

When people hear about artificial intelligence, deep learning, and machine learning, many think of movie-like robots that resemble or even outperform human intelligence. Others believe that such machines simply consume information and learn from it by themselves. Well... It's kind of far from the truth. Computer systems have limited capabilities without human guidance, and data labeling is the way to teach them to become "smart."
In this article, you will find out what data labeling is, how it works, data labeling types, and the best practices to follow to make this process smooth as glass.
Data labeling can be costly and slow at scale. In these cases, self-supervised learning lets models learn directly from unlabeled data. Read our dedicated article to learn more.
What is data labeling?
Data labeling (sometimes referred to as data annotation) is the process of adding metadata, or tags, to raw data to show a machine learning model the target attributes — answers — it is expected to predict. A label or a tag is a descriptive element that tells a model what an individual data piece is so it can learn by example. Say the model needs to predict music genre. In this case, the training dataset will consist of multiple songs with labels showing genres like pop, jazz, rock, etc.
In this way, labeled data underlines data features (characteristics) to help the model analyze information and identify the patterns within historical data to make accurate predictions on new, relevantly similar inputs.
The process of labeling objects in a picture via the LabelImg graphical image annotation tool. Source: GitHub
The process of labeling data is one of the essential stages in preparing data for supervised machine learning workflows.
More on how data is preprocessed for machine learning can be found in our dedicated video and/or article on preparing a dataset for ML.


How is data prepared for machine learning?
So, what challenges does data labeling involve?
Data labeling challenges
High cost in terms of time and effort. Not only is it hard to get lots of data (particularly for highly specialized niches such as healthcare), but manually adding tags for each item of data is also a difficult, time-consuming task requiring the work of human labelers. Within the full cycle of ML development, data preparation (including labeling) takes up almost 80 percent of the project time.
Need for domain expertise. You may need to hire domain experts to add metadata. For example, if you are about to build an ML model capable of recognizing tumors on X-Ray scans, unprepared annotators will unlikely do that correctly.
Risk of inconsistency. In most cases, cross-labeling — when several people label the same sets of data — leads to higher accuracy. But as people often have different levels of expertise, labeling criteria and labels themselves may be inconsistent, which is another challenge on the list. There might be disagreement on some tags between two or more annotators. For instance, one expert may score a hotel review as positive while the other may see it as sarcastic and give it a negative label.
Error proneness. No matter how experienced and attentive your labelers are, manual tagging is prone to human error. This is unavoidable because annotators usually deal with large sets of raw data. Imagine a person marking 150,000 pictures with up to 10 objects each!
And yet, with all these shortcomings, data labeling is still the cornerstone of most machine learning projects. So, let’s deal with how this process happens.
Data labeling approaches
There are different ways to perform data annotation. The choice of the style depends on the complexity of the problem statement, the amount of data to be tagged, the size of a data science team, and, of course, your financial resources and available time. We’re going to quickly review each approach here. But you can go back to the dedicated article on how to organize data labeling for your machine learning project to dive deeper.
In-house data labeling. As the name suggests, in-house data labeling is carried out by specialists within an organization. It's the way to go when you have enough time, human and financial resources, and it provides the highest possible labeling accuracy. On the flip side, it is slow.
Crowdsourcing. There are special crowdsourcing platforms, like Amazon Mechanical Turk (MTurk), where you can sign in as a requester and assign different labeling tasks to available contractors. Affordable and relatively fast, the approach can’t guarantee high quality of annotated data.
Outsourcing. Another way to get things done is to outsource data labeling jobs to freelancers that can be found on multiple recruitment and freelance platforms like Upwork. Similar to the previous approach, outsourcing is a quick way to obtain data labeling services but the quality may sink.
Automatic data labeling. Apart from being performed manually, the process can be assisted by software. Tags can be identified and added to the training dataset automatically with the help of the technique known as active learning. Basically, human experts create an AI Auto-label model that marks raw, unlabeled data. After that, they identify whether the model has done the labeling correctly. In the case of failure, human labelers correct the errors and re-train the model.
Synthetic data development. Synthetic data is an artificially generated dataset with labels that comes as an alternative to real-world data. It is created by computer simulations or algorithms and is often used to train machine learning models. In the context of labeling approaches, synthetic data is a great solution to the problems of data shortage and diversity. The solution is the production of artificial data from scratch. Dataset developers create 3D environments with objects and surroundings the model will need to recognize. It is possible to render as much synthetic data as needed for the project.
How data labeling works
Whatever the approach, the process of data labeling works in the following chronological order.
