

Data systematizes daily processes and governs them by enabling data-driven decisions for businesses and organizations. But in order to analyze the information correctly and profit from it, you should guarantee data integrity. This article explores what data integrity is, what it is not, and why it’s difficult to achieve the integrity. Also, we dive into data integrity threats and propose countermeasures to them.
Learn about master data mangement, its examples, and how it improves data integrity.
What is data integrity?
Data integrity ensures that data is complete, consistent, accurate, and up to date throughout its lifecycle, from collection,to usage, and to deletion. Data integrity failure undermines management and decision making, while increasing the risks related to safety.
There is a set of requirements that ensures data integrity called ALCOA. The acronym stands for attributable, legible, contemporaneous, original, and accurate. It was suggested by the US Food and Drug Administration (FDA) to define good data integrity practices within the pharmaceutical, biologic, medical device, and food industries. Applied within the healthcare industry, this set of requirements can guide data integrity practices across other domains as well. Let’s have a look at these principles.
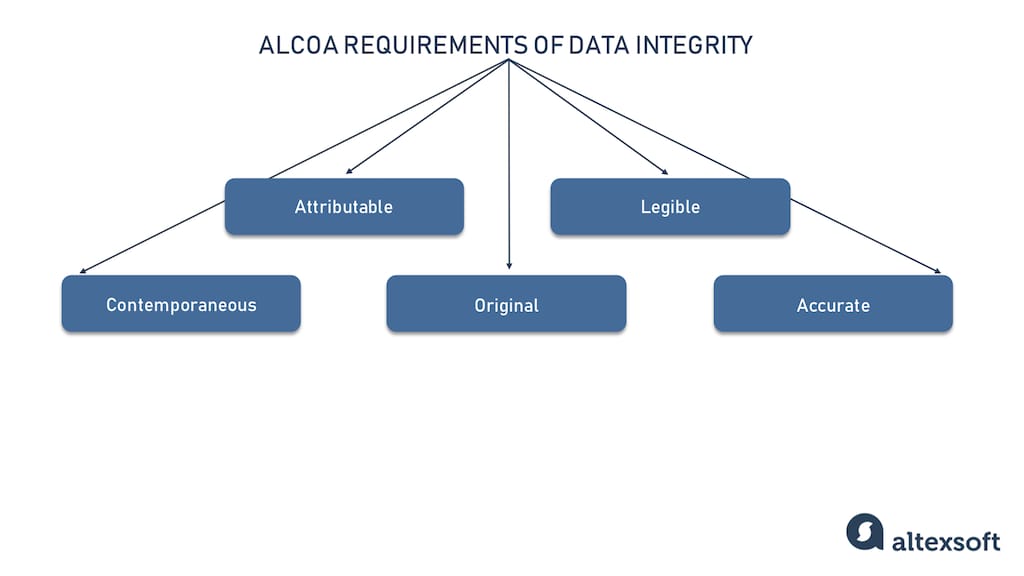
ALCOA requirements of data integrity
- The attributable principle means there must be a clear indication of who recorded data and when (read more about these and other metadata attributes in a separate post).
- Legible criteria means that it must be possible to read and interpret data after recording. Also data shouldn’t contain unexplained symbols. And in case of corrections, there must be a justified reason for them.
- Contemporaneous refers to time requirements: Data must be recorded at the moment it was generated.
- The originality of data requires that data be preserved in an unaltered state, and all its modifications should have a valid reason.
- Accuracy points out that data should reflect actions or observations correctly.
