for a specific business purpose — such as decision-making, answering research questions, or strategic planning. It’s the first and essential stage of data-related activities and projects, including business intelligence, machine learning, and big data analytics.
Data gathering also plays a key role in different steps of product management, from product discovery to product marketing. Yet it employs techniques and procedures different from those in machine learning and, thus, lies beyond the scope of this post.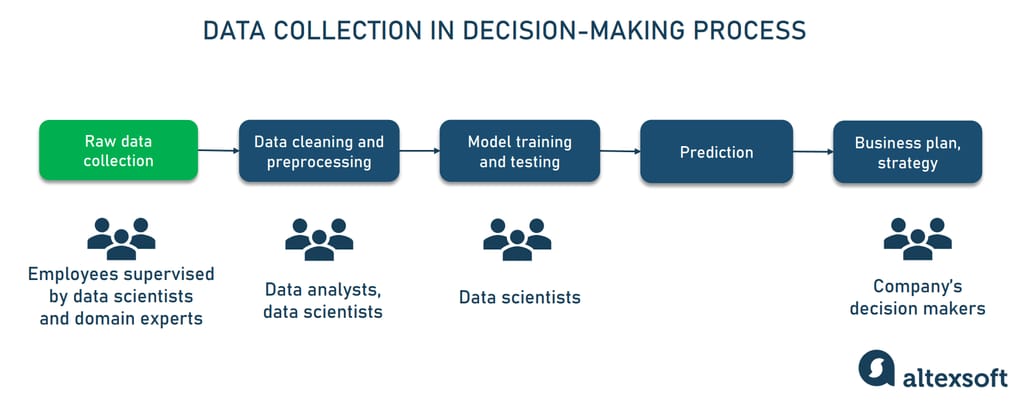
Data collection as the first step in the decision-making process, driven by machine learning
In machine learning projects, data collection precedes such stages as data cleaning and preprocessing, model training and testing, and making decisions based on a model’s output. Note that in many cases, the process of gathering information never ends since you always need fresh data to re-train and improve existing ML models, gain consumer insights, analyze current market trends, and so on.
Read our article on Hotel Data Management to have a full picture of what information can be collected to boost revenue and customer satisfaction in hospitality.
Data collection vs data integration vs data ingestion
Data collection is often confused with data ingestion and data integration — other important processes within the data management strategy. While all three are about data acquisition, they have distinct differences.
Data collection revolves around gathering raw data from various sources, with the objective of using it for analysis and decision-making. It includes manual data entries, online surveys, extracting information from documents and databases, capturing signals from sensors, and more.
Data integration, on the other hand, happens later in the data management flow. It converts raw data collections scattered across the systems into a single schema and consolidates them in a unified repository. Commonly, the entire flow is fully automated and consists of three main steps — data extraction, transformation, and loading (ETL or ELT, for short, depending on the order of the operations.)
The ultimate goal of data integration is to gather all valuable information in one place, ensuring its integrity, quality, accessibility throughout the company, and readiness for BI, statistical data analysis, or machine learning.
Dive deeper into the subject by reading our article Data Integration: Approaches, Techniques, Tools, and Best Practices for Implementation.
Data ingestion means taking data from several sources and moving it to a target system without any transformation. So it can be a part of data integration or a separate process aiming at transporting information in its initial form.
Data can be ingested in batches — meaning, it’s collected in large chunks and transferred at regular intervals or under certain conditions. Another approach is streaming ingestion, when data is acquired continuously as it’s generated. It enables real-time analytics used for fraud detection, health conditions monitoring, stock market analysis, and other time-sensitive tasks.
Both data integration and ingestion require building data pipelines — series of automated operations to move data from one system to another. For this task, you need a dedicated specialist — a data engineer or ETL developer.
Read our article Data Engineering Concepts, Processes, and Tools, or watch a dedicated video to learn more.


