

If you've ever been to a bookstore, you’ve probably experienced the book-location dilemma. Say you're looking for Atlas Shrugged, and you know it’s a genre mix of science fiction, mystery, and romance. Now, which section will you go to to find it? The science fiction, the romance section?
The document classification problem relates to library, information, and computer sciences. It concerns the way we categorize items in databases and inventories. As today’s digital storages can serve large amounts of items, it becomes difficult to categorize them manually. So businesses employ machine learning (ML) and Artificial Intelligence (AI) technologies for classification tasks.
In this article, we’ll explore the essence of document classification, and study the main approaches to categorizing files based on their content. Namely, we’ll look at how rule-based systems and machine learning models work in this context. Additionally, we’ll explain how Natural Language Processing (NLP), Computer Vision, and Optical Character Recognition (OCR) are applied to document classification.
What is document classification?
Document classification is a process of assigning categories or classes to documents to make them easier to manage, search, filter, or analyze. A document in this case is an item of information that has content related to some specific category. Product photos, commentaries, invoices, document scans, and emails all can be considered documents. Document classification may be a part of a broader initiative called intelligent document processing (IDP). Read our separate article on that.
Generally, document classification tasks are divided into text and visual classifications.
Text classification concerns defining the type, genre, or theme of the text based on its content. Depending on the task, complex techniques like NLP can be used to analyze words and phrases in context and understand their semantics (meaning). For example, NLP is applied in sentiment analysis, where we define the emotion or opinion expressed in the text.
Visual classification focuses on a visual structure of documents, employing computer vision and image recognition technologies. Visuals can be represented by motion pictures or still images. Here, we analyze pixels that make up an image, identify the objects pictured, and classify them by their behavior or specific attributes.
Document classification real-life use cases
Document classification can address various business problems, and some of them are not that evident as classification tasks. Let’s analyze how classification can be implemented and which problems it may help to solve, using real-life examples.
Spam detection
Analyzing words in context, NLP-based classifiers can define spam phrases and count how often they occur in the text to tell if it’s a spam message.
Google’s Gmail spam detector, for instance, employs NLP to find junk messages and drop them into a corresponding folder. In 2015, Google also implemented a neural network that enhanced the NLP capabilities of their spam filter. Basically, neural networks are applied in case you need more sophisticated technology to detect less obvious spam.
Opinion classification and social listening
Businesses want to hear what their customers think about them. And one of the most effective ways is to apply sentiment analysis to classify commentaries and reviews on social media by their emotional nature.
Sentiment analysis is a narrow case of NLP-based systems that focuses on understanding the emotion, opinion, or attitude expressed through the text. They can extract words that have positive or negative connotations. That’s how we can analyze customer feedback or reactions to your products or services automatically.
For example, Gensler, a company that architects airports, implements sentiment analysis to classify feedback travelers place on social media. Opinion mining allows managers to make effective decisions, win contracts, and deliver better services.
Customer support ticket classification
Customer support agents usually deal with a large volume of requests during the day. An NLP-based system can be implemented for a ticket routing task in this case. Analyzing the text in the message, the system classifies it as “claims,” “refunds,” or “tech support” and sends it to the corresponding department.
Vtenext, a CRM provider, uses the Klondike system to analyze the content of a support ticket sent to their IT department. Based on the text provided, their system labels the ticket with a required category like “configuration” or “development.” This significantly improves the speed of ticket processing and partially automates the work of the IT department servicing their CRM.
Document scan classification
Working with paper-based records presents another challenge within document classification. First, we have to scan them and then extract written or typed text for further analysis. The technology required for these purposes must recognize text and its layout from images and scans, which facilitates turning paper documents into a digital format and then classifying them.
For instance, the healthcare industry still deals with paper documents. Digitizing medical reports and other records is one of the critical tasks for medical institutions to optimize their document flow. Because of strict regulations and high accuracy standards, document processing automation becomes complex. But some healthcare organizations like the FDA implement various document classification techniques to process tons of medical archives daily.
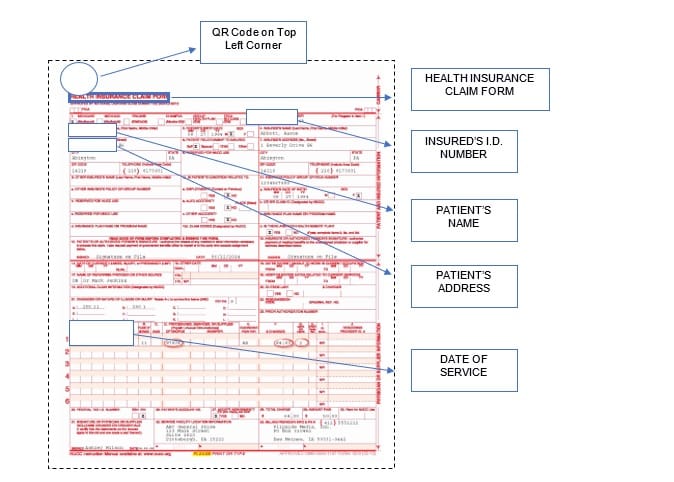
An example of document structure in healthcare insurance. Source: affine.ai
Another example is the insurance industry that processes tens of thousands of claims daily. But it suffers from inefficient workflow since the majority of claims come as scans. It requires extracting raw data from claims automatically and applying NLP for analysis. For example, Wipro, a software vendor, provides an NLP classifier to detect fake claims in the insurance sector.