Sometimes to define a concept better we must understand not only what it is but also what it is not. Data integrity is often confused with data quality, data accuracy, and data security. Let’s discuss the differences between them.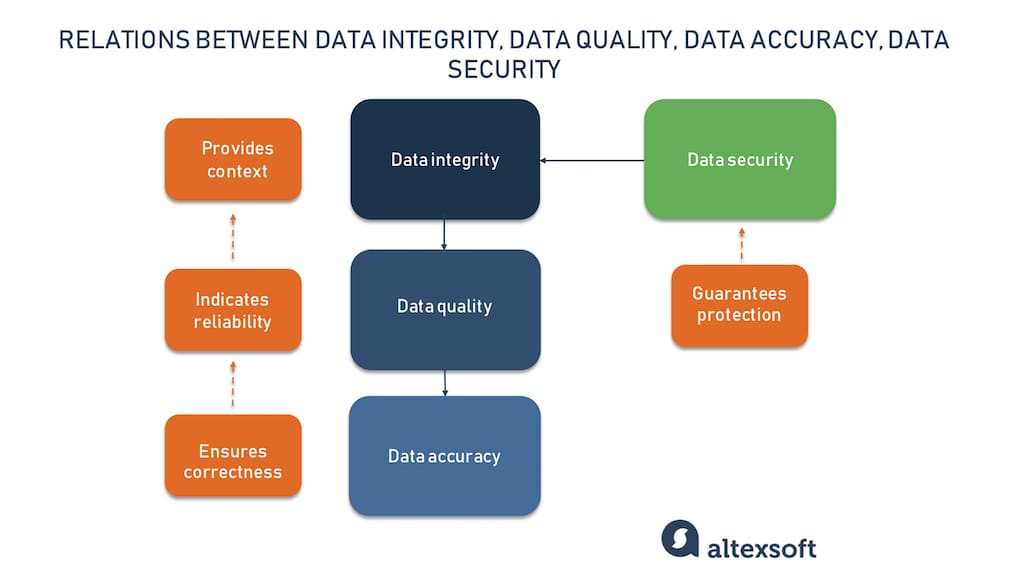
Relations between data integrity, data quality, data accuracy, and data security
Data integrity vs data quality
Data quality indicates how reliable the data is to serve a specific purpose, while data integrity ensures the safety of information on servers and machines, and also its rationality and logic. In the bigger picture, data quality is subject to data integrity. Notice that quality is not equal to usefulness; data can be fully in order but without a purpose, it serves no goal. Data integrity provides context to measure the quality, making it useful and applicable.
Data integrity vs data accuracy
Data accuracy ensures that information is correct, complete, trustworthy, and represents reality in a reliable way. Data accuracy is subject to data quality, as it’s the first component of quality validation. And so data quality is the starting point for data integrity.
Data integrity vs data security
While the previous two are under the umbrella of data integrity, data security is a separate concept. Data security represents the set of measures to ensure the protection of the information and well functioning of software and hardware environments. It prevents data corruption caused by malicious actions, unauthorized access, viruses, and bugs. Basically, data security serves the well-being of data integrity.
Types of data integrity
There are two main types of data integrity: physical and logical. Let’s discuss each type and have a look at examples.
Physical integrity
Physical integrity ensures proper storage of data on hardware and physical copies and available access to it. Physical integrity can be compromised by all kinds of threats that occur in the physical environment. For example, device failure, power outages, natural disasters, and extreme weather conditions.
Logical integrity
Logical integrity means that data makes sense in a particular context. It governs the correctness and rationality of information by providing four integration requirements.
Entity integration deals with the primary key concept. Basically, it states that every row in the table must have a unique ID. For example, we have a dataset of customers with information about their name and sex. Naturally, there could be two persons with the same name and, most likely, the same sex. To indicate that these are different people, we assign an ID to each.
