

ETL and ELT are the most widely used methods in data engineering for delivering information from one or many sources to a centralized system for easy access and analysis. Both consist of the extract, transform, and load stages. The distinction is based on the order of events. While you might think that a slight change in the stage sequence would have no impact, it makes a world of difference to the integration flow.
In this post, we'll dive deep into the explanation of ETL vs ELT processes and compare them against essential criteria so you can decide which is best suited for your data pipeline.
Learn how ELT and ETL aid master data management implementation in our dedicated article.
ETL and ELT overview
As we mentioned before, ETL and ELT are the two ways to integrate data into a single location. The primary difference resides in WHERE and WHEN data transformation and loading happens. With ETL, data is transformed in a temporary staging area before it gets to a target repository (e.g., an enterprise data warehouse) whereas ELT makes it possible to transform data after it's loaded into a target system (cloud data warehouses or data lakes). Why does it matter so much? Let’s figure it out.
What is ETL?
ETL is the initialism for extraction, transformation, and loading. It is the process of collecting raw data from disparate sources, transmitting it to a staging database for conversion, and loading prepared data into a unified destination system.
ETL tools are used for data integration to meet the requirements of relational database management systems and/or traditional data warehouses that support OLAP (online analytical processing). OLAP tools and structured query language (SQL) queries need data sets to be structured and standardized through a series of transformations that happen before data gets into a warehouse.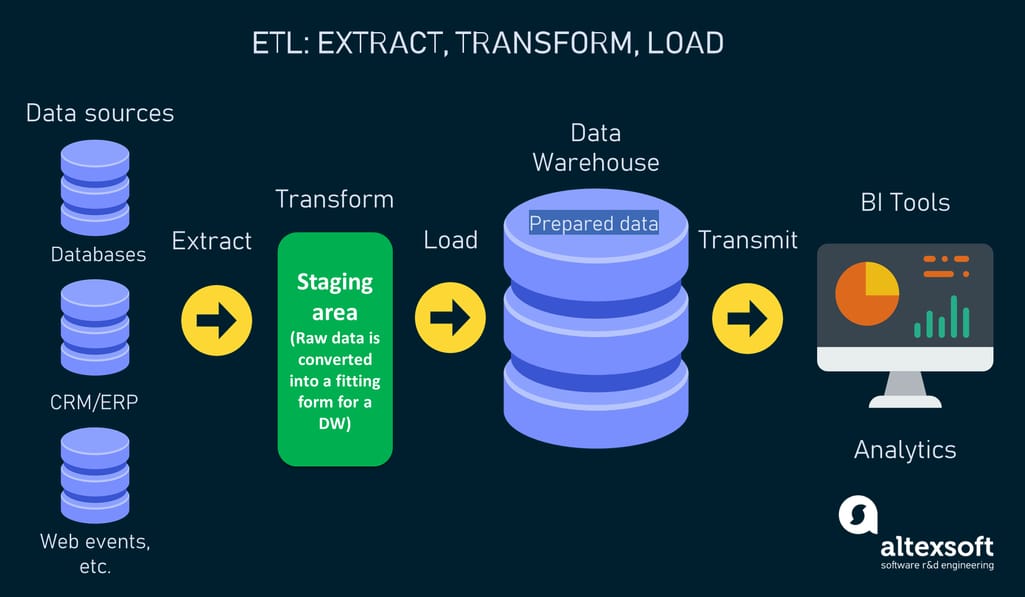
The ETL workflow.
The approach originated in the 1970s when companies started using multiple data repositories for work with different types of business information. As the number of disjointed databases grew larger, the need to consolidate all that data into a centralized system grew as well. ETL arrived to meet that need and became the standard data integration method. From the late 1980s, when data warehouses showed up, and up to the mid-2000s, ETL was the main method used to create data warehouses to support business intelligence (BI).
As data keeps growing in volumes and types, the use of ETL becomes not only rather ineffective but also more costly and time-consuming. And ELT comes to the rescue.
What is ELT?