Data engineering explained in 14 minutes
At the same time, data collection can be conducted by a wide range of specialists as a part of their daily operations, under the supervision of domain experts or/and data scientists. Let’s look at the main steps it includes.
Data collection steps
The main reason for collecting data is to get answers to critical business questions. For example, you want to understand how your business performs compared to competitors, what demand for your product or service to expect in a month, or how you can improve customer satisfaction. According to PwC Customer Loyalty Survey 2022, four out of five people are willing to share some personal information — like age or birthdate — for a better experience.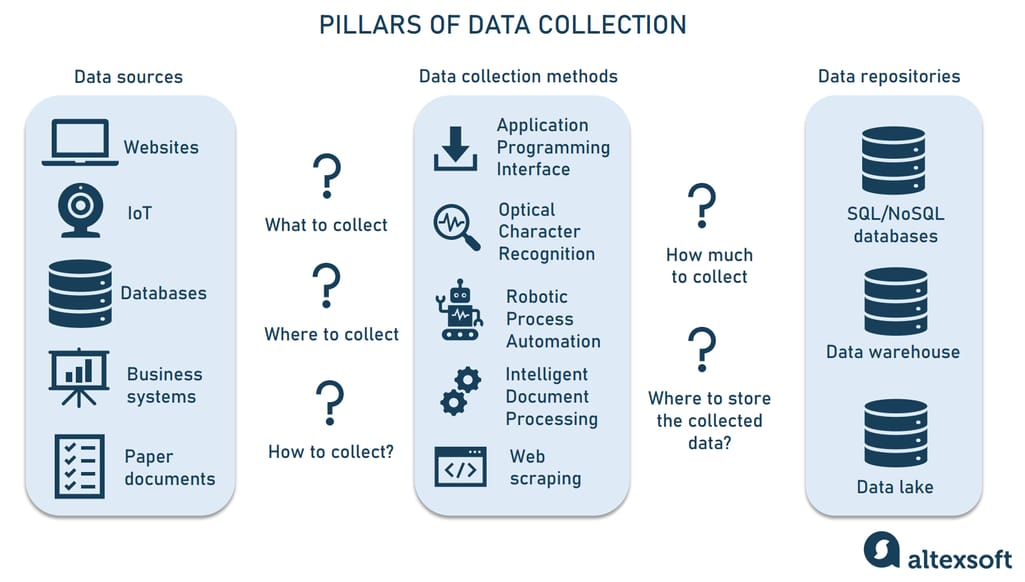
Key questions to answer for data collection
Articulating exactly what you want to know is the starting point for a data collection journey. From here, you’ll have to take the next steps.
- Define what information you need to collect.
- Find sources of relevant data.
- Choose data collection methods and tools.
- Decide on a sufficient data amount.
- Set up data storage technology.
Below, we’ll elaborate on each step one by one and share our experience of data collection.
Data types: what to collect
Data lives everywhere, taking myriad forms — texts, images, tables, videos, and printed and electronic documents, to name just a few. Not to get lost, try to identify what information is critical to answering your question as early in the project as possible.
Say, in our practice, we worked with companies focusing on gathering
- comments and opinions of customers to perform sentiment analysis and understand how people perceive certain services;
- flight details which include the airline’s name, departure and arrival time, route, date of journey, date and time of booking, price, and other vital factors to predict flight fares;
- certain booking details — such as price changes, location, and seasonality — to forecast occupancy rate; and
- recording of snoring sounds to develop an app for audio analysis of sleeping patterns.
All these examples relate to complex machine learning projects involving data scientists and industry experts. Yet, even in simpler scenarios, it makes sense to engage both data and domain professionals to elaborate on necessary data elements and rule out excessive details. This way, you won’t waste resources on gathering content irrelevant to your goal.
