

Sharing top billing on the list of data science capabilities, machine learning, and artificial intelligence are not just buzzwords: Many organizations are eager to adopt them. But prior to building intelligent products, you need to gather and prepare data, that fuels AI. A separate discipline — data engineering, lays the necessary groundwork for analytics projects. Tasks related to it occupy the first three layers of the data science hierarchy of needs suggested by Monica Rogati.

Data science layers towards AI by Monica Rogati
In this article, we will look at the data engineering process, explain its core components and tools, and describe the role of a data engineer.
What is data engineering?
Data engineering is a set of operations to make data available and usable to data scientists, data analysts, business intelligence (BI) developers, and other specialists within an organization. It takes dedicated experts – data engineers – to design and build systems for gathering and storing data at scale as well as preparing it for further analysis.


Main concepts and tools of data engineering
Within a large organization, there are usually many different types of operations management software (e.g., ERP, CRM, production systems, etc.), all containing databases with varied information. Besides, data can be stored as separate files or pulled from external sources — such as IoT devices — in real time. Having data scattered in different formats prevents the organization from seeing a clear picture of its business state and running analytics.
Data engineering addresses this problem step by step.
Data engineering process
The data engineering process covers a sequence of tasks that turn a large amount of raw data into a practical product meeting the needs of analysts, data scientists, machine learning engineers, and others. Typically, the end-to-end workflow consists of the following stages.

A data engineering process in brief
Data ingestion (acquisition) moves data from multiple sources — SQL and NoSQL databases, IoT devices, websites, streaming services, etc. — to a target system to be transformed for further analysis. Data comes in various forms and can be both structured and unstructured.
Data transformation adjusts disparate data to the needs of end users. It involves removing errors and duplicates from data, normalizing it, and converting it into the needed format.
Data serving delivers transformed data to end users — a BI platform, dashboard, or data science team.

How data science teams work
Data flow orchestration provides visibility into the data engineering process, ensuring that all tasks are successfully completed. It coordinates and continuously tracks data workflows to detect and fix data quality and performance issues.
The mechanism that automates ingestion, transformation, and serving steps of the data engineering process is known as a data pipeline.
Data engineering pipeline
A data pipeline combines tools and operations that move data from one system to another for storage and further handling. Constructing and maintaining data pipelines is the core responsibility of data engineers. Among other things, they write scripts to automate repetitive tasks – jobs.
Commonly, pipelines are used for
- data migration between systems or environments (from on-premises to cloud databases);
- data wrangling or converting raw data into a usable format for analytics, BI, and machine learning projects;
- data integration from various systems and IoT devices; and
- copying tables from one database to another.
To learn more, read our detailed explanatory post — Data Pipeline: Components, Types, and Use Cases. Or stay here to briefly explore common types of data pipelines.
ETL pipeline
ETL (Extract, Transform, Load) pipeline is the most common architecture that has been here for decades. It’s often implemented by a dedicated specialist — an ETL developer.
As the name suggests, an ETL pipeline automates the following processes.
- Extract — retrieving data. At the start of the pipeline, we’re dealing with raw data from numerous sources — databases, APIs, files, etc.
- Transform — standardizing data. Having data extracted, scripts transform it to meet the format requirements. Data transformation significantly improves data discoverability and usability.
- Load — saving data to a new destination. After bringing data into a usable state, engineers can load it to the destination, typically a database management system (DBMS) or data warehouse.