With the exploding number of data sources and increasing need to process massive datasets for business intelligence purposes and big data analytics, ELT, the alternative to the traditional data integration method, is gaining popularity.
ELT is the initialism for extraction, loading, and transformation. Basically, ELT inverts the last two stages of the ETL process, meaning that after being extracted from databases, data is loaded straight into a central repository where all transformations occur. The staging database is absent.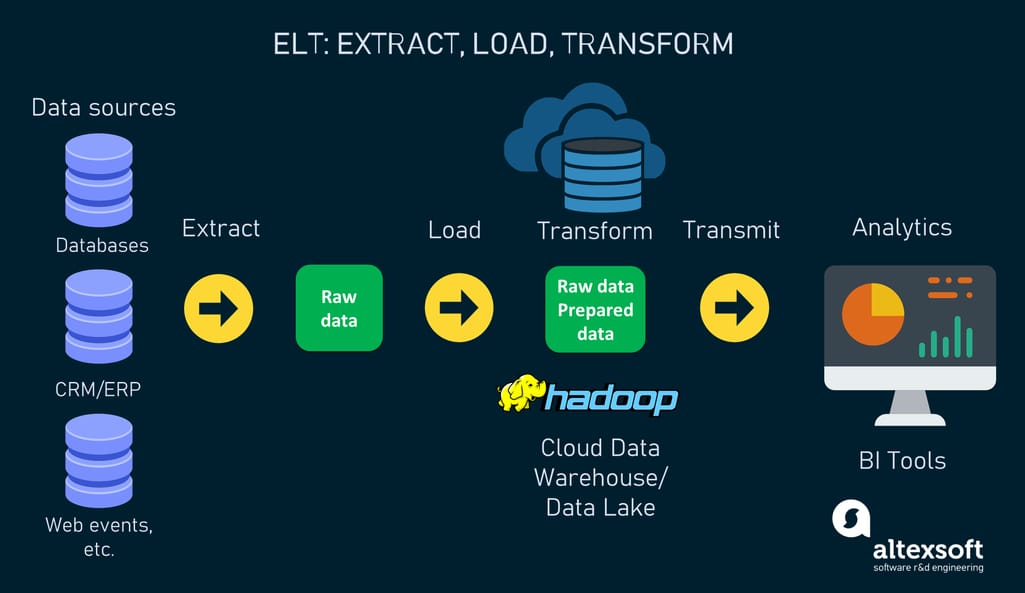
The ELT workflow.
The approach is possible thanks to the modern technologies that allow for storing and processing huge volumes of data in any format. This includes Apache Hadoop, an open-source software that was initially created to continuously ingest data from different sources, no matter its type. Cloud data warehouses such as Snowflake, Redshift, and BigQuery also support ELT, as they separate storage and compute resources and are highly scalable.
Key stages of the ETL and ELT processes
The data flow of both ETL and ELT relies on three core stages. Despite the identical names, the stages of each approach differ not only by the order they happen but also by the ways they are performed.
Extract
Stage 1 in both processes
The data journey always begins with its extraction and copying from a pool of sources — ERP and CRM systems, SQL and NoSQL databases, SaaS applications, web pages, flat files, emails, mobile apps, etc. The initial phase may be quite intricate due to the complexities of each source system.
Data is usually extracted in one of the three ways.
- Full extraction is applied to systems that can’t identify which records are new or changed. In such cases, the only way to pull data out of the system is to extract all records — old and new.
- Partial extraction with update notifications is the most convenient way to extract data from source systems. It is possible if the systems provide alerts when any records are changed so there’s no need to load all data.
- Incremental extraction or partial extraction without update notifications is the method of getting extracts on only those records that have been modified.
With the ETL method, users have to plan ahead which data items should be extracted for further transformation and loading. ELT, on the flip side, makes it possible to extract and load all the data immediately. Users can decide which data to transform and analyze later.
Transform
Stage 2 in ETL / Stage 3 in ELT
The transformation phase involves an array of activities aiming at preparing data by changing it to fit the parameters of another system or the desired result.