Data collection. The starting point of any ML project is collecting the right amount of raw data (images, audio files, videos, texts, etc.) Sources may differ from one company to another. Some organizations have been accumulating information internally for years. Others use publicly available datasets. Either way, this data is often inconsistent, corrupted, or simply unsuitable for the case. So, it needs to undergo cleaning and preprocessing before any labels are created. As a rule, there should be a large amount of diverse data for a model to provide more accurate results.
Data annotation. Here comes the heart and soul of the process. Specialists go through the data and add metadata labels to it. In this way, they attach meaningful context that the model can use as ground truth — target variables you want your model to predict. These can be, for example, tags in images describing the depicted objects.
Quality assurance. Data must be high quality, reliable, accurate, and consistent. The quality in datasets for ML model training is determined by how precisely the labels are added to a particular data point. To ensure the accuracy of metadata and optimize it when needed, there must be continuous QA checks in place.
For this purpose, labelers often use such QA algorithms as
- the Consensus Algorithm — data reliability is achieved through agreement on a single data point among different systems or individuals — and
- the Cronbach’s alpha test — the average consistency of data items in a set is measured.
An often overlooked stage of data labeling, quality assurance contributes greatly to the accuracy of the results.
Model training and testing. A logical follow-up to the previous stages is the use of labeled data containing the correct answers to train the model. The process typically involves testing the model on an unlabeled data set to see if it delivers the expected predictions or estimations. Based on the use case, you will decide on confidence scores or accuracy levels. Say, the model is considered to be successfully trained if the accuracy is 96 percent and higher, meaning it makes 960 good predictions out of 1000 examples.
With the basics explained, let’s move on to reviewing typical data labeling types for each AI domain, namely
- image and video labeling,
- text labeling, and
- audio labeling.
Image and video labeling for computer vision tasks
Computer vision (CV) is a subset of artificial intelligence (AI) that enables machines to “see.” While it sounds too futuristic, the ability of computers to see basically means that they can derive meaningful information from visual inputs like digital images, simulating human visual perception. To make that happen, computers need
- image annotation — the process of assigning tags to images and
- video annotation — the process of adding labels to video frames (still images extracted from video footage).
Based on the CV task, workers may use different types of image/video annotation.
Image classification
The essential CV task, image classification is the process of attaching one label (single-label classification) or several labels (multi-label classification) to an image itself based on what class the depicted object belongs to. Whether there is a cat or two cats in the picture, it will be labeled as the “cat.” The same goes for video clip classification.
Image classification example
Bounding boxes
The most common way to annotate images, bounding boxes are rectangular or square boxes that are drawn around objects to show their location in the image. The boxes are identified by the x and y-axis coordinates in the upper left and lower right corners of the rectangle.
Bounding boxes are mainly used in object detection and classification with localization tasks.
- Object detection deals with detecting and classifying multiple objects in an image or a video frame along with showing the positions of each one with bounding boxes.
- Image classification with localization means classifying images into a few predefined classes based on the objects depicted and drawing boxes around those objects. Unlike object detection, this approach is commonly used to define the location of a single object or several objects as one entity (see the picture below).

Image classification with localization vs object detection
Polygon annotation
Polygon annotation uses closed polygonal chains to determine the location and shape of objects. Since non-rectangular shapes (like a bike) are more common for real-world environments, polygons are a more suitable image annotation variant than bounding boxes.
Bike annotated with the help of a polygon. Source: COCO dataset
With polygons, data annotators can take more lines and angles in work and change the directions of verticals to show the object's true shape more accurately.
Semantic segmentation
Semantic segmentation is an annotation approach used to assign a label to specific pixels of an image that belong to a corresponding class of what is shown. Annotators would draw polygons around a set of pixels they want to tag and group those of the same class as one entity, separating them from the background and other objects. For example, in the picture below, all sheep are segmented as one object while road and grass make the other two objects.
Differences between image classification, object detection, semantic segmentation, and instance segmentation. Source: Medium
A similar approach is instance segmentation but it differentiates multiple objects of the same class and treats them as individual instances. For example, each sheep in the image is segmented as an individual object in addition to road and grass.
3D cuboids

The example of 3D cuboid annotation. Source: Cogito Tech
3D cuboids are 3D representations of objects, meaning they depict not only the length and width of each object but also its depth. In this way, annotators can show the volume feature in addition to the position. If the edges of the object are hidden from view or blocked by other objects, annotators will define them approximately.
Key-point annotation
Key-point annotation involves adding dots across the image and connecting them by edges. At the output, you get the x and y-axis coordinates of key points that are numbered in a certain order. The approach is used to identify small objects and shape variations that have the same structure (e.g., facial expressions and features, human body parts and poses).

An example of key-point annotation of a video clip. Source: Keymakr
Key-point annotation is commonly used for labeling video frames.
