

What if we told you that one of the world's most powerful search and analytics engines started with the humble goal of organizing a culinary enthusiast's growing list of recipes? Shay Banon navigated job searches in a cozy London apartment while his wife honed her culinary skills at Le Cordon Bleu. To help her, Banon developed a search engine for her recipe collection. This endeavor would unwittingly plant the seeds for Elasticsearch, a technology that today drives data search and analytics for businesses around the globe.
From those homemade beginnings as Compass, Elasticsearch has matured into one of the leading enterprise search engines, standing among the top 10 most popular database management systems globally according to the Stack Overflow 2023 Developer Survey. But like any technology, it has its share of pros and cons. Whether you're an enterprise striving to manage large datasets or a small business looking to make sense of your data, knowing the strengths and weaknesses of Elasticsearch can be invaluable.
In this edition of “The Good and The Bad” series, we'll dig deep into Elasticsearch — breaking down its functionalities, advantages, and limitations to help you decide if it's the right tool for your data-driven aspirations.
What is Elasticsearch?
First publicly introduced in 2010, Elasticsearch is an advanced, open-source search and analytics engine that also functions as a NoSQL database. It is developed in Java and built on the highly reputable Apache Lucene library.
The engine's core strength lies in its high-speed, near real-time searches. Unlike traditional databases that rely on tables and schemas, Elasticsearch employs an index-based structure. These indices are specially designed data structures that map out the data for rapid searches, allowing for the retrieval of queries in milliseconds. As a result, Elasticsearch is exceptionally efficient in managing structured and unstructured data. It interacts through comprehensive REST APIs, processing and returning results in JSON format.
In 2023, Elasticsearch introduced the Elasticsearch Relevance Engine (ESRE), a powerful upgrade integrating AI and machine learning into the search. ESRE enables advanced relevance ranking, natural language processing (NLP), and the ability to work with large language models (LLMs) like OpenAI's GPT-3 and GPT-4. Accessible via a unified API, these new features enhance search relevance and are available on Elastic Cloud.
The Elastic Stacks
Elasticsearch is integral in analytics stacks, collaborating seamlessly with other tools developed by Elastic to manage the entire data workflow — from ingestion to visualization. There are three main versions of such stacks: the original ELK (Elasticsearch, Logstash, Kibana), the enhanced ELK incorporating Beats, and the EFK, where Fluentd replaces Logstash.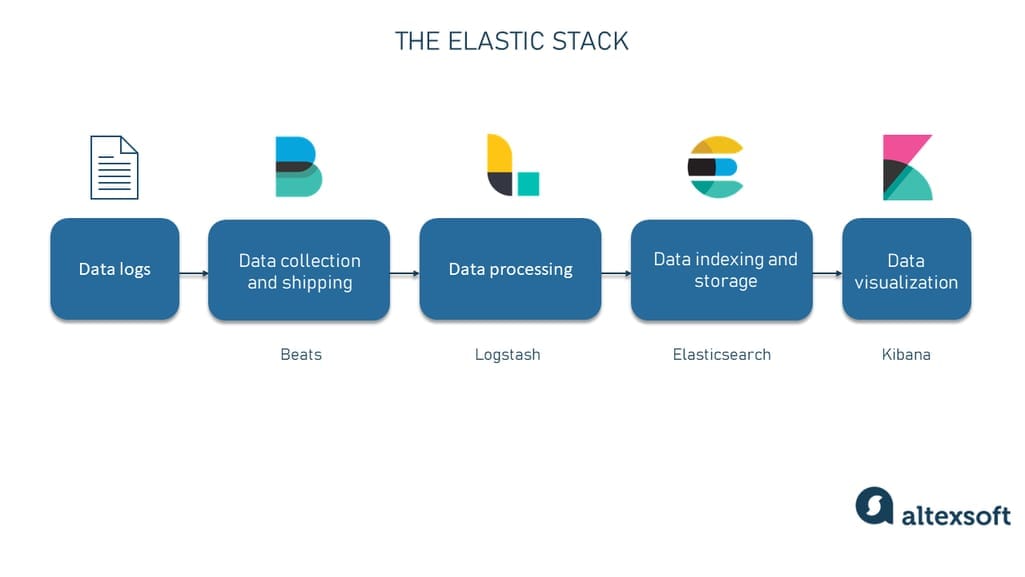
The Elastic (ELK) stack.
Besides Elasticsearch, which is the hub for indexing, searching, and complex data analytics, the stacks include the following tools.