Transformations may include:
- data sorting and filtering to get rid of irrelevant items,
- de-duplicating and cleansing,
- translating and converting,
- removing or encrypting to protect sensitive information, and
- splitting or joining tables, etc.
In ETL, all these operations occur outside the destination system in a staging area. There are data engineers who are responsible for implementing these processes. For example, Online Analytical Processing (OLAP) data warehouses only allow relational data structures so the data has to be transformed into the SQL-readable format beforehand. Any conversions can happen only once, making ETL quite inflexible. In case a new type of analysis is necessary to apply to the already transformed data, you may end up modifying the whole data pipeline from scratch.
The ELT method is flexible and transformation-friendly as data goes straight to a data warehouse, data lake, or data lakehouse where it can be validated, structured, and converted in different ways at any time. Moreover, raw data can undergo numerous transformations as it is stored indefinitely. Since everything happens inside a target system, data analysts can assist data engineers to perform transformations using SQL for this purpose.
Load
Stage 2 in ELT/ Stage 3 in ETL
This stage applies to loading data into a target data storage system so that users can access it. The ETL process flow implies the import of previously extracted and already prepared data from a staging database into a target data warehouse or database. This is performed either through physically inserting separate records as new rows into the table of a warehouse using SQL commands or with the help of a massive bulk load scenario.
ELT, in turn, delivers the mass of raw data directly to the target storage location, skipping an intermediate level. This cuts the extraction-to-delivery cycle big time. Just like with extraction, data can be loaded either fully or partially.
ELT vs ETL: detailed, head-to-head comparison
To help you understand the benefits and limitations of both approaches for data integration, we've singled out the most important criteria against which ETL and ELT will be compared.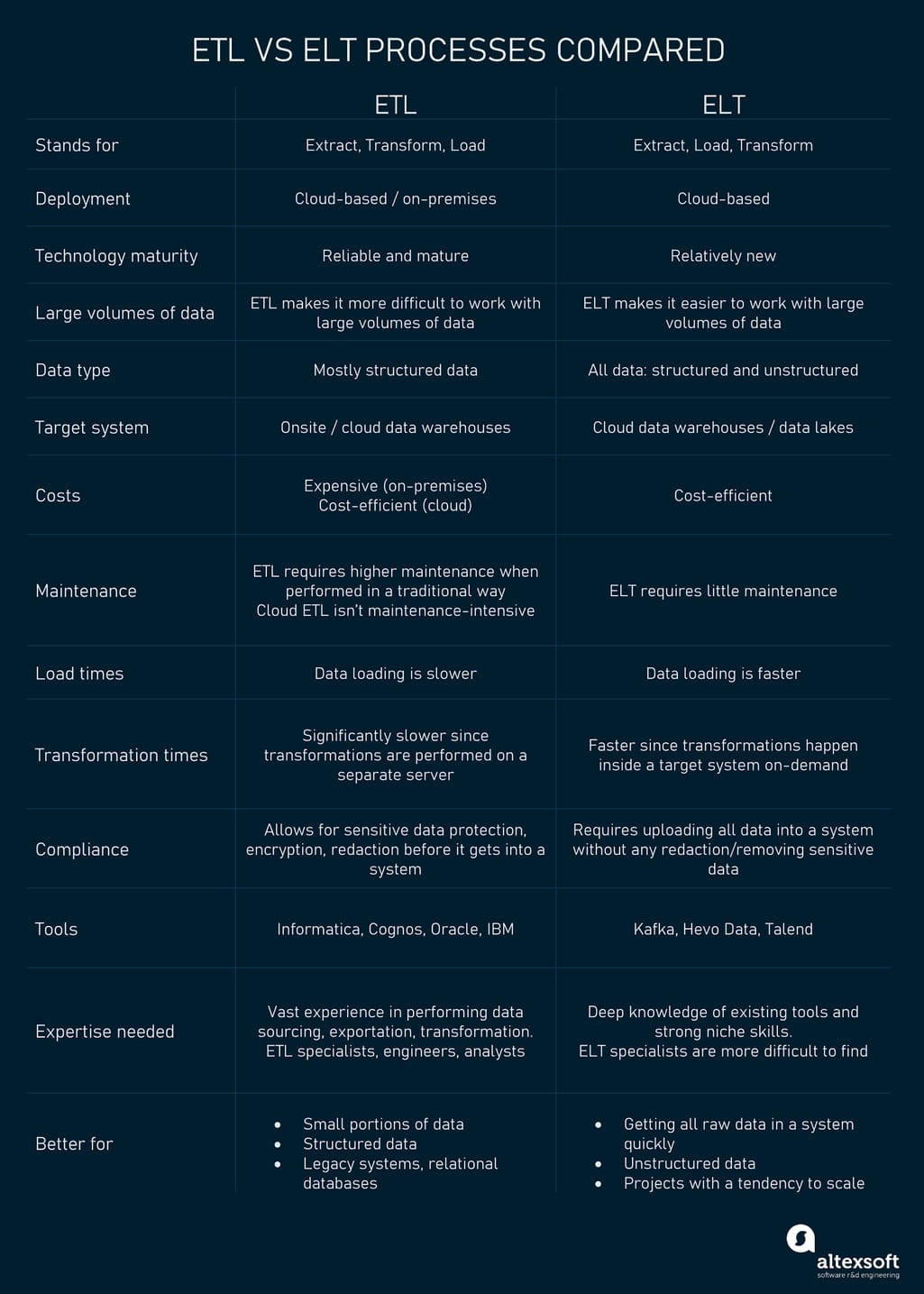
ETL vs ELT compared against essential criteria.
Technology maturity
ELT is a relatively new methodology, meaning there are fewer best practices and less expertise available. Such tools and systems are still in their infancy. Specialists, who know the ELT process, are more difficult to find.
The ETL practice, on the other hand, is rather mature. Since it has been around for a while, there are quite a few properly-developed tools, experienced specialists, and best practices to rely on.
