

Data is the lifeblood of an organization and its commercial success. You probably heard these words from a conference lecturer or saw similar headlines online. But it is what it is: You need to rely on accurate information to complete a task or deliver a service, be it planning an optimal route to deliver sushi to numerous customers or sending customized newsletters. In the first case, that’s accurate order details that you need. In the second case, you must segment customers based on their activity and interests.To do so, you need to collect and analyze appropriate data, and that would take some time and effort.
Flaws in data can lead to different outcomes. For instance, a Skyscanner customer James Lloyd was suggested to take a “long wait” layover of 413,786 hours or 47 years in Bangkok on the way from Christchurch (New Zealand) to London. The story went viral thanks to a great sense of humor the Skyscanner social media manager Jen showed when replying to James’s question about what he could do during these years:
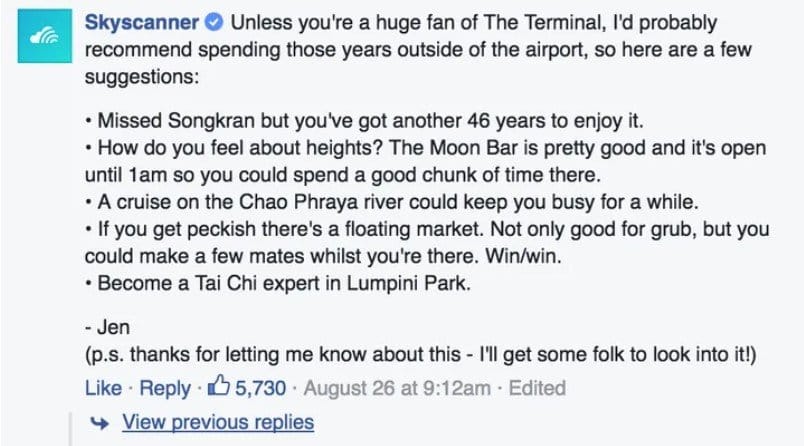
A witty reply to James Lloyd’s question on Facebook. Source: Skyscanner Facebook
Using erroneous data may lead to tragic events, especially in the medical field. David Loshin, in The Practitioner’s Guide to Data Quality Improvement, mentions the 2003 case of Jesica Santillan, who died of botched heart-lung transplant. A surgeon used organs from a donor with an incompatible blood type. Inaccurate information on blood typing caused surgery complications that resulted in death.
Low-quality data can also impede and slow down the integration of business intelligence and ML-powered predictive analytics. US company executives that participated in the Data trust pulse survey by PricewaterhouseCoopers noted that unreliable data is one of the obstacles to monetizing data. “Much of a company’s historical data, acquired haphazardly, may lack the detail and demonstrable accuracy needed for use with AI and other advanced automation,” said the survey.
Since operational efficiency and, sometimes, people's lives depend on whether the company uses reliable or unreliable information, it must consider and introduce the strategy of keeping data quality under control.
We mentioned the concept of data quality several times, so let’s explore it to the fullest. In this article, we’ll discuss what specialists take part in data quality activities and how they might contribute to the initiative. Also, we’ll explore techniques and tools for improving the health of data and maintaining it on the level that allows a company achieve its business goals.
What is data quality? Data quality dimensions
Data quality shows the extent to which data meets users’ standards of excellence or expectations. High-quality data can be easily processed and interpreted for various purposes, such as planning, reporting, decision making, or carrying out operating activities.
But what kind of data can we consider high quality? Views on what features make good quality data can differ not only across industries but also at the company level. Experts also suggest different combinations of data aspects and features to assess for quality evaluation. These measurable categories are called data quality dimensions.