Beats are lightweight data shippers that are part of the Elastic Stack. Beats facilitate data movement from source to destination, which can be either Elasticsearch or Logstash, depending on the use case.
Logstash is a server-side data processing pipeline that ingests data from multiple sources, transforms it, and then sends it to Elasticsearch for indexing.
Fluentd is a data collector and a lighter-weight alternative to Logstash. It is designed to unify data collection and consumption for better use and understanding. It efficiently gathers data from various sources and forwards it to Elasticsearch or other destinations.
Kibana is a data visualization tool that serves as the user interface for the Elastic Stack. It enables users to visualize, explore, and manage data in Elasticsearch.
Elasticsearch use cases
Elasticsearch isn't only a solution for one problem; it offers the speed and flexibility to adapt to various scenarios. While its core strength lies in search and analytics, its applicability stretches far beyond.
Here are some noteworthy use cases.
Search feature for apps and websites. Elasticsearch can be embedded into applications or websites to offer a powerful, fast, and efficient search box, ensuring users can quickly find what they're looking for.
Analysis of logs, metrics, and security events. With Elasticsearch, you can aggregate and analyze large streams of logs, metrics, and security events in near real-time, making it indispensable for system monitoring and security information and event management (SIEM).
Real-time behavior modeling with ML. Elasticsearch supports machine learning algorithms that can automatically model and analyze the behavior of your data in real time, providing valuable insights and predictions.
Business workflow automation. You can leverage Elasticsearch as a storage engine to automate complex business workflows, from inventory management to customer relationship management (CRM).
Geospatial analysis. Elasticsearch manages and integrates spatial data, enabling precise applications like real-time location tracking and geomarketing. It’s crucial for location-based search, dynamic mapping, and environmental monitoring applications. Consequently, it can be used in risk management, asset tracking, and fleet management scenarios, providing detailed insights into spatial patterns, consumer behavior, and environmental conditions in varied geographical areas.
These diverse use cases demonstrate the engine's versatility, making it a popular choice for organizations dealing with various data types and requiring fast, actionable insights.
How Elasticsearch works: Core concepts
The architecture of Elasticsearch is built to be distributed, meaning its capabilities, including storing data, executing searches, and processing analytics, are not limited to a single machine or server. Instead, the workload is distributed across multiple nodes in a cluster. Each node is a running instance of Elasticsearch, and the cluster is a collection of these nodes, connected and working together.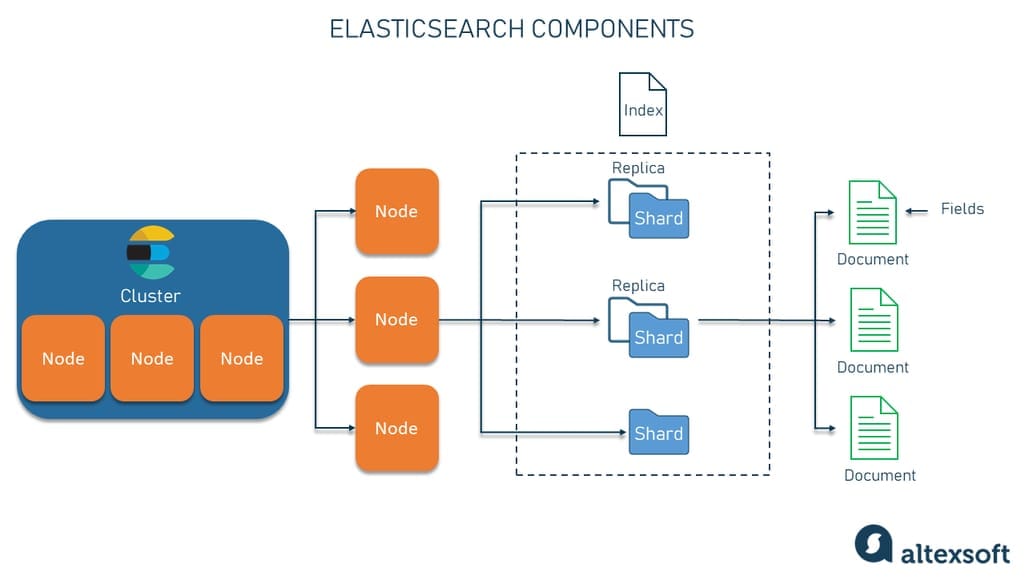
Key components of the Elasticsearch architecture.
Data in Elasticsearch is organized into documents, which are then categorized into indices for greater search efficiency. Each document is a collection of fields, the basic data units to be searched. Fields in these documents are defined and governed by mappings akin to a schema in a relational database. Elasticsearch uses a data structure called an inverted index to make search operations faster.
