

Steve Jobs once said, “People don’t know what they want until you show it to them.” Well, try arguing that considering that we all watch videos suggested by YouTube, buy goods suggested by Amazon, and watch TV shows suggested by Netflix. People like being guided and given relevant offers and recommendations. They like being treated in a personal manner. The truth is, 91 percent of consumers are more likely to go with brands that provide exclusive customer experiences. But how to start personalizing product and content offers? And what does machine learning have to do with it?
In this article, we’re taking you down the road of machine learning-based personalization. You’ll encounter the types of recommender systems that exist, their differences, strengths, and weaknesses, complete with real-life examples.
Personalization and recommender systems in a nutshell
According to Todd Yellin, Netflix’s vice president of product innovation, “Personalization is about creating the right connection between a viewer and their content.”
In other words, personalization is the way to match the right types of services, products, or content to the right users. When approached appropriately, it helps improve user engagement — any interactions people have with a product, website, app, etc.
These days, the true power of customer experience personalization can be realized with the help of machine learning. By utilizing ML algorithms and data, it is possible to create smart models that can precisely predict customer intent and as such provide quality one-to-one recommendations.
At the same time, the continuous growth of available data has led to information overload — when too many choices complicate decision-making. Primarily developed to help users deal with the large range of choices they encounter, recommender systems come into play.
Recommender systems, also known as recommender engines, are information filtering systems that provide individual recommendations in real-time. As powerful personalization tools, recommendation systems leverage machine learning algorithms and techniques to give the most relevant suggestions to particular users by learning data (e.g., past behaviors) and predicting current interests and preferences.
By the way, we have an expert video about recommender systems on our YouTube channel. Check it out too if the topic arouses your interest.


Recommender systems explained
These systems may provide such recommendations as:
- product recommendations (e.g., Amazon, Booking.com) and
- content recommendations (e.g., Netflix, Spotify, TikTok, Instagram).
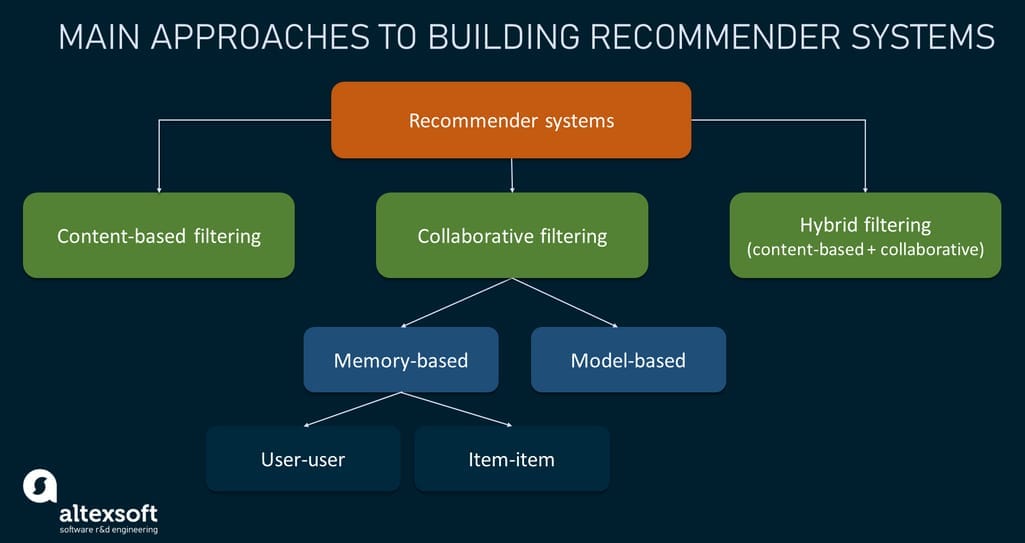
Main approaches to building recommender systems
Based on the methods and features used to predict what items users would prefer, there are three main approaches to building recommender systems, namely:
- content-based filtering, which generates predictions by analyzing item attributes and searching for similarities between them;
- collaborative filtering, which generates predictions by analyzing user behavior and matching users with similar tastes; and
- hybrid filtering, which combines two or more models.