Image and video labeling use cases
Both video and image annotation sees a wide array of practical applications in different areas.
- In healthcare, you can label disease symptoms in an X-ray, MRI, and CT scan as well as in microscopic images for diagnostic analysis and disease detection (for instance, detecting cancer cells at early stages).
- In logistics and transportation, you can label barcodes, QR codes, and other identification codes to track goods and enable smart logistics.
- In the automotive industry, you can segment vehicles, roads, buildings, pedestrians, cyclists, and other objects in images and videos to help autonomous cars distinguish these entities and avoid contact with them in real life.
- In cybersecurity, you can annotate facial features and emotions to help AI systems identify individuals in images and security video footage.
Text labeling for natural language processing tasks
Natural language processing or NLP is a subset of artificial intelligence that enables machines to interpret human language. NLP uses the power of linguistics, statistics, and machine learning to study the structure and rules of language and create smart systems that can derive meaning from text and speech. The algorithms can analyze various linguistic aspects such as semantics, syntax, pragmatics, and morphology and then apply this knowledge to perform desired tasks.
Here are a few popular ways to annotate the text for NLP tasks.
Text classification
Text classification (also referred to as text categorization or text tagging) is a process of assigning one or several labels to the text blocks as a whole to classify them based on predefined categories, trends, subjects, or other parameters.
Sentiment annotation is used for sentiment analysis, which is the process of understanding whether a given text delivers a positive, negative, or neutral message. For example:
“Customer service was top notch.” → Positive message
“ They won’t respond to requests on the app and put me on hold for 30 mins.” → Negative message
“The new design of the website is generally fine.” → Neutral message
Speaking of sentiment analysis, AltexSoft has built an ML-powered model capable of scoring hotel amenities based on customer reviews. It was an interesting journey we’d like to share with you.
Topic categorization is the task of identifying the topic a piece of text conveys. Annotation involves adding theme labels such as Pricing or Ease of Use when analyzing customer reviews, for example.
Language categorization is the task of detecting the language of a text. Annotation involves adding corresponding language labels to texts based on the language they are written in.
Entity annotation
Entity annotation is the act of detecting, locating, and tagging some fundamental entities inside each line of the unlabeled text. Unlike text classification, entity annotation deals with labeling individual words and phrases.
There are several types of entity annotation such as named entity recognition, keyphrase tagging, and Part-of-Speech tagging.
Named entity recognition extracts, chunks, and identifies entities and annotates them with proper names. The most common categories include names of people, products, organizations, locations, dates, and times, etc.
An example of how the sentence is annotated by named entities. Source: Towards Data Science
Let’s imagine you are building an ML model designed to trade stocks depending on the events in the news. The algorithm goes through data and comes across the headline that looks like this:
News headline from the Financial Express resource
While a human can easily understand the context, the machine won’t be able to tell if the word “Tesla'” refers to a company name, an item of a Tesla vehicle, or … you never know … Nicola Tesla. Named entity annotation does this job for a machine and explains the right meaning.
Keyphrase or keyword extraction and tagging. In addition to annotating named entities, labelers may also tag keyphrases or keywords in the text. This type of text labeling can be used to summarize documents/paragraphs or index a corpus of texts. The procedure requires a thorough examination of each text block to extract the most meaningful keywords.
Part-of-Speech or POS tagging. This approach involves annotating all the words within a sentence according to their parts of speech. The labels will include nouns, verbs, prepositions, adjectives, etc.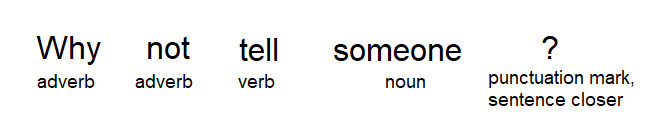
POS tagging example. Source: Towards Data Science
It is used for identifying relationships between words in a sentence and drawing out meanings. With proper POS tagging, algorithms can determine the exact representation of similar words in different situations and as such provide more accurate results.
Entity linking
Entity linking is the process of labeling certain entities in text and connecting them to larger repositories of data. Basically, that’s when tagged entities are linked to URLs with sentences, phrases, and facts offering more information about them. The procedure is especially important for cases when the corpus of text contains data that can be interpreted in multiple ways.
Text labeling use cases
There are many interesting applications for text annotation and NLP processes, namely
- tagging messages as spam and ham (non-spam) for spam detection,
- explaining text meaning and word relationships for machine translation,
- classifying documents,
- designing conversations for chatbots, and
- extracting consumer feelings and opinions from reviews for sentiment analysis.