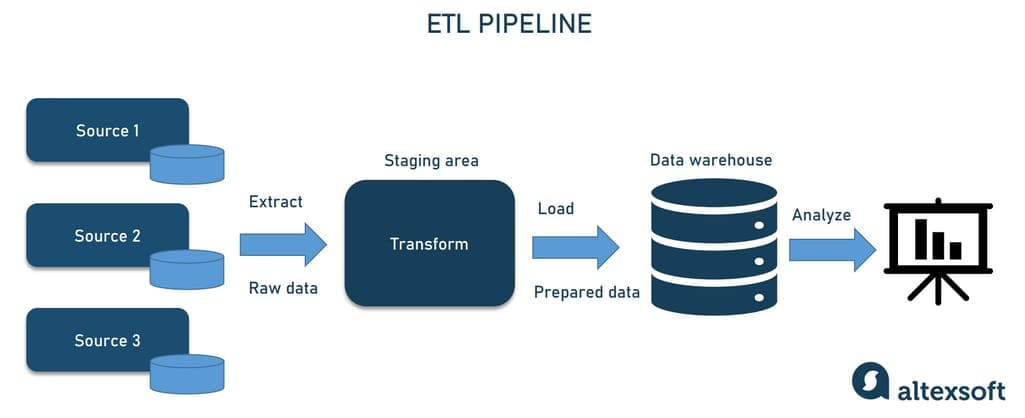
ETL operations
Once the data is transformed and loaded into a centralized repository, it can be used for further analysis and business intelligence operations, i.e., generating reports, creating visualizations, etc. The specialist implementing ETL pipelines
ELT pipeline
An ELT pipeline performs the same steps but in a different order — Extract, Load, Transform. Instead of transforming all the collected data, you place it into a data warehouse, data lake, or data lakehouse. Later, you can process and format it fully or partially, once or numerous times.
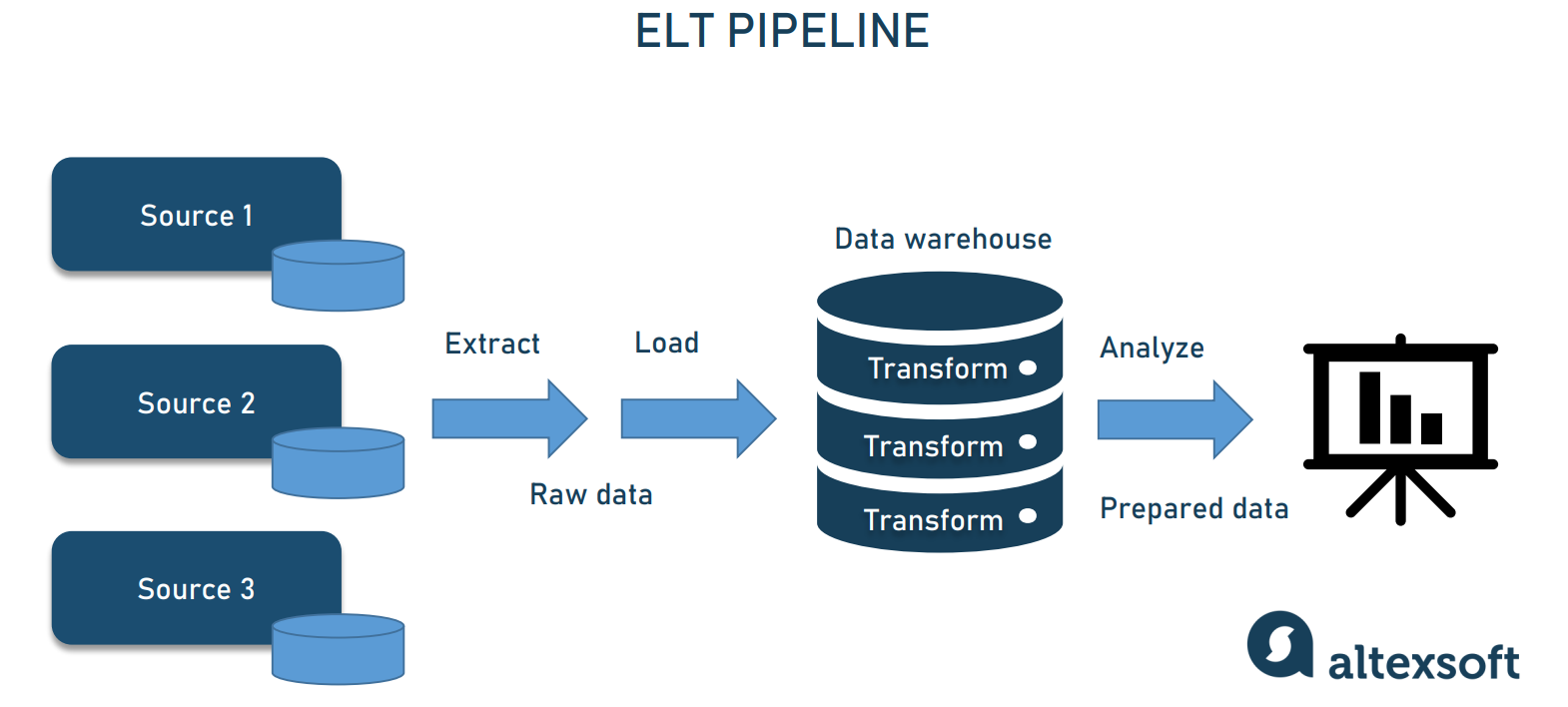
ELT operations
ELT pipelines are preferable when you want to ingest as much data as possible and transform it later, depending on the needs arising. Unlike ETL, the ELT architecture doesn’t require you to decide on data types and formats in advance. In large-scale projects, two types of data pipelines are often combined to enable both traditional and real-time analytics. Also, two architectures can be involved to support Big Data analytics.