Another important aspect is the type of information you collect. From the perspective of data science, all miscellaneous forms of data fall into three large groups: structured, semi-structured, and unstructured.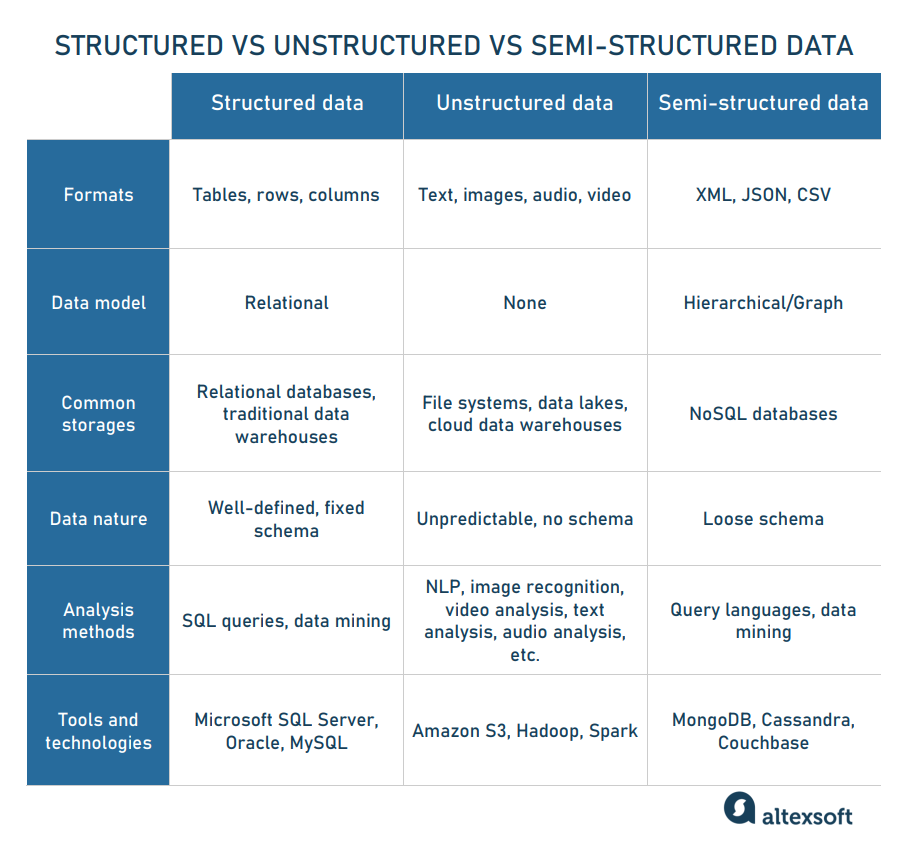
Key differences between structured, semi-structured, and unstructured data
Structured data is well-organized information deliberately placed in tables with columns and rows. Common examples are inventory lists or spreadsheets capturing transactions and their attributes — like the time of purchase, the place where it happened, the price, the payment method, the discount applied, and more. Such tables create the basis for business intelligence, traditional data analytics, and time series forecasting (if data about the same item is collected at different points of time.)
Structured data is modeled to be easily searchable and occupy minimal storage space. It dwells in special repositories known as relational or SQL databases since experts use structured query language (SQL) to manipulate tables and retrieve records.
Semi-structured data is not as strictly formatted as tabular, yet it preserves identifiable elements — like tags and other markers — that simplify the search. Formats belonging to this category include JSON, CSV, and XML files. They can be accumulated in NoSQL databases like MongoDB or Cassandra.
Unstructured data represents up to 80-90 percent of the entire datasphere. As the name suggests, it doesn’t fit into conventional schemas, covering a wide range of instances — from texts to audio records to sensor signals.
Usually, unstructured data is easy to obtain but difficult to work with. It requires a lot of storage space and advanced, compute-intensive machine learning techniques like natural language processing (NLP) or image recognition for processing. No wonder only 0.5 percent of this potentially high-valued asset is being used. Luckily, the situation has been gradually changing for the better with the evolution of big data tools and storage architectures capable of handling large datasets, no matter their type (we’ll discuss different types of data repositories later on.)
