

Whatever the industry, dealing with various documents accounts for at least a quarter of business operations. The healthcare "headache," for example, is millions of patient records and medical forms. Transportation is fueled by copious maintenance and driver logs.
The documents often come in semi-structured and unstructured data formats, which makes them difficult to process quickly and accurately. That's when intelligent document processing or IDP enters the game. IDP's main focus is minimizing or eliminating the need for any manual intervention by extracting information from different sources automatically.
This post is a perfect place to get acquainted with intelligent document processing. We'll explain the essence of IDP, guide you through its key stages, and provide real-life examples of this technology's use. By the time you finish the read, you'll know where to get started with the automation of valuable data extraction from your documents.
What is intelligent document processing (IDP)?
Intelligent document processing is the kind of technology that can automatically recognize and extract valuable data from diverse documents like scanned forms, PDF files, emails, etc., and transform it into the desired format. The technology is also referred to as Cognitive Document Processing, Intelligent Document Recognition, or Intelligent Document Capture.
Whatever the name, there are numerous reasons to implement such software, including:
- elimination of manual interventions in the document-driven workflows;
- improved data quality and reliability as human-prone errors get excluded; and
- reduction in document processing execution time, resulting in decreased operational costs.
IDP is often combined with other technologies employed to automate mundane business tasks, namely Robotic Process Automation (RPA) and Optical Character Recognition (OCR). Let’s see how all three work together and what enables the “intelligent” part of the system.
The three pillars of intelligent document processing
When it comes to processing documents in a new, smart way, it all heavily relies on three cornerstones: machine learning, optical character recognition, and robotic process automation. To better understand how the magic happens, let's picture intelligent document processing as a living organism. In this way, OCR can be seen as the "eyes,” machine learning as the "brain," and RPA as the "arms and legs."
Optical Character Recognition or OCR is a narrowly focused technology that can recognize handwritten, typed, or printed text within scanned images and convert it into a machine-readable format. As a standalone solution, OCR simply "sees" what’s there on a document and pulls out the textual part of the image, but it doesn’t understand the meanings or context. That’s why the “brain” is needed.
Machine learning is a field of knowledge that focuses on creating algorithms and training models on data so that they can process new data inputs and make decisions by themselves. IDP heavily relies on such ML-driven technologies as
- Computer Vision (CV) that utilizes deep neural networks for image recognition. It identifies patterns in visual data — say, document scans — and classifies them accordingly.
