

Humans have been trying to make machines chat for decades. Alan Turing considered computer generation of natural speech as proof of computer generation of to thought. Today, we converse with virtual companions all the time. But despite years of research and innovation, their unnatural responses remind us that no, we’re not yet at the HAL 9000-level of speech sophistication.
But despite failing to understand us in some instances, machines are extremely good at making sense of our talking and writing in others. Internet search engines are wonderfully helpful when auto-filling our queries, language translation has never been more seamless and correct, and advanced grammar checks save our reputation when we’re sending emails. And Natural Language Processing technology is available to all businesses.
Keep reading to learn:
- what problems NLP can help solve,
- available methods for text processing and which one to choose,
- specifics of data used in NLP,
- tools you can use to build NLP models,
- and finally, what stands in the way of NLP adoption and how to overcome it.
What is Natural Language Processing? Main NLP use cases
Natural language processing or NLP is a branch of Artificial Intelligence that gives machines the ability to understand natural human speech. Using linguistics, statistics, and machine learning, computers not only derive meaning from what’s said or written, they can also catch contextual nuances and a person’s intent and sentiment in the same way humans do.
So, what is possible with NLP? Here are some big text processing types and how they can be applied in real life.

Low-level vs high-level NLP tasks
Text classification
Both in daily life and in business, we deal with massive volumes of unstructured text data: emails, legal documents, product reviews, tweets, etc. all come in a diversity of formats, which makes it hard to store and make use of. Hence, many companies fail to derive value from it.
Text classification is one of NLP's fundamental techniques that helps organize and categorize text, so it’s easier to understand and use. For example, you can label assigned tasks by urgency or automatically distinguish negative comments in a sea of all your feedback.
Some common applications of text classification include the following.
Sentiment analysis. Here, text is classified based on an author’s feelings, judgments, and opinion. Sentiment analysis helps brands learn what the audience or employees think of their company or product, prioritize customer service tasks, and detect industry trends.
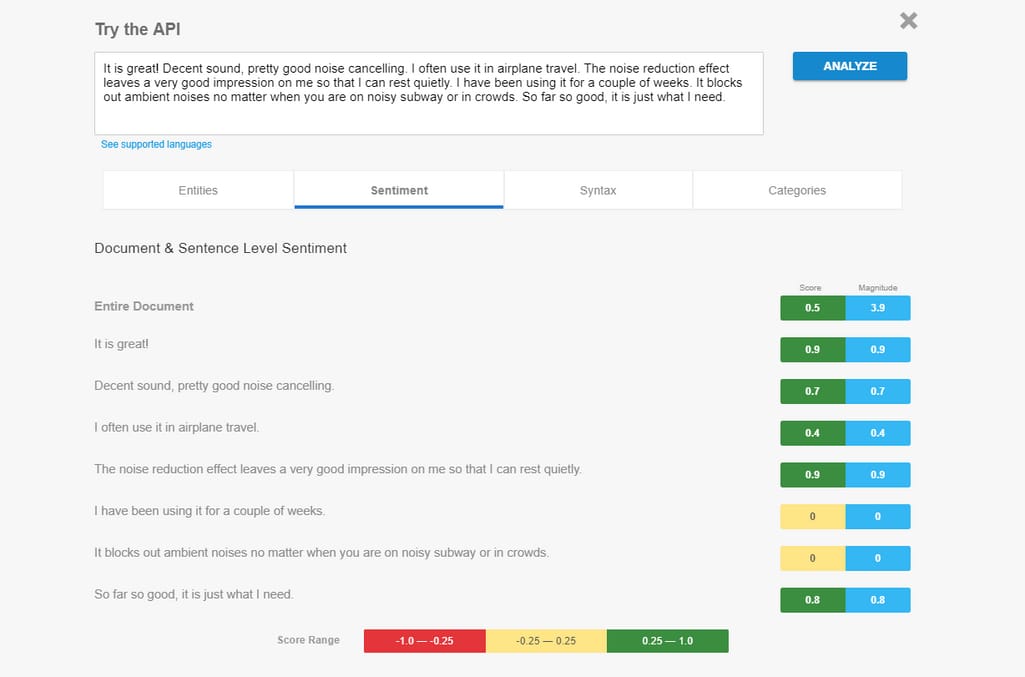
Sentiment analysis results by Google Cloud Natural Language API
Spam detection. ML-based spam detection technologies can filter out spam emails from authentic ones with minimum errors. Besides simply looking for email addresses associated with spam, these systems notice slight indications of spam emails, like bad grammar and spelling, urgency, financial language, and so on.