Read our articles on structured vs unstructured data and unstructured data to learn more.
Data sources: where to collect
During data collection, information is extracted from different sources that can be internal or external to the company.
Internal sources, also called primary or first-hand, capture information within the business, embracing areas like finance, operations, personnel, customer relationships, and maintenance. Examples of internal data sources are
- an enterprise resource planning (ERP) system;
- a hotel’s central reservation system and property management system;
- revenue management software;
- an airline’s passenger service system;
- customer relationship management (CRM) software;
- a company’s eCommerce website;
- call centers;
- IIoT systems, monitoring the condition of equipment, and many more.
This also includes employee and customer surveys and questionnaires that can be both electronic or paper-based and different types of hard-copy documents.
Being relevant to your company, data from internal sources help gain insights into current performance, operation efficiency, and customer preferences to find opportunities for improvement. But often, it’s not enough to scale your business or reach new audiences.
External or third-party data sources, on the other hand, deal with outside information, which comes from partners, competitors, social media, general market studies, databases with publicly available datasets, etc. Facts and figures generated by third parties are essential to understand market trends, your standing among competitors, and more.
Our experience shows that you definitely need both internal and external data to make accurate forecasts. To create a hotel price prediction algorithm for a family hotel, we combined its own booking data with information on rivals of the same size and located in the same region.
Data collection methods and tools: how to collect
For centuries, people have been collecting data manually. Even now, in the era of ChatGPT, we still fill out paper-based documents and type numbers and words into an Excel file to capture events and record observations. Yet, processes that rely on hard copies and manual data entries are time-consuming, labor-intensive, and, what's worse, prone to human error.
While manual data collection still works for small businesses, bigger companies tend to outsource these tedious and repetitive tasks or — automate them as much as possible. Here, we’ll review the most common technologies for streamlining data gathering.
Data extraction via application programming interfaces
An application programming interface, or API is a software layer enabling programs to communicate with each other. Most modern platforms expose public or private APIs as a way to access their data directly. Thanks to APIs, your system can automatically collect the content you’re interested in.
Unlike web scraping, API connections don’t pose legal problems since they can’t be established without permission from a data source, which may set restrictions on the number of requests and types of content available. It also dictates a data format, but more often than not, you’ll deal with JSON files, most common for modern REST APIs.
To learn more, read our dedicated article What is an API: Definition, Types, Specification, Documentations or watch a short video explainer.

How systems exchange data
Optical character recognition
Optical character recognition, or OCR is a technology that detects printed or written text in scanned papers, images, PDFs, and other files and converts it into machine-readable electronic form. It allows you not only to digitize hard copies quickly but also to extract valuable content from various documents and make it available for further processing.
Advanced systems like ABBYY FineReader PDF and OCR solutions from Google rely on machine learning to analyze the document layout and recognize text, no matter the language.
Robotic process automation
Robotic process automation, or RPA is a type of software designed to perform repetitive and tedious daily operations otherwise done by humans. Among other things, RPA bots can take care of some activities related to data collection — say, opening emails and attachments, collecting social media statistics, extracting data from pre-defined fields in documents, reading required data from databases and spreadsheets, etc.
Traditional RPA tools are capable of working with structured and semi-structured data only. When it comes to unstructured data — which, as you probably remember, makes up 80 or even 90 percent of potentially useful content — you need more advanced solutions powered by AI.
Learn more about RPA from our dedicated articles Robotic Process Automation: Technology Overview, Types, and Application Examplers, Implementing Traditional and Cognitive RPA Tools, and What is RPA Developer.
Intelligent document processing
Intelligent document processing, or IDP combines
- OCR to pull out text from scans,
- RPA to do routine manipulations with structured and semi-structured data, and
- machine learning techniques — particularly computer vision and NLP — to classify documents based on texts, images, or visual structure, extract meaningful information, and clean, organize, and label unstructured data to make it ready for training ML models.
