

By 2028, the global volume of data is expected to reach over 394 zettabytes—the number with 21 zeros. Picture this: only one ZB is enough to hold 10 billion movies of 4k resolution that will take you 1.8 million years to watch. Those are some impressive figures, aren't they? Well, there's something even more impressive: 80—90 percent of data generated, captured, and copied is unstructured.
In this article, we'll examine structured and unstructured data. We'll learn the difference between the two, how to handle each data type, and what software tools are available for each purpose.
Structured vs unstructured data in a nutshell
Data exists in many different forms and sizes, but most can be presented as structured or unstructured. This table has collected the main differences between these two data types.
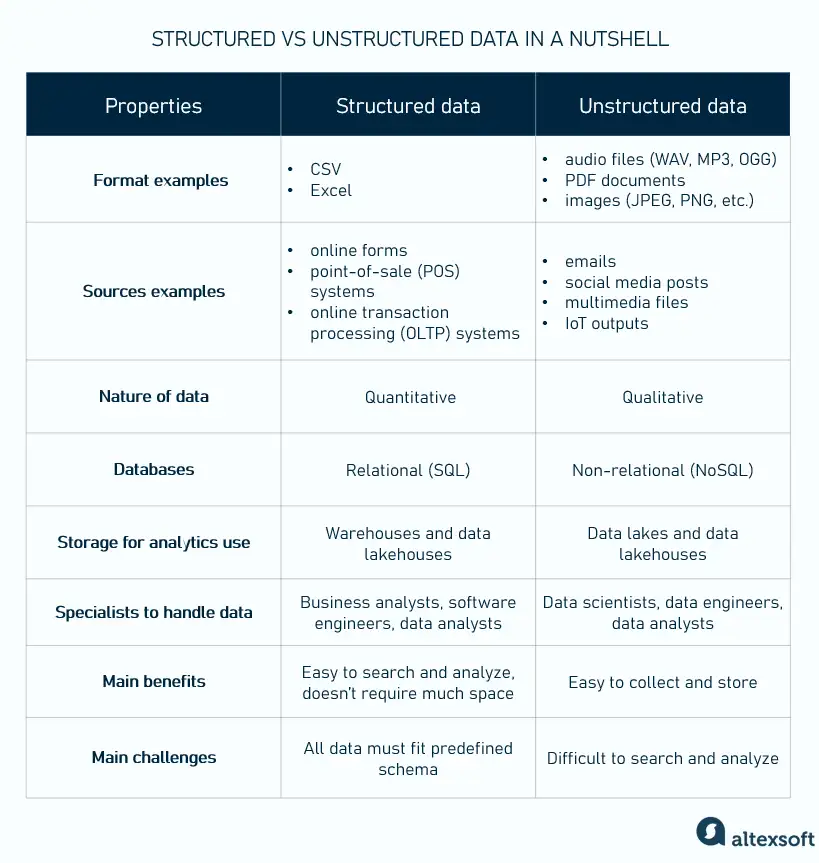
The key differences between unstructured data and structured data.
With that summary, let's move on to a more detailed description.
What is structured data?
Structured data is highly organized and exists in tabular format with interconnected rows and columns, so you can easily search for specific details and single out the relationships between its pieces. It doesn’t normally require much storage space. To manipulate it, there is a special language called SQL, which stands for Structured Query Language and was developed back in the 1970s by IBM.
Structured data examples. Most of us are familiar with structured data — Google Sheets and Microsoft Office Excel files are the first things that spring to mind. This data can comprise both textual elements and numbers, such as employee names, contacts, ZIP codes, addresses, credit card numbers, etc.

Pretty much everyone has dealt with booking a ticket via one of the airline reservation systems. They operate structured data: passenger names, location names, flight numbers, number of passengers, etc. Once you have entered information into the appropriate field, the application saves the data and allocates it to the appropriate tables in the database.
This information will be stored, read, changed, or deleted when needed. And it’s easy to analyze. For example, just retrieve specific columns and rows of the corresponding tables to compare the prices or the number of tickets purchased on different dates.
What is unstructured data?
Unstructured data is schemaless, meaning it has no pre-defined structure and is stored in its native format. This includes imagery, text documents, and video and audio files. It’s easy to capture, provides many insights, and can be used in various ways, given that you have enough storage to keep it and advanced technologies for analysis.
Unstructured data examples. Unstructured data includes a wide array of forms, such as email, text files, social media posts, video, images, audio, sensor data, and so on.