Read our article ETL vs ELT: Key differences to dive deeper into the subject.
Data pipeline challenges
Setting up secure and reliable data flow is challenging. Many things can go wrong during data transportation: Data can be corrupted, hit bottlenecks causing latency, or data sources may conflict, generating duplicate or incorrect data. Getting data into one place requires careful planning and testing to filter out junk data, eliminating duplicates and incompatible data types to obfuscate sensitive information while not missing critical data.
Juan De Dios Santos, an experienced practitioner in the data industry, outlines two major pitfalls in building data pipelines:
- lacking relevant metrics and
- underestimating data load.
“The importance of a healthy and relevant metrics system is that it can inform us of the status and performance of each pipeline stage while underestimating the data load, I am referring to building the system in such a way that it won’t face any overload if the product experiences an unexpected surge of users,” elaborates Juan.
Besides a pipeline, a data warehouse must be built to support and facilitate data science activities. Let’s see how it works.
Data warehouse
A data warehouse (DW) is a central repository storing data in queryable forms. From a technical standpoint, a data warehouse is a relational database optimized for reading, aggregating, and querying large volumes of data. Traditionally, DWs only contained structured data or data that can be arranged in tables. However, modern DWs can also support unstructured data (such as images, pdf files, and audio formats).
Without DWs, data scientists would have to pull data straight from the production database and may report different results to the same question or cause delays and even outages. Serving as an enterprise’s single source of truth, the data warehouse simplifies the organization’s reporting and analysis, decision-making, and metrics forecasting.
Surprisingly, DW isn’t a regular database. How so?
First of all, they differ in terms of data structure. A typical database normalizes data excluding any data redundancies and separating related data into tables. This takes up a lot of computing resources, as a single query combines data from many tables. Contrarily, a DW uses simple queries with few tables to improve performance and analytics.
Second, aimed at day-to-day transactions, standard transactional databases don’t usually store historical data, while for warehouses, it’s their primary purpose, as they collect data from multiple periods. DW simplifies a data analyst’s job, allowing for manipulating all data from a single interface and deriving analytics, visualizations, and statistics.
Data vault architecture is a method of building a data warehouse. Our dedicated article covers this approach in detail; read it to learn more.
Typically, a data warehouse doesn’t support as many concurrent users as a database designed for a small group of analysts and decision-makers. 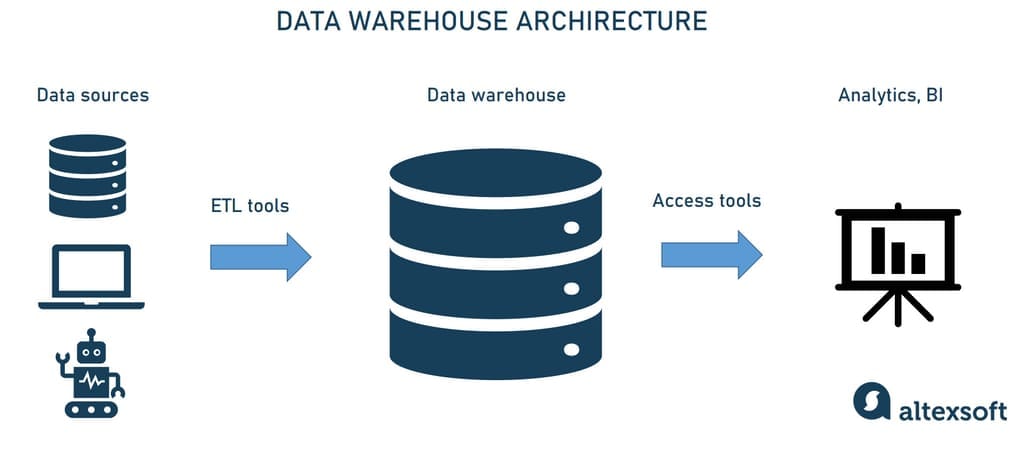
Data architecture with a data warehouse
To construct a data warehouse, four essential components are combined.