Elasticsearch's true power lies in its ability to partition indices into smaller units known as shards, facilitating data distribution across multiple servers. It also employs replicas to duplicate these shards to ensure data reliability and availability.
Now, let's delve into these core concepts in more detail.
Cluster
A cluster is a collection of one or more nodes that work together to fulfill indexing, search, and other data-related requests. Clusters use a single name to identify themselves and have one node as the "master" responsible for various administrative tasks.
Nodes
Nodes are individual servers that are part of an Elasticsearch cluster. They can have different roles.
The Master Node is the controlling node in an Elasticsearch cluster. It is responsible for creating or deleting indices, tracking which nodes are part of the cluster, and reallocating shards when nodes join or leave the cluster. There is usually only one master node active at any given time to prevent split-brain scenarios.
The Data Node stores data and performs data-related operations like search and aggregation. These are the workhorses of Elasticsearch, doing the heavy lifting when executing queries.
The Client Node doesn't store any data or have any cluster management responsibilities. Instead, it acts as a smart load balancer that forwards requests to appropriate nodes (master or data nodes) in the cluster. This helps efficiently route the requests to the nodes that are most capable of handling them.
Shards
Shards allow Elasticsearch to scale horizontally as each shard is a self-contained index. Sharding your index lets you distribute these shards across multiple servers. Elasticsearch routes your query to the appropriate shards and then compiles the results to return to you. This is particularly useful in large-scale applications, like searching through a worldwide database of hotels or customer reviews.
Replicas
Replica shards are copies of your primary shards and serve two main purposes: fault tolerance and load balancing. Having replica shards ensures your data is not lost if a node fails. Replicas are also used to serve read requests, so having multiple replicas can increase search speed and performance.
Indices
Indices are like categories under which similar types of documents are grouped. For instance, you could have different indices for Hotels, Guests, and Bookings in the hospitality industry. The Hotels index could contain documents about various hotels, like location, amenities, room types, etc. Similarly, the Guests index could have documents detailing the information about each guest, like name, contact information, and booking history.
Just as you have databases and tables in SQL, you have indices and documents in Elasticsearch. You would query against these indices when you are searching for specific data.
Inverted Index
An inverted index is crucial for making search queries fast. For every unique term found in the document, the inverted index lists the documents in which the term appears. When you search, Elasticsearch doesn't look through every document. Instead, it consults this inverted index to determine which documents contain the terms in your query, drastically speeding up the search process.
Documents
Documents are JSON objects that contain the data you want to store in Elasticsearch. Think of a document as a more complex version of a dictionary or a JSON object. In the hospitality industry context, a single document could represent one hotel room's data, including attributes like room number, type, price, amenities, and availability status. Each document has unique metadata fields like index, type, and id that help identify its storage location and nature.
Fields
Fields are the smallest data unit in Elasticsearch, serving as key-value pairs within documents. Fields come in various datatypes, including core types like strings and numbers and complex and specialized types. Fields can be indexed in multiple ways, thanks to the "multi-fields" option, and some fields serve as metadata for documents, known as meta-fields.
By understanding these core concepts, you can better appreciate the scalability, robustness, and speed that Elasticsearch brings to data search and analytics.
Elasticsearch advantages
There are quite a few compelling benefits that Elasticsearch brings to the table, particularly regarding scalability, rich query language, and documentation. The following are the key advantages that make Elasticsearch a great choice for data search and analytics.
Scalability
Elasticsearch is built for scalability, enabling businesses to grow without worrying about data management constraints. One of the platform's core strengths lies in its distributed architecture, which means you can expand your Elasticsearch deployment across numerous servers to accommodate petabytes of data. As you add more servers or nodes to your Elasticsearch cluster, the system intelligently redistributes your data and query load, optimizing performance and resilience.
Elasticsearch's flexible infrastructure can adapt to changing needs by automatically migrating shards to balance the cluster as it grows or shrinks. This automatic rebalancing ensures that your application remains highly available without requiring manual adjustments. Also, you can modify the number of replica shards at any time without disrupting your ongoing operations, allowing you to adapt to changing performance needs.
Speed and performance
Speed and performance are foundational to Elasticsearch's appeal, setting it apart from traditional data storage and retrieval systems. A critical technology underpinning its swift query times is an inverted index that catalogs all unique words in documents along with their locations. With its distributed architecture that allows for parallel query execution across multiple shards, Elasticsearch delivers impressively rapid search responses. For instance, in real-world applications with more than 2 billion documents indexed, retrieval speeds have been reported to remain consistently under one second. This remarkable efficiency is a game-changer compared to traditional batch processing engines like Hadoop, enabling real-time analytics and insights.