The travel agency Facebook post: an example of unstructured data.
For instance, a travel agency posts new travel tours on social media and wants to know the audience's reactions. Each post contains metadata descriptions or attributes like shares or hashtags that can be quantified and structured. However, the post itself (pictures plus text) and comments belong to the category of unstructured data. Collecting valuable insights will take advanced techniques like sentiment analysis.
The key differences between structured and unstructured data
Let’s discuss the important differences between structured and unstructured data — their formats, sources, nature, models, storage options, and analysis tools — in more detail.
Data formats: few formats vs a plethora of formats
Structured data is formatted before being placed in data storage. It’s presented in a standardized and user-readable tabular format. The most common examples are CSV, Excel, and Google Sheets.

Data formats
Unstructured data exists in various shapes and sizes. As we said earlier, it can be stored in native or original formats that include audio (WAV, MP3, OGG, etc.) or video files (MP4, WMV, etc.), PDF documents, images (JPEG, PNG, etc.), emails, social media posts, sensor data, etc.
Data sources: tabular format recordings vs web content and multimedia streams
Structured data comes from online forms, network, and web server logs, point-of-sale (POS) systems, online transaction processing (OLTP) systems, IoT sensor readings like temperature or humidity recorded in a tabular format, location coordinates from GPS devices, and more.
Unstructured data sources embrace emails, social media platforms (posts, tweets, comments, and likes); website content including articles, images, videos, and audio; multimedia files generated by people or systems; business documents; and video and audio feeds from cameras and microphones.
Data nature: quantitative vs qualitative
Structured data is often referred to as quantitative data. This means it commonly contains numbers or textual elements that can be counted. It’s easy to group, sort, and analyze based on specific attributes or characteristics. Teams can quickly query specific information using SQL. Structured data integrates seamlessly with traditional analytics platforms for faster, more efficient workflows.
Unstructured data, in turn, is often classified as qualitative data containing subjective information. Analyzing it requires additional manipulations, such as
- data stacking or investigation of large volumes of data, splitting them into smaller items and consolidating the variables with similar values into a single group; and
- data mining or the process of detecting certain patterns, oddities, and interactions in large data sets to express possible outcomes in advance.
With unstructured data, it’s often impossible to extract meaningful conclusions without advanced techniques like machine learning. While unstructured data can yield valuable insights, it is inherently harder to manage and analyze compared to structured data.
Data models: pre-defined vs flexible
Structured data is schema-dependent and relies on the strict organization of a data model that dictates the configuration of columns (also called fields), as well as the types of data meant to be held in these columns. Such dependency is both an advantage and a disadvantage. While the information here can be easily searchable and processed, all records have to follow very strict requirements.
Unstructured data, on the other hand, offers more flexibility and scalability and can be stored in various file formats. But despite the lack of a predefined schema, there are still ways to effectively organize and retrieve texts, images, audio, and video. Four common data models for this are document-oriented, key-value, graph, and wide-column. We’ll talk about SQL and NoSQL databases next.
Databases: SQL vs NoSQL
Structured data lives in relational databases or relational database management systems (DBMSs). It is set up in tables with many rows (also called records) and columns with labels denoting specific data types they are supposed to keep. The configuration of data types and columns makes up the schema of the database table.
Each row has a unique ID called a primary key and can also contain foreign keys that establish relations between the data in different tables.

A relational database is perfect for structured data. PK = primary key, FK = foreign key
Relational databasesuse use SQL to reach the stored data and manipulate it. SQL syntax is similar to that of the English language, providing the simplicity of writing, reading, and interpreting it. While the information is easily searchable and processed, the strict requirements of the schema limit the capabilities of the database.

The most common relational database management systems
The most commonly used relational databases are the following:
- PostgreSQL—a free, open-source RDBMS that supports both SQL and JSON querying, as well as the most widely used programming languages such as Java, Python, C/C+, etc;
- SQLite—a lightweight transactional system that doesn’t require a separate server; it operates as an embedded database in a web or desktop application or a device (e.g., a phone or IoT device);
- MySQL—one of the most popular open-source RDBMSs that is fast and reliable and allows for the creation of both small and large apps;
- Oracle Database—an advanced database that can be used for data warehousing, online transaction processing, and mixed database workloads. Besides structured data, it supports various data models —including JSON and XML documents, key-value pairs, graphs, and more ;
- Microsoft SQL Server—a reliable and functional DBMS that offers a seamless connection with Microsoft tools (e.g., Azure, Power BI, and Excel) and provides a complete suite for data integration through an ETL (extract, transform loading) process.
When it comes to unstructured data, the most suitable option for it is non-relational or NoSQL databases, where NoSQL stands for "not only SQL." They store data in a non-tabular, schemaless way.