Whatever the recommender system, its main goals are to keep users engaged, populate products or content, simplify decision-making, and eventually stimulate demand. So, let’s look at each type of recommender system in more detail.
Content-based filtering
The content-based filtering (CBF) model provides recommendations using specific attributes of items by finding similarities. Such systems create data profiles relying on description information that may include characteristics of items or users. Then the created profiles are used to recommend items similar to those the user liked/bought/watched/listened to in the past.
Content-based filtering example
If we talk about movie recommendations, for example, the attributes may be the length of a film, its genre, cast, director, and so on.
Say, a user has watched such movies as “Heat,” “Goodfellas,” and “The Irishman.” A content-based system will probably provide the user with recommendations like:
- more crime dramas,
- more Al Pacino movies,
- more Robert De Niro movies,
- more Joe Pesci movies, and
- more movies directed by Martin Scorsese.
This is just an approximate list, of course. Once the user makes choices, the recommender system can give more tailored results.
Jumping into practical examples, Pandora — a subscription-based music streaming service — leverages the content-based filtering model to recommend songs to users. They call their recommendation approach the Music Genome Project, in which songs are classified based on a set of their genes (musical traits). There are approximately 450 genes to represent every track. Each gene comes with a specific music characteristic like the electric guitar distortion level, lead vocalist timbre, etc. All these characteristics are mapped out manually by professional musicians, so the system can have enough genes (attributes) to render relevant results.
So, the key point of content-based filtering is the assumption that if users liked some items in the past, they may like similar items in the future. Of course, this approach has its strengths and weaknesses.
Content-based filtering strengths
Being quite simple by nature, the content-based filtering technique boasts some considerable advantages.
No cold start for new items. The cold start problem refers to the situation when a recommender system doesn't have enough information about new users or new items to draw any recommendations. The content-based systems can partially solve the cold-start problem for items since the content attributes of items are already available. E.g. if you’re selling mobile phones, you know the brands, screen sizes, memory, and other content features.
User independence. The content-based recommendation systems are user-independent as they are based on item representation. As a result, such systems don’t suffer from the data sparsity problem — the situation when users interact with only a small part of items or when there aren’t enough users.
Transparency. Systems use the same content, so they provide transparent explanations of how recommendations are generated to users.
Content-based filtering weaknesses
At the same time, content-based systems suffer from different problems, including over-specialization and limited content analysis.
Over-specialization. CBF systems pick similar items for users and it often leads to over-specialization in recommendations. Users are limited to items similar to those they have previously consumed.
Difficulties with extracting content features. Content-based systems largely depend on the metadata of items. But extracting rich features that can guide someone's choice is a complex, labor-intensive task.
Let’s get back to the movie recommendation example we provided earlier. Just because you may watch one crime drama doesn’t mean that you only want to watch crime dramas. Neither does it mean that you apriori enjoy all the De Niro movies. Yes, you may stand in front of a mirror repeating the famous “You talkin’ to me?” line from “Taxi Driver” over and over again but still hate lame 2010s comedies featuring him.
Taking into account all the pros and cons, it’s fair to say that content-based filtering models fill the bill when there isn’t enough interaction data. However, making predictions solely based on specific user’s or item’s characteristics typically ignores contributions from other users. That’s when collaborative filtering is needed.
Collaborative filtering
The most commonly implemented model, collaborative filtering (CF) provides relevant recommendations based on interactions of different users with target items. Such recommender systems gather past user behavior information and then mine it to decide which items to display to other active users with similar tastes. This can be anything from songs users listened to or products they added to a cart to ads users clicked on and movies they previously rated, etc. The idea of such a system is to try to predict how a person would react to items that they haven't interacted with yet.
How collaborative filtering sets a problem
For example, there are two users with quite similar interests in books. User X enjoys George Orwell's 1984, Aldous Huxley's Brave New World, and John Steinbeck's Of Mice and Men, while user Y likes Jack Kerouac's On the Road in addition to Orwell and Steinbeck. As far as collaborative filtering, there’s a good chance that user X would like Kerouac and Y would enjoy Huxley. Of course, we simplified the principle of collaborative filtering in this example. In reality, such systems examine the interactions of millions of users.