Data warehouse storage. The foundation of data warehouse architecture is a database that stores all enterprise data allowing business users to access it to draw valuable insights.
Data architects usually decide between on-premises and cloud-hosted DWs noting how the business can benefit from this or that solution. Although the cloud environment is more cost-efficient, easier to scale up or down, and isn’t limited to a prescribed structure, it may lose to on-prem solutions regarding querying speed and security. We’re going to list the most popular tools further on.
A data architect can also design collective storage for your data warehouse – multiple databases running in parallel. This will improve the warehouse’s scalability.
Metadata. Adding business context to data, metadata helps transform it into comprehensible knowledge. Metadata defines how data can be changed and processed. It contains information about any transformations or operations applied to source data while loading it into the data warehouse.
Data warehouse access tools. These instruments vary in functionality. For example, query and reporting tools are used for generating business analysis reports. And data mining tools automate finding patterns and correlations in large amounts of data based on advanced statistical modeling techniques.
Data warehouse management tools. Spanning the enterprise, the data warehouse deals with a number of management and administrative operations. Dedicated data warehouse management tools exist to accomplish this.
For more detailed information, visit our dedicated post — Enterprise Data Warehouse: EDW Components, Key Concepts, and Architecture Types.
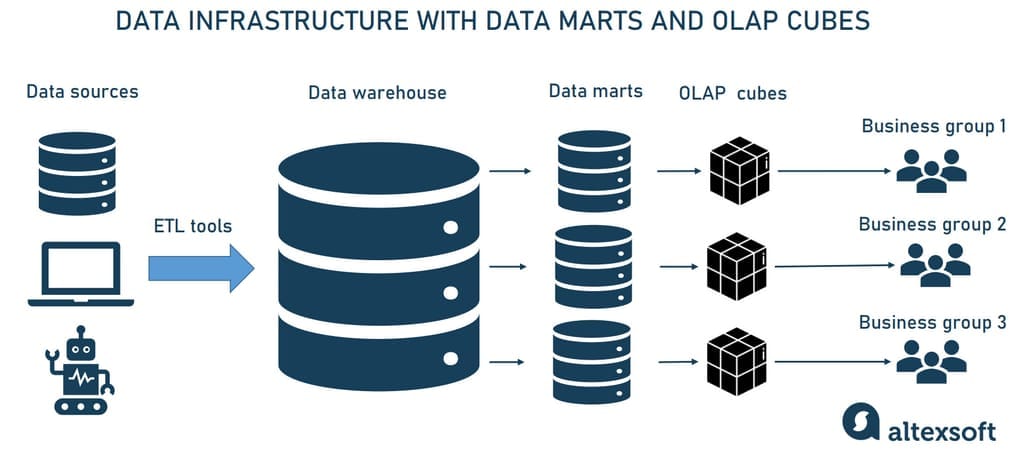
Data warehouses are a significant step forward in enhancing your data architecture. However, DWs can be too bulky and slow to operate if you have hundreds of users from different departments. In this case, data marts can be built and implemented to increase speed and efficiency.
Data marts
Simply speaking, a data mart is a smaller data warehouse (their size is usually less than 100Gb.). They become necessary when the company and the amount of its data grow and it becomes too long and ineffective to search for information in an enterprise DW. Instead, data marts are built to allow different departments (e.g., sales, marketing, C-suite) to access relevant information quickly and easily.