NoSQL database types
The most common types of NoSQL databases are
- key-value, organizing data as pairs of unique keys and associated information or value;
- document-oriented, keeping information in the form of JSON, XML, and other document formats;
- graph, designed to store, manage, and query data in the form of graphs that consist of nodes and edges; and
- column-oriented, arranging data by column rather than rows.
Such databases can handle large volumes of data and deal with high user loads, prioritizing scalability and performance over strict structure and immediate consistency.

Unstructured data management tools.
Below, you will find a few examples of DBMSs to manage unstructured data effectively:
- MongoDB—one of the most popular NoSQL databases that stores data in BinaryJSON or BSON format;
- Amazon DynamoDB—an advanced database service for complete data management, offered by Amazon as a part of their AWS package. It handles document and key-value data structures and is a good fit for working with unstructured data;
- ArangoDB—a multi-model database supporting key-value, document, and graph models. This makes it versatile for applications requiring diverse data structures, such as recommender systems or social networks.
- Apache Cassandra—a free Java-based DBMS designed for scalability and high availability. It combines features of traditional relational databases with the flexibility of NoSQL systems. Its query language, Cassandra Query Language (CQL), closely resembles SQL, making it easier for developers familiar with relational databases to work with.
Read our article on NoSQL databases to learn more about their types and use cases as well as about the most popular DBMSs to handle non-tabular data.
Storage for analytical use: data warehouses vs data lakes
If we apply data for analytical processing and use so-called data pipelines, the final destination of the structured data's journey will be data warehouses. These are space-saving repositories with a defined structure that is difficult to change. Even minor changes to the schema may require reconstructing huge volumes of data, which might entail spending time and resources.
The bigger the data volume is, the more space it requires for storage. A picture with high resolution weighs a lot more than a textual file. Therefore, unstructured data requires more storage space and is usually kept in data lakes, which allows for storing almost limitless amounts of data in its raw formats. At the same time, unstructured data can’t be used for analytics right away — it must be integrated, cleaned, and prepared to become understandable for computers.
A new, hybrid architecture combining features of a data lake and data warehouse—a data lakehouse—can handle both structured and unstructured data.
Any system dealing with data processing requires moving information from storage and transforming it into something that people or machines can utilize. This process is known as Extract, Transform, Load, or ETL. You can learn more about ETL and an ETL developer role, if you read our dedicated article. Also, explore our piece on data lake vs data warehouse.
Ease of use and tools for analysis: mature vs advanced
One of the main differences between structured and unstructured data is how easily it can be subjected to analysis. Structured data is overall easy to search and process whether it is a human who processes data or program algorithms. Unstructured data, by contrast, is a lot more difficult to search and analyze. Once found, such data has to be processed attentively to understand its worth and applicability. The process is challenging as unstructured data can't fit within the fixed fields of relational databases until it is stacked and handled.
From a historical point of view, since structured data has been dealt with longer, it’s logical that there is a great choice of mature analytics tools for it. At the same time, those who work with unstructured data may face a poorer choice of analytics tools as most of them are still being developed.
Let’s see what tools and technologies are used to work with structured data.
Business intelligence tools (e.g., Tableau, Power BI) enable users to manipulate, visualize, and report data stored in relational databases or spreadsheets. These platforms provide user-friendly interfaces for building dashboards, identifying trends, and creating actionable insights.
Online analytical processing (OLAP) tools allow users to query data from different perspectives, combining data mining and reporting features. Oracle Essbase, SAP BW (SAP Business Warehouse), and Apache Kylin are some of the most popular open-source OLAP systems.
Unstructured data requires more sophisticated technologies. Preprocessing is often necessary to organize raw data into an analyzable format.
Machine learning libraries (like TensorFlow, PyTorch), and a suite of libraries (like Hugging Face), are essential for deriving insights from unstructured data.
Natural language processing (NLP) tools allow users to handle text-based unstructured data: extract meaning, identify sentiments, and perform named entity recognition. For instance, a cloud-based suite of AI tools Azure Cognitive Services provides Text Analytics and Translator APIs to integrate with your apps, and an open-source Python library spaCy helps you build apps for NLP.
Data search and indexing tools like Elasticsearch enable powerful indexing, full-text search, and pattern recognition in logs, text, or multimedia.
Big data processing tools like Apache Spark and Apache Hadoop are open-source frameworks for scalable preparation, management, and analysis of vast volumes of information. While Hadoop is cost-effective and good for batch processing, Spark excels in real-time analytics for immediate insights and in-memory computing for fast data processing.
Visual data analysis tools offer image recognition tools for object and face detection, image search, and object captioning/description. For example, the Google Cloud Vision AI platform provides image recognition APIs for integrating such features within applications.
Data teams: different levels of skills vs deep expertise
Because relational databases have been here longer, they are more familiar to a user. Specialists with different levels of skills, from business analysts to software engineers, can work with any RDBMS quite easily and quickly as a data model is pre-defined.
Unlike structured data tools, those designed for unstructured data are more complex to work with. Therefore, they require a certain level of expertise in data science and machine learning to conduct deep data analysis. To handle unstructured data, a company will need qualified help from data scientists and data engineers.
To know more about the data engineering processes, concepts, and tools, read our article.


