

The pace of data being created is mind-blowing. For example, Amazon receives more than 66,000 orders per hour with each order containing valuable pieces of information for analytics. Yet, dealing with continuously growing volumes of data isn’t the only challenge businesses encounter on the way to better, faster decision-making. Information often resides across countless distributed data sources, ending up in data silos. To get a single unified view of all information, companies opt for data integration.
In this article, you will learn what data integration is in general, key approaches and strategies to integrate siloed data, tools to consider, and more.
What is data integration and why is it important?
Data integration is the process of taking data from multiple, disparate internal and external sources and putting it in a single location (e.g., a data warehouse) to achieve a unified view of collected data.
So, why does anyone need to integrate data in the first place?
Today, companies want their business decisions to be driven by data. But here’s the thing — information required for business intelligence (BI) and analytics processes often lives in a range of databases and applications. These systems can be hosted on-premises, in the cloud, and on IoT devices, etc. Logically, each system stores information differently: in structured, unstructured, and semi-structured formats. With the right data integration strategy, companies can consolidate the needed data into a single place and ensure its integrity and quality for better and more reliable insights.
Let’s imagine you run an eCommerce business and you want to build a predictive propensity model to calculate customer lifetime value. For this purpose, you will need a range of customer data. The problem is, the information you have is scattered across different systems isolated from one another including
- CRM with customer and sales data,
- POS with customer purchase history, and
- Google Analytics with website traffic and user flow analytics data, to name a few.
So, each of these systems contains information related to the specific operations of the company. You need all this data, some fragments of which are locked in silos in separate databases only certain groups of people have access to. This is something known as the “data silo problem,” meaning no team or department has a unified view of data. And without it, you will not be able to build accurate predictions.
Disappointing, isn’t it?
Luckily, integration comes to the rescue as it allows for extracting all valuable information and creating a 360-degree customer view. And that’s exactly what you need for your project.
How does data integration work?
The one-size-fits-all approach to data integration doesn’t exist. At the same time, there are a few typical elements involved in an integration process. They are a set of disconnected data sources, clients, and a master server that provides a unified viewpoint on all data.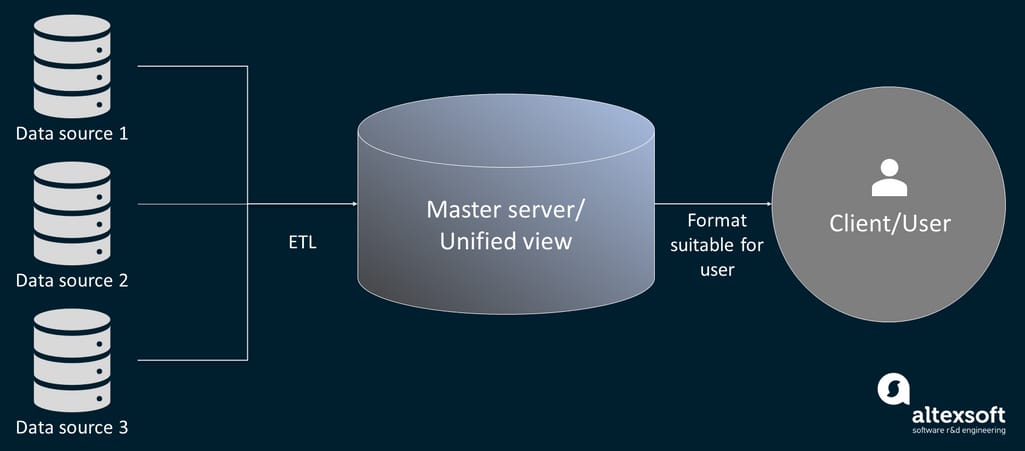
Data integration process
The common case involves the client sending a data request to the master server. The server then pulls out the requested data from internal and external sources and unifies it into a cohesive view, which is eventually delivered back to the client.
An important part of data integration is the ETL process that consists of the extract, transform, and load steps. With it, data is retrieved from its sources, migrated to a staging data repository where it undergoes cleaning and conversion to be further loaded into a target source (commonly data warehouses or data marts).
A newer way to integrate data into a centralized location is ELT. Consisting of the same steps as in ETL, ELT changes the sequence — it first extracts raw data from sources and loads it into a target source, where transformation happens as and when required. The target system for ELT is usually a data lake or cloud data warehouse.