Object recognition with computer vision
Object recognition can be applied in business areas that require processing large amounts of visual data to classify them by categories. Mostly, this is a task in inventory management where images depict products that have to be categorized.
For example, Scalr developed an image recognition software implemented in Ecommerce that automates product type classification.
These are some business cases where document classification can be applied in different forms to give a basic understanding of when it can be used. Now, let’s talk about how document classification works in specific cases, and outline technology choice in more detail.
Visual classification with computer vision
Computer vision (CV) is an AI technology for recognizing objects on still images or videos. Image recognition can be used in document classification to detect objects, their location, or behavior on the visual content. This provides us with capabilities to categorize photos and videos and apply filtering and search.


Computer vision explained
There are several classification tasks that computer vision systems can solve.
- Image classification with localization – identifying an object on the image and marking its location. This technique can be applied to classify scanned documents based on their structure, for example, distinguishing documents that have 5 fields to fill in from those with 3 fields.
- Object detection – recognizing and labeling multiple objects on the image and showing the location of every object. For example, classifying user-generated visual content. Travel platforms can define images containing restaurant menus, interiors, etc.
- Object (semantic) segmentation – identifying specific pixels that belong to each object in an image. For instance, detecting disorders on X-ray images and classifying them depending on whether they require a physician's attention.
- Instance segmentation – differentiating multiple objects of the same class. For instance, naming a breed of a dog, human beings, a kind of tree, etc.
This type of classification is not considered a text classification even if it deals with documents because it analyzes the pixel structure of an image and tries to find how text blocks or boxes are situated on the field.
An example of computer vision classification for recognizing different elements of the document. Source: www.sciencedirect.com
Image recognition technologies run on deep neural networks – computing systems designed to recognize patterns. In this case, a neural network is trained specifically to analyze pixel patterns that make up an object on the image. Training neural networks and implementing them in your classifier can be a cumbersome task since they require knowledge of deep learning and pretty large datasets.
So, for this reason, we can use image recognition APIs that are available on the web. Those APIs ship computer vision capabilities to your software, allowing you to perform visual content classification. You can check our image recognition API list to discover some.
Text classification
In most cases, classification concerns textual information, since businesses and organizations rely on text documents for everyday operations. There are several scenarios for implementing a classifier.
Keep in mind that you can’t classify texts before they’re digitized. So, if you have scanned or physical documents, you need to digitize them first using optical character recognition.
Document and text digitization with OCR
Document classification may involve physical documents since in industries such as banking, insurance, and healthcare a vast amount of documents are still on paper. Which forces businesses to establish complex workflows to convert handwritten or typed data into a digital format for classification and other tasks.
Optical Character Recognition (OCR) is a technology that allows for the detection and extraction of text information from scanned documents. Once the text is recognized and digitized, it becomes suitable for further processing. Here, we look at some scenarios of how the basic and more advanced approaches of text classification work.
Rule-based text classification: detecting and counting keywords
The basic way to classify documents is building a rule-based system. Such systems use scripts to run tasks and apply a set of human-crafted rules.
Delineating document categories. Before approaching any type of document classification system, the first step is gathering existing data and analyzing it to understand which classes of items exist. Let’s say we analyzed a set of 50 articles about health and saw that all of them relate to 3 categories: psychology, nutrition, and sports.
A rule-based system will use those categories as a primary input to classify new documents in the future.
Defining keywords. To classify documents, we need to extract domain-specific words usually met in this topic.
Having analyzed, say, 20 articles about psychology, we may find that words like “depression,” “anxiety,'' “syndrome,” “mental,” and “thought” are used frequently. The same analysis is conducted with nutrition and sports categories. As a result, we collect a set of features (keywords) for each category.
Keyword list related to specific categories of articles
At this point, we form a list of keywords that will help us define whether an article relates to a given topic. A rule-based engine consisting of scripts will scan documents and find relevant keywords to count. As a result, it will score each article by the number of found keywords.
Rule-based systems are easy to implement and can handle a lot of routine classification tasks. For instance, if you have a set of standard documents like invoices and receipts, you can classify them by checking whether the first line contains such keywords as “invoice” and “receipt.”
That said, you have to know specific rules. It’s great if you know the criteria of classification. But once the task goes beyond mere keyword count, it becomes increasingly difficult to come up with exhaustive and definitive principles of classification.
Classifying formal documents by type is the most basic example where rule-based systems would work well. When it comes to advanced tasks like defining emotions in text or detecting spam – that’s where rule-based systems meet their limitations.
Machine learning classification with natural language processing (NLP)
Working with more complex text classification tasks requires natural language processing or NLP. NLP lies at the intersection of several disciplines – linguistics, statistics, and computer science techniques that allow computers to understand human language in context. With the help of NLP, document classifiers can define patterns in texts or even grasp the meaning of words – kinda.
