

There is nothing particularly unlucky about the number 13. Unless you meet it in the article that discloses that “only 13 percent of data science projects... make it into production.” This sounds really ominous — especially, for companies heavily investing in data-driven transformations.
The bright side is that no initiative is initially doomed to fail. New approaches arise to speed up the transformation of raw data into useful insights. Similar to how DevOps once reshaped the software development landscape, another evolving methodology, DataOps, is currently changing Big Data analytics — and for the better.
What is DataOps: a brief introduction
DataOps is a relatively new methodology that knits together data engineering, data analytics, and DevOps to deliver high-quality data products as rapidly as possible. It covers the entire data analytics lifecycle, from data extraction to visualization and reporting, using Agile practices to speed up business results.
The shorthand for data and operations was first introduced in 2015 by Lenny Liebmann, former Contributing Editor at InformationWeek. In his blog post “DataOps: Why Big Data Infrastructure Matters,” Lenny describes the new concept as “the discipline that ensures alignment between data science and infrastructure.”
Gartner broadens the initial definition to “a collaborative data management practice focused on improving the communication, integration, and automation of data flows between data managers and data consumers across an organization.” Whichever explanation you prefer, this doesn’t change DataOps objectives — building trust in analytics through better data quality and accelerating value creation in data-intensive projects.
To get a solid understanding of how DataOps achieves its goals, we must mention its close relatives — DevOps and MLOps.

How DataOps relates to Agile, DevOps, and MLOps.
DataOps vs DevOps
DataOps is inspired by the success of DevOps that enables companies to reduce a software release cycle from months to hours and minutes. Say, in 2013, Amazon jumped to 23, 000 deployments a day (one deployment every three seconds) and an average lead time of a few minutes for each update — all thanks to DevOps.

The table shows how DevOps helps tech giants accelerate deployment of updates with no loss in quality. Source : The Phoenix Project
DevOps, in turn, owes its breakthrough to Agile — an approach promoting small and frequent software releases instead of rare global changes. Seeking to speed up delivery of trustworthy data insights, DataOps takes the cue and incorporates Agile into data analytics. It also borrows some other best practices along with the overall mindset from DevOps, which we explained in our video.


DataOps can be a useful addition to DevOps, ensuring that an application is delivered with the right production data and is being tested against the right datasets.
DataOps vs MLOps
Another representative of the Ops family — MLOps — merges operations with machine learning. It applies DevOps patterns to automate the lifecycle of ML models, from their generation to deployment to retraining.

What MLOps has in common with DataOps.
Both DataOps and MLOps can be viewed as an extension of DevOps methodology in data science. DataOps covers data journeys from extraction to deployment analytics products. It may prepare quality datasets and features for machine learning algorithms but doesn’t offer solutions for training ML models and running them in production. That’s where MLOps steals initiative.
Shared Ops principles
No matter the implementation area, all Ops frameworks start with mindset shifts. DataOps sticks to the same values and principles as DevOps and MLOps namely:
- cross-functional collaboration,
- shared responsibility for outcomes,
- component reusability,
- pervasive automation,
- observability or the ability to track and measure results,
- learning from mistakes, and
- continuous improvement through multiple iterations.
DataOps adopts these fundamentals for the needs of data professionals and data analytics flows.
DataOps process structure
DataOps considers the end-to-end data analytics process as a sequence of operations — or a data pipeline. Each pipeline comprises multiple steps, starting with data extraction and ending with delivery of data products to be consumed by businesses or other applications.
All data operations run within a continuous integration / continuous delivery (CI/CD) workflow promoted by DevOps. It introduces automation throughout the entire lifecycle of the data analytics pipeline and into its individual segments to enable updates and ensure data quality at each step.