Advanced query flexibility and real-time analytics
One of the standout advantages of Elasticsearch is its highly flexible Query API, which integrates both search and real-time analytics. The platform uses a JSON-based RESTful API, allowing straightforward data indexing and efficient execution of complex queries. Features like filtering, sorting, pagination, and aggregations are seamlessly supported in a single query. Moreover, Elasticsearch's robust analytics engine enables nuanced data analysis, such as nested aggregations that can group users by multiple criteria like city and gender and then calculate the average age for each group. This level of analytical granularity makes Elasticsearch ideal for a wide array of data-intensive applications.
An active and growing community
One of the significant advantages of Elasticsearch is its thriving and enthusiastic community, which serves as a vital resource for developers and users alike. With an active discussion forum boasting 129,375 users, community members can easily find answers to their questions across various topic categories and tags. The rapid response time, with questions often answered in approximately an hour, testifies to the high level of the community's engagement.
For real-time interaction, Elastic also offers a Slack channel, making it easier to get quick help or to discuss topics in depth. Beyond forums and chats, Elastic has institutionalized community involvement through the Elastic Contributor Program. This program recognizes and rewards contributions and fosters knowledge sharing and friendly competition within the community.
Additionally, the vast repository of 58,061 Elasticsearch-related questions on Stack Overflow offers many user experiences and problem-solving insights. Finally, the Elastic project on GitHub is another testament to its community strength, boasting over 65k stars and involving more than 1.8k contributors. This active and growing community provides invaluable support, making it easier for newcomers to adapt and for experienced users to excel.
Integrated solutions
Elasticsearch excels in its ability to integrate seamlessly with various data sources. You can stream logs, metrics, and other data from your apps, endpoints, and infrastructure, whether cloud-based, on-premises, or a mix of both. With native integrations for major cloud platforms like AWS, Azure, and Google Cloud, sending data to Elastic Cloud is straightforward. Its turn-key solutions further simplify data ingestion from multiple sources, including security systems and content repositories. This means that Elasticsearch can be easily integrated into different modern data stacks.
Built-in fault tolerance and recovery mechanisms
With its distributed architecture, Elasticsearch automatically replicates data to prevent loss in case of hardware failures. Each document in an index belongs to a primary shard, and replica shards act as copies of these primary shards, enhancing both data availability and query capacity. In the event of a node failure, Elasticsearch's recovery mechanisms kick in to ensure that data is not lost and operations continue smoothly, providing enterprises with a highly resilient data storage and search solution.
Compatibility with multiple languages
The last but not least advantage of Elasticsearch is its robust multilanguage support, which makes it an incredibly versatile tool for developers. Built upon a NoSQL database framework and enriched with powerful search and analytics capabilities, Elasticsearch provides client libraries in many programming languages, including but not limited to Java, JavaScript, PHP, C#, Ruby, and Python.
This wide-ranging language support simplifies the integration process and enables developers to leverage the platform's features regardless of their programming language of choice. As a result, teams can easily collaborate and build on Elasticsearch without facing language-specific constraints, further broadening its appeal and utility across various software development ecosystems.
Elasticsearch disadvantages
While Elasticsearch's features and capabilities are highly regarded, it's crucial to understand that, like any technology, it has limitations. Knowing these shortcomings can help you decide whether Elasticsearch is the right fit for your specific use case.
Resource intensive tool
While Elasticsearch excels in speed and performance, it's important to note that it can be CPU-intensive, especially when handling multiple tasks like indexing, searching, and aggregating data concurrently. The software's computational demands mean that a sufficient number of CPU cores will be needed to operate efficiently. The exact number of cores required can vary depending on your specific workload and use case, so resource planning is an important consideration when deploying Elasticsearch.
Hard learning curve
Elasticsearch offers a rich set of features and functionalities, but tapping into its full potential can require overcoming a steep learning curve. According to user reviews, the query mechanism can be complex to grasp, especially for those not well-versed in SQL or database concepts. The architecture itself can also present challenges in setup and optimization.
Furthermore, mastering Elasticsearch's specialized query language necessitates a deep understanding of elements like analyzers and tokenizers. While the platform is incredibly powerful, beginners may find it daunting to get started, and even experienced developers might need time to familiarize themselves with the system's intricacies.