Key types of data integration
Organizations have different requirements and needs regarding data integrity. For this reason, there are various types of data integration. The key ones are data consolidation, data virtualization, and data replication. These types define the underlying principles of integrating data. Let’s review them in more detail.
Data consolidation
Because data consolidation is the classic data integration process leveraging ETL technology, the two terms are sometimes used interchangeably. It involves combining data from disparate sources, removing its redundancies, cleaning up any errors, and aggregating it within a single data store like a data warehouse. Although complex, it fits the majority of cases. The delivery style to consolidate data is common data storage we’re covering below.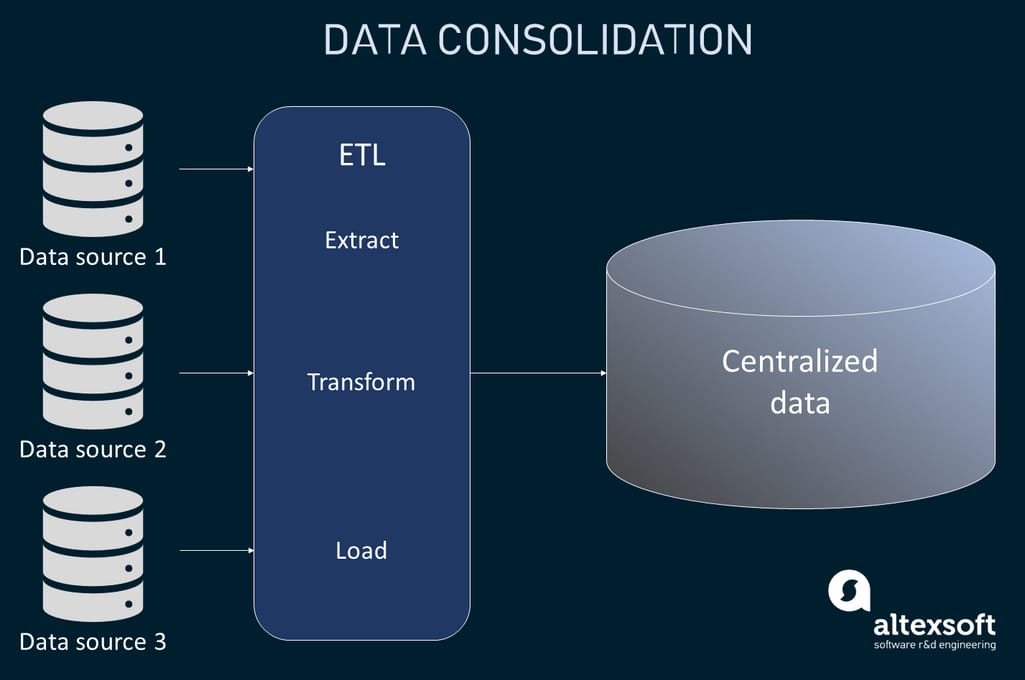
How data consolidation works
The main idea of data consolidation is to provide end users with all critical data in one place for the most detailed reporting and analysis possible.
When it is a good option: Organizations that need to cut down the number of systems where data is stored and standardize their data.
The flip side: The consolidation approach may be expensive if you deal with large volumes of data.
Data virtualization
Data virtualization is the process that brings data from multiple sources together in a virtual data layer. That said, you don’t move and transform the data via ETL: Physically it remains in original databases. Instead, you create integrated virtual (logical) views of all required data to access and query it on demand. Data virtualization can be approached through data federation — a process involving the creation of a virtual database that doesn’t contain the data but knows the paths to where it actually is.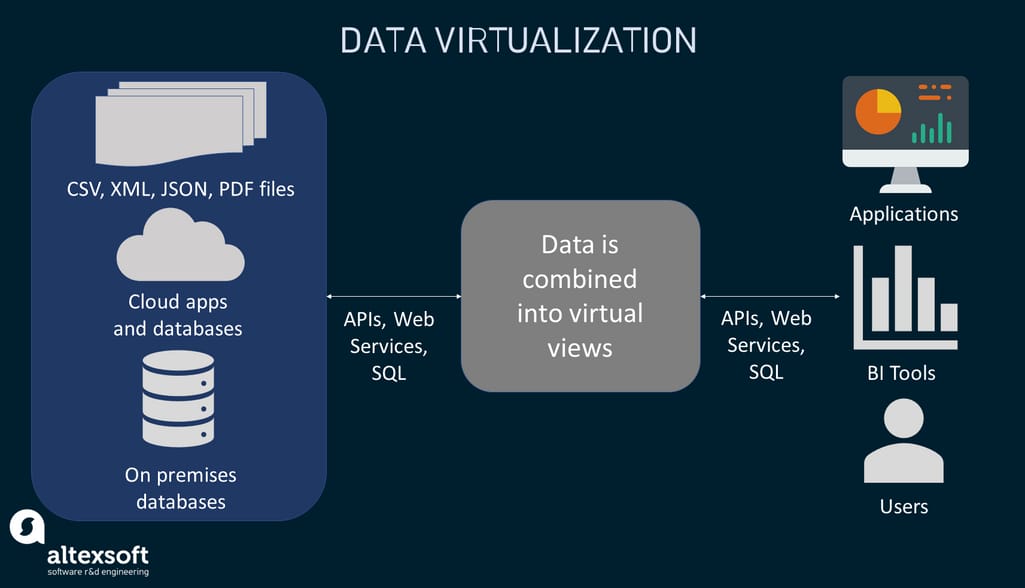
How data virtualization works
When a user makes a query, the virtualization layer reaches out to the source systems and creates a unified view of queried data on the go. This can be performed through multiple mechanisms including APIs.