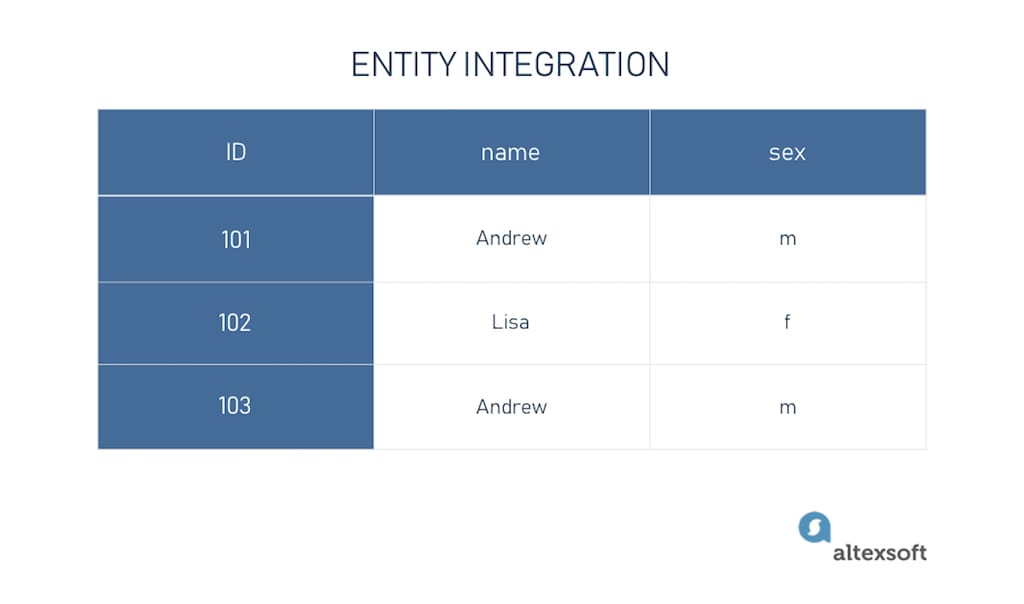
Example of entity data integrity
Referential integrity introduces a foreign key into databases. A foreign key ensures that data is consistent in the relation between two different tables, so modifications or deletions wouldn’t affect data integrity. For example, if we have one table with customer data and the other one with orders, the primary key of the first table becomes a foreign key for the second datasheet.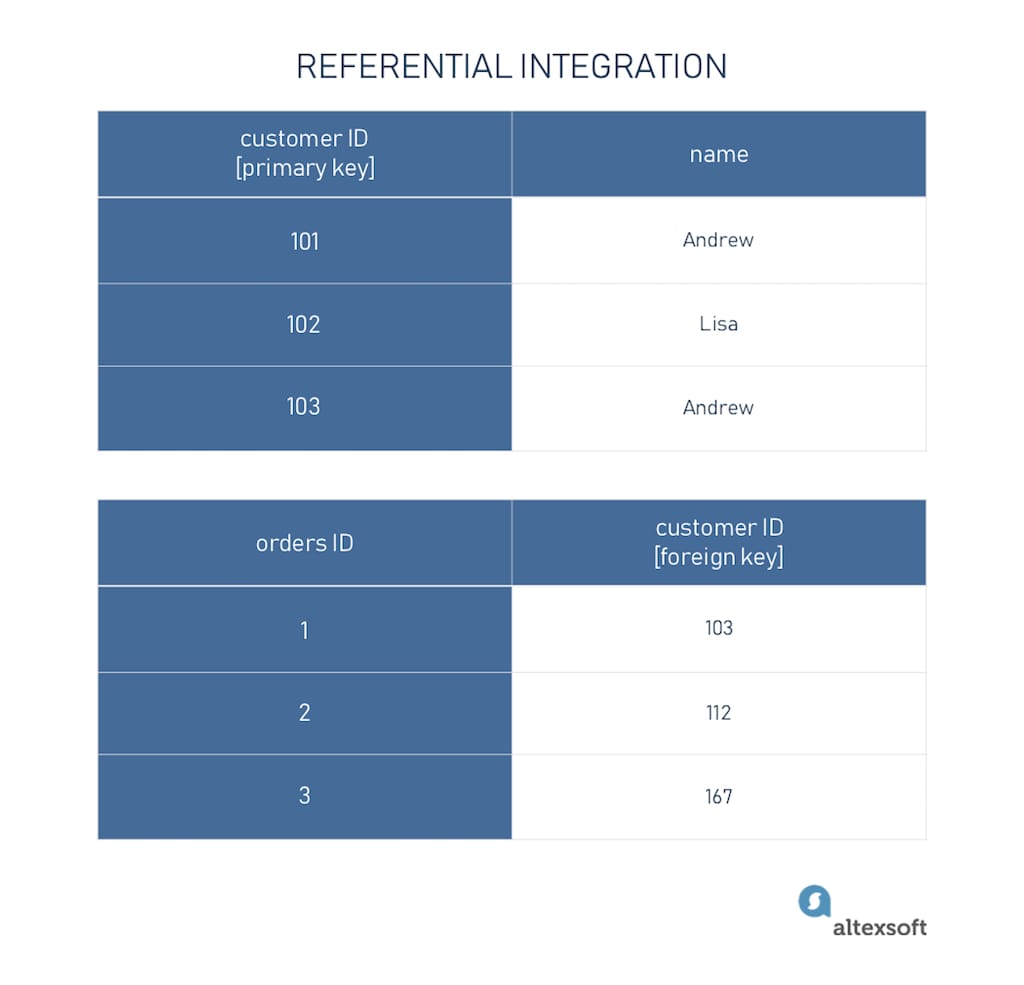
Example of referential data integrity
Domain integrity sets up the format and quantity of variables that populate the tables. For example, if we have a column with phone numbers, we can create a rule of domain integrity to have all the inputs starting with the plus, followed by the country code, and containing a specific number of digits.
