

If you’ve been following the direction of expert opinion in data science and predictive analytics, you’ve likely come across the resolute recommendation to embark on machine learning. As James Hodson in Harvard Business Review recommends, the smartest move is to reach for the “low hanging fruit” and then scale for expertise in heavier operations.
Just recently we talked about machine-learning-as-a-service (MLaaS) platforms. The main takeaway from the current trends is simple. Machine learning becomes more approachable for midsize and small businesses as it gradually turns into a commodity. The leading vendors – Google, Amazon, Microsoft, and IBM – provide APIs and platforms to run basic ML operations without a private infrastructure and deep data science expertise. In the early stages, taking this lean and frugal approach would be the smartest move. As an analytics capabilities scale, a team structure can be reshaped to boost operational speed and extend an analytics arsenal.
This time we talk about data science team structures and their complexity.
Data-driven teams
Most successful data-driven companies address complex data science tasks that include research, use of multiple ML models tailored to various aspects of decision-making, or multiple ML-backed services. In the case of large organizations, data science teams can supplement different business units and operate within their specific fields of analytical interest. Obviously, being custom-built and wired for specific tasks, data science teams are all very different.


Watch our video for a quick overview of data science roles
Let’s look, for example, at the Airbnb data science team. You can watch this talk by Airbnb’s data scientist Martin Daniel for a deeper understanding of how the company builds its culture or you can read a blog post from its ex-DS lead, but in short, here are three main principles they apply.
Experiment. Find ways to put data into new projects using an established Learn-Plan-Test-Measure process.
Democratize data. Scale a data science team to the whole company and even clients.
Measure the impact. Evaluate what part DS teams have in your decision-making process and give them credit for it.
These three principles are pretty common across tech leaders as they enable data-driven decision making. To follow them though, you have to have a clear strategy in mind and an understanding of who these teams are composed of and how they fit into organizational structures.
Regardless of whether you’re striving to become the next best data-driven company or not, having the right talent is critical. Who are the people you should look for?
Data science team roles
Let’s talk about data scientist skill sets. Unfortunately, the term data scientist expanded and became too vague in recent years. After data science appeared in the business spotlight, there is no consensus developed regarding what the skillset of a data scientist is. Matthew Mayo, Data Scientist and the Deputy Editor of KDNuggets, argues: “When I hear the term data scientist, I tend to think of the unicorn, and all that it entails, and then remember that they don't exist, and that actual data scientists play many diverse roles in organizations, with varying levels of business, technical, interpersonal, communication, and domain skills.”
This is true. It’s hard to find unicorns, but it’s possible to grow them from people with niche expertise in data science. We at AltexSoft consider these data science skills when hiring machine learning specialists: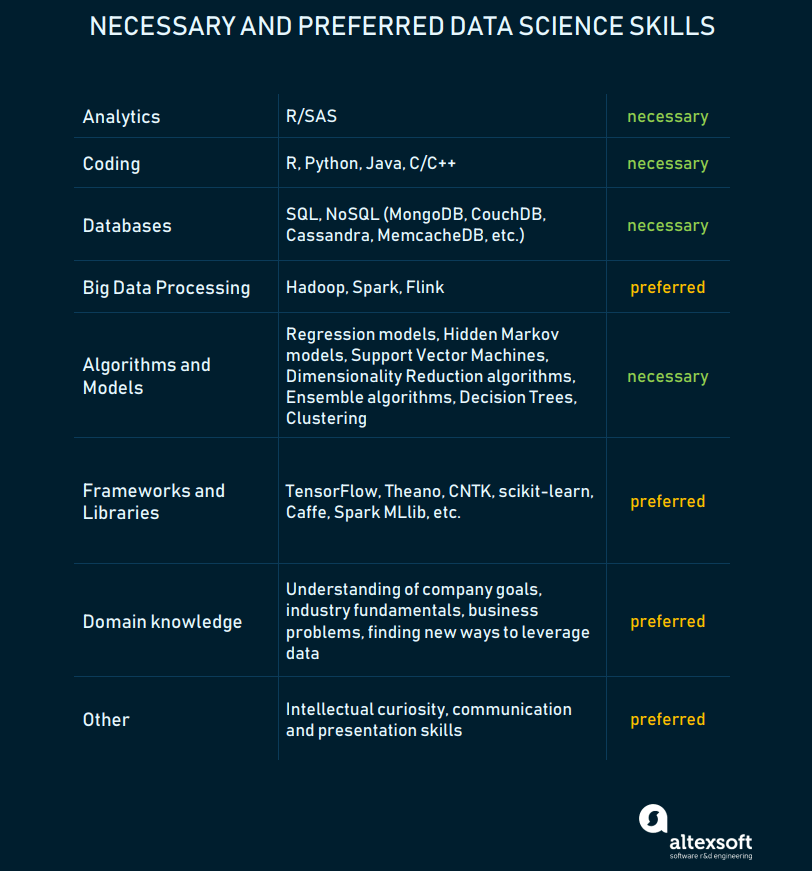
Skillset of a data scientist
As you will see below, there are many roles within the data science ecosystem, and a lot of classifications offered on the web. We will share with you the one offered by Stitch Fix’s Michael Hochster. Michael defines two types of data scientists: Type A and Type B.