- Natural Language Processing (NLP) that finds language elements such as separate sentences, words, symbols, etc., in documents, interprets them, and performs a linguistic-based document summary.
Robotic Process Automation or RPA is designed to perform repetitive business tasks through the use of software bots (robots). The technology has proved to be effective in working with data presented in a structured format. RPA software can be configured to capture information from certain sources, process and manipulate data, and communicate with other systems. Most importantly, since RPA bots are usually rule-based, if there are any changes in the structure of the input, they won’t be able to perform a task.
So relation-wise, most IDP solutions are built on top of the RPA platforms involving the use of the OCR technology at different stages of the document processing cycle. As a result, document-driven operations can be automated end to end.
Now that we have cleared things up, let’s take a look at how intelligent document processing works step by step.
The key stages of the IDP process
Intelligent document processing goes through several stages that may vary depending on the system and business requirements.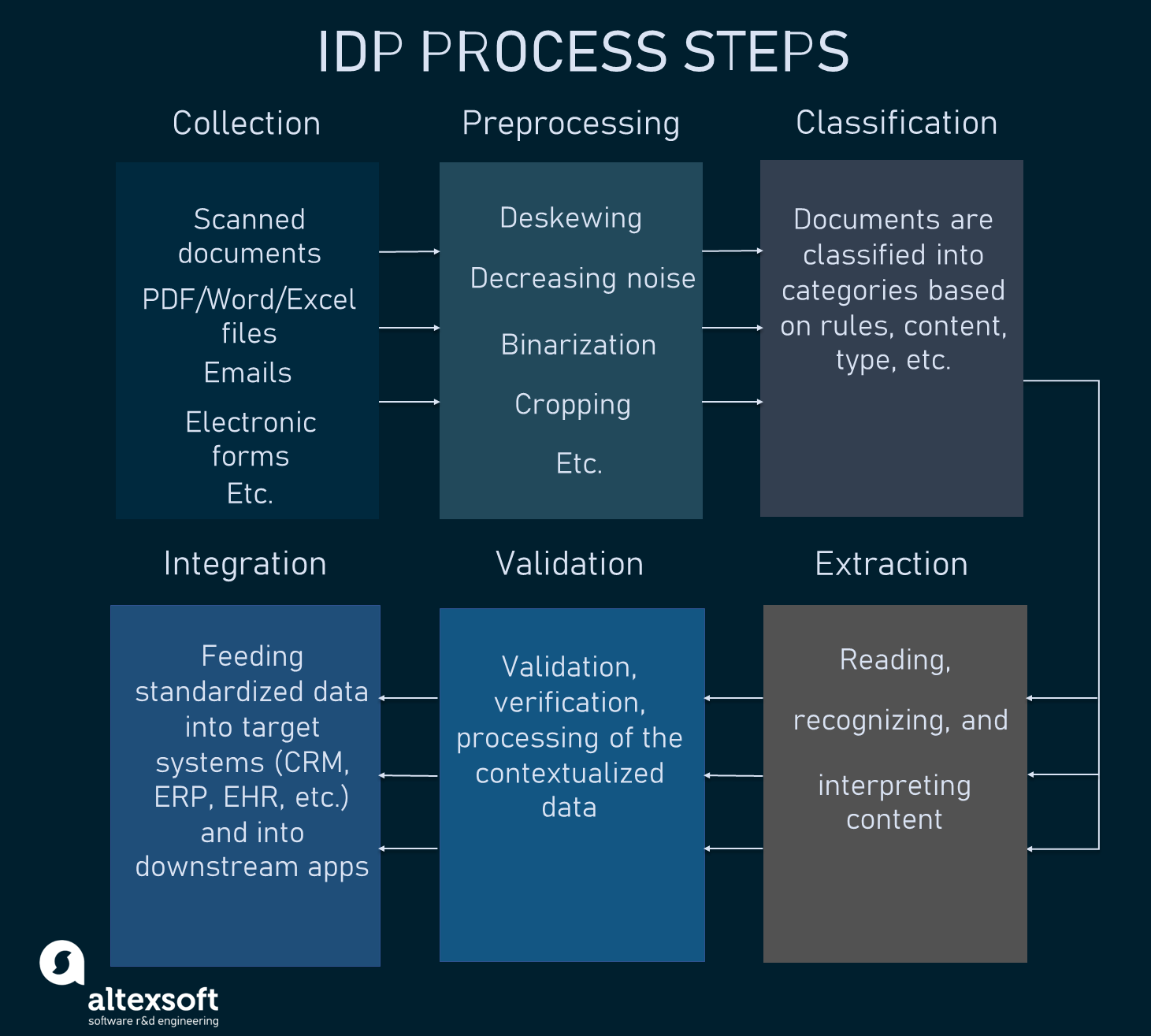
The typical IDP process in steps
The most common scenario includes collecting, pre-processing, and classifying documents with further data extraction, validation, and ingestion into IT systems such as CRM and ERP.
Document collection
Document collection is the set of actions referring to gathering different types of either paper or electronic documents from multiple content sources. At this stage, IDP solutions integrate with hardware like scanners to digitize paper/handwritten documents and speed up the scanning processes. Docs presented in digital forms, including PDF, Word, and Excel files, emails, etc., are also ingested via built-in integrations.
Document preprocessing
The next step aims at improving the quality and accuracy of scanned or camera-captured documents. Pre-processing includes procedures, like
- deskewing — correcting the angle of the scanned image skew;
- decreasing noise — getting rid of background spots, interfering strokes, uneven contrast, and other textual and non-textual noise;
- binarization — converting the grayscale scanned document image into black and white; and
- cropping — removing the unwanted outer areas from an image.

An example of a document that needs pre-processing. Source: Scribd
In scanned images, there may be numerous elements to bias the text recognition, so the use of the above-mentioned as well as other techniques is a smart move to derive the most value from the document data. To lean more about data preparation, watch our 14-minute explainer:


Data preparation, explained
Document classification
This phase aims at dividing documents into different categories by structure, content, and/or type. The step also has to do with detecting the beginning and the ending of the document.
AI-driven document classification can be performed
- based on image patterns, with the help of computer vision algorithms — in the case of scans or document pictures; and
- based on the textual content, using NLP techniques — in the case of electronic documents.
Document classification greatly enhances the follow-up extraction process as the data from a particular document gets to the right workflow faster.