Language detection. Often used for directing customer requests to an appropriate team, language detection highlights the languages used in emails and chats. This can be also helpful in spam and fraud detection as language is sometimes changed to conceal suspicious activity.
Information extraction
Another way to handle unstructured text data using NLP is information extraction (IE). IE helps to retrieve predefined information such as a person’s name, a date of the event, phone number, etc., and organize it in a database.
Information extraction is a key technology in many high level tasks including:
Machine translation. Translation tools such as Google Translate rely on NLP not to just replace words in one language with words of another, but to provide contextual meaning and capture the tone and intent of the original text.
Intelligent document processing. Intelligent Document Processing is a technology that automatically extracts data from diverse documents and transforms it into the needed format. It employs NLP and computer vision to detect valuable information from the document, classify it, and extract it into a standard output format.

Information from an invoice is extracted, tagged, and structured Source: NanoNets
Question answering. Virtual assistants like Siri and Alexa and ML-based chatbots pull answers from unstructured sources for questions posed in natural language. Such dialog systems are the hardest to pull off and are considered an unsolved problem in NLP. Which of course means that there’s an abundance of research in this area.
Language modeling
You might have heard of GPT-3 -- a state-of-the-art language model that can produce eerily natural text. It predicts the next word in a sentence considering all the previous words. Not all language models are as impressive as this one, since it’s been trained on hundreds of billions of samples. But the same principle of calculating probability of word sequences can create language models that can perform impressive results in mimicking human speech.
Speech recognition. Machines understand spoken text by creating its phonetic map and then determining which combinations of words fit the model. To understand what word should be put next, it analyzes the full context using language modeling. This is the main technology behind subtitles creation tools and virtual assistants.
Text summarization. The complex process of cutting down the text to a few key informational elements can be done by extraction method as well. But to create a true abstract that will produce the summary, basically generating a new text, will require sequence to sequence modeling. This can help create automated reports, generate a news feed, annotate texts, and more. This is also what GPT-3 is doing.
This is not an exhaustive list of all NLP use cases by far, but it paints a clear picture of its diverse applications. Let’s move on to the main methods of NLP development and when you should use each of them.
Approaches to NLP: rules vs traditional ML vs neural networks
NLP techniques open tons of opportunities for human-machine interactions that we’ve been exploring for decades. Script-based systems capable of “fooling” people into thinking they were talking to a real person have existed since the 70s. But today’s programs, armed with machine learning and deep learning algorithms, go beyond picking the right line in reply, and help with many text and speech processing problems. Still, all of these methods coexist today, each making sense in certain use cases. Let’s go through them.
Rule-based NLP -- great for data preprocessing
Rules are considered an outdated approach to text processing. They’re written manually and provide some basic automatization to routine tasks. For example, you can write rules that will allow the system to identify an email address in the text because it has a familiar format, but as soon as any variety is introduced, the system's capabilities end along with a rule writer’s knowledge.
Yet, rules are still used today because in certain cases, they’re effective enough. This includes the tasks that have:
An existing rule base. For example, grammar already consists of a set of rules, same about spellings. A system armed with a dictionary will do its job well, though it won’t be able to recommend a better choice of words and phrasing.
Domain specifics. Rules are written by people who have a strong grasp of a domain. For example, even grammar rules are adapted for the system and only a linguist knows all the nuances they should include.
A small sets of rules. As soon as you have hundreds of rules, they start interacting in unexpected ways and the maintenance just won’t be worth it.
Rules are also commonly used in text preprocessing needed for ML-based NLP. For example, tokenization (splitting text data into words) and part-of-speech tagging (labeling nouns, verbs, etc.) are successfully performed by rules.
Machine learning-based NLP -- the basic way of doing NLP
Machine learning (also called statistical) methods for NLP involve using AI algorithms to solve problems without being explicitly programmed. Instead of working with human-written patterns, ML models find those patterns independently, just by analyzing texts. These won’t be the texts as we see them, of course. There are two main steps for preparing data for the machine to understand.