Type A stands for Analysis. This person is a statistician that makes sense of data without necessarily having strong programming knowledge. Type A data scientists perform data cleaning, forecasting, modeling, visualization, etc.
Type B stands for Building. These folks use data in production. They’re excellent good software engineers with some stats background who build recommendation systems, personalization use cases, etc.
Rarely does one expert fit into a single category. But understanding these two data science functions can help you make sense of the roles we’ve described further.
Keep in mind that even professionals with this hypothetical skillset usually have their core strengths, which should be considered when distributing roles within a team. In most cases, acquiring talents will entail further training depending on their background.
But people and their roles are two different things. For instance, if your team model is the integrated one, an individual may combine multiple roles. So, let’s disregard how many actual experts you may have and outline the roles themselves. Obviously, many skillsets across roles may intersect.
Chief Analytics Officer/Chief Data Officer. In our whitepaper on machine learning, we broadly discussed this key leadership role. CAO, a “business translator,” bridges the gap between data science and domain expertise acting both as a visionary and a technical lead. You may get a better idea by looking the visualization below.
Preferred skills: data science and analytics, programming skills, domain expertise, leadership and visionary abilities 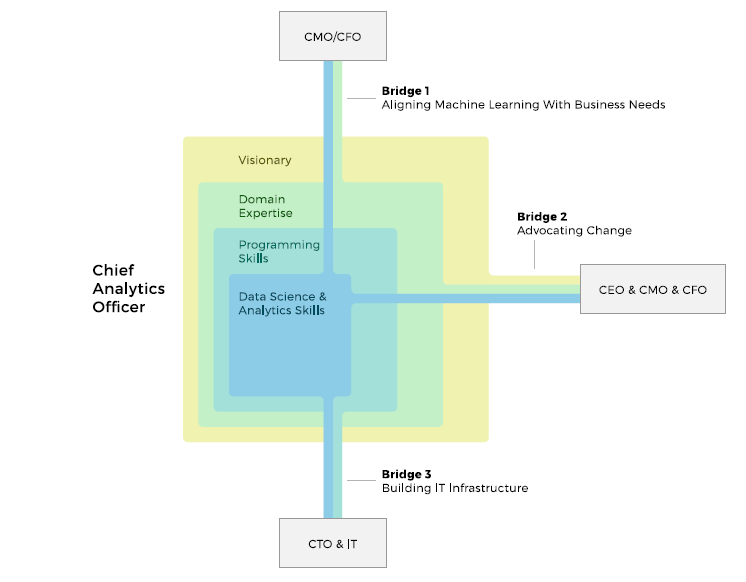
Role of a Chief Analytics Officer
Data analyst. The data analyst role implies proper data collection and interpretation activities. An analyst ensures that collected data is relevant and exhaustive while also interpreting the analytics results. Some companies, like IBM or HP, also require data analysts to have visualization skills to convert alienating numbers into tangible insights through graphics.
Preferred skills: R, Python, JavaScript, C/C++, SQL
Business analyst. A business analyst basically realizes a CAO’s functions but on the operational level. This implies converting business expectations into data analysis. If your core data scientist lacks domain expertise, a business analyst bridges this gulf.
Preferred skills: data visualization, business intelligence, SQL
Data scientist (not a data science unicorn). What does a data scientist do? Assuming you aren’t hunting unicorns, a data scientist is a person who solves business tasks using machine learning and data mining techniques. If this is too fuzzy, the role can be narrowed down to data preparation and cleaning with further model training and evaluation.