When it is a good option: Virtualization is the way to go for companies that need data available for analytics and processing in real time. Multiple users from different locations can get access to data at the same time.
The flip side: Such systems can be difficult to set up.
Data replication
Data replication, as the name suggests, is the integration process of copying and pasting subsets of data from one system to another. Basically, data still lives at all original sources; you just create its replica inside the destination locations.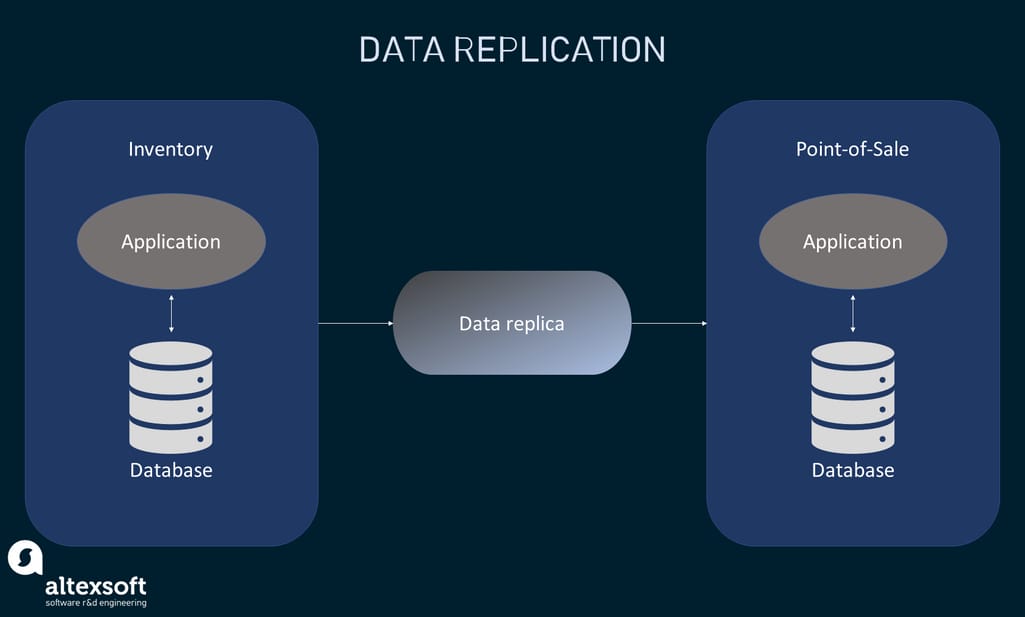
Inventory data is replicated to the point-of-sale database
The approach is often used when you need to augment data in one system with information from another. Say, a sales department works with a point of sale (POS) system. But they need some data entities stored in an inventory database. So, instead of using multiple applications duplicating data entries, a sales team can use their primary system with a replica of data from the inventory system.
You can replicate data in three ways:
- full table replication — copying all the new, updated, and existing data from the sources to the destination;
- key-based incremental replication — copying only data that has changed since the previous update; and
- log-based incremental replication — copying data based on the changes in the log files of source systems.
When it is a good option: Organizations with fewer data sources and different departments that need faster access to the same data.
The flip side: When it comes to a big number of different data locations, it may be costly and resource-intensive to keep information duplicates.