Text annotation and formatting. Any ML project starts with data preparation. Check our video to learn more about how data is prepared:


Data preparation, explained
In NLP tasks, this process is called building a corpus. Corpora (plural for corpus) are collections of texts used for ML training. You can’t simply feed the system your whole dataset of emails and expect it to understand what you want from it. That’s why texts must be annotated -- enhanced by providing a larger meaning. Tokenization, part-of-speech tagging, and parsing (describing the syntactic structure of a sentence) are some forms of annotations. Annotated data is then organized into standard formats, thus becoming structured.
Feature engineering. Apart from a corpus, machines use features to perceive text. Features are different characteristics like “language,” “word count,” “punctuation count,” or “word frequency” that can tell the system what matters in the text. Data scientists decide what features of the text will help the model solve the problem, usually applying their domain knowledge and creative skills. Say, the frequency feature for the words now, immediately, free, and call will indicate that the message is spam. And the punctuation count feature will direct to the exuberant use of exclamation marks.
Most frequent words in spam messages detected and visualized by spam classifier Source: Dimensionless
Model training and deployment. The prepared data is then fed to the algorithm for training. Training done with labeled data is called supervised learning and it has a great fit for most common classification problems. Some of the popular algorithms for NLP tasks are Decision Trees, Naive Bayes, Support-Vector Machine, Conditional Random Field, etc. After training the model, data scientists test and validate it to make sure it gives the most accurate predictions and is ready for running in real life. Though often, AI developers use pretrained language models created for specific problems. We will cover that in the following sections.
So, just like the rule-based approach requires linguistic knowledge to create rules, machine learning methods are only as good as the quality of data and the accuracy of features created by data scientists. This means that while ML is better at classification than rules, it falls short in two directions:
- the complexity of feature engineering, which requires researchers to do massive amounts of preparation, thus not achieving full automation with ML; and
- the curse of dimensionality, when the volumes of data needed grow exponentially with the dimension of the model, thus creating data sparsity.
That’s why a lot of research in NLP is currently concerned with a more advanced ML approach -- deep learning.
Deep learning-based NLP -- trendy state-of-the-art methods
Deep learning or deep neural networks is a branch of machine learning that simulates the way human brains work. It’s called deep because it comprises many interconnected layers -- the input layers (or synapses to continue with biological analogies) receive data and send it to hidden layers that perform hefty mathematical computations.
Neural networks are so powerful that they’re fed raw data (words represented as vectors) without any pre-engineered features. Networks will learn what features are important independently.

Statistical NLP vs deep learning
Deep learning propelled NLP onto an entirely new plane of technology. There are two revolutionary achievements that made it happen.
Word embeddings. When we feed machines input data, we represent it numerically, because that’s how computers read data. This representation must contain not only the word’s meaning, but also its context and semantic connections to other words. To densely pack this amount of data in one representation, we’ve started using vectors, or word embeddings. By capturing relationships between words, the models have increased accuracy and better predictions.
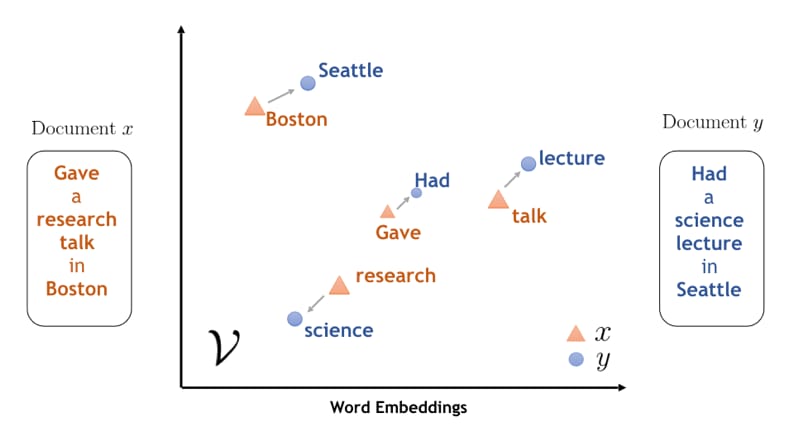
Semantically similar words are aligned in word embeddings of Document x and y. Source: IBM
Attention Mechanism. This technique inspired by human cognition helps enhance the most important parts of the sentence to devote more computing power to it. Originally designed for machine translation tasks, the attention mechanism worked as an interface between two neural networks, an encoder and decoder. The encoder takes the input sentence that must be translated and converts it into an abstract vector. The decoder converts this vector into a sentence (or other sequence) in a target language. The attention mechanism in between two neural networks allowed the system to identify the most important parts of the sentence and devote most of the computational power to it. This allowed data scientists to effectively handle long input sentences.
