

Have you ever visited a public library that doesn’t have a computerized book search? If so, you probably used an antique-style catalog that looked like a set of totally identical little drawers where thousands of paper cards were stored in strict order. Each card contained important information about one book that helped identify and locate it: name, author, date of creation or publication, subject coverage, and the Dewey Decimal Classification number.
That’s one of the ways metadata was used long before the computer era. Another example is labeling and categorizing objects in any scientific field, whether it's archeological finds, chemical samples, or living things in biology. Or think of the nutritional information on the food packaging – it also lists the predetermined characteristics of the product inside.
People agree about attributes that help them describe and categorize stuff in different areas of life. In the digital domain, it’s called metadata. And that’s what we’re going to talk about in this post. We’ll briefly recap the basics first and then discuss metadata management and tools that can come in handy.
What is metadata?
Metadata is basically information that describes other data. It helps us understand the origin, structure, nature, and context of data. As a result, we can categorize, organize, and then easily retrieve information.
Metadata examples
The most basic text document’s metadata would be
- author,
- file size,
- date created, and
- date modified.
An audio track’s metadata can indicate
- singer,
- album,
- track duration,
- bit rate, and so on.
An image’s metadata might be
- resolution,
- dimensions,
- focal length,
- color profile, etc.

Image metadata. Source: WP-Rocket
The metadata of web pages often comes in the form of meta tags (e.g., the and elements) that describe its content and linked keywords. These are important for SEO purposes because search engines use them to “understand” what the page is about and how it has to be displayed and ranked in search results. Besides, they have to attract users to visit the website, so it’s a powerful marketing tool.
In data science, metadata is one of the central aspects: It describes data (including unstructured data streams) fed into a big data analytical platform, capturing, for example, formats, file sizes, source of information, permission details, etc.
Types of metadata
There are multiple ways to categorize metadata. The National Information Standards Organization (NISO) suggested dividing metadata into three main groups.
Descriptive metadata includes the attributes that help identify and locate information, e.g., title, author, abstract, and keywords.
Structural metadata describes how compound objects are organized, for example, how pages are ordered to form chapters. It also documents the relationship between assets.
Administrative metadata helps manage digital objects and includes information about the type, format, access permissions, and when and how it was created.
There are definitely many more metadata types distinguished according to different criteria.
Now that we’ve discussed the basics, let’s talk about how metadata can be managed.
What is metadata management?
Metadata management is a set of activities, technologies, and policies that target metadata collection, storage, and organizing. Its goal is making data assets understandable and discoverable for users. In our library analogy, metadata management (in its simplest form, of course) would involve creating a book catalog and a user guide to guide library visitors around the stacks.
Metadata management is a part of the data governance process which, in turn, is an element of the overall data management strategy.
Today, such modern data management frameworks as DataOps strongly rely on effective metadata capture and management to bring order to the chaotic data flows. Plus, a data fabric architecture design approach is also based on metadata as one of the main building blocks.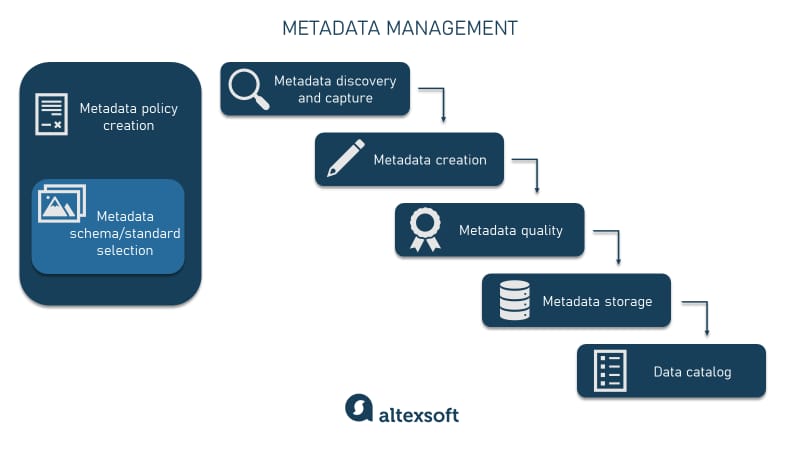
Metadata management components
Key metadata management processes include the following.
- Metadata policy creation is essential to govern the management process.