Key message: ETL is more reliable and mature.
Data size and type
Along with structured data, ELT allows for processing large amounts of non-relational and unstructured data, which is required for efficient big data analytics and BI.
In case all the source data comes from relational databases or when it needs to be thoroughly cleansed before loading into a target system, ETL is often chosen over ELT.
Key message: Flexible and scalable, ELT overruns its older brother in terms of its capability to ingest massive sets of various data types.
Data warehouse/Data lake support
ETL is applied when working with OLAP data warehouses, legacy systems, and relational databases. It doesn’t provide data lake support.
ELT is a modern method that can be used with cloud-based warehouses and data lakes.
Key message: Different methods work for different use cases.
Costs
Not only is ELT overall cost-efficient as against high-performance on-premise solutions, but it also provides a lower entry cost. Many cloud providers offer flexible pay-as-you-go pricing plans.
Architectures running traditional ETL processes can be expensive due to the initial investment in hardware and costs related to the power of the transformation engine. At the same time, modern cloud ETL services also provide flexible pricing plans based on usage requirements.
Key message: ELT is relatively lower in cost compared to onsite ETL.
Maintenance
ELT is a cloud-based solution with automated features that need little to no maintenance. All data is at the ready and can be transformed piece-by-piece for analytical purposes.
ETL processes demand higher maintenance when it comes to onsite solutions with physical servers. Speaking of cloud ETL solutions with automated processes, things are pretty much the same as with ELT: They aren't maintenance-intensive.
Key message: ELT beats onsite ETL in terms of maintenance.
Load times
Unlike ETL, ELT reduces the load times owing to the built-in processing capabilities of cloud solutions that allow for loading data in its raw formats without prior transformations.
With ETL, the process of data loading is slower due to the need to transform data on a separate processing server before ingesting it into a destination system.
Key message: ELT provides faster loading.
Transformation times
With ETL, transformations are performed on a separate server and are significantly slower, especially in regard to large volumes of data.
In ELT, a target system is responsible for transformations. Due to the separate storage and compute, data can be stored in its original formats and converted on-demand. The size of data doesn't influence the speed.
