

Whether your goal is data analytics or machine learning, success relies on what data pipelines you build and how you do it. But even for experienced data engineers, designing a new data pipeline is a unique journey each time.


Data engineering in 14 minutes
Integrating data from numerous, disjointed sources and processing it to provide context provides both opportunities and challenges. One of the ways to overcome challenges and gain more opportunities in terms of data integration is to build an ELT (Extract, Load, Transform) pipeline.
In this article, we will explore the ELT process in detail, including how it works, its benefits, and common use cases. We will also discuss the differences between ELT and ETL (Extract, Transform, Load), and provide tips for building and optimizing an ELT pipeline.
What is ELT?
ELT is the acronym for extraction, loading, and transformation. It is a data integration process with which you first extract raw information (in its original formats) from various sources and load it straight into a central repository such as a cloud data warehouse, a data lake, or a data lakehouse where you transform it into suitable formats for further analysis and reporting.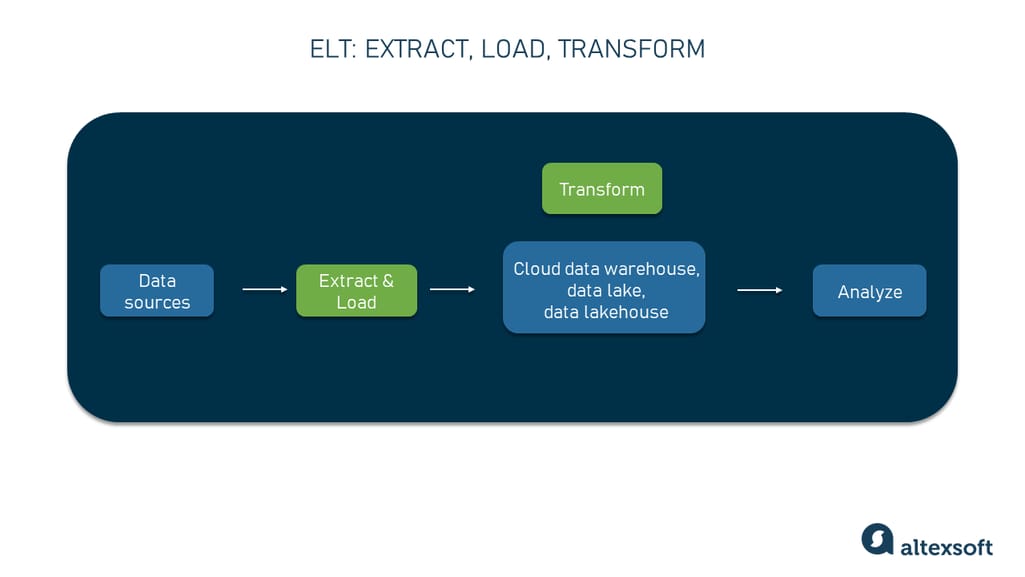
The ELT workflow
ELT is now gaining popularity as an alternative to a traditional ETL (Extract, Transform, Load) process, in which the transformation phase occurs before the data is loaded into a target system. One of the main reasons for this method is the need to timely process huge volumes of data in any format.
ELT vs ETL
ETL and ELT are two approaches to moving and manipulating data from various sources for business intelligence. Let’s take a look at a few key differences between these patterns.
Order of process phases. In ETL, all the transformations are done before the data is loaded into a destination system. For example, Online Analytical Processing (OLAP) systems only allow relational data structures so the data has to be reshaped into the SQL-readable format beforehand. In ELT, raw data is loaded into the destination, and then it's transformed as needed.
Scalability. Organizations now operate huge amounts of varied data stored in multiple systems. ELT makes it easier to manage and access all this information by allowing both raw and clean data to be loaded and stored for further analysis. If you want to use cloud-based data warehousing or powerful data processing tools like Hadoop, ELT can help you make the most of their capabilities and handle large amounts of data more efficiently.
With the ETL shift from a traditional on-premise variant to a cloud solution, you can also use it to work with different data sources and move a lot of data. However, you still need to understand how to transform information and build a corresponding schema in advance.
Flexibility. In ETL, you first decide what you’re going to do with data, set metrics, and only after that you load and use that data. In ELT, you move transformation to the end of the process instead of the beginning. It allows for more flexibility in how the data is used. Any changes to analytics requirements won't affect the whole workflow.
ELT also makes it easier to customize the pipeline for different goals. For example, if analysts want to measure something new, they don't have to change the whole pipeline, they can just change the transformation part at the end. Or when data scientists want to experiment with different ML models, they can get all data from sources and then decide which features are relevant.