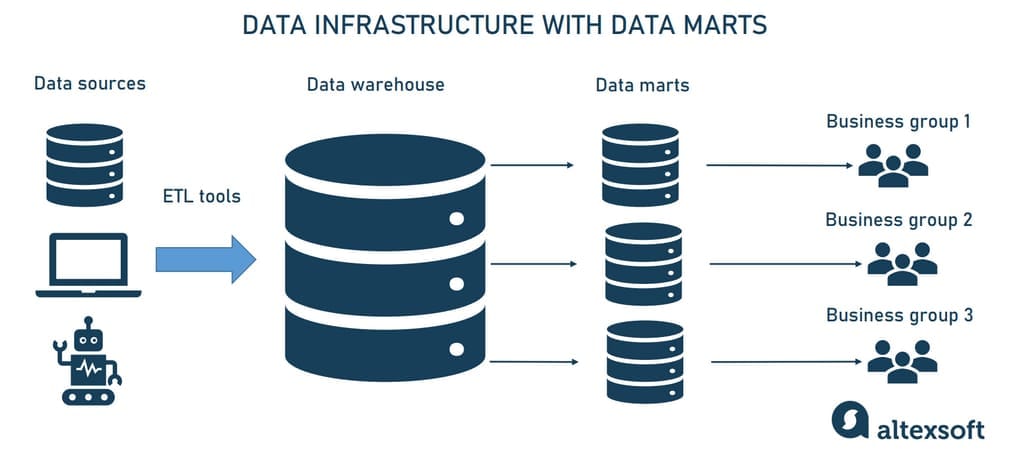
The place of data marts in the data infrastructure
There are three main types of data marts.
Dependent data marts are created from an enterprise DW and used as a primary source of information (also known as a top-down approach).
Independent data marts are standalone systems that function without DWs extracting information from various external and internal sources (it’s also known as a top-down approach).
Hybrid data marts combine information from both DW and other operational systems.
So, the main difference between data warehouses and data marts is that a DW is a large repository that holds all company data extracted from multiple sources, making it difficult to process and manage queries. Meanwhile, a data mart is a smaller repository containing a limited amount of data for a particular business group or department.
If you want to learn more, read our comprehensive overview — Data Marts: What They Are and Why Businesses Need Them.
While data marts allow business users to quickly access the queried data, often just getting the information is not enough. It has to be efficiently processed and analyzed to get actionable insights that support decision-making. Looking at your data from different perspectives is possible thanks to OLAP cubes. Let’s see what they are.
OLAP and OLAP cubes
OLAP or Online Analytical Processing refers to the computing approach allowing users to analyze multidimensional data. It’s contrasted with OLTP or Online Transactional Processing, a simpler method of interacting with databases, not designed for analyzing massive amounts of data from different perspectives.
Traditional databases resemble spreadsheets, using the two-dimensional structure of rows and columns. However, in OLAP, datasets are presented in multidimensional structures -- OLAP cubes. Such structures enable efficient processing and advanced analysis of vast amounts of varied data. For example, a sales department report would include such dimensions as product, region, sales representative, sales amount, month, and so on.
Information from DWs is aggregated and loaded into the OLAP cube, where it gets precalculated and is readily available for user requests.
Data analysis with OLAP cubes
Within OLAP, data can be analyzed from multiple perspectives. For example, it can be drilled down/rolled up if you need to change the hierarchy level of data representation and get a more or less detailed picture. You can also slice information to segment a particular dataset as a separate spreadsheet or dice it to create a different cube. These and other techniques enable finding patterns in varied data and creating a wide range of reports.
It’s important to note that OLAP cubes must be custom-built for every report or analytical query. However, their usage is justified since, as we said, they facilitate advanced, multidimensional analysis that was previously too complicated to perform.
Read our article What is OLAP: A Complete Guide to Online Analytical Processing for a more detailed explanation.
Big data engineering
Speaking about data engineering, we can’t ignore Big Data. Grounded in the four Vs – volume, velocity, variety, and veracity – it usually floods large technology companies like YouTube, Amazon, or Instagram. Big Data engineering is about building massive reservoirs and highly scalable and fault-tolerant distributed systems.
Big data architecture differs from conventional data handling, as here we’re talking about such massive volumes of rapidly changing information streams that a data warehouse can’t accommodate. That’s where a data lake comes in handy.
Data lake
A data lake is a vast pool for saving data in its native, unprocessed form. It stands out for its high agility as it isn’t limited to a warehouse’s fixed configuration.