In 1996, professors Richard Wang and Diane Strong described their conceptual framework for data quality in Beyond Accuracy: What Data Quality Means to Data Consumers. The research authors consider four data quality categories: intrinsic, contextual, representational, and accessibility. Each category includes several dimensions, 15 in total.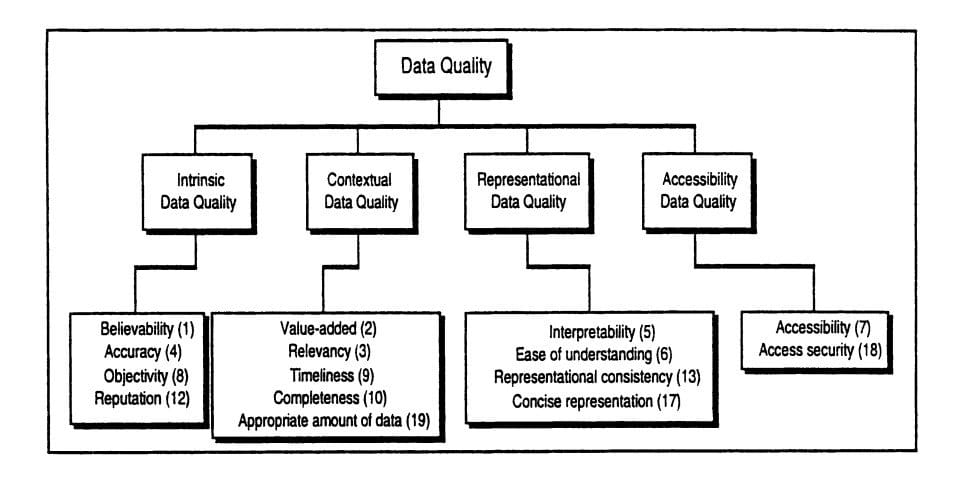
Data quality categories and their dimensions. Source: Beyond Accuracy: What Data Quality Means to Data Consumers
Data Quality Assessment Framework (DQAF) by the International Monetary Fund (IMF) considers five data quality dimensions:
- Integrity – statistics are collected, processed, and disseminated based on the principle of objectivity.
- Methodological soundness – statistics are created using internationally accepted guidelines, standards, or good practices.
- Accuracy and reliability – source data used to compile statistics are timely, obtained from comprehensive data collection programs that consider country-specific conditions.
- Serviceability – statistics are consistent within the dataset, over time, and with major datasets, as well as revisioned on a regular basis. Periodicity and timeliness of statistics follow internationally accepted dissemination standards.
- Accessibility – data and metadata are presented in an understandable way, statistics are up-to-date and easily available. Users can get a timely and knowledgeable assistance.
The DQAF includes seven dataset-specific frameworks for evaluating and maintaining unified quality standards (national accounts, price index, monetary, the government finance statistics, and other types of statistics.)
To sum up expert opinions, the most commonly mentioned quality dimensions are:

Critical data quality dimensions and features of data that meet their criteria
Data quality expert Laura Sebastian-Coleman, in Measuring Data Quality for Ongoing Improvement, notes that data quality dimensions function just like length, width, and height function to express the size of a physical object. “A set of data quality dimensions can be used to define expectations (the standards against which to measure) for the quality of the desired dataset, as well as to measure the condition of an existing dataset,” explains Sebastian-Coleman.
Data quality dimensions also allow for monitoring how the quality of data stored in various systems and/or across departments changes over time. These attributes are one of the building blocks for any data quality initiative. Once you know against what data quality dimensions you will evaluate your datasets, you can define metrics. For instance, duplicate records number or percentage will indicate the uniqueness of data.
Now let’s discuss the roadmap to implementing a data quality program in an organization.
Data quality management: how to implement and how it works
Data quality management (DQM) is a set of practices aimed at improving and maintaining the quality of data across a company’s business units. Data management specialist David Loshin underlines the continuous nature of DQM. The expert notes that the process includes a “virtuous cycle” that’s about ongoing observation, analysis, and improvement of information. The purpose of this cycle is to become proactive in controlling the health of data instead of fixing flaws once they are identified and dealing with the consequences of these flaws.