Data availability. ELT is more useful than ETL in situations when data needs to be processed in real-time, e.g., streaming data from telematics IoT devices. If this is the case, ELT is a good choice because the transformation happens after the data is already in its final location, which means it can be used on the go.
Costs. ELT is generally more cost-effective than ETL, as it requires fewer specialized tools and resources to be initially implemented. Most cloud providers offer pay-as-you-go pricing plans. Besides that, there's no need to purchase expensive hardware like with traditional on-premise ETL. This doesn’t apply to cloud ETL, though.
Overall, both ETL and ELT can be used in different contexts, depending on the needs of the organization.
For more information, read our detailed, head-to-head ETL vs ELT comparison.
ELT use cases
There are different scenarios when you may need to use ELT.
- There’s the need to make real-time decisions based on data. ELT is a good option since it allows for almost real-time analytics. This is because the target system can perform data transformation and loading in parallel, which speeds up the process.
- A project requires large amounts of both structured and unstructured data, such as data generated by sensors, GPS trackers, and video recorders. In this case, ELT can help you improve performance and make data available immediately.
- If you're planning a big data analytics project, ELT is well-suited to addressing the challenges of big data, such as volume, variety, velocity, and veracity.
- There’s a data science team that needs access to raw data for machine learning projects. ELT allows them to work with the data directly.
- If your project is expected to grow and you want to take advantage of the high scalability of modern cloud warehouses and data lakes, ELT can help you do so.
These are just a few ways you can make use of ELT. The number of applications is bigger and more versatile.
ELT process steps
ELT is a process that involves three main stages: extraction, loading, and transformation. We’ll briefly describe each stage below to show how ELT works.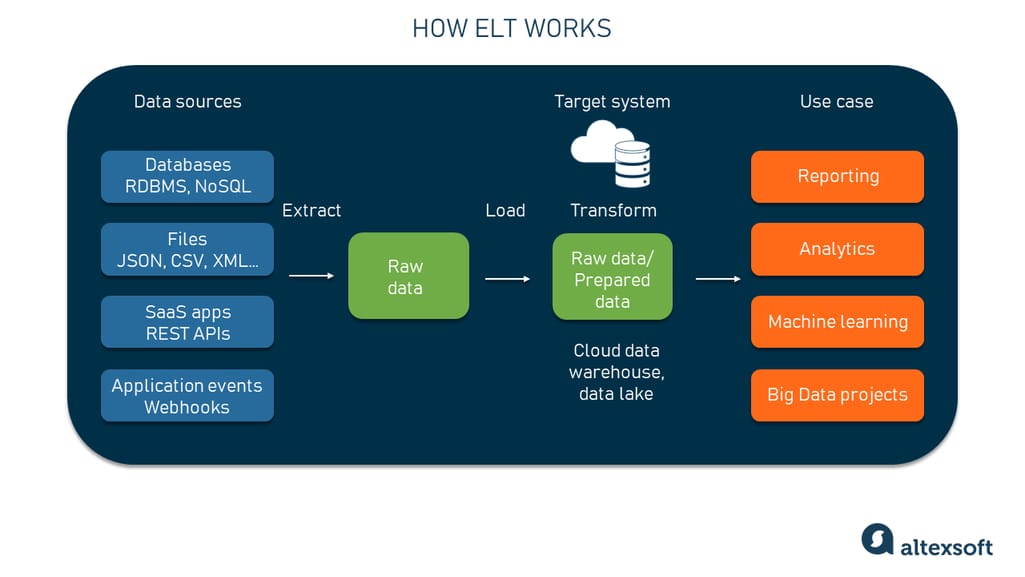
How ELT works
Extract
The “extract” phase involves getting the data from the sources such as databases, flat files, or APIs. This may involve using SQL queries, web scraping, or other methods of extracting data. There are three key types of extraction.
Full extraction. All available data is pulled from a particular data source. This process can involve extracting all rows and columns of data from a relational database, all records from a file, or all data from an API endpoint.
Partial data extraction with update notifications. This method involves data extraction from a source system that can send notifications when records are changed. You receive a notification each time data is added to the system or is changed so that you can decide whether to load it. To make this happen, a source system must be equipped with an automation mechanism or have an event-driven structure with webhooks.
Incremental extraction. Some data sources can't send notifications when updates occur, but they can identify modified records and provide an extract of those records. This can involve extracting only the rows and columns of data that have been added or changed since the last extraction, or only the records that have been added or modified in a file.
Both incremental patterns are often used when the goal is to keep a local copy of the information up to date, or when the data source is very large and extracting all of the data would be impractical.