Collaborative filtering techniques can be categorized as memory-based and model-based.
Memory-based
The memory-based CF method relies on the assumption that predictions can be made on the pure “memory” of past data. It uses the past ratings to predict the preferences of one user by searching for similar users, or the “neighbors” that share the same preferences. That is why the method is sometimes referred to as neighborhood-based.
Well known for its relative effectiveness and easy implementation, memory-based CF is limited in terms of recommendation variety. It’s unlikely to provide real-time recommendations or those not so popular among users.
There are two ways to achieve memory-based collaborative filtering — through item-item and user-user CF techniques.
Item-item collaborative filtering makes predictions based on the similarities between items that users have previously rated. Simply put, users get recommendations of items that are similar to the ones they already rated taking into account ratings given by all users.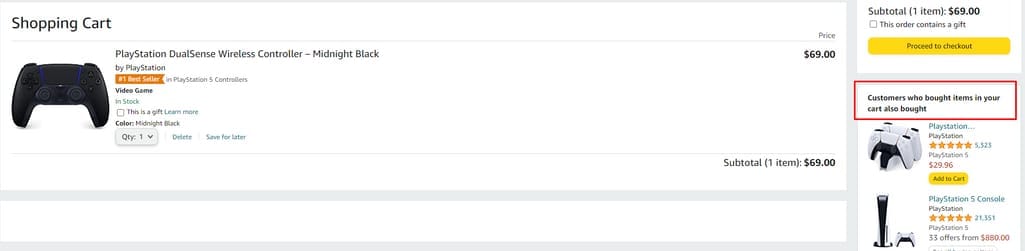
Amazon’s “Customers who bought items in your cart also bought” recommendations are an example of item-item collaborative filtering. Source: Amazon.com
Amazon, for example, developed its own item-to-item collaborative filtering that focuses on finding items similar to those a user purchased or rated, aggregating them, and producing real-time recommendations. An example would be their shopping cart recommendations — product suggestions are generated based on the items in the customer’s cart.