Inconsistent and incomplete documentation
While Elasticsearch boasts of a robust set of features, its documentation often falls short of expectations. Users frequently point out that the material can be inconsistent and incomplete, especially regarding best practices for specific components. Beginners find the lack of comprehensive tutorials challenging, and even experienced developers note the absence of detailed examples for advanced functionalities.
Documentation gaps, including hardware configuration and capacity planning at scale, exacerbate the product's steep learning curve. The extensive documentation requires significant improvement to be truly useful for developers at all levels.
Complex licensing and unclear costs
The intricacies of Elasticsearch's licensing model can present challenges for organizations, particularly those intending to incorporate it as an embedded feature in their products. The evolving licensing terms may raise questions and demand a thorough understanding to ensure proper adherence to its guidelines. The platform's licensing can be complicated for those who aim to incorporate Elasticsearch without explicitly revealing its utilization, necessitating careful examination to avoid unintentional noncompliance.
Regarding the cost structure, the varied pricing models and additional features can render the total cost less transparent, requiring organizations to diligently evaluate what exactly is included in their pricing plan to avoid unforeseen expenses.
Elasticsearch alternatives
While Elasticsearch is a leading search and analytics engine, it's not the only option available. Different use cases or preferences may lead you to consider alternatives like Apache Solr or Algolia. Below is a brief comparison of these two alternatives to Elasticsearch.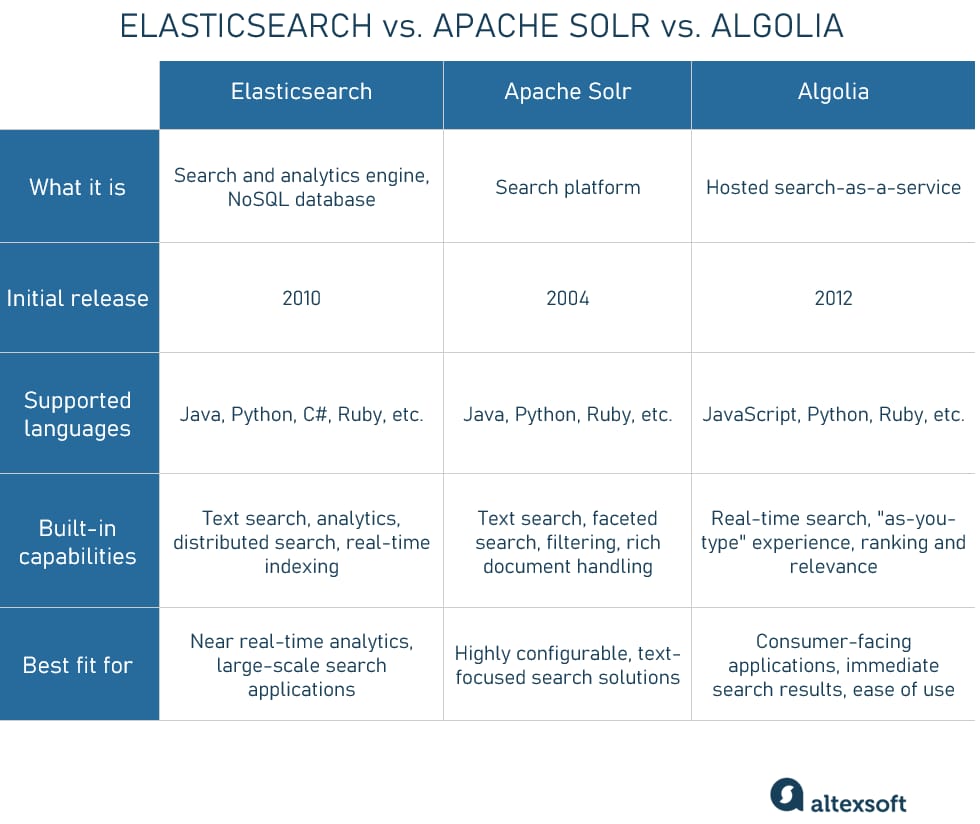
Elasticsearch vs. Apache Solr vs. Algolia comparison.
Apache Solr
Apache Solr is a project from the Apache Software Foundation and is a powerful search platform built on Apache Lucene. Like Elasticsearch, Solr is designed for scalability and boasts fault-tolerant distributed search capabilities.
Solr's core offerings include faceted search, filtering, and rich document handling. Unlike Elasticsearch, which is more often recognized for its real-time analytics capabilities, Solr has traditionally focused on text search functionalities.