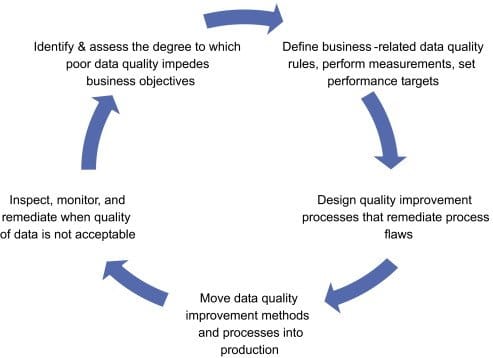
The virtuous cycle of data quality management. Source: Business Intelligence
Let’s explore each of these five stages and processes that take place during each of them.
1. Defining the impact of poor data on performance via data quality assessment
First of all, the data quality analyst reviews data to find potential issues that cause delays in specific operations and, consequently, decrease revenue and influence margins. The qualitative data review gives a basic understanding of what data flaws have the big impact on business processes. Then the specialist/s outlines data quality requirements and critical data quality dimensions that will be in a company.
Next, the team starts data quality assessment via top-down and bottom-up approaches. The top-down approach allows for learning how employees create and use data and what data-related problems they face along the way, and which of them are the most critical. Data assessment also helps defining operations that are the most affected by poor-quality data.
The data quality analyst may examine how data is organized in databases, interview users personally, or organize surveys in which users can document issues.
The bottom-up approach uses statistical and data analysis tools and techniques, for instance, data profiling. Data profiling employs various statistical and analytical algorithms and business rules to explore content of datasets and characteristics of their data elements.There are three types of data profiling:
- Structure discovery (structure analysis) is used to learn whether data consistent and formatted correctly. Pattern matching is one of the ways to explore data record structure. Analysts can also check statistics in data, such as the minimum and maximum values, medians, means, or standard deviations to learn about the validity of data.
- Content discovery entails examination of individual data records in a database to discover null or wrong values (incorrectly formatted).
- Relationship discovery is about understanding interconnections between datasets, data records, database fields, or cells. Relationship discovery starts from metadata review. This analysis allows for spotting and eliminating such issues as duplicates, which may occur in non-aligned datasets.
Analysts then may consult about found data issues with domain experts.
2. Defining data quality rules and metrics
First, data quality analysts compile data assessment results focusing on data elements that seem critical based on the specific user’s needs. “The results of the empirical analysis will provide some types of measures that can be employed to assess the level of data quality within a particular business context,” notes David Loshin in The Practitioner's Guide to Data Quality Improvement.
Then DQ analysts correlate business impacts to data flaws via defined business rules. That way, specialists define metrics they will use to ensure data is accurate enough and can be used for operational or analytical needs. They consult with data users on acceptability thresholds for metric scores. Data with metric scores that are lower than acceptability levels, doesn’t meet user expectations and must be improved to avoid negative impact on operations. Integrating acceptability thresholds with measurement methods allows for the framing of data quality metrics.
3. Defining data standards, metadata management standards, data validation rules
Once the impact of poor data is identified, data is examined, data quality rules and metrics are clear, the time comes to introduce techniques and activities on quality improvement. So, the goal of this stage is to document unified rules for data and metadata usage across the data lifecycle.
Data standards. Data quality standards are agreements on data entry, representation, formatting, and exchange used across the organization.
Metadata management standards. Policies and rules about metadata creation and maintenance are the baselines for successful data analytics initiatives and data governance. Metadata management standards can be grouped into three categories:
- Business – the use of business terms and definitions in different business contexts, the use of acronyms; data security levels and privacy level settings.
- Technical – structure, format, and rules for storing data (i.e., format and size for indexes, tables, and columns in databases, data models)
- Operational – rules for using metadata describing events and objects during the ETL process (i.e., ETL load date, update date, confidence level indicator)
Please note that some practitioners consider operational metadata as a type the technical one.
Data validity rules. Data validity rules are used to evaluate data against inconsistencies. Developers write data validity rules and integrate into applications so that tools can identify mistakes even during data entry, for instance. Data validity rules enable proactive data quality management.