Data analytics pipeline exists within a CI/CD framework.
Data analytics pipeline: key stages
Data analytics pipelines can be very complex, embracing hundreds of procedures, but typically they can be split into four key stages.
Data ingestion. Data, extracted from various sources, is explored, validated, and loaded into a downstream system.
Data transformation. Data is cleansed and enriched. Initial data models are designed to meet business needs.
Data analysis. At this stage, data teams may understand that they need to collect more data to derive trustworthy conclusions. Otherwise, they produce insights using different data analysis techniques.
Data visualization/reporting. Data insights are represented in the form of reports or interactive dashboards.
Different teams conduct different stages of the data workflow pipeline. However, all individuals involved should share knowledge, learn from each other, and document how they achieve success.
CI /CD for data operations
As we mentioned above, DataOps puts data pipelines into a CI/CD paradigm. It suggests the same procedures as in DevOps, but with due regard to specificity of data analytics production.
Development. In DataOps, the step may involve building a new pipeline, changing a data model or redesigning a dashboard.
Testing. The DataOps framework fosters checking the most minor update for data accuracy, potential deviation, and errors. Testing of inputs, outputs and business logic should be performed at each stage of the data analytics pipeline, to verify that results of the particular data job meet expectations. For complex pipelines, this means myriad tests that should be automated where possible.
Deployment. This presumes moving data jobs between environments, pushing them to the next stage, or deploying the entire pipeline in production.
Monitoring. A prerequisite for data quality, monitoring allows data professionals to identify bottlenecks, catch abnormal patterns, and measure adoption of changes. Currently, monitoring often relies on AI-driven anomaly detection algorithms.
Orchestration. In the data world, orchestration automates moving data between different stages, monitoring progress, triggering autoscaling, and other operations related to the management of data flows. It covers each stage and the end-to-end data analytics pipeline.
DataOps people
DataOps breaks down organization silos, bringing together all data stakeholders and aligning them with business goals.

Data stakeholders uniting around business requirements.
The methodology builds the bridge between
- data managers — data architects, data engineers, ETL developers, and data stewards;
- data consumers — data analysts, data scientists, dashboard developers, BI teams, machine learning engineers and others who use data to deliver results via visualizations, APIs, ML models, applications or other mediums; and
- a DevOps team — software developers and IT operations professionals.
Each of these players contributes to the end-to-end process of data transformation — from raw pieces of information to analytics solutions for end customers. Getting settled into the DataOps environment, they work together to deliver valuable business insights faster.
Now that you have a general idea of DataOps principles, players and components, the question is: What makes the entire ecosystem work? Below, we’ll look at the core practices and technologies to put the concept into practice.
Best practices to support DataOps
Each organization develops a DataOps strategy in a slightly different way, making decisions on where to store data, how to use it, and which tools to opt for based on specific needs. However, there are recommended or even mandatory practices to follow — regardless of the business domain or company size.
Treat data as code
Software developers use version control systems to manage changes in source code. DataOps dictates treating data pipelines and datasets the same way which means versioning and storing them in a centralized repository. This ensures reproducibility of data flow components along with the ability to quickly roll back to a previous working state if something goes wrong.
Create a data catalog
A data catalog is a core aspect of data governance that brings data versioning and overall traceability of analytics flows to a new level. Acting as a library of existing data assets, the catalog contains data origins, usage information, metadata describing a particular data entity, and data lineages — or maps of data journey, from source to final destination, with all stops and alterations along the way.
Catalogs enable data professionals to easily find and understand datasets they need. This results in significant time savings along with improved speed and quality of insights. Besides that, data catalogs can prevent unauthorized data access and simplify compliance with GDPR and other data protection regulations.
Consider ELT
ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are two competing methods of moving data between systems — from a data source to a storage medium. The core difference lies in the point at which raw data is transformed. In the ETL scenario, modifications occur before loading. ELT copies data from numerous sources into a single repository in its original formats.
For decades, ETL prevailed over ELT because storage mediums couldn’t cope with the volume and complexity of raw data. So, businesses had to reshape, clean, and organize information before loading it.
Modern cloud data warehouses are much cheaper and faster than their predecessors. They handle both structured and unstructured data, making ELT an optimal choice for many DataOps projects — and here are key reasons why.
- ELT is faster and cheaper to run.
- ELT creates rich and easy-to-access pools of historical data, with no details missed during transformations. Businesses can use it anytime for analysis and generating BI.
- With ETL, transformations are owned by data engineers. In ELT, changes happen in the warehouse, where data analysts can also contribute to transformations writing them in SQL.
- You can design new data models multiple times without revising the entire pipeline.