Structured and unstructured data examples and use cases
As we've touched on structured and unstructured data examples above, it would be useful to point out particular use cases.

How structured and unstructured data is used in different industries.
Industries often need to leverage both data types to make their applications work and improve the efficiency of their services.
Structured data use cases
Structured data primarily facilitates basic CRUD operations (create, read, update, delete). These operations support transactional workflows and enable applications to manage and track user interactions.
Online booking. Different hotel booking engines and ticket reservation services leverage the advantages of the pre-defined data model as all booking details, such as dates, prices, destinations, etc., fit into a standard data structure with rows and columns.
ATMs. Any ATM is a great example of how relational databases and structured data work. All the actions a user can do follow a pre-defined model.
Inventory management systems. Companies use many variants of inventory management systems, but they all rely on a highly organized environment of relational databases.
Banking and accounting. Various companies and banks must process and record huge amounts of financial transactions. They use relational database management systems to maintain structured data.
Unstructured data use cases.
The most crucial use of unstructured data is analysis. It powers applications requiring insights from complex, non-tabular information.
Speech recognition. Call centers use speech recognition to identify customers and collect information about their queries and emotions.
Image recognition. Online retailers employ image recognition to allow customers to shop from their phones by posting a photo of the desired item.
Text analytics. Manufacturers utilize advanced text analytics to examine warranty claims from customers and dealers and elicit specific pieces of important information for further clustering and processing.
Chatbots. Using natural language processing (NLP) for text analysis, advanced chatbots help different companies boost customer satisfaction with their services. Depending on the question input, customers are routed to the corresponding representatives who would provide comprehensive answers.
What is semi-structured data?
As the name suggests, semi-structured data is partially structured. It incorporates certain markers that can split semantic elements and implement data hierarchies but differs from the tabular data models in relational databases. Such a structure is called self-describing.
Markup languages such as XML are the forms of semi-structured data. JSON is also a semi-structured data format used by new-generation databases such as MongoDB and Couchbase. It is significantly easier to process than unstructured data.

How data is organized in JSON. Source: techEplanet
While semi-structured data may seem like a happy medium, it is not like that. In today's highly competitive environment, the best-case scenario for corporations is to adopt all data types and sources, improving the effectiveness of business intelligence.
The blurred line between structured and unstructured data
To wrap things up, it is worth saying that there is no real struggle between unstructured data and structured data. Both types of data carry great value for businesses in diverse fields and scales. Picking a data source may depend on the structure of the data. But more often than not, we don’t choose one type over the other and rather look for software opportunities to handle all data.
In the past, companies had no real way of analyzing unstructured data, so it was discarded while the focus was put on the data that could be easily counted. Nowadays, companies can use artificial intelligence, machine learning opportunities, and advanced analytics to do the tricky unstructured data analysis for them. For example, corporations like Google have made huge advances in image recognition technology by creating AI algorithms that can automatically detect what or who is in a photograph.
Truth be told, those lines between structured and unstructured data are a little bit blurred because most datasets are semi-structured these days. Even if we take unstructured data like a photograph, it still has components of structured data such as image size, resolution, the date the image was taken, etc. This information can be organized in a tabular format of relational databases.
Now that you know the characteristics and differences between unstructured and structured data, you can make an informed decision about whether or not to invest in technologies to reap the benefits of unstructured data. The best-case scenario for corporations is to adopt both data types, improving the effectiveness of business intelligence.
Consider checking our overview of the main data storage types to learn how to store and manage different types of data.

Olga is a tech journalist at AltexSoft, specializing in travel technologies. With over 25 years of experience in journalism, she began her career writing travel articles for glossy magazines before advancing to editor-in-chief of a specialized media outlet focused on science and travel. Her diverse background also includes roles as a QA specialist and tech writer.
Want to write an article for our blog? Read our requirements and guidelines to become a contributor.