It’s also crucial to decide how to track data problems. Data quality issue tracking log provides information about flaws, their status, criticality, responsible employees, and includes the report notes. George Firican, director of data governance and BI at the University of British Columbia, has written an informative yet concise post, in which he advises on attributes to include in the log.
Another aspect to consider and approve is how to improve data. We’ll talk about them in the following section.
4. Implementing data quality and data management standards
During this step, the data quality team implements data quality standards and processes it documented before to manage the solid quality of data across its lifecycle.
The team may organize meetings to explain to employees the new data management rules or/and introduce a business glossary – a document with common terminology approved by stakeholders and managers.
Also, the data quality team members can train employees on how to use a data quality tool to perform remediation, whether it’s a custom or an-of-the-shelf solution.
5. Data monitoring and remediation
Data cleaning (remediation, preparation) entails detecting erroneous or incomplete records in data, removing or modifying them. There are many ways of performing data preparation: manually, automatically with data quality tools, as batch processing through scripting, via data migration, or using some of these methods together.
Data remediation includes numerous activities, such as:
- Root cause analysis – identifying the source of erroneous data, reasons for the error to occur, isolating factors that contribute to the issue, and finding the solution.
- Parsing and standardization – reviewing records in database tables against defined patterns, grammar, and representations to identify erroneous data values or values in the wrong fields and formatting them. For example, a data quality analyst may standardize values from different metric systems (lbs and kg), geographic record abbreviations (CA and US-CA).
- Matching – identifying the same or similar entities in a dataset and merging them into one. Data matching is related to identity resolution and record linkage. The technique can be applied when joining datasets and when data from multiple sources were integrated into one destination (the ETL process). One uses identity resolution in datasets containing records about individuals to create a single view of the customer. Record linkage deals with records that may or may not refer to a common entity (i.e., database key, Social security number, URL) and which may be due to differences in record shape, storage location, or curator style or preference.
- Enhancement – adding extra data from internal and external sources.
- Monitoring – evaluating data in given intervals to ensure it can well serve its purposes.
And now, we need to find out what specialists would define metrics and standards to get data so good that it deserves a spot in perfectionist heaven, who would assess data, train other employees best practices, or who will be in charge of the strategy's technical side.
Data quality team: roles and responsibilities
Data quality is one of the aspects of data governance that aims at managing data in a way to gain the greatest value from it. A senior executive who is in charge of the data usage and governance on a company level is a chief data officer (CDO). The CDO is the one who must gather a data quality team.
The number of roles in a data quality team depends on the company size and, consequently, on the amount of data it manages. Generally, specialists with both technical and business backgrounds work together in a data quality team. Possible roles include:
Data owner – controls and manages the quality of a given dataset or several datasets, specifying data quality requirements. Data owners are generally senior executives representing the team’s business side.
Data consumer – a regular data user who defines data standards, reports on errors to the team members.
Data producer – captures data ensuring that data complies with data consumers’ quality requirements.
Data steward – usually is in charge of data content, context, and associated business rules. The specialist ensures employees follow documented standards and guidelines for data and metadata generation, access, and use. Data steward can also advise on how to improve existing data governance practices and may share responsibilities with a data custodian.
Data custodian – manages the technical environment of data maintenance and storage. The data custodian ensures the quality, integrity, and safety of data during ETL (extract, transform, and load) activities. Common job titles for data custodians are data modeler, database administrator (DBA), and an ETL developer that you can read about in our article
Data analyst – explores, assesses, summarizes data, and reports on the results to stakeholders.
Since a data analyst is one of the key roles within the data quality teams, let’s break down this person’s profile.
Data quality analyst: a multitasker
The data quality analyst's duties may vary. The specialist may perform the data consumer’s duties, such as data standard definition and documentation, maintain the quality of data before it’s loaded into a data warehouse, which is usually the data custodian’s work. According to the analysis of job postings by an associate professor at the University of Arkansas at Little Rock Elizabeth Pierce and job descriptions we found online, the data quality analyst responsibilities may include:
- Monitoring and reviewing the quality (accuracy, integrity) of data that users enter into company systems, data that are extracted, transformed and loaded into a data warehouse
- Identifying the root cause of data issues and solving them
- Measuring and reporting to management on data quality assessment results and ongoing data quality improvement
- Establishing and oversight of service level agreements, communication protocols with data suppliers, and data quality assurance policies and procedures
- Documenting the ROI of data quality activities.