Key message: It takes less time for transformations in ELT.
Compliance
With ELT, data is uploaded “as is” without any reduction or encryption done prior, which can make data vulnerable to hacking and violate some compliance standards.
ETL allows for redacting, encrypting, or removing sensitive data before it gets to a data warehouse. As such, it is easier for companies to protect data and stick to different compliance standards including HIPAA, CCPA, or GDPR.
Key message: The good old ETL has the upper hand in terms of compliance.
Tools and expertise
The implementation of both processes requires deep knowledge of existing tools and strong skills.
Due to ELT immaturity, specialists with expertise in this methodology are difficult to find. Kafka, Hevo Data, Talend, and some other software offer comprehensive ELT capabilities along with ETL.
Performing processes such as data sourcing, exporting, transformation, and migration requires skilled ETL specialists. Luckily, it is easier to find the talent. Informatica, Cognos, and Oracle are a few examples of traditional ETL tools.
Key message: ETL offers greater availability of tools and expertise on the market.
Wrapping up, both processes have their advantages and limitations. To decide on the winner of the rivalry (if there is one), let's look through the possible use cases of ETL and ELT.
ETL vs ELT use cases
Cloud data warehouses have opened new horizons for data integration, but the choice between ETL and ELT relies on the needs of a company in the first place.
It is better to use ETL when . . .
- You need to ensure compliance with established standards for protecting the sensitive data of your clients. For instance, healthcare organizations must maintain compliance with the HIPAA Security Rule. So, they can opt for ETL to mask, encrypt or remove sensitive data before loading it in the cloud.
- You only work with structured data and/or with small portions of data.
- Your company runs a legacy system or deals with on-premise relational databases. An example of ETL real-life use cases can be EHR data extraction during legacy EHR system modernization with patient data to be first selectively extracted from the legacy system and then transformed into a fitting format for the new system.
It is better to use ELT when . . .
- Real-time decision-making is the most important factor in your strategy. The speed of data integration is a key advantage of ELT since the target system can do the data transformation and loading in parallel. This, in turn, allows nearly real-time analytics.
- Your company operates massive amounts of data both structured and unstructured. For example, a transportation company that uses telematics devices in its fleet may need to process huge volumes of diverse data generated by sensors, video recorders, GPS trackers, etc. All that data processing requires great resources as well as investments in those resources. ELT is the way to save money and achieve better performance.
- You deal with cloud projects or hybrid architectures. Though modern ETL has opened its doors to the cloud warehouses, it still requires a separate engine to perform transformations before loading data into the cloud. ELT eliminates the need for installing intermediate processing engines, and as such, it is a better choice for cloud and hybrid use cases.
- You are going to run a Big Data project. ELT is born to address the key challenges of Big Data: Volume, Variety, Velocity, and Veracity.
- You have a data science team that needs access to all raw data to use it in machine learning projects.
- Your project tends to scale and you want to take advantage of the high scalability of modern cloud warehouses and data lakes.
The future of ETL and ELT
The technologies of data warehousing are advancing in leaps and bounds. Modern cloud solutions are progressively replacing traditional ways of storing data. Providing scalable data storage and compute powers with on-demand pricing plans, cloud-based platforms allow for keeping, accessing, and processing huge volumes of data when needed. All of that means a greater number of companies are stepping away from the ETL method to manage data pipelines using the ELT method.
The spread of data lakes also plays in favor of ELT as more and more organizations prefer migrating their data processes from on-premises to the cloud. The management of data lakes happens using a big data platform like Apache Hadoop we mentioned before or a NoSQL database management system. ELT is also a preferred approach for data science teams as it provides them with an opportunity to use raw data and transform it according to their unique requirements.
That being said, ELT seems to be the logical future for building effective data flows as it offers a myriad of benefits over ETL. ELT is cost-effective, flexible, and lower maintenance. It fits businesses of diverse fields and sizes. ETL is an outdated and slow process with tons of hidden rocks on which organizations can stumble on the way to data integration. But as we can tell from the use cases ETL cannot be replaced completely.