Data extraction
The most critical step in the process comes after the document classification is finished. It deals with the extraction of important data from documents.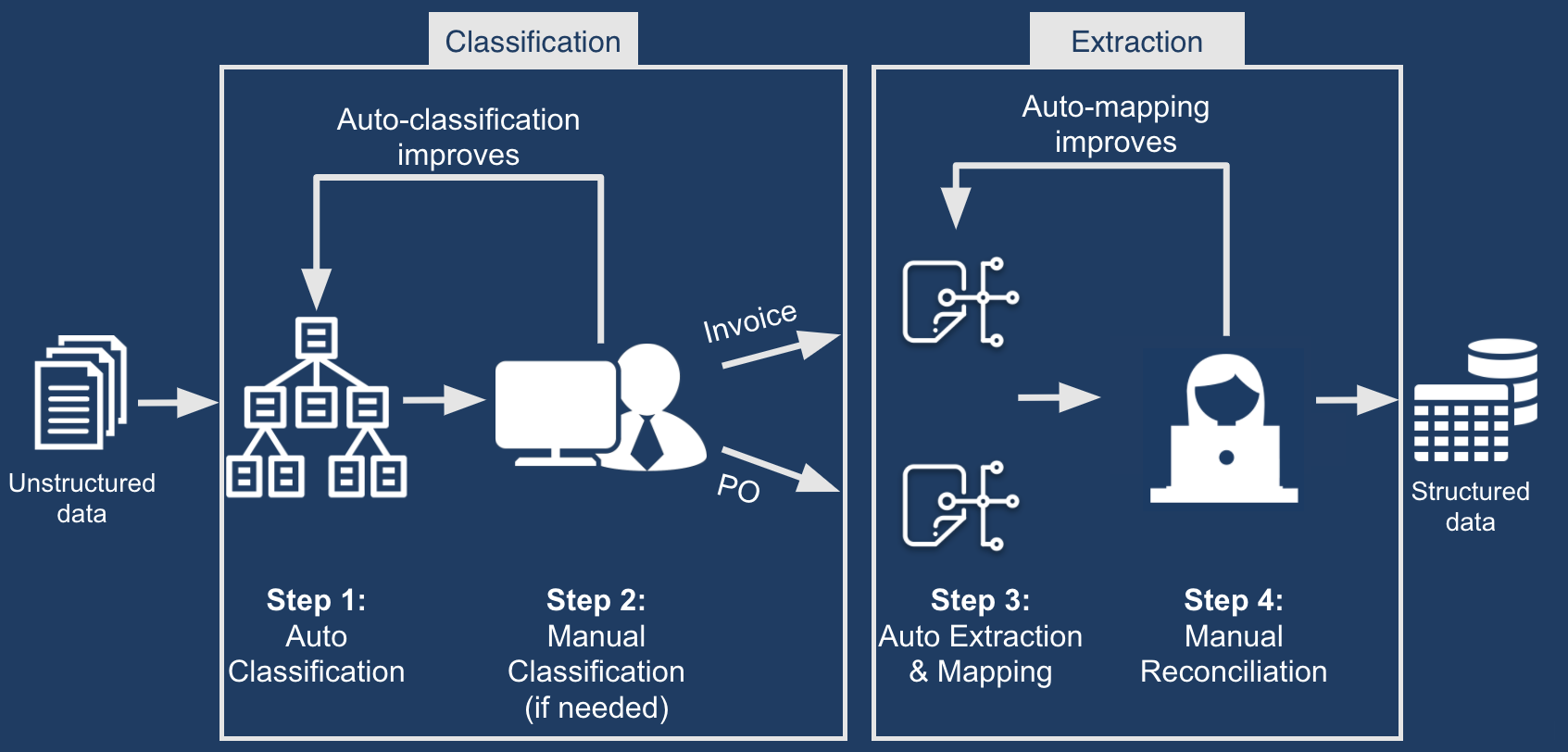
An illustration of how IDP can turn unstructured documents into a standardized structured format. Source: Appian
First, IDP relies on OCR that extracts textual data from images, scanned documents, and PDF files and converts it into a readable digital output.
Then NLP tools enter the game and decide on the type of data being extracted including dates, figures, names, etc. In addition, ML-trained models can be used to make data consistent (e.g., $5 instead of 5 dollars), correct some common misspellings, transform data into a standard output format, and much more.
Validation
Even extracted and normalized, data isn't ready for use yet. It should pass the validation procedure to ensure accuracy. At this step, RPA bots can be employed to verify data across multiple IT systems or databases and/or check it against vetted and approved documents. If the data fails validation, it has to be manually enhanced, corrected, enriched, etc.
Integration
When all these procedures are done, the data can be fed into the enterprise’s IT systems through APIs. This includes local and cloud databases and document repositories. Since we have the data in a standardized, structured variation (typically JSON or XML files), RPA tools can connect to a target system API and transfer the information there.
It’s worth noting that more often than not, IDP doesn’t automate the entire process, engaging human experts at the most critical steps.
Intelligent document processing use cases across industries
IDP implementation can be helpful for all kinds of organizations regularly engaged in manual document processing. We’ll cover the major use cases in this section.
Healthcare records
Medical forms and patient records contain tons of data that must be processed as accurately as possible. Healthcare workers can't lose even a tiny detail in that data as it may influence the effectiveness of provided care or even have fatal consequences.
With the IDP solution in place, you can automatically retrieve meaningful information from a variety of healthcare documents, including doctors’ notes, vaccination consent forms, government COVID testing forms, and health status records, to name a few.