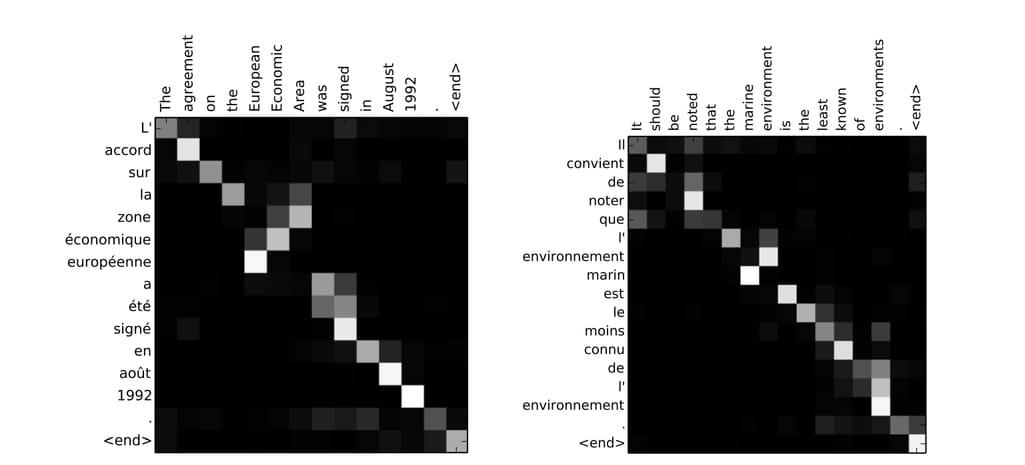
The attention mechanism in action Source: Neural Machine Translation by Jointly Learning to Align and Translate
The attention mechanism truly revolutionized deep learning models. And now it’s used beyond translation tasks. For instance, it handles human speech input for such voice assistants as Alexa to successfully recognize a speaker's intent.
Deep learning is a state-of-the-art technology for many NLP tasks, but real-life applications typically combine all three methods by improving neural networks with rules and ML mechanisms. Though the use of such methods comes with a price.
- Massive computational resources are needed to be able to process such calculations.
- Massive volumes of data are required for neural network training.
Now, armed with an understanding of the methodologies and principles behind building NLP models, let’s tackle the main component of all ML projects -- the dataset. What should it be like and how do we prepare a great one?
Preparing an NLP dataset
Great training data is a key to NLP success. But what makes data great? For ML -- and even more for deep learning -- the abundance of data matters a lot. At the same time, you want to be sure that the quality doesn’t suffer because you prioritized the size. So, the main questions ML researchers must answer when preparing data are
- how do we know we have enough data to get useful results and
- how do we measure our data’s quality?
These considerations arise both if you’re collecting data on your own or using public datasets. Let’s go through both of these questions.
Determining dataset size
No one can tell you how many product reviews, emails, sentence pairs, questions/answers you will need for an accurate outcome. For example, for our sentiment analysis tool, we collected 100,000 hotel review samples from public resources. But there are some methods to help you identify the size of a dataset that's adequate for your project. These are methods proposed by ML specialist Jason Brownlee.
Follow someone’s example. People are doing NLP projects all the time and they’re publishing their results in papers and blogs. Look for similar solutions to give you at least an estimation.
Acquire domain knowledge. Use your own knowledge or invite domain experts to correctly identify how much data is needed to capture the complexity of the task.
Use statistical heuristics. There are statistical techniques for identifying sample size for all types of research. For example, considering the number of features (x% more examples than number of features), model parameters (x examples for each parameter), or number of classes.
Guesstimate/get as much as you can. These unreliable but still popular methods will get you started. Plus, you likely won’t be able to use too much data.
Assessing text data quality
There are different views on what’s considered high quality data in different areas of application. In NLP, one quality parameter is especially important -- representational.