User-defined integrity serves all the other possible purposes and individual rules that cover companies’ needs. For example, banking systems could set up a rule to complement customers’ names in the table with the postcode of the city where they have issued their accounts.
Why is it so difficult to get data integrity right?
Integrity is essential in working with data, but there are some difficulties in achieving it. Let’s mention the most common ones.
Insufficient employee training. Unawareness of personnel leads to potential high levels of human errors when working with data and general misunderstandings of consequences.
Lack of corporate data culture. Absence of the main company’s vector regarding data integrity means that not only personnel but also top management do not respect data hygiene. This leads to a variety of problems, from biased decision making to regulator penalties.
Inadequate technical processes. Organizations must introduce protocols and rules across the entire data lifecycle. Neglecting them can compromise integrity as well..
Business and performance pressure. Work overload may entail that employees interacting with data have no spare time and pay little attention to perform all processes correctly.
Outsourcing and contracting. When dealing with third parties, it's difficult to supervise all the data related processes and ensure quality.
That said, there are several stragies to mitigate these challenges and address data integrity threats.
Data integrity threats and countermeasures
Before starting with actual threats and how to mitigate them, we must understand the consequences a company can face if data integrity is compromised. Well, first of all, the reliability of data itself. Weak standards of data integrity can't ensure quality data-driven decisions and can’t enable strategic data insights.
Then there are regulatory consequences if your data undergoes inspections by authorities. it may result in suspension of product approval and other measures that interrupt normal business activities. The next level for serious data integrity violations may threaten product bans and heavy charges. And finally, in such critical fields as healthcare, data integrity failure can result in criminal enforcement for both employees and management.
Now let’s go through the main types of data integrity threats which include:
- human error,
- security threats, and
- hardware and software issues.
And also let’s point out countermeasures to maintain data integrity given each type of threat.
Human error
Human errors can be intentional and unintentional, and they occur at different stages of the data lifecycle, for instance, while collecting, inserting, or transferring data. Also, human errors include data duplication and data deletion. Let’s see which countermeasures a company can take to minimize the human error factor.
Training and educational materials
Start with employees. It’s a good practice to provide workers with learning materials and data integrity training, updating measures each time there are changes in the policy or new compliances to follow. Emphasize the importance and highlight the possible consequences regarding data integrity. Create clean, step-by-step instructions for different employees, and make those materials easy to access at the workplace. For instance, you can set up a knowledge base dedicated to integrity practices.
Protocols
Protocols standartize the actions with data. A company should create as many as needed to establish an accurate working process. We recommend composing and following at least three of them: data validation, data transfer, entity and referential integration.
A data validation protocol is a strict policy on how to verify that inserted information is accurate and correct with rules about how the data should be collected, stored, and processed throughout the data lifecycle.
A data transfer protocol regulates how exactly the information can be sent from one device, server, or cloud to another, including security and authentication measures. The data transfer policy ensures that the sent data is complete.
Entity integration and referential integration refer to logical data integration. Each employee working with data inputs should apply primary key and foreign key principles to datasets. Logical data integration ensures basic integrity requirements for all the data.