- Metadata standard/schema selection allows you to bring uniformity to your metadata.
- Metadata discovery and capture refers to extracting metadata across your data assets.
- Metadata creation, also referred to as tagging or enrichment, is adding missing metadata to digital assets.
- Metadata quality assurance is checking if metadata complies to quality requirements.
- Metadata storage usually implies developing a specialized repository.
- Metadata cataloging is organizing metadata into a searchable inventory.
Efficient metadata management ensures data integrity, consistency, trustworthiness, and compliance. More importantly, it facilitates the interaction of data consumers with information, i.e., people know which data the company has, where it is (which is especially important in today’s distributed environments), and how to find it – to derive maximum business value from digital assets.
Nowadays there’s also a concept of active metadata management that’s gaining popularity, so it’s worth touching on it too. In a nutshell, passive and active metadata can be distinguished. Passive metadata refers to basic technical characteristics and static metadata catalogs. Meanwhile, active metadata also includes behavioral, or social, attributes that reflect how it was changed over time (like who was interacting with data and how it was modified).
So, active metadata management extends beyond passive metadata and implies capturing real-time metadata, maintaining an up-to-date data catalog, and creating an accurate data lineage (we’ll talk about it further on). In many cases, it also involves applying AI and/or ML to enhance the management processes, make metadata recommendations, and flag invalid or missing data.
Now, let’s look closer at each of the metadata management activities.
Metadata policy creation
A metadata policy is a business document that has to be created to guide all metadata management activities and define the key data principles. Such policies outline
- main definitions,
- main procedures of metadata management,
- policy violation cases and consequences,
- taxonomy,
- roles and responsibilities, and
- metadata schemas and/or domain standards.
Metadata schema or standard selection is crucial for effective metadata management, so let’s explain what they are.
Metadata schema and metadata standard selection
A metadata schema is the overall structure of metadata that includes the list and syntax of attributes which reflect information about the digital asset. Some schemas were developed by national and international communities and adopted for wider usage. In this case, they become standards.
A metadata standard is a requirement that defines a common understanding of data elements which describe information and the rules for using these elements. Metadata standards imply agreeing on the language, spelling, formats, and other characteristics. Such uniform usage enables interoperability and integration between disparate systems.
There are generic or general metadata standards like Dublin Core Metadata Element Set or an XML-based Metadata Object Description Schema, which were originally developed for library catalogs. Such standards usually include essential elements which can describe almost any data. As a result, they are easy to use but lack elements specific for different disciplines.
There are also subject or domain-specific metadata standards that meet the unique requirements of certain industries, domains, and disciplines. For example, the ISO 19115 standard is designed for the geospatial community, while Darwin Core works well to describe the information on biological specimens.
To compare the two groups, the Dublin Core comprises 15 elements (such as title, language, creator, format, and so on), while Darwin Core includes 169 terms (e.g., scientific name, kingdom, locality, occurrence, etc.).
An example of Dublin Core image metadata. Source: LibGuides
When managing metadata, you can evaluate which standards would work best for your use cases and your communities.
Metadata discovery and capture
Metadata appears whenever a document, file, or other digital information asset is created, modified, or even deleted. Some metadata is generated automatically (sometimes with the help of specialized data processing tools) while other records have to be done manually.
Metadata capture or extraction is harvesting metadata across your asset landscape, including internal and external data sources like business applications, databases, data warehouses, data lakes, BI tools, webpages, etc.
An example of social media post metadata. Source: Pagefreezer
Metadata creation
Sometimes, captured metadata is not complete or has some missing or invalid attributes. You might find out that it’s not sufficient for your analytical needs. Or you might want to add certain tags or keywords to your data assets to facilitate search (especially for business users). In this case, additional metadata is created (again, either manually or automatically) and linked to digital resources.
You can get more information about data labeling in machine learning from another post (it's one of the main steps of preparing datasets for ML).
Metadata quality assurance
When dealing with metadata, we have to make sure it meets a number of requirements that characterize its quality.
- Accuracy involves checking if the recorded metadata is factual and precise.
- Completeness means that all possible metadata attributes have to be recorded.
- Interoperability is about selecting metadata standards to make your data comparable and integrable across different systems.
- Consistency relates to following the selected metadata schemes or standards throughout all datasets.