Strategic methods to integrate data
Given these three key types of data integration, there are different strategies to bring the above-mentioned data integration types to life. To help you figure out which method makes the most sense for your business, we’ll cover them briefly in this section.
Manual data integration
Corresponding types: Data consolidation, data replication
Manual data integration, as the name suggests, is the method requiring dedicated specialists to do integration jobs manually, often through hand-coding. Every single process from searching for particular data entities, to converting them into a suitable format, to loading and presenting them within the right system is done by hand.
For example, there isn't much data you operate with: You maintain your reporting in Excel spreadsheets, store some data in a CRM, and also use a BI tool. In such a case, you can delegate integration work to a data engineer who will manually upload data into, say, a CSV file and move it to a BI system. This person will code the right data connectors for each system, clean the data, and transfer it when and where needed.
Pros and cons: The technique works well when there are a few data sources or when there are no available tools to support your data integration initiative. On the other hand, manual integration and hand-coding are often prone to error and time-consuming. Also, you will not be able to make use of your current data in real time. Not to mention that if any changes occur within your data integration strategy, you need to rebuild the whole system.
When to use it: Manual data integration can be considered as an option by companies that already have or are willing to hire data engineering or data management staff to obtain complete control over data integration.


Learn more on how data engineering works from our video
Middleware data integration
Corresponding types: Data consolidation, data virtualization, data replication
Another approach to data integration entails using middleware that acts as a bridge between different applications, systems, and databases. Partially automated, this method helps with data transformation and validation before it is moved to the target location.
For example, you have a couple of legacy data systems and no tools available to integrate them with a newer BI system. Your data engineer configures middleware and data connections. When requested, the script would search for data, transform it, and upload it into a new system in a form appropriate for analytics.
Pros and cons: Efficient middleware enables better communication between disparate systems as data is transformed and transferred consistently. At the same time, not all systems can be connected with the help of middleware. Plus, its installation and maintenance require a skilled developer.
When to use it: As mentioned above, middleware data integration is mostly used when you need to connect legacy systems with newer ones. With this method, it is possible to transform data and make it compatible with a format suitable for more modern applications.
Application-based integration
Corresponding types: Data consolidation, data virtualization, data replication
This method suggests that software applications automatically do all the integration work. The software pulls data out of sources, converts it, and transmits it into the desired destination. This often involves the use of open-source tools and pre-configured connections to different data sources. You can also add new systems when required. This approach entails full automation of processes: Scripts can run integration jobs within a schedule.
Pros and cons: There’s seamless information transfer between different systems and departments. While automation simplifies data integration processes, you still need technical expertise on-site in the case of on-premise software.
When to use it: The method may be attractive for businesses working in hybrid cloud environments, meaning they make use of internal (private cloud) and external (public cloud) services.
Uniform data access integration
Corresponding type: Data virtualization
The uniform data access integration method defines a set of views for data in a virtual dashboard after connecting the sources. Multiple users from different locations can query and analyze data while it remains physically in original sources.
Say you have a few teams located in different places and you need to configure accessibility to certain data in the cut of individual departments. Uniform data access will allow you to keep data protected as it sits in sources while departments can reach the data they need and when they need it via a pre-configured uniform image.
Pros and cons: The ability to exchange information across the entire business in real time and present it uniformly allows for nearly zero latency. Also, there’s no need to build a separate repository for integrated data. However, the approach can only be applied to similar data sources, e.g., databases of the same type. Systems hosting data may not be able to handle too many requests in this process.
When to use it: The approach could work well for companies that drive insights from multiple disparate data sources and want to save costs on creating separate storage for a copy of that data.
Common storage integration
Corresponding type: Data consolidation
Common data storage is one of the most advanced delivery styles for data consolidation. Within this method, a new data system is created to store, process, and display a copy of selected data from various systems in a unified view to users. That’s why it is sometimes referred to as "data warehousing." Common data storage allows for accessing and managing data right away without dependency on source systems.
Pros and cons: Keeping data in one source allows for better data integrity, meaning data is more accurate and consistent. Due to this, users can run more complex queries and perform better analytics. Of course, common data storage comes with its drawbacks that mainly relate to higher costs both for storage and maintenance.
When to use it: Companies that are ready to handle high associated costs for the good of flexible data management and sophisticated data analysis tasks.