Automation and audit trails
Check for errors automatically and keep track of all the changes. The goal of the audit is to verify if the system contains human errors. There are many possible ways to do that. You can purchase error detecting software such as Nakisa and Precisely, write custom scripts, or use RPA (robotic process automation) bots to verify data. We recommend creating a strict auditing schedule and performing it regularly.
Keeping an audit trail allows tracking down the source of data modifications. Audit trails electronically record any action related to data such as adding, changing, or deleting along with the attached employee name and time of the action.
In short, automation protects datasets from human-made mistakes while an audit trail helps to record who made the mistake and when.
Backup and recovery
Always back up your data. For various reasons, data can be modified, erased, or not accessible. Backup plans and recovery measures minimize the threat and prevent irreversible changes to datasets. When planning a backup, specify where the data will be stored as it can rest on an internal server, cloud, hardware, or even as a physical copy. Also specify how often your IT staff must back up data, in which formats, and which security measures will protect the data at rest.
Security threats
Security threats include potential attacks and malicious events such as hacking, data leaks, viruses, and bugs. Some measures mentioned in the previous block and some that will be described in the following one are relevant for security insurance as well. For example, creating backups and various protocols helps minimize security threats.
Levels of access
Different levels of access to datasets are meant to protect data from unauthorized usage and also ensure data privacy. The best practice in role assignment is to fulfill that minimum of information access that an employee needs to perform tasks. Basically, the less data available to each role, the better.
When giving access to data, require strong passwords with implemented two-factor authentication (2FA), which requires a user to submit at least two pieces of identification such as something a person knows (password), something a person has (smartphone), and something of the physical person (fingerprint).
And finally, be sure to secure physical sources of data as well. For example, if employees print some valuable or sensitive datasheet, provide a clear policy on what to do with the copy. Depending on possibilities, physical data copies can be destroyed, or stored in vaults, safes, and offices of authorized personnel. Access to physical data should be controlled by filling or signing special forms, video surveillance, and so on.
Encryption
Encryption is one of the fundamental methods of data protection. Encrypt the data in rest, in archives and backups, and information that is about to be transferred to any environment during data migration. Encryption is also a tool for masking unnecessary data from unauthorized personnel.
Security architecture
The whole of security architecture should protect data during its lifecycle across all environments. First of all, apply such minimum measures as antivirus software to detect intrusions, and install a firewall to isolate networks.
Then, secure the internet connection and reduce network vulnerability. You can achieve that with changing the wireless network’s default name, checking that the device does not auto-connect to Wi-Fi, using encryption, and strong passwording.
There are some general recommendations to follow. In communication with an IT department, create a guide on security measures, make a schedule of security checks, and perform them frequently. When it comes to other personnel, provide training about ransomware and phishing emails in order to protect the system as much as possible.
Hardware and software issues
Hardware and software issues can compromise data, when you store, process, or transfer it. Hardware problems mostly relate to physical integrity. Software malfunctioning usually leads to unupdated and unsecure systems.
Physical integration
Physical integration ensures that data is stored properly on the hardware and can be easily accessible when needed. Physical integration is achieved by taking care of hardware that functions well in normal conditions by protecting it from damage and fatigue, and also in cases of extreme situations like natural disasters.
Updates and checks
To provide optimal and reliable software functioning, keep it up to date, and regularly check error logs. It’s hardly possible to detect all vulnerabilities manually. This is why it’s essential to understand the vulnerabilities that have been located and to update the software as soon as new versions and patches become available. Updates and checks help businesses take care of potential threats quickly and effectively.
Configuration management
Configuration management means sustaining both hardware and software systems and certifying that they function optimally.
It focuses on configuring operating systems, devices, networks, and assets, ensuring that they are well protected. Also configuration management helps keep track of configuration changes across different systems, and by doing so prevents device outages, security breaches, and information leakage. Configuration management can both manual and automated.
Final recommendations
Data integrity is not a task but a process to be constantly performed. Here are some extra tips.
Assign employees. Select people responsible for each data task and keep track of their performance. These employees don’t have to be from the IT department only. Any person in contact with data can take charge.
Provide schedules. Create specific schedules for security procedures and operations with data.
Keep track of compliance. Constantly check for new regulations and laws in your industry to update your policies.