ETL and ELT approaches to moving data.
There are still companies where ETL would be preferable. This includes cases when data is predictable, transformations are minimal, and required models are unlikely to change. ETL is also inevitable for legacy architectures and data workflows that must be transformed before entering the target system — say, when you have to delete personal identifying information (PII) to comply with GDPR.
However, with more organizations moving to the cloud, ELT gains greater popularity due to its agility, low price, and flexibility. The downside is that, as with any relatively new concept, ELT tools are often far from perfect, requiring a high level of expertise from your data team.
Build Directed Acyclic Graphs (DAG) for orchestration
To orchestrate pipelines, DataOps represents a sequence of steps that produces analytics as directed acyclic graphs or DAGs. This approach to data workflow management was first taken by Airbnb. In 2016, the company open-sourced their internal solution — Apache Airflow — enabling data engineers to create DAG objects using Python. Since then, many organizations have adopted the platform to schedule and automate data operations.

Visualizing of DAG dependencies in Apache Airflow.
Technologies to run DataOps
DataOps is still an emerging discipline, and so are the toolchains supporting it. The methodology mixes and matches DevOps tools with data engineering instruments and business intelligence tools.
Among preferred technologies are Git for version control and Jenkins for CI/CD practices. Similar to DevOps, DataOps accords well with microservices architecture, using Docker for containerization and Kubernetes for managing containers. For data visualizations, DataOps often utilizes Tableau. However, the core of the DataOps stack is made of data-specific solutions.
Data pipeline tools
The category embraces a large variety of instruments for creating, managing, and orchestrating data analytics pipelines and their stages. Many of them require knowledge of Python, Java, or other programming languages to write data workflows, SQL for data transformation, and R for data analysis.
Besides mentioned-above Apache Overflow, the list of solutions widely used in DataOps include
- Piperr, a suite of pre-built pipelines to run data integration, cleaning, and enrichment;
- Genie, an open-source engine designed by Netflix to orchestrate Big Data jobs;
- Apache Oozie, a workflow scheduler for Hadoop jobs;
- Prefect, a platform for data flow automation and monitoring;
- Pachyderm for data version control and data lineage; and
- dbt (data built tool), a development environment to write and execute data transformation jobs in SQL. In essence, dbt is the T in the ELT (extract, load, transform) process.
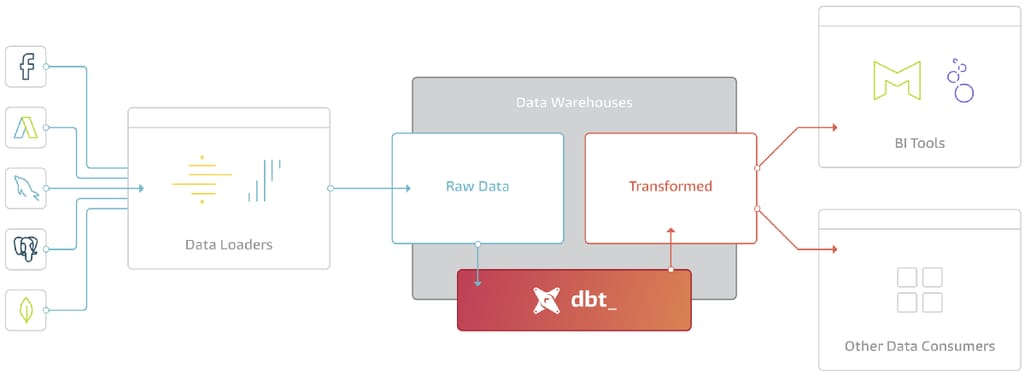