How data preparation works in machine learning
Preferred skills: R, SAS, Python, Matlab, SQL, noSQL, Hive, Pig, Hadoop, Spark
To avoid confusion and make the search for a data scientist less overwhelming, their job is often divided into two roles: machine learning engineer and data journalist.
A machine learning engineer combines software engineering and modeling skills by determining which model to use and what data should be used for each model. Probability and statistics are also their forte. Everything that goes into training, monitoring, and maintaining a model is ML engineer’s job.
Preferred skills: R, Python, Scala, Julia, Java

ML engineer role, explained in 12 minutes or less
Data journalists help make sense of data output by putting it in the right context. They're also tasked with articulating business problems and shaping analytics results into compelling stories. Though required to have coding and statistics experience, they should be able to present the idea to stakeholders and represent the data team with those unfamiliar with statistics.
Preferred skills: SQL, Python, R, Scala, Carto, D3, QGIS, Tableau
Data architect. This role is critical for working with large amounts of data (you guessed it, Big Data). However, if you don’t solely rely on MLaaS cloud platforms, this role is critical to warehouse the data, define database architecture, centralize data, and ensure integrity across different sources. For large distributed systems and big datasets, the architect is also in charge of performance.
Preferred skills: SQL, noSQL, XML, Hive, Pig, Hadoop, Spark
Data engineer. Engineers implement, test, and maintain infrastructural components that data architects design. Realistically, the role of an engineer and the role of an architect can be combined in one person. The set of skills is very close.
Preferred skills: SQL, noSQL, Hive, Pig, Matlab, SAS, Python, Java, Ruby, C++, Perl
To learn more about data engineering in general, check our explainer video:

What is data engineering?
Application/data visualization engineer. Basically, this role is only necessary for a specialized data science model. In other cases, software engineers come from IT units to deliver data science results in applications that end-users face. And it’s very likely that an application engineer or other developers from front-end units will oversee end-user data visualization.
Preferred skills: programming, JavaScript (for visualization), SQL, noSQL.
Team assembly and scaling
The initial challenge of talent acquisition in data science, besides the overall scarcity of experts, is the high salary expectations. According to O’Reilly Data Science Salary Survey 2017, the median annual base salary was $90,000, while in the US the figure reached $112,774 at the time of updating this article. These numbers significantly vary depending on geography, specific technical skills, organization sizes, gender, industry, and education. If you decide to hire skilled analytics experts, further challenges also include engagement and retention.
No doubt, most data scientists are striving to work in a company with interesting problems to solve. But not every company is Facebook, Netflix, or Amazon. However, the needs to fulfill data-related tasks encourage organizations to engage data scientists for entry-level positions. Thus, hiring a generalist with a strong STEM background and some experience working with data, as Daniel Tunkelang advises, is a promising option on the initial levels of machine learning adoption. This approach suggests shifting to strong and narrow-focused specialists at a later stage. They would replace rudimentary algorithms with new ones and advance their systems on a regular basis.
Another way to address the talent scarcity and budget limitations is to develop approachable machine learning platforms that would welcome new people from IT and enable further scaling. Even if no experienced data scientists can be hired, some organizations bypass this barrier by building relationships with educational institutions. In the US, there are about a dozen Ph.D. programs emphasizing data science and numerous boot camps with 12-month-or-so courses.
How to integrate a data science team into your company
As a data science team along with the company’s needs grows, it requires creating a whole new department that needs to be organized, controlled, monitored, and managed. This huge organizational shift suggests that a new group should have established roles and responsibilities – all in relation to other projects and facilities. So, how do you integrate data scientists in your company?
We’ll base the key types on Accenture’s classification, and expand on the team’s structure ideas further.
Decentralized
This is the least coordinated option where analytics efforts are used sporadically across the organization and resources are allocated within each group’s function. This often happens in companies when data science expertise has appeared organically. Business units, like product teams, or functional units at some point recognize their internal need for analytics. They start hiring data scientists or analysts to meet this demand. Sometimes a data scientist may be the only person in a cross-functional product team with data analysis expertise.
Decentralized implementation.
The decentralized model works best for companies with no intention of spreading out into a data-driven company. It may also be applied to the early stages of data science activities for the short-term progress of demo projects that leverage advanced analytics.