Companies may require that the data quality analyst organizes and provides data quality training to employees, recommends actions for enhancing data fit for purpose. The specialist may also be in charge of ensuring compliance with the company's data privacy policy.
It's up to you how to assign duties across the data quality team. However, any team must include the person who manages the whole process, the one who does quality checks, manages data quality rules, develops data models, and a techie who maintains the flow of data and its storage across the organization.
Data quality tools
Off-the-shelf data quality tools automate remediation and quality control with features like profiling, matching, metadata management, or monitoring. Businesses have a variety of options to choose from. Gartner included 15 providers in its Magic Quadrant for Data Quality Tools, seven of which became the leaders. Let’s explore several solutions by the best-rated vendors from Gartner's point of view.
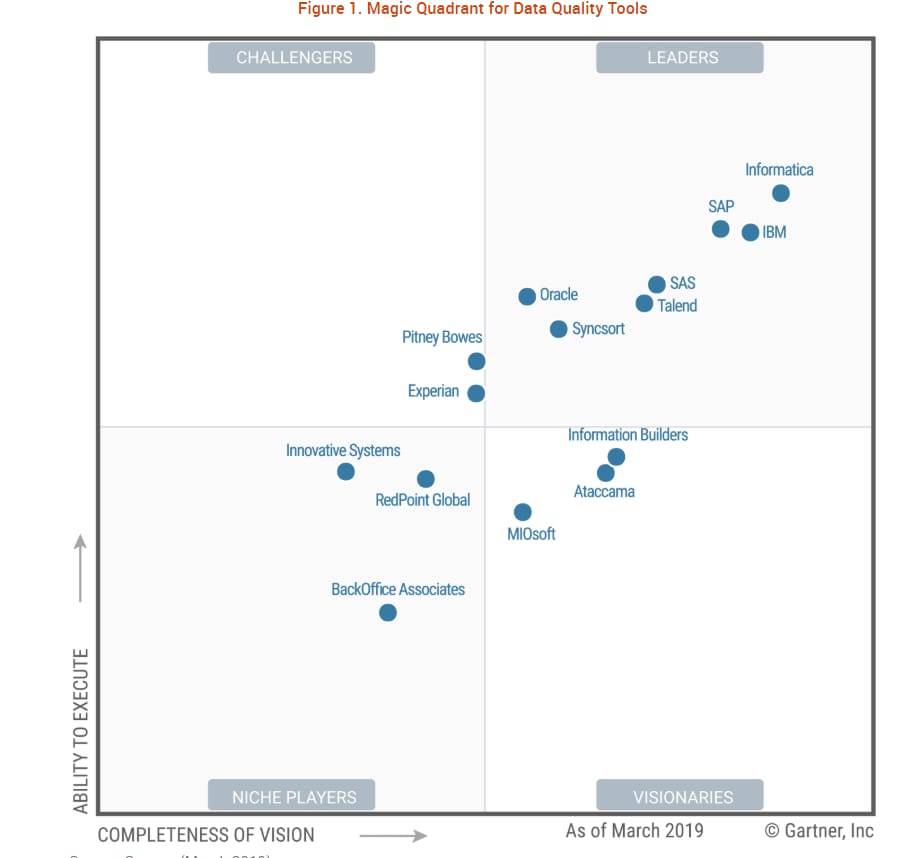
Gartner includes 15 data quality tool providers into its Magic Quadrant
IBM InfoSphere Information Server for Data Quality: end-to-end for ongoing data monitoring and cleansing
IBM InfoSphere Information Server for Data Quality is one of four DQ products the vendor offers. It provides automated data monitoring and customizable cleansing in batches or real time. The solution detects data quality flaws and establishes a remediation plan based on metrics that are aligned with the user’s business goals. So, companies can define their own data quality rules.