To ensure metadata quality as well as correct application of metadata policies and proper compliance with requirements and standards, audits have to be regularly conducted by data stewards.
Now that we’ve chosen the metadata scheme or standard, created or captured metadata, and ensured its quality, we have to think about where and how to store it.
Metadata storage
Metadata can be stored in two forms. The human-readable or text-based format (e.g., XML) is easy to understand for people. The binary form can’t be read by humans and requires special tools to become legible, but its advantage is that it shows greater efficiency in storage capacity and processing speed.
As for storage location, there are two options. Metadata can be stored internally which means it’s embedded in a digital object (e.g., in HTML documents or the headers of image files). In this case, metadata is changed whenever the digital object is modified and travels together with it if it’s moved.
Metadata can also be stored externally in a separate file with a link to the original asset. Usually such files are kept in a database system – a metadata repository. Having all metadata gathered in one place facilitates its management and information search. The downside of this approach is that if the reference link isn’t properly built, whenever the original data asset is moved or modified, metadata isn’t updated and therefore isn’t valid anymore.
Data cataloging
Data cataloging is creating a full, detailed, organized inventory of your digital assets by collecting and arranging metadata descriptions. Remember the library catalog from our example? That’s exactly it.
Such catalogs are essential to help data consumers search and retrieve data as they connect business context to actual data and its location.
Data cataloging is often associated with two other important data management processes: data profiling and data lineage.
Data profiling is reviewing source digital assets for content, structure, quality, and interrelationships. It involves arranging metadata in readable tables or dashboards to summarize and conveniently view all the characteristics of the dataset.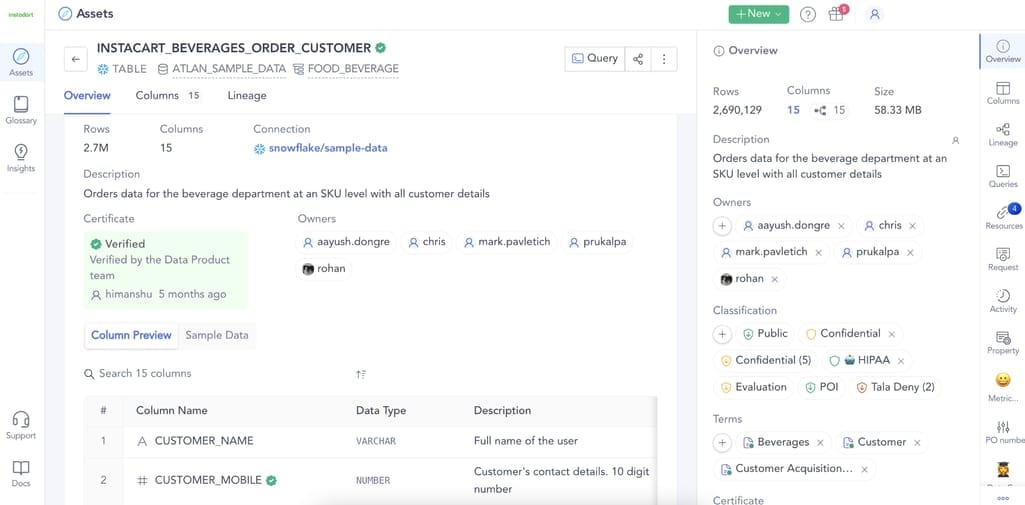
Metadata profile. Source: Atlan
Then, metadata can be analyzed to define how well data is structured, if there are any missing or invalid elements, or how it is related to other data. For example, such an analysis may discover that not all mandatory fields contain data or that certain records are of an incorrect format.