Representational data quality indicators consider how easy it is for a machine to understand the text. This includes the following problems in the dataset:
- wrong formulted data values (same entities with different syntax, like September 4th and 4th of September);
- typing and spelling mistakes;
- different spellings of the same word;
- co-reference problems (the same person in the text can be called Oliver, Mr. Twist, the boy, he, etc.);
- lexical ambiguity (some words and phrases in different contexts can have different meanings, like rose as a flower and rose as got up.);
- large percentage of abbreviations;
- lexical diversity; and
- large average sentence length.
NLP tools overview and comparison
The easiest way to start NLP development is by using ready-made toolkits. Pretrained on extensive corpora and providing libraries for the most common tasks, these platforms help kickstart your text processing efforts, especially with support from communities and big tech brands. There are two types to be aware of.
Open-source toolkits. Free and flexible, tools like NLTK and spaCy provide tons of resources and pretrained models, all packed in a clean interface for you to manage. They, however, are created for experienced coders with high-level ML knowledge. If you’re new to data science, you want to look into the second option.
MLaaS APIs. High-level APIs by Amazon, IBM, Google, and Microsoft are highly automated services that don’t require any machine learning knowledge and just need to be integrated into your workflow. They are paid, so are usually preferred by enterprises rather than researchers and developers. We have a large section comparing MLaaS APIs from these companies if you want to check it out.
In this article, we want to give an overview of popular open-source toolkits for people who want to go hands-on with NLP.
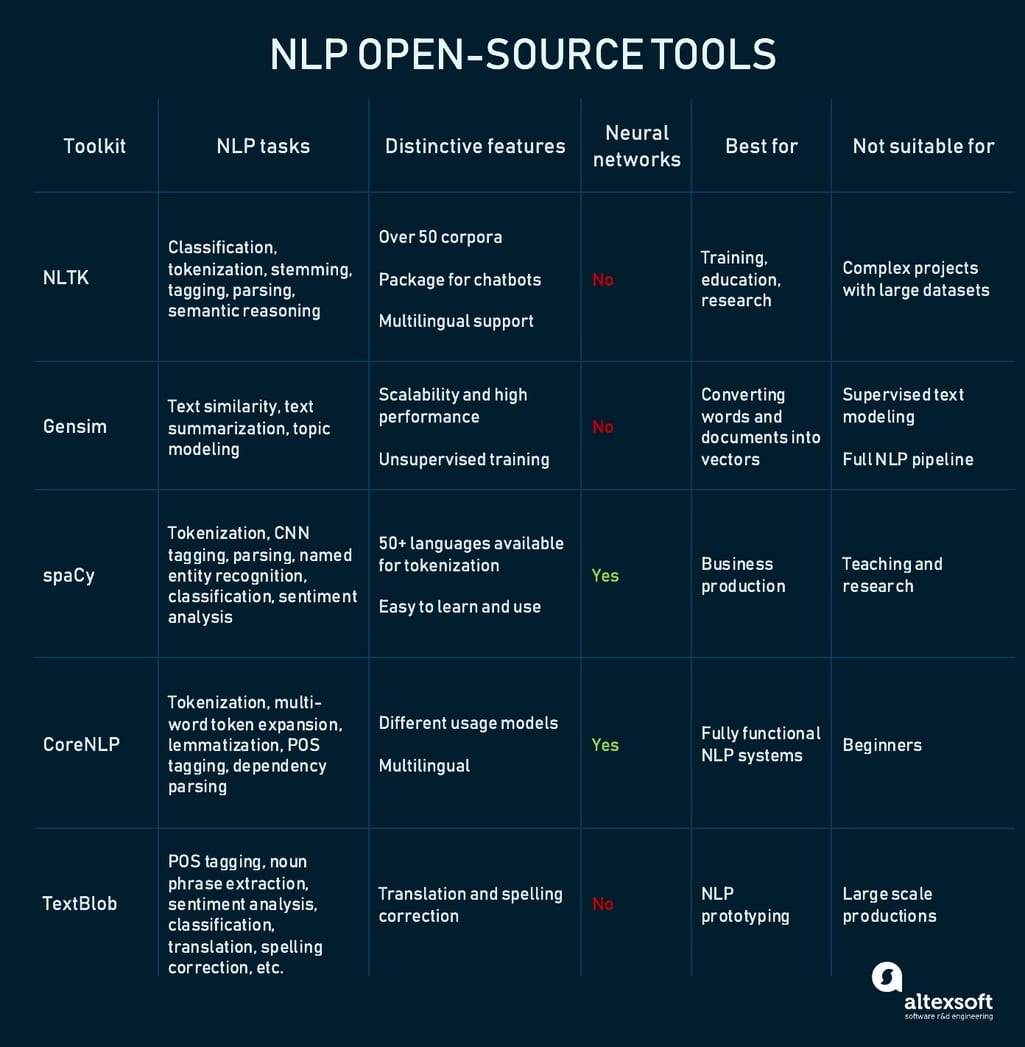
Comparing popular open-source NLP tools
NLTK -- a base for any NLP project
The Natural Language Toolkit is a platform for building Python projects popular for its massive corpora, an abundance of libraries, and detailed documentation. Though community support might be its equally substantional bonus. Whether you’re a researcher, a linguist, a student, or an ML engineer, NLTK is likely the first tool you will encounter to play and work with text analysis. It doesn’t, however, contain datasets large enough for deep learning but will be a great base for any NLP project to be augmented with other tools.