That is partially possible thanks to such platforms as Amazon. It offers a fully-managed, HIPAA-compliant service called Amazon Comprehend Medical. The solution uses the power of machine learning not only to extract the information from a bunch of medical documents but also to decide on the relationships between the extracted information.
Loan applications in finance
Loan application processing can be streamlined greatly by enabling IDP. It can automatically analyze documents submitted to a company website, extract relevant information, verify it against existing databases, and route validated submissions to the proper systems. As a result, the complexity of the loan approval process is reduced and service quality is improved.
A UK Claims Management Company – Impakt Claims – automated their incoming payday loan claims with the help of the Robocloud RPA Service. IDP was used to enable the identification of incoming claims and check the signatures on the letters of authority to validate the person in the Case Management System. The company disclosed that automation helped their business save the cost of recruiting several full-time employees and improve the quality and speed of the process.
Insurance claims
Insurance claims make up the lion’s share of the insurance sector, which generates a mountain of documents and paperwork. The claims must be verified for eligibility against the policy documents by insurance carriers. In addition, auxiliary documents like receipts and invoices need verification too.
Some insurance claims are machine-printed, some are handwritten, and some come with attached files like photos of the damage. Going through these claims manually is a tedious, time-consuming task. With the right IDP system in place, insurance companies can automate claims processing. As a result, the relevant data is pulled out of a diversity of claims and fed into a downstream claims processing system.
Here's a detailed post about IDP in insurance.
Proof of delivery in transportation and logistics
Proof of delivery or POD is a written acknowledgment that a consignee has received the expected items from a sender.
While electronic proof of delivery keeps spreading across the industry, the hardcopy is still the most common type. To process this type of PODs more effectively and quickly, logistics companies may opt for IDP. The POD documents are scanned and injected into an IDP system.
The metadata is then extracted automatically. This data can be the name of a person who has received a product, the date and time of delivery, remarks on a product's condition, the amount of money paid, and other shipping details. When extracted, the information is available in transportation management systems, facilitating the search and retrieval of the needed information.
For example, NFT Distribution Operations Ltd. that provides food and beverage logistics services managed to automate their POD processing through IDP. They streamlined the handling of more than 100,000 PODs weekly thanks to the assistance of e-docs UK (now CogiDocs) that used the ABBYY FlexiCapture tool.
IDP technology implementation scenarios
You can get started with IDP in different ways based on your business requirements and opportunities. Here are a few possible scenarios.
Scenario 1: You work with easy-to-convert documents with little to no variation
If the documents fueling your business operations aren’t too complex and don’t vary that much, you may opt for services of legacy OCR and RPA providers that also have IDP offerings. Apart from having an advanced tool for the automation of document processing, such a choice will be more cost-effective than, say, IDP-focused or custom solutions.
Besides, if you are already working with any of the RPA or OCR vendors, it'll be a smart move to extend your collaboration with their IDP package. However, it’s worth keeping in mind that such systems may be limited in terms of functionality.
Here are a few examples of RPA and OCR vendors who also provide IDP capabilities:
- Automation Anywhere is an AI-powered cloud RPA platform that has IDP on board.
- ABBYY is a digital intelligence company specializing in OCR that also provides an intelligent document processing platform called ABBYY FlexiCapture mentioned above.
- UIPath is an end-to-end RPA platform that has an intelligent document processing solution under the hood.
- Blue Prism is one of the major RPA players that offers Decipher IDP enabling the exaction of data from structured and semi-structured documents.
Scenario 2: You deal with large volumes of complex, mostly unstructured documents
Some businesses are more demanding than others when it comes to the automation of document processing. This often has to do with a larger volume of complex documents that vary greatly. If you find yourself in this setting, you need a more innovative approach and a greater focus on artificial intelligence and machine learning technologies to improve business processes.
Here are some out-of-the-box solutions on the market that offer more comprehensive and technically complex IDP functionality to address quite demanding automation challenges.
- Infrrd is an innovative IDP-focused solution enabling high-quality data extraction from complex, unstructured documents.
- Hyperscience offers an ML-powered IDP tool that can classify and extract data within complex documents such as PDFs, emails, handwritten forms, images, and more.
- Rossum provides an end-to-end intelligent document processing solution that helps organize and automatically process incoming documents of different formats.
Scenario 3: You run a niche business with a unique document workflow
Some companies are so atypical that their business tasks cannot be solved with any existing intelligent document processing software. If you have complex requirements, it’s a good idea to opt for custom software development.
Last but not least, to implement IDP smoothly, it is recommended to
- choose a use case where humans make a final decision to minimize the cost of failure,
- run a proof of concept to make sure that the project is feasible, and
- add complexity and ML solutions step-by-step to enhance accuracy and reduce human intervention.
In this way, you will be able to tackle every – even the most demanding – challenge within your document stream.