Data lineage involves using technical metadata to track the evolution and movement of data in the organization. It helps understand the data lifecycle, provides full visibility into data usage, and enables traceability (e.g., of the errors back to the root cause).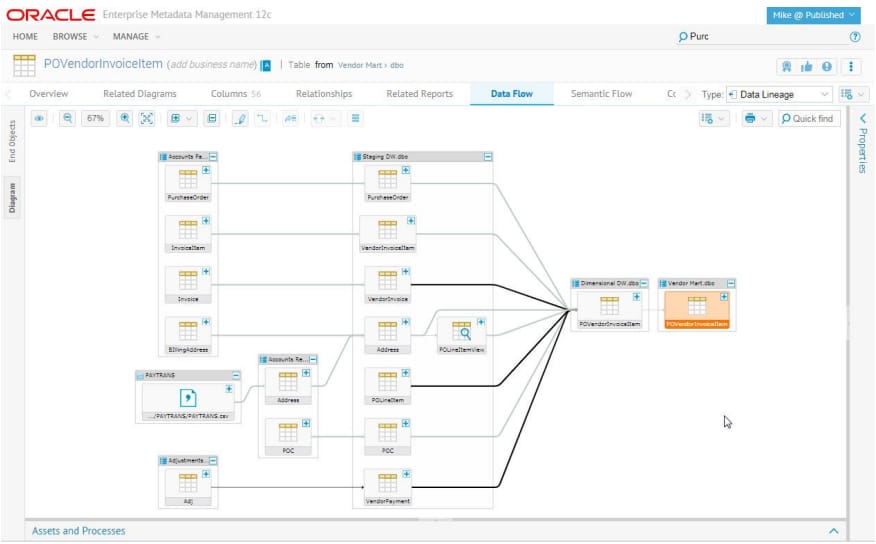
Data lineage graph. Source: Oracle
You can see there are a lot of different activities that can be done with metadata. Performing them manually is too much of a hassle. So, there are specialized tools that automate metadata management. Let’s explore what they are.
Metadata management tools and key software providers
Metadata management tools (also called enterprise metadata management or EMM systems) are software solutions that help capture and control metadata. Usually they come as modules of data governance, digital asset management, or data management platforms.
Here’s a list of common features for most metadata management solutions.
Metadata discovery and collection refers to automated metadata capturing (including technical, business, and usage metadata) across multiple sources.
Metadata tagging is the process of assigning metadata to digital assets. Software solutions automatically generate metatags and convert metadata according to the selected schema/standard. For example, modern technologies such as computer vision help analyze the imagery content and can accurately generate meta descriptions.
Data quality KPIs monitoring helps ensure data quality by tracking essential metrics.
A metadata repository is a universal storage for your aggregated metadata. It often comes in the form of metadata lake that can store all kinds of metadata and enables further discovery and management activities.
A data catalog helps data consumers retrieve data. Robust data cataloging solutions provide tools for metadata profiling and enrichment (with tags, annotations, or any other context). It’s crucial to connect your data cataloging software to all your data assets to create a full digital directory. Besides, a data catalog must have advanced search capabilities including natural language query support for non-IT data users.
Data catalogs often come as separate modules enhanced with AI capabilities so that they not only arrange information but also provide recommendations and build metadata knowledge graphs to facilitate user interaction with data.
A business glossary is a list of digital assets with related business context, definitions, and relationships between disparate datasets.
Data lineage is also often implemented as a standalone tool that records the transformation of data over time providing an end-to-end map of the data journey and any changes that happened due to user interaction with the digital asset.
Data profiling is the automatic creation of metadata profiles that aid in understanding data structure, content, and its relationship to other digital assets.
Impact analysis helps identify potential consequences of interacting with your metadata. It highlights how changing certain assets would impact other data and thus defines digital asset interdependencies.
Metadata collaboration involves having communication and sharing channels to support connectivity between different departments or teams. Collaborative processes might include workflows, stewardship, version control, and audit trails.