While ELT is more commonly used with unstructured data, information can come from various structured or unstructured sources, such as SQL or NoSQL databases, CRM and ERP systems, text and document files, emails, web pages, SaaS applications, and IoT systems, name a few.
Load
The “load” phase involves loading the extracted data into a central repository, such as a data warehouse or data lake. This involves using a tool or script to load the data into the repository.
Full load. This is the process of loading all available data from a particular data source into a repository of destination.
Incremental load. Only new or modified data gets into a repository regularly with certain intervals.
Stream load. This is the process of loading data into a repository in real-time — as it becomes available. This can involve continuously loading data from a data source as it is being generated or modified.
You can check how data streaming works in our video.

Data streaming explained
Once the data reaches its destination, it is at your disposal for transformations based on your project and requirements.
Transform
The “transform” phase involves applying various transformations to the data to make it suitable for analysis and reporting.
Many different types of data transformations can be performed, and the specific changes will depend on the needs and goals of the organization. Here are a few examples of possible transformations.
Cleansing. Also known as data scrubbing or data cleaning, it is the process of identifying and correcting or removing inaccuracies and inconsistencies in data. Data cleansing is often necessary because data can become dirty or corrupted due to errors, duplications, or other issues.
Aggregation. You combine data from multiple records or sources to produce summary or aggregate data. Examples include summing up the total sales for a given period or calculating the average transaction value.
Filtering. This is a process of selecting a subset of data based on specific criteria. For example, you might filter the data to include only records for customers in a certain region or with a certain level of activity.
Joining. This is the process of combining data from multiple tables or sources based on a common key or attribute. For example, you, as a data consumer, might want to join a table of customer data with a table of order data to create a single table with information about both.
Normalization. You convert data to a consistent format or structure: You might normalize dates to a specific format or convert currencies to a common base currency.
Enrichment. This is the process of adding external data or context (metadata) to the existing data. For example, you might add demographic data to customer records or geographic data to sales data.
Of course, the three phases of ELT don’t happen all by themselves: You need effective tools to handle operations or automate them.
Tools for building an ELT pipeline
Luckily for data engineers and other specialists involved in the process, there are a variety of tools and technologies that you can use to build an ELT pipeline. The right choice will depend on your specific needs and requirements. Here are some examples of technologies that you might consider using.
Please note! We do not promote any of the providers presented on the list.
Apache Airflow
Apache Airflow is an open-source platform that allows users to build and manage data engineering pipelines or workflows including ELT processes.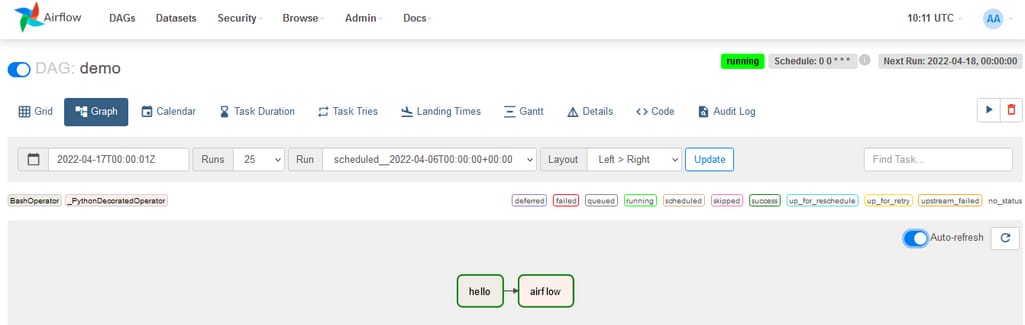
Airflow DAG dashboard. Source: Qubole
In Apache Airflow, you can use DAGs (Directed Acyclic Graphs) to automate the execution of your ELT workflows, ensuring that tasks are run in the correct order and at the right time. You can set up dependencies between tasks, schedule tasks to run at specific intervals and retry tasks if they fail. You can also use DAGs to monitor the status of your workflows and get notified if any tasks fail.
Airflow provides some other useful features, such as the ability to send email notifications when certain events occur and support for the parallel execution of tasks. All of these features make it easier to build and maintain ELT processes.
You can install the software for free or contact a vendor for a freemium version of the offerings.