There are a number of drawbacks that this model has.
- This model often leads to silos striving, lack of analytics standardization, and – you guessed it – decentralized reporting.
- The hiring process is an issue. When managers hire a data scientist for their team, it’s a challenge for them to hold a proper interview. They clearly understand, say, a typical software engineer’s roles, responsibilities, and skills, while being unfamiliar with those of a data scientist. So, putting it all together is a challenge for them.
- Managing a data scientist career path is also problematic. While team managers are totally clear on how to promote a software engineer, further steps for data scientists may raise questions. The same problem haunts building an individual development plan.
- Lower quality standards and underestimated best practices are often the case. The point is that data scientists must gain knowledge from other mentoring data scientists. As such an option is not provided in this model, data scientists may end up left on their own. This usually leads to no improvements of best practices, which usually reduces data quality and the quality of a product as a whole.
Functional
Here most analytics specialists work in one functional department where analytics is most relevant. And, it’s often marketing or supply chain. This option also entails little to no coordination and expertise isn’t used strategically enterprise-wide.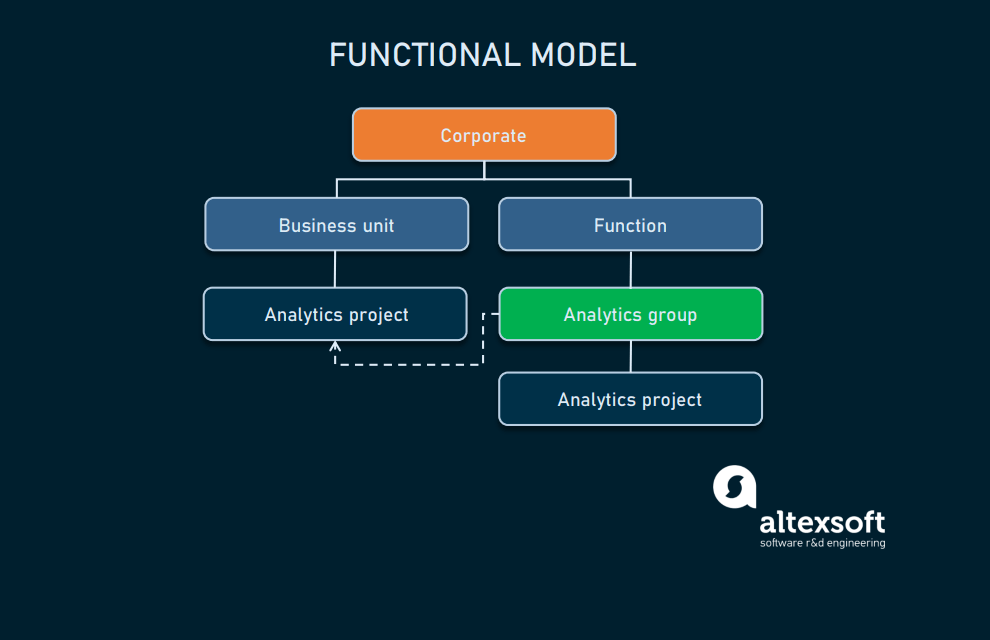
Functional implementation
The functional approach is best suited for organizations that are just embarking on the analytics road. They have no need to analyze data from every single point, and consequently, there are not so many analytical processes to create a separate and centralized data science team for the whole organization.
Drawbacks of the functional model hide in its centralized nature.
- Keeping off from the global company’s pains. The approach entails that analytical activities are mostly focused on functional needs rather than on all enterprise necessities. Such unawareness may result in analytics isolation and staying out of context.
- Weak cohesion due to the absence of a data manager. As an analytical team here is placed under a particular business unit, it submits reports directly to the head of this unit. In this way, there may not be a direct data science manager who understands the specifics of their team.