Audio labeling for speech recognition tasks
Speech recognition is a subfield of artificial intelligence that enables machines to understand voice narration by identifying spoken words and converting them into text. While audio information is clear to humans, computing machinery can't understand its semantic structure as effortlessly. To deal with this issue, there is audio labeling -- when you assign labels and transcripts to audio recordings and put them in a format for a machine learning model to understand.
Speaker identification
Speaker identification is a process of adding labeled regions to audio streams and identifying the start and end timestamps for different speakers. Basically, you break the input audio file into segments and assign labels to parts with speaker voices. Often, segments with music, background noise, and silence are marked too.
Audio-transcription annotation
Annotation of linguistic data in audio files is a more complex process that requires adding tags for all surrounding sounds and transcripts for speech in addition to linguistic regions. Many audio and video annotation tools allow users to combine different inputs like audio and text into a single, straightforward audio-transcription interface.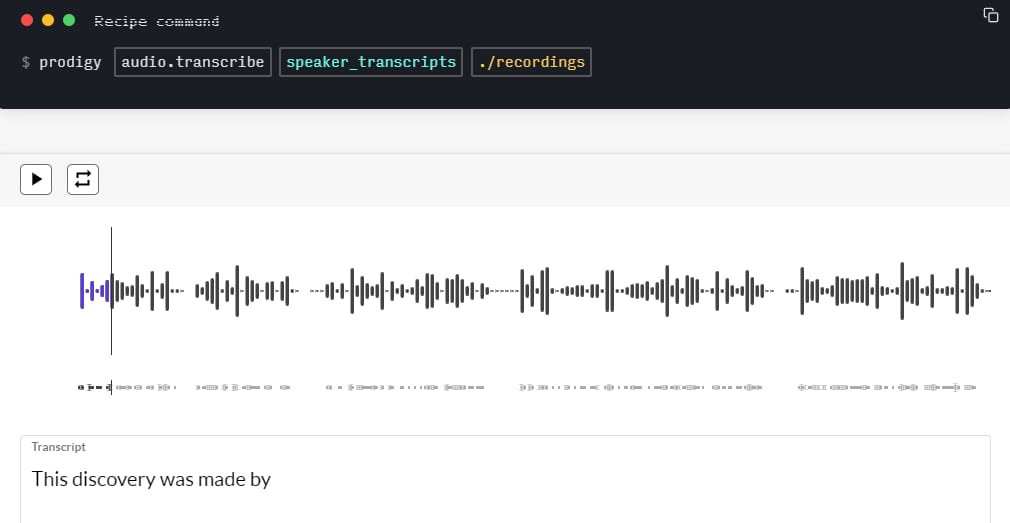
The process of audio annotation using the Prodigy tool
Once the spoken language is converted into a written form, previously discussed NLP tasks come into play.
Audio classification
Audio classification jobs require human annotators to listen to the audio recordings and classify them based on a series of predefined categories. The categories may describe the number or type of speakers, the intent, the spoken language or dialect, the background noise, or semantically related information.
Audio emotion annotation
Audio emotion annotation, as the name suggests, aims at identifying the speaker’s feelings such as happiness, sadness, anger, fear, and surprise, to name a few. This process is more accurate than textual sentiment analysis since audio streams provide a number of additional clues such as voice intensity, pitch, pitch jumps, or speech rate.
Audio labeling use cases
Since adding labels to audio and video files is a cornerstone of speech recognition, it finds use in
- developing voice assistants like Siri and Alexa,
- transcribing speech to text,
- providing the context of conversations for advanced chatbots,
- measuring customer satisfaction for support calls, and
- designing apps for language learning and pronunciation assessment, to name a few.
Best practices to nail data labeling
As you can see manual data labeling work isn’t a piece of cake. To overcome the challenges and make the most out of the process, there are some best practices you can follow.
Find quality raw data
The big step towards accurate results of your machine learning model is high raw data quality. Before any annotations are assigned, make sure that data is adequate for the task, properly cleaned, and balanced. That said, if you are building a model to classify images into those containing cats and dogs, unlabeled data must include both animals in equal proportion and without any noisy elements.
Find domain experts
Half the success of data labeling work is determined by the ability of annotators to understand the subject matter. It is always better to hire experts who know the industry in and out and will be able to tag data more accurately and faster.
Create an annotation handbook
Decide on your annotation techniques and criteria and round up all important points in a handbook. It may include thoroughly-explained instances of correct, incorrect, and edge tag examples.
QA test your datasets
Never underestimate the importance of QA testing. You should incorporate QA processes into your data labeling pipeline to make sure that labeling goes in accordance with set criteria and mistakes are corrected in a timely fashion.
Assign multiple annotators for cross-labeling
Whatever the annotation job, it is always better to have several (up to three) annotators cross-label the same data to validate the tags. Following this practice, you will be able to ensure higher accuracy of the results.