As we said, you can use different software tools for your metadata management. You might want to adopt a comprehensive platform to govern the entire data management process or implement a specialized module to cover one or several workflows (e.g., data cataloging). We’ll explore several popular options you can look at to get an idea of what’s on the market, compare the functionality, and maybe decide what works best for your company.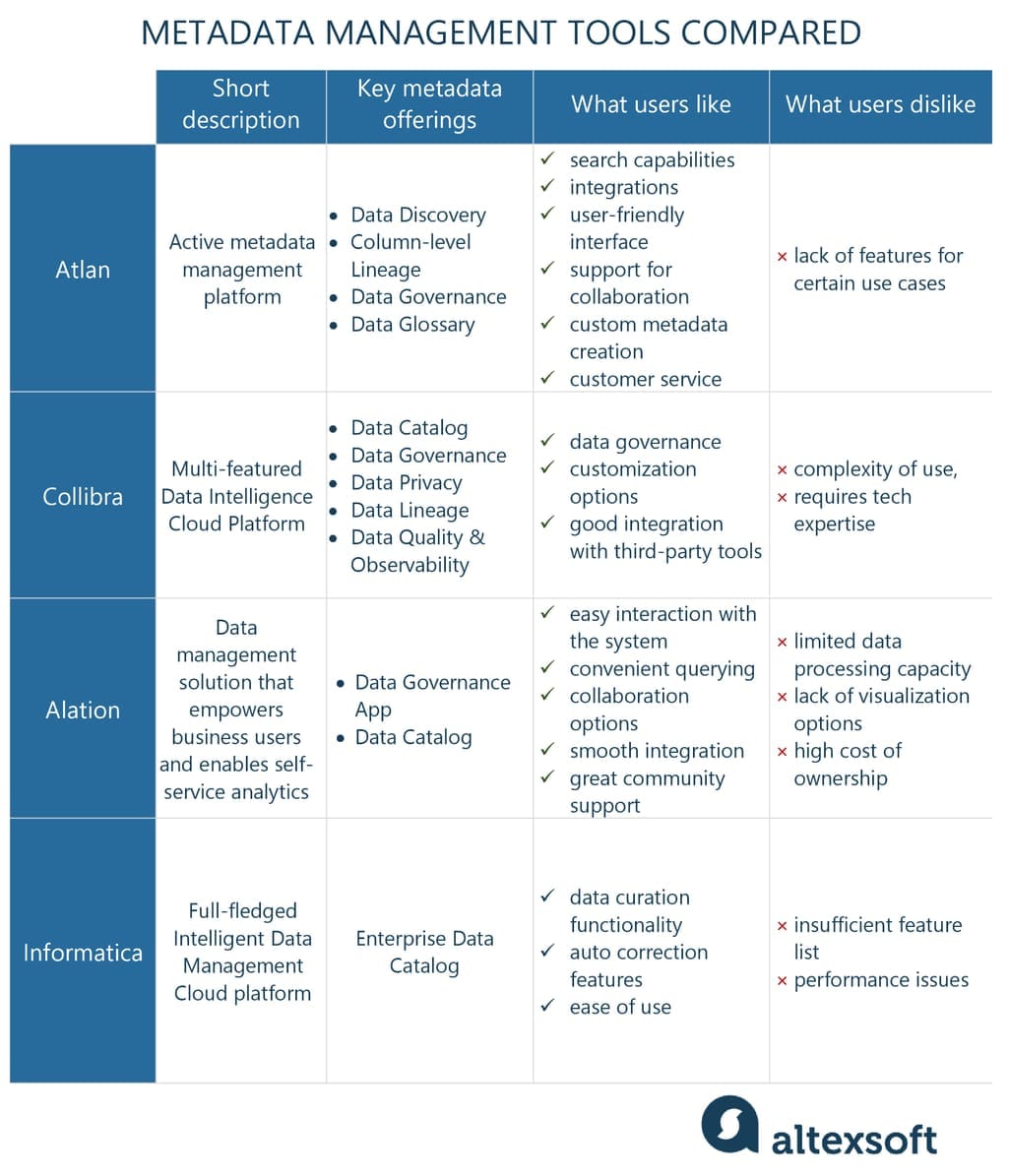
Metadata management platforms compared
Atlan: active metadata management
Atlan, "the company reinventing data management for the cloud era,” is a leading active metadata management platform. They offer a personalized metadata experience, powerful collaboration capabilities, and an open API architecture to support greater connectivity.
Among other nominations, Atlan was named a Gartner 2020 Cool Vendor in DataOps and elected a leader in the Forrester Wave Enterprise Data Catalogs for DataOps, Q2 2022.
Main Atlan active metadata management offerings are
- Data Discovery,
- Column-level Lineage,
- Data Governance,
- Data Glossary, and others.
Atlan users recognize the platform's well-built search capabilities, seamless integrations, user-friendly interface, support for collaboration, as well as the vendor’s customer service. Consumers also admire how the platform helps govern data quality and create custom metadata. Scarce complaints were related to the lacking features for individual use cases.
Collibra: complex data governance for various workflows
Collibra offers the Data Intelligence Cloud Platform that simplifies and automates key data management aspects. It was positioned as a leader in the IDC MarketScape: Worldwide Data Catalog Software 2022 Vendor Assessment. Its suite of products includes
- Data Catalog,
- Data Governance,
- Data Privacy,
- Data Lineage, and
- Data Quality & Observability.