Matillion
Matillion is an ELT tool designed for use with cloud data warehouses such as Amazon Redshift, Google BigQuery, Snowflake, and Azure Synapse. It is built to handle data transformation tasks and sits between raw data sources and your business intelligence and analytics tools.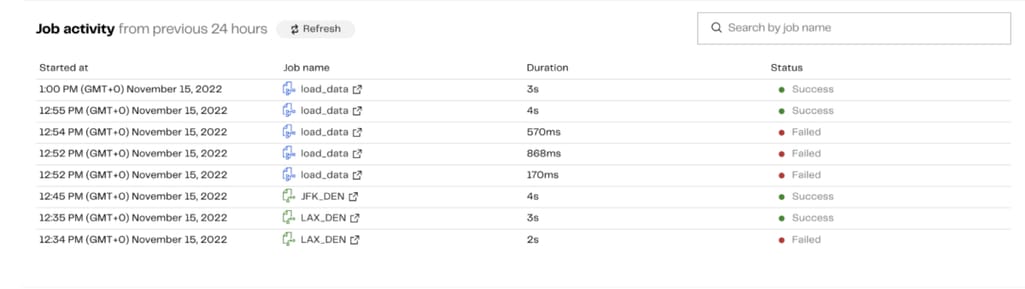
Matillion Observability Dashboard provides information on the status of your ELT jobs – whether your instance is running, stopped, or has an error. Source: Matillion
Matillion offers an easy-to-use interface for building and scheduling ELT jobs. It provides a drag-and-drop UI and automates the process of transferring and transforming data so that users do not have to write any code. It also has a pay-as-you-go pricing model with no long-term commitment. The tool is scalable, making it suitable for large amounts of data.
The vendor offers four pricing plans, including a free model. The basic plan starts at $2 per credit.
Hevo
Hevo Data is a no-code data integration tool that offers a fully managed solution for ELT tasks, meaning it handles the process of transferring and transforming data without the need to write any code. It can quickly transfer data from over 100 sources (40+ are free) to the desired data system. The data can then be cleaned and organized for analysis.
Hevo ELT pipeline dashboard. Source: Capterra
Hevo's ELT approach uses models and workflows to transform data and offers an intuitive interface for applying transformations. The tool is secure, automatically manages schemas, and is easy to use. Hevo can scale to handle millions of records per minute with minimal latency. It also supports incremental data load and real-time monitoring. Hevo provides live support through chat, email, and calls.
There are three pricing plans for users, including the one that comes for free.
How to build and optimize an ELT pipeline
If you are at a crossroads and have no idea where to start with your ELT processes, here are some general recommendations for building and optimizing a pipeline.
Define the scope and goals of the pipeline
Clearly define the purpose of the ELT pipeline and the data that needs to be extracted, loaded, and transformed. This will help you to design the pipeline and choose the appropriate tools and technologies.
Choose the right tools and technologies
Select the tools and technologies that are best suited to your needs. Consider factors such as the type and volume of data, the complexity of the transformation logic, and the performance and scalability requirements.
Extract data efficiently
Optimize the data extraction processes to minimize the time and resources required to get that data from the source systems. This may involve using specialized extractors or optimizing the SQL queries used to retrieve data.
Map out data loading strategy
Choose an appropriate data loading strategy based on the volume and velocity of the data. For example, you may want to use batch loading for large volumes of data from relational databases but choose to stream data that is generated continuously and should be available immediately.
Decide on transformations
Think of how to optimize and manage the data transformation processes to minimize the time and resources required to transform the information. This may involve configuring SQL queries, parallel processing, or distributed computing.
Monitor the pipeline
Monitor the performance of the ELT pipeline and identify bottlenecks or issues that may be impacting its efficiency. Use this information to optimize the pipeline and improve its performance.
Perform ELT testing
Last but not least, test the ELT pipeline thoroughly to ensure that it is functioning as expected and producing accurate results. ELT testing is an important step in the development and maintenance of an ELT process, as it helps ensure that the data you load and transform is of high quality and can be used for downstream analysis and decision-making.
There are several useful ELT testing tools for this purpose.
JUnit — a unit testing framework for the Java programming language. In the context of ELT testing, JUnit can be used to test individual units of code that are responsible for ELT processes.
Selenium — an open-source tool available for free under the Apache License 2.0. and it is primarily designed for testing web applications. Selenium might be used to automate the process of extracting data from web-based sources or to test the functionality of ELT processes that involve web-based data sources.
Postman — a tool that allows software engineers to develop and validate APIs. It might be used to test APIs that are part of the ELT process.
There are many different instruments for ELT testing, and choosing one depends on the specific needs and constraints of the project. They may include data quality tools, test automation tools, and even manual testing.
To sum up, ELT processes and tools are essential for any organization looking to maximize the value of its data and make informed decisions based on accurate, up-to-date information.