User-user collaborative filtering compares how different users rate the same items and in that way calculates the similarity of their tastes. So, instead of getting recommendations for items having the best ratings, users are grouped in clusters of people with similar interests and get content based on their historic choices. As opposed to item-based CF, such a technique provides more personalized results.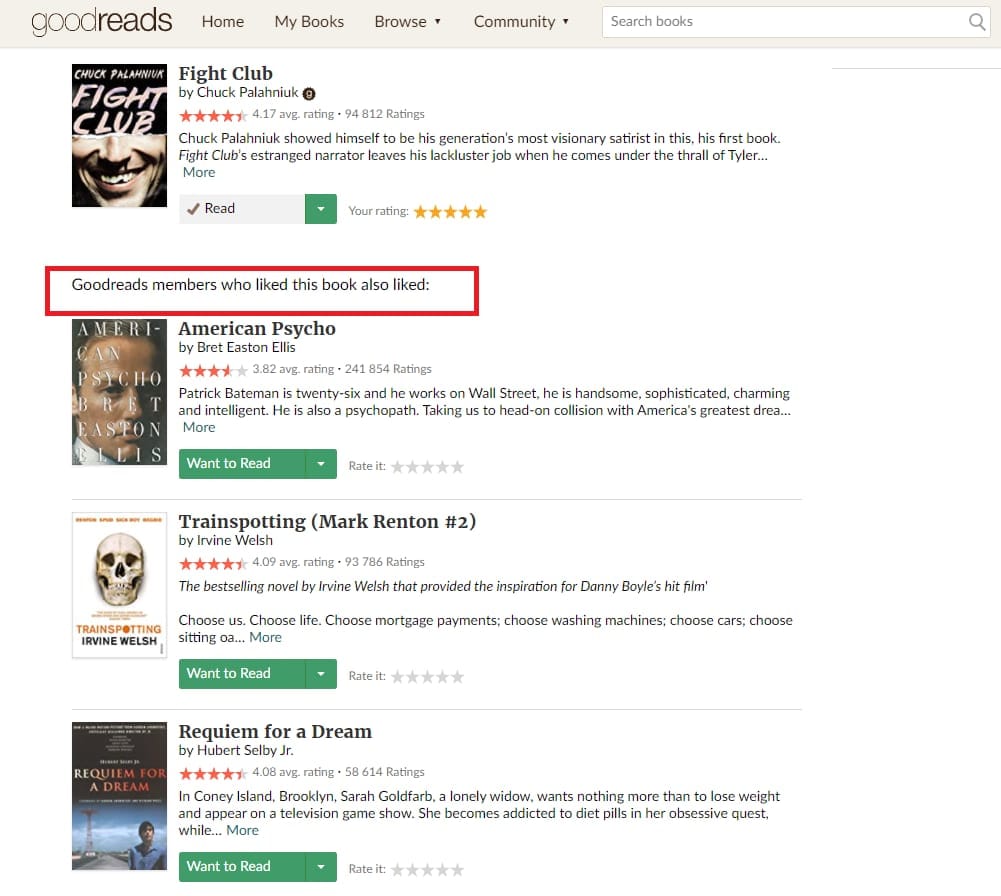
Goodreads leverages user-user collaborative filtering for making book recommendations. Source: Goodreads
For example, when you rate Chuck Palahniuk’s Fight Club on Goodreads, the service will recommend you the top-ranked books from the lists of readers who also liked Fight Club.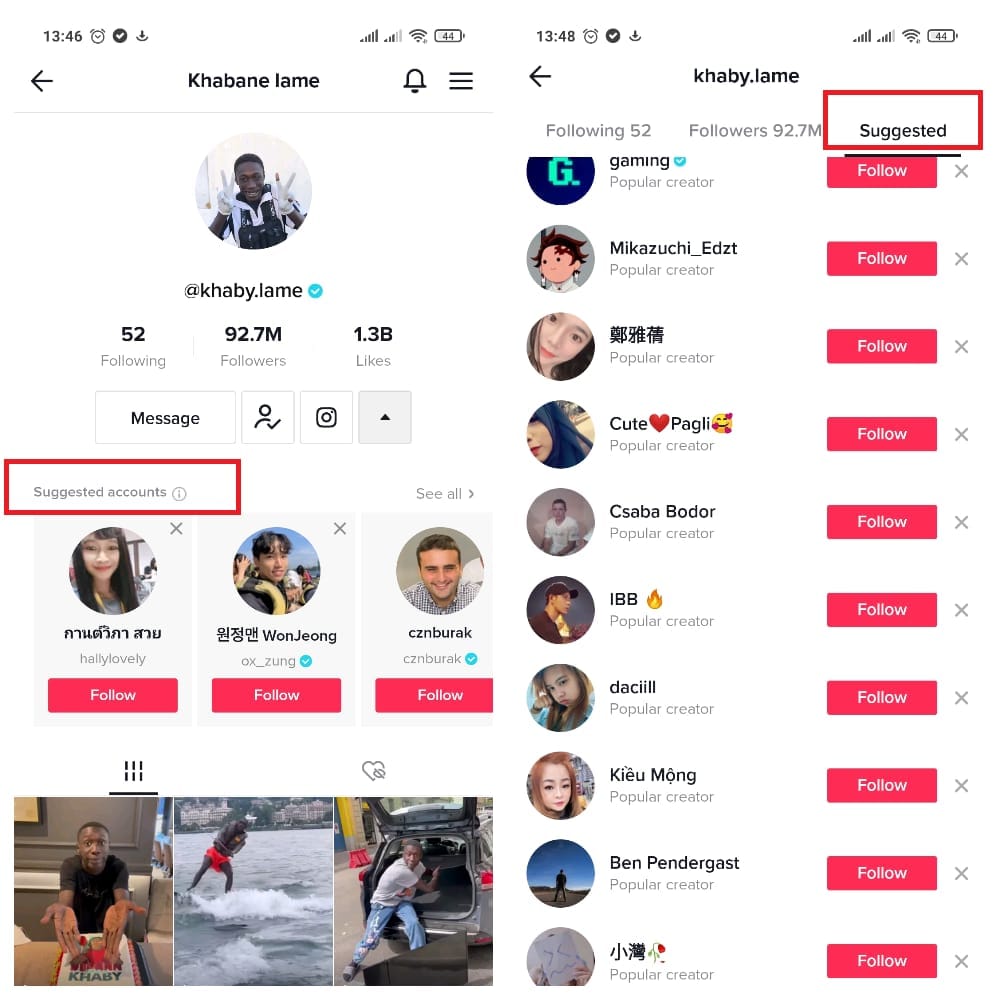
TikTok uses collaborative filtering to suggest accounts to follow. Source: TikTok
TikTok – the China-based social media platform popular with teenagers – recommends accounts to follow with the help of user-centered modeling. Here’s how it works: If you follow accounts X and Y, the system will look at all other users who also follow the same accounts and select relevant suggestions of new accounts based on the overlap between the users who have similar interests to yours.