Most users report that the Collibra platform works great for data governance, can be customized for multiple workflow management, and integrates well with third-party tools. However, reviews state that it’s not very user-friendly and requires significant technical expertise to implement.
Alation: support for self-service analytics and BI
Alation is an industry-recognized provider whose data management solutions focus primarily on fueling self-service analytics, data governance, and cloud data migration. They cater to data specialists (data engineers, data scientists, and data analysts) and business leaders alike, driving the transition “from data-rich to data-driven.”
Alation supports active metadata management with its Data Governance App and Data Catalog tools. The platform helps capture, organize, understand, retrieve, and exchange metadata. It serves as a database for all the company data, allowing users to run queries that are then used in analytics and BI tools. You can also leverage data lineage, impact analysis, and other handy functionality.
Alation users report easy interaction with the system, convenient querying, collaboration options, smooth integration, and great community support. On the other hand, some reviewers complained about limited data processing capacity, lacking visualization options, and high cost of ownership.
Informatica: data management software with ML-based data cataloging
Informatica is another provider of a full-fledged data management system – Intelligent Data Management Cloud (IDMC). It supports data integration, data quality, master data management, and other aspects including metadata management.
Its award-winning Enterprise Data Catalog tool is built on the ML-based discovery engine to scan and catalog digital assets across multiple sources. It provides data consumers with
- robust search functionality,
- automated relationship discovery,
- detailed data lineage,
- profiling statistics,
- data quality scorecards,
- data similarity recommendations,
- impact analysis feature, and
- an integrated business glossary.
Active metadata serves as the unifying foundation for IDMC, fueling further analytics and other data management processes.
Users especially highlight the data curation and autocorrection features as well as general ease of use, though some pointed out the insufficient feature list and poor platform performance.
Metadata management use cases
There are several main metadata management use cases that are common for data-centric organizations.
Risk management and compliance. Whenever companies deal with personal or sensitive data, they have to ensure data security and comply with multiple regulations (e.g., GDPR, HIPAA, and others). Metadata management is essential to identify sensitive data, regulate user access, audit compliance practices, and so on.
Data governance. Data governance is a crucial element of data management that controls the complete lifecycle of information, regulates its usage, ensures its quality, availability, security, and much more. Metadata management plays an important role in this process since only well-organized metadata gives a holistic view of the company data.
Data analytics. Besides helping to oversee digital assets, metadata enables data analytics as it ensures data quality and conformity. In addition, well-managed metadata supports self-service analytics and business intelligence by making digital assets more accessible and discoverable for business consumers.
Other use cases include data quality assessment, data mapping, dataset relationships identification, etc.
Metadata management best practices
Metadata management in today’s data-flooded world isn’t duck soup. Many companies are now realizing its importance but struggle with the starting point. We’ve outlined several steps you can consider.
Develop a metadata strategy. It’s crucial to define what your metadata management objectives are and align them with business goals. A comprehensive strategy would also determine your use cases, evaluate resources and requirements, assess the project scope and scale, and outline KPIs.
Build a metadata team. Engage skilled, experienced professionals with expertise in data management to guide and supervise your metadata activities.
Select standards. As we said, the choice of the right schemes/standards is vital for metadata uniformity and interoperability and must be based on the domain you operate in and your use cases.
Implement software. Today’s volumes of metadata can’t be managed manually so evaluate your needs and choose the tool that best covers your workflows. Ensure scalability and integrability. Consider leveraging AI/ML-based platforms that enable active metadata management and offer wider capabilities including predictive analytics.
Be consistent throughout your enterprise. When you’ve already started, add metadata consistently according to your policy and selected standards. That will allow you to have complete metadata across your assets. Communicate the importance of metadata to all data users and stakeholders and ensure their commitment.
Use specific metadata. Make your data even more usable and searchable with domain-, company-, or department-specific metadata.
Create a metadata directory. Remember about your non-tech data consumers and develop a user-friendly directory (FAQ, knowledge base, you choose the name) to help them use your data catalog.
Metadata makes information discoverable, measurable, organizable, and analyzable. The digital asset can be seen as the tip of an iceberg with the huge value of metadata hidden underneath – and often underestimated. So, this precious metadata has to be carefully nurtured to deliver maximum benefits.