The tool’s core features include:
- Data profiling
- DQ transformations: cleansing, matching, validation (i.e., flexible output table configuration for data validation rules, sequencing and impact analysis)
- Customizable data standardization (i.e., data enrichment and data cleansing)
- Data lineage maintenance -- users can see what changes were made to data during its lifecycle
- Data integration
- Data classification (i.e., identifies the type of data contained in a column using three dozen predefined customized data classes)
- Data quality assessment and cleansing activities within a Hadoop cluster
Сustomers can also benefit from FlexPoint licensing -- get flexible access to IBM Unified Governance and Integration Platform.
The solution can be deployed on-premises or in the cloud. Pricing is available on demand. IBM offers information (video and interactive demos e-books) to help users learn about the solution’s capabilities.
Informatica Data Quality: automating data quality management for machine learning and AI
Informatica Data Quality uses a metadata-driven machine-learning-based approach to data quality management. One of the features the provider emphasizes is the tool’s flexibility in terms of workloads (web services, real time, batch, and big data), user roles (various business and IT), data types (transaction, IoT, third-party, product or supplier data), and use cases. Use cases include data governance, analytics, master data management, enterprise data lakes, etc.
Other key features of Informatica Data Quality are:
- Automation of DQ critical tasks (data discovery) with the CLAIRE engine that uses ML and other AI techniques
- Data profiling
- DQ transformations: standardization, matching, enrichment, validation
- Data integration
- Rule builder for business analysts (building and testing without the help of IT members)
- Pre-built, reusable common DQ business rules and accelerators (i.e., one rule can be used from tool to tool)
- Managing exceptions (records that don’t meet data quality rules conditions).
Informatica Data Quality supports public cloud (i.e., AWS and Microsoft Azure) and on-premises deployment. One needs to contact the vendor to get pricing details.
Trillium DQ: flexible and scalable data quality platform for various use cases
Trillium DQ is a suite of enterprise-grade tools for data quality monitoring and management. It’s one of the six data quality solutions by Syncsort. It provides batch data quality but can scale to real-time and big data as well. Trillium DQ is also flexible regarding user roles, providing self-service capabilities for data stewards, business analysts, and other specialists. The platform supports numerous initiatives, such as data governance, migration, master data management, single customer view, eCommerce, fraud detection, etc.
The main Trillium DQ features include:
- Data profiling
- Pre-built or custom-built DQ transformations: data parsing, standardization, validation, matching, enrichment
- Data linking
- Data discovery (for internal and external sources)
- Integration with custom and third-party applications via open-standards APIs
- Integration with distributed architectures, such as Hadoop and Spark, Microsoft Dynamics, SAP, Amazon EMR service, and any hybrid environment for distributed platforms
- Pre-built reports and scorecards
Users can choose between on-premises and cloud deployment. Pricing is available on demand.
You can always consider solutions by other leading providers like Oracle, SAS, Talend, and SAP or other vendors included in the Magic Quadrant. You can also explore listings by such peer-to-peer review sites as G2 or Capterra.
Demand for these packaged solutions is growing, especially amid a tremendous body of data generated daily and which must be harmonized. According to Gartner, the market for data quality software tools reached $1.61 billion in 2017, which is 11.6 percent more than in 2016.
Final word
There is a popular notion among experts that the data quality management strategy is the combination of people, processes, and tools. Once people can understand what makes a high-quality data in their specific industry and organization, what measures must be taken to ensure data can be monetized, and what tools can supplement and automate these measures and activities, the initiative would bring desired business outcomes.
Data quality dimensions serve the reference point for constructing data quality rules, metrics, defining data models and standards that all employees must follow from the moment they enter a record into a system or extract a dataset from third-party sources.
Ongoing monitoring, interpretation, and enhancement of data is another essential requirement that can turn reactive data quality management into a proactive one. Since everything goes in circles, let this be the circle of managing high-quality, valuable data.