Solr is written in Java and offers extensive configuration options, allowing for more tailored search solutions. Its ecosystem includes features like SolrCloud for distributed storage and search functionality and a wide array of query parsers for advanced search operations.
If your primary requirement is a highly configurable, text-focused search engine, Apache Solr could be an excellent alternative to Elasticsearch.
Algolia
Algolia is a Search-as-a-Service solution known for its ease of use and real-time capabilities. It is a fully managed service, allowing users to avoid the complexities of setup and maintenance, focusing instead on utilizing its features to enhance their applications and services.
Algolia provides a highly responsive “as-you-type” search experience and is particularly effective for consumer-facing applications where immediate search results and performance are critical. Its API-first approach and SDKs in various languages like JavaScript, Python, and Ruby make it easy to integrate into existing or new projects.
However, Algolia is not as feature-rich as Elasticsearch or Solr when it comes to analytics and data visualization capabilities. It's a more specialized tool focused on search functionalities and user experience.
How to get started with Elasticsearch: Tutorial
If you're intrigued by the world of search engines, real-time analytics, and data visualization, Elasticsearch could be a crucial addition to your toolkit. According to the Stack Overflow 2023 Developer Survey, Elasticsearch consistently ranks among the most popular search engines and analytics tools, demonstrating the high demand for professionals skilled in this technology. Mastering Elasticsearch could not only advance your technical prowess but also be a profitable career move.
Helpful skills
Before diving into Elasticsearch, it's beneficial to have some foundational skills that can make your journey smoother:
- JSON understanding: Elasticsearch leverages JSON for data representation, so a basic understanding of JSON is advantageous.
- RESTful API: Familiarity with RESTful APIs will make it easier to interact with Elasticsearch, which primarily uses it for operations.
- Basic programming: While Elasticsearch can be used without extensive coding, having basic knowledge in a programming language like Python, Java, or JavaScript will be helpful.
- Understanding of distributed systems: Knowing the basics of distributed computing can be an asset, as Elasticsearch is designed as a distributed search engine.
Once you are armed with these foundational skills, the next step is to explore Elasticsearch.
Training and certification
Numerous resources can guide you through your Elasticsearch learning path. You can opt for official Elasticsearch documentation, enroll in online courses, or learn from community tutorials.
Here are some course recommendations.
- Complete Elasticsearch Masterclass with Logstash and Kibana on Udemy covers everything from the basics to advanced features.
- Database Architecture, Scale, and NoSQL with Elasticsearch on Coursera covers PostgreSQL architecture and the differences between SQL and NoSQL while also providing hands-on experience in creating and utilizing an Elasticsearch index.
- Elastic Stack Essentials on Pluralsight offers a comprehensive look at the entire Elastic Stack.
To validate your skills and improve your professional standing, consider obtaining an Elasticsearch certification. Some noteworthy options include:
- Elastic Certified Engineer: This certification by Elastic proves your skills in data ingestion, data transformation, data storage, and more.
- Elastic Certified Analyst: This is aimed at professionals using Kibana for data visualization.
Remember, mastering any technology is a matter of practice and ongoing learning. Start with simpler projects and scale up as you get more comfortable.
This post is a part of our “The Good and the Bad” series. For more information about the pros and cons of the most popular technologies, see the other articles from the series:
The Good and the Bad of Kubernetes Container Orchestration
The Good and the Bad of Docker Containers
The Good and the Bad of Apache Airflow
The Good and the Bad of Apache Kafka Streaming Platform
The Good and the Bad of Hadoop Big Data Framework
The Good and the Bad of Snowflake
The Good and the Bad of C# Programming
The Good and the Bad of .Net Framework Programming
The Good and the Bad of Java Programming
The Good and the Bad of Swift Programming Language
The Good and the Bad of Angular Development
The Good and the Bad of TypeScript
The Good and the Bad of React Development
The Good and the Bad of React Native App Development
The Good and the Bad of Vue.js Framework Programming
The Good and the Bad of Node.js Web App Development
The Good and the Bad of Flutter App Development
The Good and the Bad of Xamarin Mobile Development
The Good and the Bad of Ionic Mobile Development
The Good and the Bad of Android App Development
The Good and the Bad of Katalon Studio Automation Testing Tool
The Good and the Bad of Selenium Test Automation Software
The Good and the Bad of Ranorex GUI Test Automation Tool
The Good and the Bad of the SAP Business Intelligence Platform
The Good and the Bad of Firebase Backend Services
The Good and the Bad of Serverless Architecture