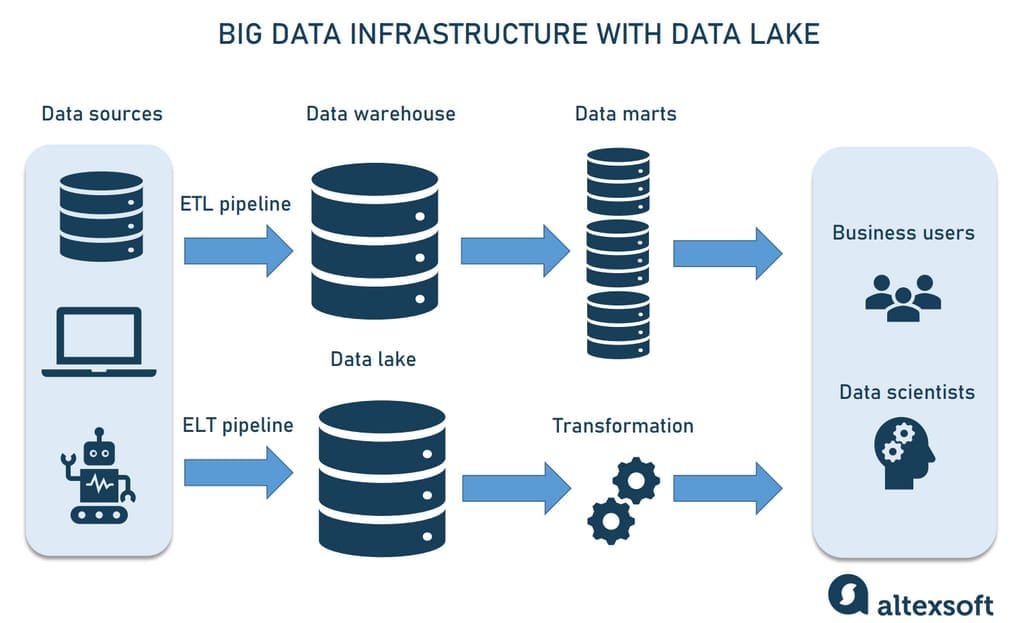
Big data architecture with a data lake
A data lake uses the ELT approach and starts data loading immediately after extracting it, handling raw — often unstructured — data.
A data lake is worth building in those projects that will scale and need a more advanced architecture. Besides, it’s very convenient when the purpose of the data hasn’t been determined yet. In this case, you can load data quickly, store it, and modify it as necessary.
Data lakes are also a powerful tool for data scientists and ML engineers, who would use raw data to prepare it for predictive analytics and machine learning. Read more about data preparation in our separate article or watch this 14-minute explainer.

How to prepare datasets for machine learning projects
Lakes are built on large, distributed clusters that would be able to store and process masses of data. A famous example of such a data lake platform is Hadoop.
Hadoop and its ecosystem
Hadoop is a large-scale, Java-based data processing framework capable of analyzing massive datasets. The platform facilitates splitting data analysis jobs across various servers and running them in parallel. It consists of three components:
- Hadoop Distributed File System (HDFS) capable of storing Big Data,
- a processing engine MapReduce, and
- a resource manager YARN to control and monitor workloads.
Also, Hadoop benefits from a vast ecosystem of open-source tools that enhance its capabilities and address various challenges of Big Data.
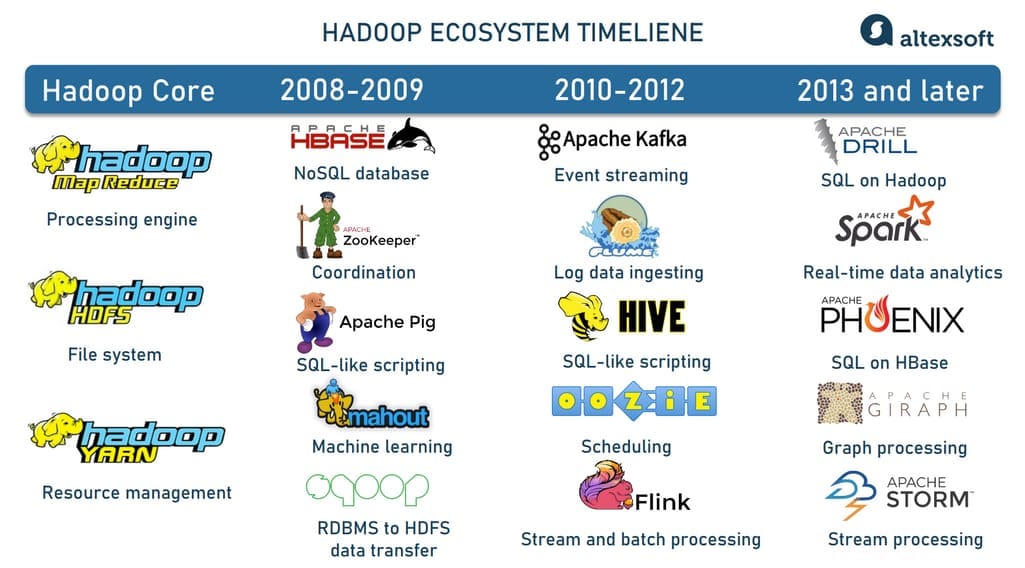
Hadoop ecosystem evolvement
Some popular instruments within the Hadoop ecosystem are
- HBase, a NoSQL database built on top of HDFS that provides real-time access to read or write data;
- Apache Pig, Apache Hive, Apache Drill, and Apache Phoenix to simplify Big Data exploration and analysis when working with HBase, HDFS, and MapReduce; and
- Apache Zookeeper and Apache Oozie to coordinate operations and schedule jobs across a Hadoop cluster.