IDP can be used to collect and cleanse data from insurance claims, medical forms, invoices, agreements, and other documents, minimizing human intervention.
Learn more about IDP from our dedicated article Intelligent Document Processing: Technology Overview.
Web scraping
Web scraping is an automated method to collect, filter, and structure data from websites. Typically, web scrapers or bots crawl multiple web pages gathering prices, product details, user comments, and more.
Note, though, that not any type of web scraping is legal. You can freely crawl your own website and, in most cases, gather publicly available information data across the Internet (as long as it’s not hidden behind a login).
However, some types of data are subject to regulations. It primarily refers to personal details — such as names, ID numbers, contacts, locations, shopping preferences, video recordings of people, political opinions, and more. For example, General Data Protection Regulation (GDPR) adopted in the EU apply to any information that can be used to identify a European citizen.
Also, keep in mind that many online services prohibit scraping activities. Airbnb doesn’t allow using “any robots, spider, crawler, scraper or other automated means or processes to access or collect data or other content from or otherwise interact with the Airbnb Platform for any purpose.” So, you must carefully read a website’s terms of use before launching a web bot.
You can also capture data with web forms, advanced chatbots, and other tools or automatically gather it from sensors, IoT devices, and POS systems. But in any case, data collection and its methods won’t be successful without a place to keep the data.
Data amount: how much to collect
Sometimes, the answer is quite obvious. For example, if you want to conduct a monthly or yearly performance analysis of your hospitality business, you collect important hotel KPIs — such as average daily rate, occupancy rate, and revenue per available room — during a set period of time (month, year, etc.)
But what if you not only want to see the current state of things clearly but also predict how things will develop in the future? Predictive analytics, able to foresee what will happen, requires much more data than needed for descriptive analytics, which lets us know what already happened.
The specific amount largely depends on your goals and the complexity of the algorithm employed. You may forecast demand relying on traditional statistical models. To reap accurate results, it’s advised to gather data on sales for at least two years.
When developing machine learning models, you need several years’ worth of historical data (two to three years, at the very minimum), complemented with current information. In total, datasets prepared for ML projects amount to thousands of data samples. Deep learning models consume even more — tens and hundreds of thousands of samples. They won’t make accurate predictions if trained on small datasets.
Just for reference, to predict occupancy rate with a CNN-based time series model, we trained it on historical data with 140,000 data samples. And for a sentiment analysis project, our data science team prepared a hotel review dataset containing 100,000 samples. Yet, it’s worth noting that the rule “the more data, the better” works only to a certain point.
As Alexander Konduforov, who has led data science projects at AltexSoft, once explained, “The first thousand samples will give you, for example, 70-percent accuracy. Every additional thousand will still produce accuracy growth but at a lower rate. Say, with 15,000 samples, you may achieve 90 percent, while 150,000 will result in 95 percent. Somewhere, the growth curve will flatten, and from this point, adding new samples will make no sense.”
Data repositories: where to store collected data
The types and amounts of data you collect dictate the choice of a data repository. In many cases, companies need to combine several technologies to accommodate various information. Let’s look at the main options you should know about and select from.
Relational vs non-relational databases
As we mentioned above, relational or SQL databases are designed for structured or tabular data. It’s a natural choice for collecting and storing financial transactions, inventory lists, customer preferences, employee records, and booking details, to name just a few use cases. According to the 2023 Stack Overflow survey, the most popular SQL solutions so far are PostgreSQL, MySQL, SQLite, and Microsoft SQL Server.