NLP is a machine learning technology, which means it needs a lot of data to train a model, but helps address more intricate text classification challenges such as analyzing comments, articles, reviews, and other media documents.
As opposed to human-crafted if-then logic we write for rule-based systems, ML models are trained to recognize categories automatically. ML training assumes that we feed past data that has predefined categories and a set of features to the model to learn statistical connections between words and phrases.
With the help of natural language processing, ML models can provide a high degree of automation in text analysis, being much more accurate and flexible than rule-based systems. So, now let’s look at making ML-based classifiers.
Stating categories and collecting training dataset. Before a model can classify any documents, it has to be trained on historical data tagged with category labels. We can label existing documents to use as our training dataset.
Note that a large amount of tagged data is required to get valid results. If you don’t own enough documents or resources to label them, you can search for relevant datasets in free libraries like Google BigQuery Public Data or Paperswithcode.
However, chances are you won’t find the right fit for your specific task in open sources. Given the importance of the correct labeling, consider other options – like contacting companies that specialize in data preparation. Read our articles about Data Labeling and How to Organize Data Labeling for Machine Learning to get more information.
Preprocessing data, or documents in this case, means making them feasible and predictable. This involves numerous operations like lower-casing all the words, transforming them into a root form (walking - walk), or leaving just the root. Then, the document might be also cleaned from stop words (and, the, is, are), and normalized unifying different forms of the same words (okay, ok, kk).
While it’s not obligatory to run preprocessing tasks, machine learning projects that require high accuracy usually involve such preparation. It makes data much easier for the algorithm to digest during the training process. This is especially important when we speak about NLP-based systems and sentiment analysis projects.
Feature extraction or vectorization is the process of converting text into its numerical (vector) representation. The basic technique of feature extraction is called bag of words. It represents each sentence as a string of numbers, based on the simple principle of occurrence (or nonoccurrence) of particular keywords.
More complex vectorization approaches like Latent Semantic Analysis (LSI), Word2Vec, or GloVe (Global Vectors) can analyze contextual use of keywords, capture semantic relationships, and pinpoint phrases with the same meaning. For example, sentences “He was short of money” and “He had not enough money” convey the same idea. Converting these phrases into sets of vectors is one of the methods in text analysis to compare semantic constructions and find similarities in the content.
Model training. There are numerous algorithms out there applicable to document classification tasks. Popular options are Naive Bayes and Support Vector Machine (SVM) as they don’t require large amounts of training data to provide accurate results.
During the training, a model will learn to define how given features correlate with the categories. In the example of a Support Vector Machine algorithm, the process of learning can be visualized as a hyperplane.
Support Vector Machine Hyperplane
What it basically does is split our training vectors into two subspaces: one for documents that relate to the topic “psychology,” and another for all the rest. Analyzing vector scores, the SVM model searches for the largest margin between the training documents. This margin denotes the optimal difference between psychology and nonpsychology articles. And it will apply the learned results to classify new documents.
We’ve explored different ways of classifying documents into predefined categories. But what if these categories are unknown? What if we need to sort out documents of multiple types from a variety of sources? Let's look at the options to address this challenge.
Unsupervised classification: defining categories
In all previous cases, we control our classifiers either through rules (in rule-based systems) or via category labels assigned to training data (in ML-based systems.) The type of machine learning where we provide input (define existing categories) is called supervised learning. But it doesn’t work for scenarios when we have no idea about classification criteria. Besides that, even if categories are defined, annotating a large number of training documents takes much time and effort. That’s when unsupervised machine learning can help.
Unsupervised classification or clustering algorithms don’t require labeled datasets to do their job. They discover similarities in documents and organize them in groups (clusters) accordingly. The result is that objects from the same cluster will share more common features (like keywords) than in different clusters.
Unsupervised text classification. By applying NLP to understand the context of words, the model can scan an existing dataset and find similarities between documents. Then, it divides the set of similar documents into a cluster. This cluster will contain records with content that theoretically falls into the same category.
Unsupervised image classification. Unsupervised learning models can also be used to discover repeating patterns in images and perform clustering based on similar properties. This can be a case of object classification: The model is trained to detect objects on the image, and then define which class it relates to. Similar to clustering in text classification, unsupervised models will require quite a large amount of data to learn how to distinguish between the object types and which objects exist.
Hybrid approach to document classification
The choice of technology to classify documents depends on the particular task you need to solve. However, more often than not, the best option involves a combination of different methods.
One of the realizations of such a hybrid approach is the system built for the Berry Appleman & Layman law company. It combines computer vision and OCR for classifying immigrant documents. First, the software classifies images of common documents by their structure (for example, passports, birth certificates, etc). Second, it applies OCR to “read'' Requests for Evidence or RFEs. Once text from RFEs is extracted and digitized, a copy-paste operation is performed to create a document draft to be used by lawyers in further work.
Another example is сlinical text classification with convolutional neural networks and rule-based features. The entire process includes three steps: 1) identifying trigger phrases that contain disease names using rules; 2) predicting classes based on trigger phrases; 3) training CNN to classify clinical records. While this classifier exists as a research project, it holds a lot of promise and can become a foundation for a real-life system.