Here’s how dbt fits into data workflows. Source: Medium
Automated testing and monitoring tools
Testing is in the heart of the DataOps concept calling for continuous improvement of data quality. To ensure accuracy, engineers must run different tests including
- initial data testing,
- data structures testing (validating database objects, tables, columns, data types, etc.),
- ETL testing (if a company opts for ETL),
- integration testing verifying that all pipeline components work well together, and
- BI / Report testing.
A reliable automated test suite is key to making a go of analytics continuous delivery. Here are several platforms to consider.
iCEDQ connects with over 50 widely-used data sources to compare data across databases and files. It validates and verifies initial data, data structures, ETL processes, and BI reports. By integration with popular CI/CD and orchestration tools, the technology facilitates workflow management and deployment as well.
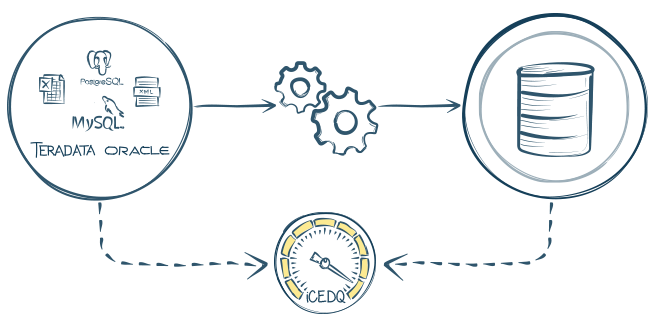
ETL testing with iCEDQ.
Naveego is a data accuracy solution that detects errors across all enterprise data sources. It teams up with Kubernetes, big data processing engine Apache Spark, and event streaming platform Apache Kafka for fast deployment and seamless integration of data, no matter its schema or structure. The platform cleans stored information to make it ready for analytics.
RightData supports numerous data sources, compares datasets between source and target, and alerts to errors. Users can create their own validation rules.
Databand tracks data quality metrics across files, tables, and pipeline inputs and outputs. It also monitors performance of workflows capturing deviations from baselines.
DataOps platforms
The technology discords can be unified via DataOps platforms that come pre-integrated with popular database management systems, Big Data ecosystems like Apache Hadoop or Databricks, Docker, and cloud platforms. Besides, they support a wide range of instruments — from Slack for team communication to Jenkins and Apache Airflow to programming languages.
DataKitchen is an enterprise-level DataOps platform that orchestrates all key operations, from data access to analytics delivery — providing the testing and monitoring of each step. The technology allows data professionals to develop and maintain pipelines with Python, create models in R, and visualize results in Tableau — all in one workspace. It also automates end-to-end ML pipelines and can be used for MLOps projects.
Saagie accelerates delivery of data projects via a Plug-and-Play orchestrator. Data professionals can create and manage data pipelines combining a range of pre-integrated tools and technologies. The platform also gives access to versioning, rollback, and monitoring capabilities.
StreamSets offers visual tools to build, execute, monitor, and optimize myriads of data pipelines. It speeds up big data ingestion and simplifies data transformation. With StreamSets this step doesn’t require coding skills. As the solution is infrastructure agnostic and legacy friendly, engineers can run projects in different environments, keeping data synchronized across platforms.
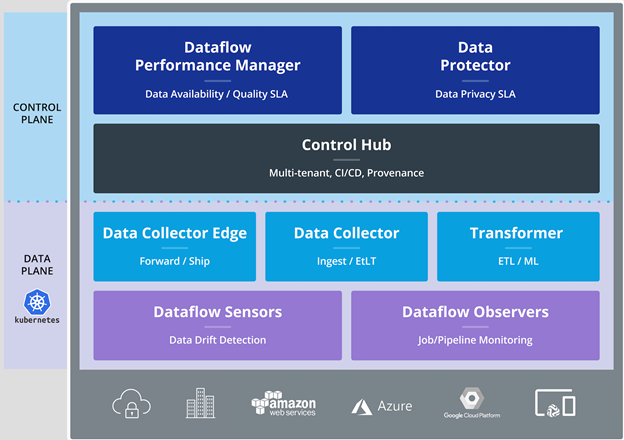
StreamSet DataOps platform structure.
DataOps implementation tips
Tools, however good they may be, are not enough to ensure the success of the DataOps initiative. You need to introduce cultural and organizational changes. Here are some tips for doing it wisely.
Choose the right time
For new data-intensive businesses, this means the adoption of DataOps principles and practices at early stages, so that they take root in the corporate culture. As for the established companies, the shift to the new framework makes sense when the need for rapid deployment towers over the cost of reorganization.
Make sure your staff has core competencies
You can’t promote DataOps without a strong knowledge of data-loading and data-testing best practices, data modeling techniques, and orchestration processes. Other important skills include experience with Git version control, CI/CD tools, containers, and databases. Many of DataOps activities revolve around Python and SQL. So, you need to identify knowledge gaps and initiate training or hire a person with the required expertise to strengthen your team.
Keep in mind that success may not come quickly
Application of Agile and DataOps principles to DataOps is a relatively new trend. It involves a great deal of research, experimentation, learning from failure, and switching tools or methods as you go. Effective automation of data operations will take time, and this endeavor should be supported by top-level executives.