Model-based
Another way to look at collaborative filtering is the model-based approach. This type of CF uses machine learning or data mining techniques to build a model to predict a user’s reaction to items. The memory-based algorithms we discussed earlier perform computations across the entire database of all known preferences of users for all items. As opposed to that, model-based algorithms first assemble the preferences of users into a detailed ML model of users, items, and ratings and then use it to generate recommendations. The model-based method allows for finding the underlying patterns in data, which adds value beyond the model’s predictions. The techniques used to build models include matrix factorization, deep neural networks, and other types of ML algorithms.
Matrix factorization is a class of collaborative filtering algorithms used to represent data about ratings and interactions as a set of matrices. One big matrix is decomposed into two smaller matrices — one with items’ features and one with features representing how much the user prefers this or that item feature.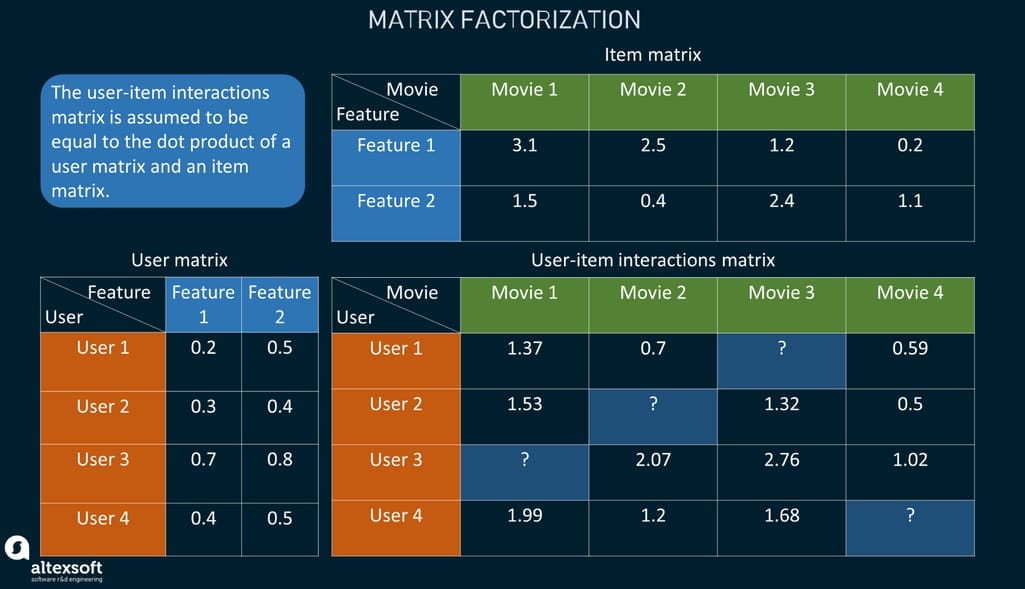
Matrix factorization
The essence of the approach is to predict all the unknown values within the user-item matrices using the existing values and taking into account probable errors. The model learns to predict item and user features given the existing data on other movies and users. Once it knows the values that populate item and user matrices, it can arrive at the dot product (multiplication of both matrices) that defines how likely a user will enjoy a content piece or buy this product.