Non-relational databases, on the other hand, work for data forms and structures other than tables. They are more scalable than SQL ones and capable of handling larger data volumes. Depending on the data format supported, NoSQL repositories can be
- document-based for JSON-like and JSON files (MongoDB, Amazon Document DB, and Elasticsearch);
- key-value, representing each data element as a pair of an attribute name or key (gender, color, price, etc.) and its value (male, red, $100, etc.). The most popular examples of the type are Redis and Amazon DynamoDB;
- column-oriented, organizing data as a set of columns rather than storing it in rows, as with SQL databases. Apache HBase and Apache Cassandra are well-known columnar technologies belonging to the Hadoop big data ecosystem;
- graphs, intended for graph structures where data points are connected through defined relationships — like in Neo4J, Amazon Neptune, and OrientDB.
To learn more about SQL and NoSQL databases and how to select among them, read our article Comparing Database Management Systems.
Data warehouses vs data marts vs data lakes
With the growth of data amount and variety, a business faces the need for a centralized place to collect and store information from diverse systems. Such a unified repository allows companies to avoid data silos, consolidate content, and make it available for different specialists across the organization. There are two different, if not opposite, storage architectures able to hold big datasets — a data warehouse and a data lake.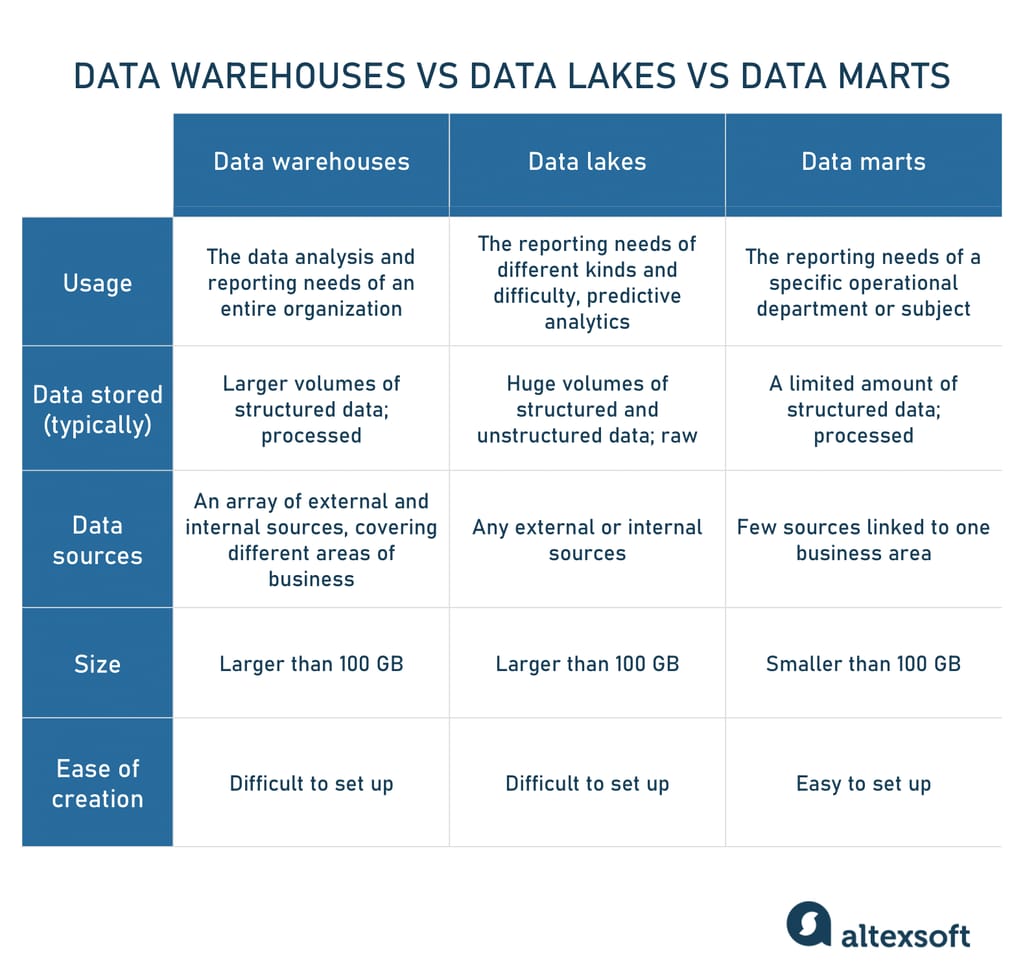
The difference between data warehouses, lakes, and marts
A data warehouse (DW) is essentially a large relational database that incorporates structured (and sometimes semi-structured) data from all departments and serves as a single source of truth for the entire company. DWs rely on an Extract, Transform, Load, or ETL process to pull information from various sources and organize it in a unified format, making it ready for data analytics and BI.