Gensim -- a library for word vectors
Another Python library, Gensim was created for unsupervised information extraction tasks such as topic modeling, document indexing, and similarity retrieval. But it’s mostly used for working with word vectors via integration with Word2Vec. The tool is famous for its performance and memory optimization capabilities allowing it to operate huge text files painlessly. Yet, it’s not a complete toolkit and should be used along with NLTK or spaCy.
spaCy -- business-ready with neural networks
Considered an advanced version of NLTK, spaCy is designed to be used in real-life production environments, operating with deep learning frameworks like TensorFlow and PyTorch. spaCy is opinionated, meaning that it doesn’t give you a choice of what algorithm to use for what task -- that’s why it’s a bad option for teaching and research. Instead, it provides a lot of business-oriented services and an end-to-end production pipeline.
CoreNLP -- language-agnostic and solid for all purposes
A comprehensive NLP platform from Stanford, CoreNLP covers all main NLP tasks performed by neural networks and has pretrained models in 6 human languages. It’s used in many real-life NLP applications and can be accessed from command line, original Java API, simple API, web service, or third-party API created for most modern programming languages.
TextBlob -- beginner tool for fast prototyping
TextBlob is a more intuitive and easy to use version of NLTK, which makes it more practical in real-life applications. Its strong suit is a language translation feature powered by Google Translate. Unfortunately, it’s also too slow for production and doesn’t have some handy features like word vectors. But it’s still recommended as a number one option for beginners and prototyping needs.
As you can see from the variety of tools, you choose one based on what fits your project best -- even if it’s just for learning and exploring text processing. You can be sure about one common feature -- all of these tools have active discussion boards where most of your problems will be addressed and answered.
Overcoming the language barrier
As we mentioned earlier, natural language processing can yield unsatisfactory results due to its complexity and numerous conditions that need to be fulfilled. That’s why businesses are wary of NLP development, fearing that investments may not lead to desired outcomes. So, what are the main challenges standing in the way of NLP adoption?
Data ambiguities and contextual understanding. Human language is insanely complex, with its sarcasm, synonyms, slang, and industry-specific terms. All of these nuances and ambiguities must be strictly detailed or the model will make mistakes.
Modeling for low resource languages. Most of the world’s NLP research is focused on English. This makes it problematic to not only find a large corpus, but also annotate your own data -- most NLP tokenization tools don’t support many languages.
High level of expertise. Even MLaaS tools created to bring AI closer to the end user are employed in companies that have data science teams. Consider all the data engineering, ML coding, data annotation, and neural network skills required -- you need people with experience and domain-specific knowledge to drive your project.
Regardless, NLP is a growing field of AI with many exciting use cases and market examples to inspire your innovation. Find your data partner to uncover all the possibilities your textual data can bring you.

Maryna is a passionate writer with a talent for simplifying complex topics for readers of all backgrounds. With 7 years of experience writing about travel technology, she is well-versed in the field. Outside of her professional writing, she enjoys reading, video games, and fashion.
Want to write an article for our blog? Read our requirements and guidelines to become a contributor.