In terms of classic matrix factorization, the approach has its limitations as it’s difficult to use any side features except for the features of users and items. It’s worth noting though that there are some advanced matrix factorization modifications, in which this problem is solved. Another issue with matrix factorization is that it tends to recommend popular features to everyone.
The algorithm was a result of the 2009 Netflix Prize competition, and it is still one of the most popular filtering approaches in this field.
Deep neural networks are the most sophisticated approach that can be used to address the limitations of matrix factorization. It allows for modeling the nonlinear interactions in the data and finding hidden patterns in the data that couldn’t otherwise be discovered.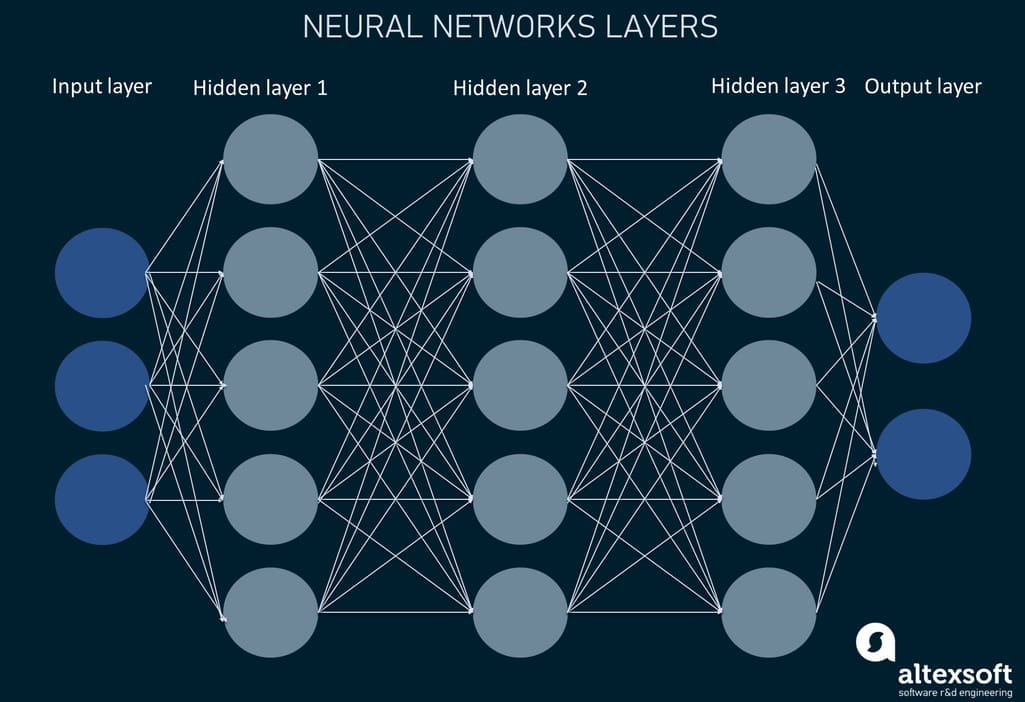
Neural networks architecture layers
Resembling the way the human neural system works, deep neural networks consist of neurons (nodes) residing in different interconnected layers (input layer, a number of hidden layers, and output layer). Deep neural nets can be trained to extract features right from the content (video, text, audio, or image) and/or make recommendations.
YouTube, for example, uses Google Brain — an Artificial Intelligence system — to drive relevant recommendations of its videos. The recommender system consists of two neural networks: one for candidate generation that takes users’ watch history as input and uses collaborative filtering for video selection and the second for ranking hundreds of videos in order.
Collaborative filtering strengths
Collaborative filtering has some considerable advantages over content-based filtering.
No domain knowledge is required. Collaborative filtering doesn’t rely on content that much, so it can perform in domains where content is difficult for a computer system to analyze (such as images, videos, music) and can also provide cross-domain recommendations.