Read our article comparing cloud data warehouse platforms to learn how to choose between popular DW solutions — like Snowflake, Redshift, BigQuery, and others.
Smaller and simpler segments of DW focusing on a single business line or department are called data marts. They allow teams to access and analyze specific data faster.
A data lake, on the other hand, accommodates raw data, no matter whether it’s structured or not. This architecture fits into scenarios when you gather a lot of information but haven’t decided what to do with it right now. Unlike DWs commonly using ETL, data lakes work with an Extract, Load, Transform, or ELT process that enables quick data ingestion but does not prepare it for business use immediately.
A relatively new architecture called a data lakehouse holds the middle ground between warehouses and lakes, combining the benefits of both.
Read our separate articles on a data lakehouse and Databrick lakehouse platform to learn about their concepts, key features, and architectural layers.
Data collection tips
In this section, we collected… essential data collection tips. Some of these points were briefly mentioned above, yet you may overlook them due to information overload.
Organize a data gathering team
While data collection may engage dozens of people from different departments and even outside your company, you definitely need a team of experts to supervise data gathering flow, address problems should they occur, and engage and train new participants. It’s important to review the process from time to time and make sure that everybody is on the same page.
Create a plan and define the timeframe for data collection
All things we discussed earlier should be translated into a clear and concise data collection plan. It will contain information on team assignments (who is responsible for what), requirements for data collected, relevant data sources, tools and methods applied, and places to store information.
You may want to track some data like financial transactions or customer preference statistics— continuously. But if you run a specific campaign — for example, a survey to uncover consumer sentiments about your new product — set a time to start and stop gathering.
Ensure data integrity
Data integrity is about checking and managing data quality, completeness, and consistency at each stage of the data lifecycle. But it all starts with the collection process. Whether it’s performed manually or automatically, create clear step-by-step instructions on how to verify data inputs, remove duplicate data, and make data backups. From time to time, validate that the data collected is
- attributable — meaning you have metadata on who and when collected it;
- legible or readable;
- contemporaneous — recorded at the moment of its generation;
- original or capturing an original observation; and
- accurate or free from errors and reflecting the observations correctly.
Learn more on how to ensure data completeness and quality from our article Data Integrity: Types, Threats, and Countermeasures.
Consider data safety and privacy
As we said before, personal data is subject to GDPR and other regulations (say, the California Consumer Privacy Act or CCPA). According to GDPR principles, businesses should work with anonymous data where possible. Otherwise, you must inform people about who gathers their personal information, for what purpose it will be used, how long it will be kept, and more (see the full list here).
The general recommendation is to collect only details relevant to the declared purpose. For example, if you run a car rental service system for daily operations and analytics goals, you may need such customer details as address, phone number, locations traveled, and even information about disability (health data.) However, there is no need to ask about ethnic origin or educational level.
Develop and implement data governance policies
If data collection is not a one-time event, establish data governance policies across your company. They dictate how data is gathered, stored, and processed and who has access to what content. Among other things, the data governance standards will ensure that people involved in information gathering do it in a consistent manner and follow the same rules.
Read our article about data governance to get familiar with its concepts, tools, and implementation practices.