Read about the advantages and pitfalls of Hadoop in our dedicated article The Good and the Bad of Hadoop Big Data Framework.
Streaming analytics instruments
Tools enabling streaming analytics form a vital group within the Hadoop ecosystem. These include
- Apache Spark, a computing engine for large datasets with near-real-time processing capabilities;
- Apache Storm, a real-time computing system for unbounded streams of data (those that have a start but no defined end and must be continuously processed);
- Apache Flink processing both unbounded and bounded data streams (those with a defined start and end); and
- Apache Kafka, a streaming platform for messaging, storing, processing, and integrating large volumes of data.

Kafka and data streaming, explained
All these technologies are used to build real-time Big Data pipelines. You can get more information from our articles Hadoop vs Spark: Main Big Data Tools Explained and The Good and the Bad of Apache Kafka Streaming Platform.
Enterprise data hub
When a big data pipeline is not managed correctly, data lakes quickly become data swamps – a collection of miscellaneous data that is neither governable nor usable. A new data integration approach called a data hub emerged to tackle this problem.
Enterprise data hubs (EDHs) are the next generation of data architecture aiming at sharing managed data between systems. They connect multiple sources of information, including DWs and data lakes. Unlike DWs, the data hub supports all types of data and easily integrates systems. Besides that, it can be deployed within weeks or even days while DW deployment can last months and even years.
At the same time, data hubs come with additional capabilities for data management, harmonizing, exploration, and analysis — something data lakes lack. They are business-oriented and tailored for the most urgent organization’s needs.
To sum it all up,
- a data warehouse is constructed to deal mainly with structured data for the purpose of self-service analytics and BI;
- a data lake is built to deal with sizable aggregates of both structured and unstructured data to support deep learning, machine learning, and AI in general; and
- a data hub is created for multi-structured data portability, easier exchange, and efficient processing.
An EDH can be integrated with a DW and/or a data lake to streamline data processing and deal with these architectures' everyday challenges.
Read our article What is Data Hub: Purpose, Architecture Patterns, and Existing Solutions Overview to learn more.
Role of data engineer
Now that we know what data engineering is concerned with, let’s delve into the role that specializes in creating software solutions around big data –a data engineer.
Juan De Dios Santos, a data engineer himself, defines this role in the following way: “In a multidisciplinary team that includes data scientists, BI engineers, and data engineers, the role of the data engineer is mostly to ensure the quality and availability of the data.” He also adds that a data engineer might collaborate with others when implementing or designing a data-related feature (or product) such as an A/B test, deploying a machine learning model, and refining an existing data source.
We have a separate article explaining what a data engineer is, so here we’ll only briefly recap.
Skills and qualifications
Data engineering lies at the intersection of software engineering and data science, which leads to skill overlapping.