Consulting
In this structure, analytic folks work together as one group but their role within an organization is consulting, meaning that different departments can “hire” them for specific tasks. This, of course, means that there’s almost no resource allocation – either specialist is available or not.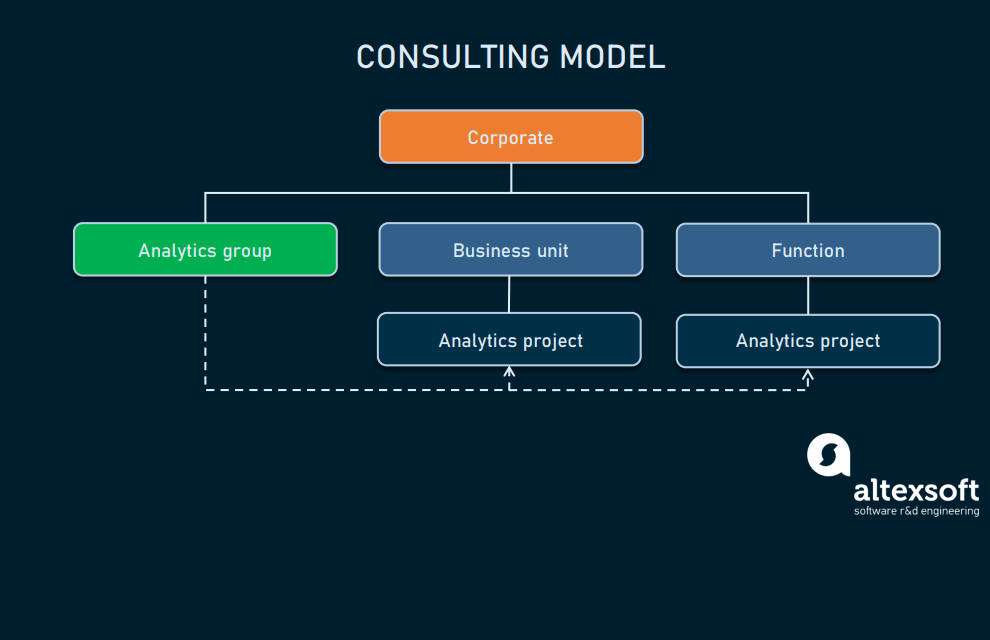
Consulting implementation
The consultancy model is best suitable for SMB companies with sporadic and small- to medium-scale data science tasks. As all DS team members submit and report to one DS team manager, managing such a DS team becomes easier and cheaper for SMB.
However, there are always some pitfalls.
- First of all, poor data quality can become a fundamental flaw of the model. As data scientists can’t adhere to their best practices for every task, they have to sacrifice quality to business needs that demand quick solutions.
- Also, there’s the low-motivation trap. As data scientists are not fully involved in product building and decision-making, they have little to no interest in the outcome.
- A serious drawback of a consulting model is uncertainty. Deadlines are not clear as data scientists are not clearly familiar with data sources and the context of their appearance. Long-term and complex projects are hardly accessible because sometimes specialists work for years over the same set of problems to achieve great results.
- The prioritization method is also unclear. It’s still hard to identify how a data science manager prioritizes and allocates tasks for data scientists and what objectives to favor first.
Centralized
This structure finally allows you to use analytics in strategic tasks – one data science team serves the whole organization in a variety of projects. Not only does it provide a DS team with long-term funding and better resource management, but it also encourages career growth. The only pitfall here is the danger of transforming an analytics function into a supporting one.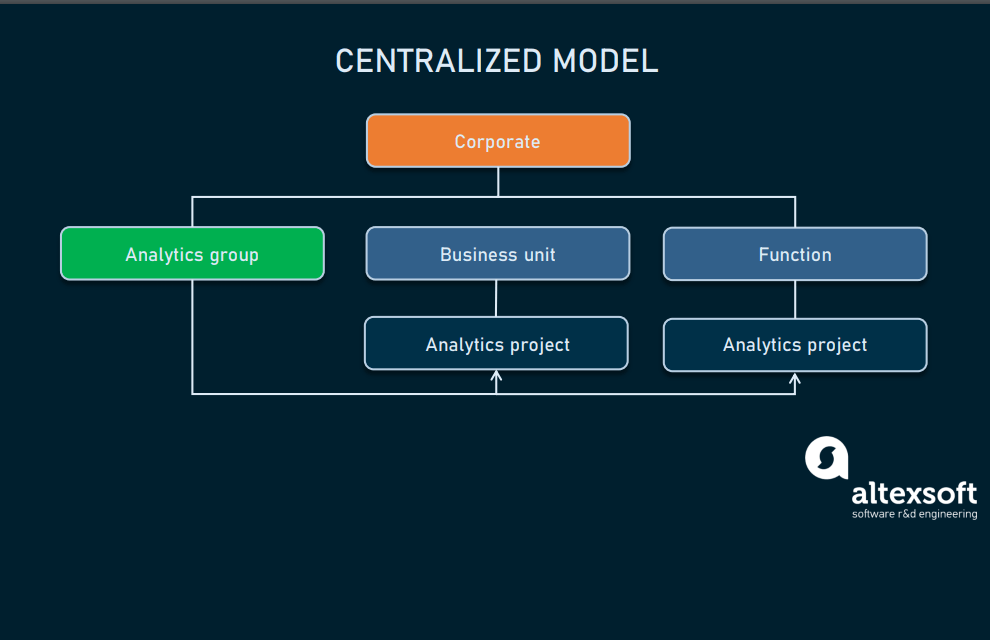
Centralized implementation
One of the best use cases for creating a centralized team is when both demand for analytics and the number of analysts is rapidly increasing, requiring the urgent allocation of these resources. Introducing a centralized approach, a company indicates that it considers data a strategic concept and is ready to build an analytics department equal to sales or marketing.