Data integration tools and how to choose them
Integrating data sources is beneficial in lots of ways but it won’t happen magically all by itself. You will most likely need the help of data engineers, ETL developers, or other specialists involved in building data pipelines. Also, you are unlikely to do without a suitable data integration tool or platform.
Types of data integration tools
The choice of a tool largely depends on where information is stored and where you are planning to deploy your data model. That's why data integration software solutions are often categorized as on-premises, cloud, and open-source ones.
Side note: We are not promoting any data integration vendors and tools. Those mentioned in the lists are just examples for a general understanding of the market. Please do your research and ask for a demo before deciding on a tool.
On-premise tools are used to build and maintain data integration on site — in a local network or private cloud. In this case, data comes from different on-premise data sources (e.g., legacy databases) and is often loaded in batches via enhanced native connectors.
Some examples of tools for on-premise data integration strategies are
Cloud-based tools are largely presented as integration platforms as services or iPaaS. Operating in the cloud but not exclusively, these are a set of automated tools that help integrate different software and data it holds. With iPaaS, for example, you can integrate streaming data from a bunch of web-based systems into a cloud-based data warehouse. By providing infrastructure on a sort of rental basis, iPaaS solutions allow companies to cut costs and eliminate the necessity to do all the integration work by themselves. Also, it is a good way to configure integrations quickly via APIs and Webhooks, etc.
Some examples of tools for cloud-based data integration strategies are
Open-source tools allow companies to develop and deploy data integration projects in-house much faster than hand-coding. Not only do they provide full control over data internally but also eliminate the need to pay for expensive proprietary solutions. Such tools are equipped with different capabilities like ETL and ELT, data flow orchestration, and file management, to name a few. Of course, to make use of these tools, there should be some level of data integration expertise inside a company.
Some examples of tools for open-source data integration strategies are
Things to consider when choosing a tool
While most data integration tools follow the same idea, choosing one should have a foundation. Consequently, there are a few considerations to take into account to make an informed choice.
Data sources. First things first, you have to determine which and how many sources containing data to be integrated you have in place.
That said, you may have a couple of internal SQL databases and that’s it. Chances are, you can do without any tools at all by performing integration manually or opt for some primitive on-premise solution.
It's a whole different story when you deal with a large number of both internal and external sources of diverse types, including overlapping systems like several CRMs. In this case, you may need advanced cloud integration software that offers automation.
One more thing to consider is the frequency of data updates. Do you need data to be processed in batches or in real time? If you are fine with your data being integrated periodically, simpler tools with basic functionality will work. Data streaming, on the other hand, will require more powerful cloud solutions and more storage.
Data formats. The sources may contain different data — structured, unstructured, semi-structured, or a combination of all. So, the tool you’re about to choose must support the required data format.
If your operations rely only on structured data that lives in relational databases and is organized in a column-row form, you will likely integrate it in a data warehouse or data mart via an ETL tool. In case you deal with diverse data formats like images, PDF files, emails, etc., and there’s a lot of it, you may need to keep it raw. So, ELT-capable tools will do the job of extracting data and consolidating it in a cloud data warehouse or data lake.
Available resources. Another important aspect in the list of considerations is whether or not your company has all the needed resources, knowledge, and skills to use the tools. Some data integration solutions require deep technical background while others can be easily handled by non-tech personnel.
Data integration best practices
There is no one-size-fits-all formula to implement data integration but there are a couple of things to keep in mind while mapping out your integration strategy.
Set clear and achievable business objectives
It is a good practice to get started with clearly defined project objectives. Does a company want to adopt new technologies and modernize its legacy system? Is the end goal to streamline business operations?
If planned out and done right, data integration projects can bring evident results. So, it’s important to set clear expectations upfront and decide on how to measure success.
Opt for simplicity
Data integration is a complex, multifaceted process. If there’s anything you can do to minimize complexities, quoting Shia LaBeouf’s motivational speech, “Do it!” For this reason, it’s better to opt for tools that offer automation of some kind.
Assign roles and responsibilities
Depending on the complexity of the project and the tools you are planning to use, you may need different specialists to be on your data integration team. Besides, when every person knows their role and responsibilities top to bottom, you end up with better work coordination and effectiveness.
Be future-oriented
It’s worth remembering that data integration isn’t something done and forgotten. Technologies keep advancing by leaps and bounds. New data sources become available. Integration solutions must be able to keep up with the times and adjust to changes. If not, they quickly become outdated and ineffective. So, when planning your data integration projects, make sure they are agile enough to effectively meet the future.