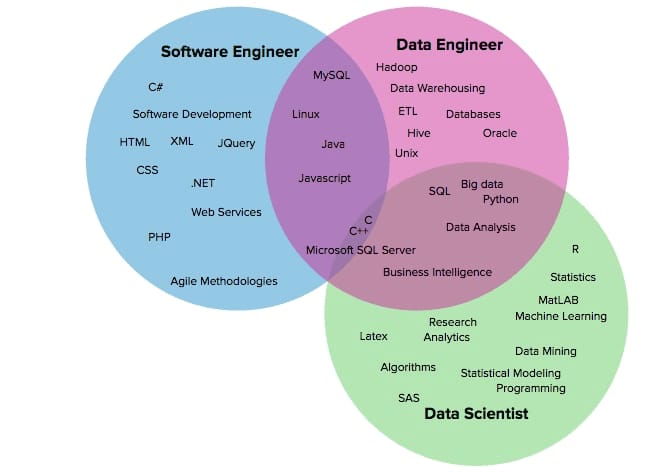
Overlapping skills of the software engineer, data engineer, and data scientist. Source: Ryan Swanstrom
Software engineering background. Data engineers use programming languages to enable reliable and convenient access to data and databases. Juan points out their ability to work with the complete software development cycle, including ideation, architecture design, prototyping, testing, deployment, DevOps, defining metrics, and monitoring systems. Data engineers are experienced programmers in at least Python or Scala/Java.
Data-related skills. “A data engineer should have knowledge of multiple kinds of databases (SQL and NoSQL), data platforms, concepts such as MapReduce, batch and stream processing, and even some basic theory of data itself, e.g., data types, and descriptive statistics,” underlines Juan.
Systems creation skills. Data engineers need experience with various data storage technologies and frameworks they can combine to build data pipelines.
Toolkit
A data engineer should have a deep understanding of many data technologies to be able to choose the right ones for a specific job.
Airflow. This Python-based workflow management system was developed by Airbnb to rearchitect its data pipelines. Migrating to Airflow, the company reduced their experimentation reporting framework (ERF) run-time from 24+ hours to about 45 minutes. Among the Airflow’s pros, Juan highlights its operators: “They allow us to execute bash commands, run a SQL query or even send an email.” Juan also stresses Airflow’s ability to send Slack notifications, complete and rich UI, and the overall maturity of the project. On the contrary, Juan dislikes that Airflow only allows for writing jobs in Python.
Read our article The Good and the Bad of Apache Airflow Pipeline Orchestration to learn more.
Cloud Dataflow. A cloud-based data processing service, Dataflow is aimed at large-scale data ingestion and low-latency processing through fast parallel execution of the analytics pipelines. Dataflow is beneficial over Airflow as it supports multiple languages like Java, Python, SQL, and engines like Flink and Spark. It is also well maintained by Google Cloud. However, Juan warns that Dataflow’s high cost might be a disadvantage.
Other popular instruments are the Stitch platform for rapidly moving data and Blendo, a tool for syncing various data sources with a data warehouse.
Warehouse solutions. Widely used on-premise data warehouse tools include Teradata Data Warehouse, SAP Data Warehouse, IBM db2, and Oracle Exadata. The most popular cloud-based data warehouse solutions are Amazon Redshift and Google BigQuery. Be sure to check our detailed comparison of the top cloud warehouse software.
Big data tools. Technologies that a data engineer should master (or at least know of) are Hadoop and its ecosystem, Elastic Stack for end-to-end big data analytics, data lakes, and more.
Data engineer vs data scientist
It’s not rare that a data engineer is confused with a data scientist. We asked Alexander Konduforov, a data scientist with over ten years of experience, to comment on the difference between these roles.
“Both data scientists and data engineers work with data but solve quite different tasks, have different skills, and use different tools,” Alexander explained, “Data engineers build and maintain massive data storage and apply engineering skills: programming languages, ETL techniques, knowledge of different data warehouses and database languages. Whereas data scientists clean and analyze this data, get valuable insights from it, implement models for forecasting and predictive analytics, and mostly apply their math and algorithmic skills, machine learning algorithms and tools.”
Alexander stresses that accessing data can be a difficult task for data scientists for several reasons.
- Vast data volumes require additional effort and specific engineering solutions to access and process them in a reasonable amount of time.
- Data is usually stored in lots of different systems and formats. It makes sense first to take data preparation steps and move information to a central repository like a data warehouse makes sense. This is typically a task for data architects and engineers.
- Data repositories have different APIs for accessing them. Data scientists need data engineers to implement the most efficient and reliable pipeline for getting data.
As we can see, working with storage systems built and served by data engineers, data scientists become their “internal clients.” That’s where their collaboration takes place.