Surprising recommendations. Instead of recommending the same content, the model helps discover new interests that users wouldn’t otherwise come across.
Flexibility. Users’ interests are unstable and unpredictable. As opposed to focusing solely on content, CF focuses on user personas and provides great flexibility and adaptivity to the change in their preferences.
Collaborative filtering weaknesses
Although collaborative filtering looks like a perfect solution to build recommender systems, the approach has a couple of major limitations — cold start and data sparsity.
Cold start. Since recommender engines that run on collaborative filtering rely on user actions to make suggestions, they can’t serve new users relevant personalized content. This is due to a lack of prior information about user interactions. As well as that it is problematic for such systems to recommend new items as they have none to very few interactions.
Data sparsity. There are certain items that are left untouched by users, so pure collaborative recommender systems don’t get enough data to match users and content, leading to the emptiness of interaction known as the sparsity problem.
Hybrid filtering
Hybrid filtering was created to cure the issues and limitations of pure recommendation system models. The hybrid models utilize multiple recommendation techniques under one roof to gain the higher accuracy of recommendations with fewer cons of any individual one. As a rule, it is collaborative filtering that gets mixed with other techniques in an effort to overcome the cold start problem. But not exclusively as approaches may be combined in different ways.
The truth is, pretty much all modern recommender system implementations are hybrid.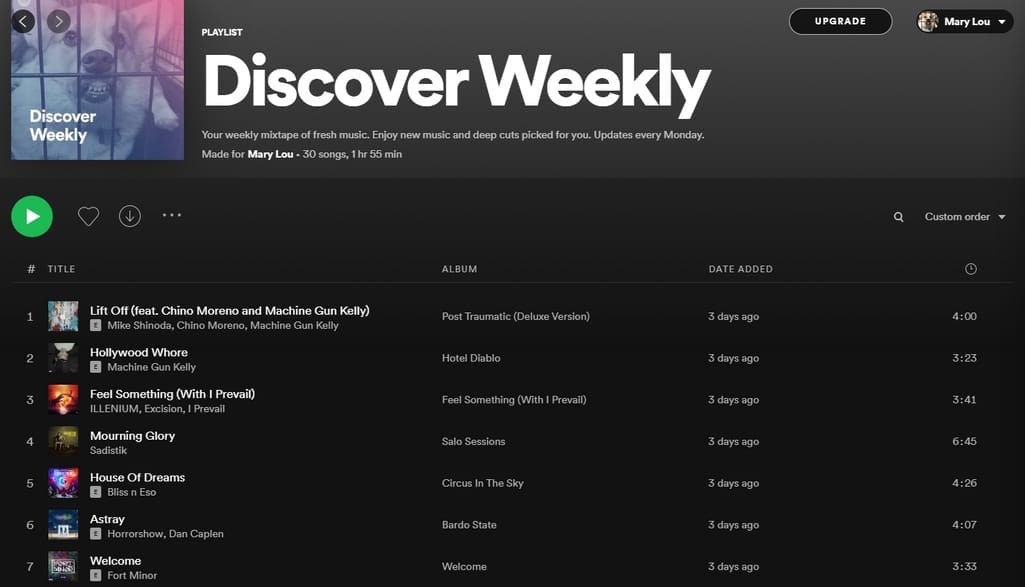
Spotify combines different recommendation models for creating its Discover Weekly mixtape. Source: Spotify
Spotify’s Discover Weekly is a great example of a hybrid recommendation engine that is built upon three models, namely:
- collaborative filtering — collecting and analyzing the listening behaviors of different users and then making clusters of users with similar music tastes,
- content-based filtering — using content attributes such as descriptions of artists and songs, and
- audio analysis — extracting features from the raw audio files using machine learning.
Thanks to content features and audio features Spotify manages to deal with the cold start problem — when there are few people listening to a song or when a song is new. The audio analysis allows for drawing out key song characteristics such as tempo, chords, time signature, etc., and then using these metrics to group songs including new ones. Also, Spotify utilizes Natural Language Processing (NLP) to draw insights about songs and artists based on public sentiment. In this way, each artist and song have a list of terms related to them. These terms are then used to determine the relationships between different pieces of music content and help "warm" cold start.