As always, there are some pitfalls in the model.
- There’s a high chance of becoming isolated and facing the disconnect between a data analytics team and business lines. As the data analytics team doesn’t participate in regular activities of actual business value units, they might not be closely familiar with the latter’s needs and pains. This may lead to the narrow relevance of recommendations that can be left unused and ignored.
- This leads to challenges in meaningful cooperation with a product team. Once the analytics group has found a way to tackle a problem, it suggests a solution to a product team. The biggest problem is that this solution may not fit into a product roadmap. And, conflict may appear. The only way out here is to create a team that would assess, design, and implement the suggested solution. This alternative, however, takes much effort, time, and money.
Sometimes, you may find that a centralized model is described as the Center of Excellence. And it’s okay, there are always unique scenarios. But we’ll stick to the Accenture classification, since it seems more detailed, and draw a difference between the centralized model and the center of excellence.
Center of Excellence (CoE)
If you pick this option, you’ll still keep the centralized approach with a single coordination center, but data scientists will be allocated to different units in the organization. This is the most balanced structure – analytics activities are highly coordinated, but experts won’t be removed from business units.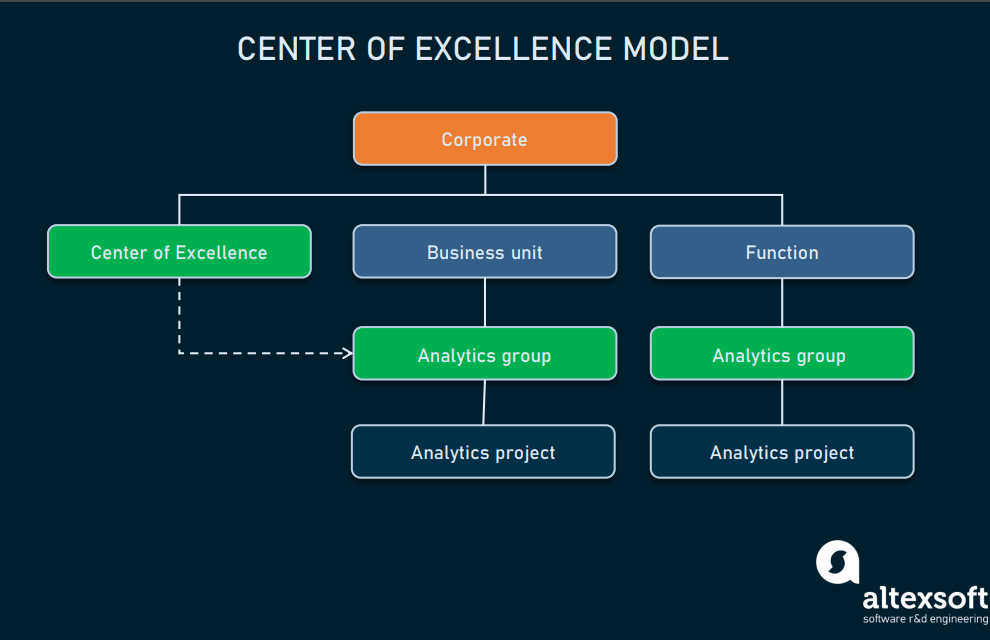
Center of Excellence implementation
Due to its well-balanced interactions, the approach is being increasingly adopted, especially in enterprise-scale organizations. It works best for companies with a corporate strategy and a thoroughly developed data roadmap.
However, even such a deeply data-focused approach has its drawbacks.
- While this approach is balanced, there’s no single centralized group that would focus on enterprise-level problems. Each analytical group would be solving problems inside their units.
- Another drawback is that there’s no innovation unit, a group of specialists that primarily focus on state-of-the-art solutions and long-term data initiatives rather than day-to-day needs.
Federated
This model is relevant when there’s an increasingly high demand for analytics talent across the company. Here, you employ a SWAT team of sorts – an analytics group that works from a central point and addresses complex cross-functional tasks. The rest of the data scientists are distributed as in the Center of Excellence model. Basically, the federated model combines the coordination and decentralization approach of the CoE model but leaves this avantgarde unit.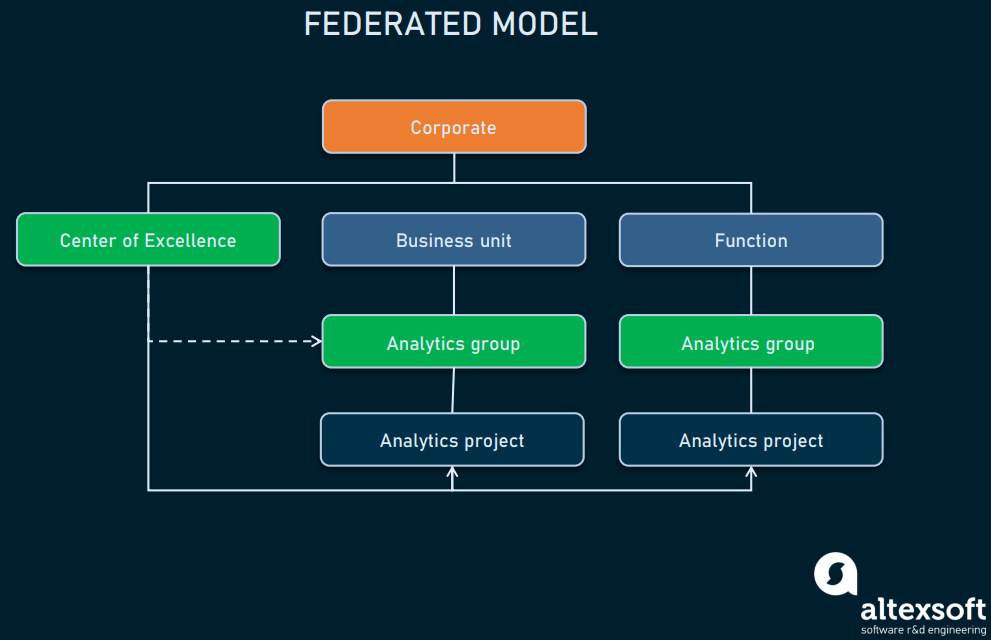
Federated implementation
The federated model is best adopted in companies where analytics processes and tasks have a systemic nature and need day-to-day updates. This approach can serve both enterprise-scale objectives like enterprise dashboard design and function-tailored analytics with different types of modeling.
While it seems that the federated model is perfect, there are still some drawbacks.
- Expenses for talent acquisition and retention. As this model suggests a separate specialist for each product team and central data management, this may cost you a penny. Thus, the approach in its pure form isn’t the best choice for companies when they are in their earliest stages of analytics adoption.
- Cross-functionality may create a conflict environment. It can lack a power parity between all team lead positions and cause late deliveries or questionable results due to constant conflicts between unit team leads and CoE management.
Democratic
This model is an additional way to think of data culture. The democratic model entails everyone in your organization having access to data via BI tools or data portals. This means that it can be combined with any other model described above. You can have a federated approach with CoE and analytics specialists inside each department and at the same time expose BI tools to everyone interested in using data for their duties – which is great in terms of fostering data culture.