Personalized content playlists generated by Netflix recommendation algorithms. Source: Medium
{kind=link}
Netflix's personalized playlists are also possible owing to the hybrid approach that combines both
- content-based filtering — recommendations of shows and movies that share common characteristics, e.g., genre — and
- collaborative filtering — recommendations based on similarities of users' viewing and searching habits.
The leading media streaming service says 80 percent of its watched content is based on algorithmic recommendations.
How recommender systems work: data processing phases
Any modern recommendation engine works using a powerful mix of machine learning technology and data that fuels everything. Google singles out four key phases through which a recommender system processes data. They are information collection, storing, analysis, and filtering. Let’s have a closer look at each phase.
Data collection
The initial phase involves gathering relevant data to create a user profile or model for prediction tasks. The data may include such points as the user's attributes, behaviors, or content of the user accesses’ resources. Recommendation engines mostly rely on two types of data such as:
- explicit data or user input data (e.g., ratings on a scale of 1 to 5 stars, likes or dislikes, reviews, and product comments) and
- implicit data or behavior data (e.g., viewing an item, adding it to a wish list, and the time spent on an article, etc.).
Implicit data is easier to collect as it doesn't require any effort from users: You can just keep user activity logs. Though such data is more difficult to analyze. On the other hand, explicit data requires more effort from users, and they aren't always ready to provide enough information. But such data is more accurate.
Also, recommender systems may utilize user attribute data such as demographics (age, gender, nationality) and psychographics (interests) as well as item attribute data (genre, type, category).
Data storing
When explaining how data is prepared for machine learning, we’ve pointed out the importance of having enough data to train a model. The more quality data there is to feed algorithms with, the more effective and relevant recommendations they will provide.

Data preparation, explained in 14 minutes
The next step involves selecting fitting storage that is scalable enough to manage all the collected data. The choice of storage depends on the type of data you’re going to use for recommendations in the first place. This can be a standard SQL database for structured data, a NoSQL database for unstructured data, a cloud data warehouse for both, or even a data lake for Big Data projects. Or you may use a mix of different data repositories depending on the purposes. You can learn more in our dedicated article about a machine learning pipeline.
Data analysis
Data is only useful when it’s thoroughly analyzed. There are different types of data analysis based on how quickly the system needs to produce recommendations.
- Batch analysis means that data is processed and analyzed in batches – periodically. This can be the analysis of daily sales data.
- Near real-time analysis means that data is processed and analyzed every few minutes or seconds but not in real time. These can be recommendations generated during one browsing session.
- Real-time analysis means that data comes in streams and gets processed and analyzed as it is created. As a result, a system makes real-time recommendations.
Data filtering — applying algorithms to make recommendations
When building a recommender system, an important aspect is to pick the most appropriate filtering approach (we described them above) and implement the right algorithm to train a model. The algorithms can be simple like the ones to measure the distance between similar items or more complex and resource-heavy ones.
What does the future hold for recommender systems?
Recommender systems have come a long way from their humble beginnings with much more on the horizon. Many machine learning engineers and data scientists are confident that the future of recommender systems is in artificial intelligence in general and deep learning in particular.
The idea of having an intelligent system that can think like a human, learn like a human, and recommend useful stuff like a human (or even better) has many applications. Yet the primary appeal lurks in the opportunities to get higher customer engagement and conversion.
A lot of research is already dedicated to deep learning and the advancements it can bring to recommender systems. This field is thought to be further explored in the future. Companies like YouTube are actively investing in the research of deep learning and applying it to personalize their offers.
An interesting trend in the world of recommendation systems is applying a reinforcement machine learning approach by showing customers sub optimal recommendations and recording their reactions. This will allow keeping the balance between content exploration and use. The great thing about using reinforcement learning in creating recommender systems is that the algorithm may not only suggest to users the content they may find most useful but also open new horizons by providing some random recommendations.