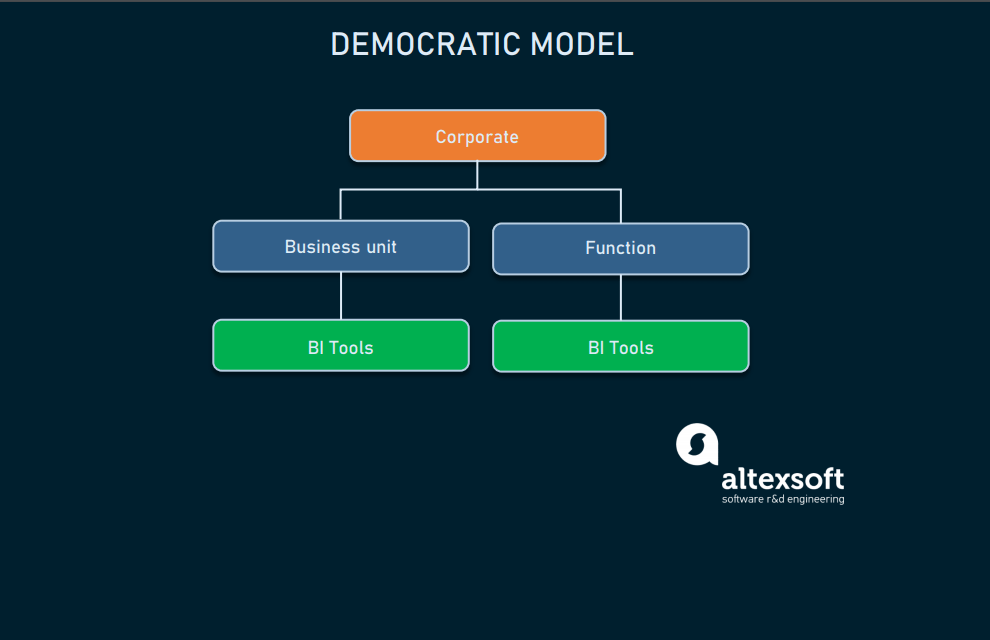
Democratic implementation
Product team members like product and engineering managers, designers, and engineers access the data directly without attracting data scientists.
What are the drawbacks?
- The company that integrates such a model usually invests a lot into data science infrastructure, tooling, and training.
- You simply need more people to avoid tales of a data engineer being occupied with tweaking a BI dashboard for another sales representative, instead of doing actual data engineering work.
Remember, that your model may change and evolve depending on your business needs: While today you may be content with data scientists residing in their functional units, tomorrow a Center of Excellence can become a necessity.
More recommendations for creating a high-performance data science team
Look around for in-house talent. Before even thinking of external talent acquisition for data science roles, assess those you already have in your company. Find out if there are any employees who would like to move in that direction. Identify their data science skills, gaps yet to fill, and invest in training.
Spend less time hiring people for each title and focus on understanding what roles one individual data specialist can fulfill. For startups and smaller organizations, responsibilities don’t have to be strictly clarified.
Foster cross-functional collaborations. Designers, marketers, product managers, and engineers all need to work closely with the DS team.
Practice embedding. As we mentioned above, recruiting and retaining data science talent requires some additional activities. One of them is embedding – placing data scientists to work in business-focused departments to make them report centrally, collaborate better, and help them feel they’re part of the big picture. Federated, CoE, or even decentralized models work here.
Establish a team environment before hiring the team. This means that your product managers should be aware of the differences between data and software products, have adequate expectations, and work out the differences in deliverables and deadlines. PMs need to have enough technical knowledge to understand these specificities. Alternatively, you can start searching for data scientists that can fulfill this role right away.
The critical thing to be aware of
If you ask AltexSoft’s data science experts what the current state of AI/ML across industries is, they will likely point out two main issues: 1. Business executives still need to be convinced that a reasonable ROI of ML investments exists. 2. If they are convinced and understand the value proposition and market demand, they may lack technical skills and resources to make products a reality.
These barriers are mostly due to digital culture in organizations. Efficient data processes challenge C-level executives to embrace horizontal decision-making. Frontline managers with access to analytics have more operational freedom to make data-driven decisions, while top-level management oversees a strategy. This reduces management effort and eventually mitigates “gut-feeling-decision” risks. Basically, the cultural shift defines the end success of building a data-driven business. As McKinsey argues, setting a culture is probably the hardest part, while the rest is manageable.

Oleksandr is a content strategist and editor. He leads (when possible) the team of independent-thinking writers and tech journalists at AltexSoft. With over 10 years of writing and editing tech-related pieces and scripts, he currently focuses on travel tech, data science, and AI. Outside of work, Oleksandr enjoys escapism in video games and game development.
Want to write an article for our blog? Read our requirements and guidelines to become a contributor.