

The listed terms while all interconnected can’t be used interchangeably. Whether you're a specialist interested in data-driven research, a business owner eager to make the most out of modern technology, or just someone who wants to be more tech-savvy, this article will help you understand not only what studies and expertise help extract knowledge from data to make machines more intelligent but how exactly they do that.
All data disciplines in a nutshell
Data science, data mining, machine learning, deep learning, and artificial intelligence are the main terms with the most buzz. So, before diving into detailed explanations, let’s have a quick read through all data-driven disciplines.
Data science disciplines illustrated by MRI image recognition.
Data science is the broad scientific study that focuses on making sense of data. Think of, say, recommendation systems used to provide personalized suggestions to customers based on their search history. If, say, one customer searches for a rod and a lure and the other looks for a fishing line in addition to the other products, there’s a decent chance that the first customer will also be interested in purchasing a fishing line. Data science is a broad field that envelops all activities and technologies that help build such systems, particularly those we discuss below.Data mining is commonly a part of the data science pipeline. But unlike the latter, data mining is more about techniques and tools used to unfold patterns in data that were previously unknown and make data more usable for analysis. Taking you back to the example with fishing supplies, data mining is about studying the last 2 years of data to find correlations between the number of sales of fishing rods before and during fishing seasons in shops located in different states.
Machine learning aims at training machines on historical data so that they can process new inputs based on learned patterns without explicit programming, meaning without manually written out instructions for a system to do an action. If it weren't for machine learning, the recommendation engines we already mentioned above would be out of reach as it is difficult for a human to process millions of search queries, likes, and reviews to discover which customers commonly buy rods with lures and which purchase fishing line on top of that.
Deep learning is the most hyped branch of machine learning that uses complex algorithms of deep neural networks that are inspired by the way the human brain works. DL models can draw accurate results from large volumes of input data without being told which data characteristics to look at. Imagine you need to determine which fishing rods generate positive online reviews on your website and which cause the negative ones. In this case, deep neural nets can extract meaningful characteristics from reviews and perform sentiment analysis.
Artificial intelligence is a complex topic. But for the sake of simplicity, let’s say that any real-life data product can be called AI. Let's stay with our fishing-inspired example. You want to buy a certain model fishing rod but you only have a picture of it and don't know the brand name. An AI system is a software product that can examine your image and provide suggestions as to a product name and shops where you can buy it. To build an AI product you need to use data mining, machine learning, and sometimes deep learning.


Data Science vs Machine Learning vs Artificial Intelligence vs Big Data explained in 6 minutes.
So, let’s recap. Data science has a more general use. It's a field of study just like computer science or applied math. Data mining is more about narrowly-focused techniques inside a data science process but things like pattern recognition, statistical analysis, and writing data flows are applicable inside both. Data science and hence data mining can be used to build the needed knowledge base for machine learning, deep learning, and consequently artificial intelligence.With this summary, we're moving to more descriptive definitions of terms along with revealing how they are related to one another.
What is data science?
Vasant Dhar, a professor at the Stern School of Business, offered the following definition:“Data science is the study of the generalizable extraction of knowledge from data”.
Though it is one of the most commonly used definitions of data science, it requires a more detailed explanation.
Data science is a constantly evolving scientific discipline that aims at understanding data (both structured and unstructured) and searching for insights it carries. Data science takes advantage of big data and a wide array of different studies, methods, technologies, and tools including machine learning, AI, deep learning, and data mining. This scientific field highly relies on data analysis, statistics, mathematics, and programming as well as data visualization and interpretation. Everything mentioned helps data scientists make informed decisions based on data and determine how to gain value and relevant business insights from it.
Data science process and use cases
Data scientists work with enormous amounts of data to make sense of it. With the right data analytics tools under the hood, data scientists can collect, process, and analyze data to make inferences and predictions based on discovered insights.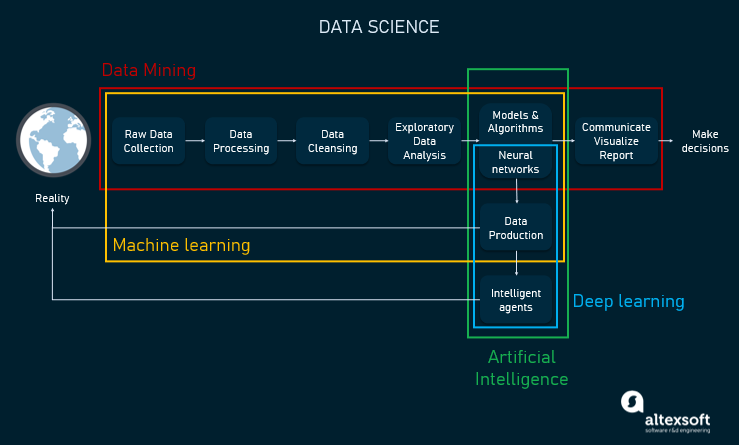
The illustration of relations between data science, machine learning, artificial intelligence, deep learning, and data mining.
For years, data science has been used effectively in different industries to bring innovations, optimize strategic planning, and enhance production processes. Huge enterprises and small startups collect and then analyze data to grow their businesses and hence increase revenue. The logic here is simple ‒ the more data you can collect and process, the greater the chance for you to draw meaningful insights from that data. With the help of predictive analytics, businesses can uncover data patterns they had no idea existed. One example of such applications include predictive lead scoring.For instance, a financial company may discover that clients who correctly capitalize letters are more trustworthy when it comes to repaying online loans.
Another popular data science use case is demand-supply forecasting. Consider a company that is engaged in the production of graphics cards. Let's assume that the company is aware of new popular game releases. They know the approximate dates, they also know which games require more powerful GPUs. The best case scenario for the company will be to complete accurate demand forecasting to predict future sales and optimally benefit. Data scientists first collect historical data, compare similar situations to the expected ones, make calculations, and plan on supply to cover demand.
What is data mining?
Data mining is a basket of techniques and tools widely used by scientists and researchers to extract new and possibly insightful information from large sets of previously unknown data and transform it into digestible structures for future use. At the base of modern data mining technologies, there is a concept of finding hidden patterns and oddities that reflect the multifaceted relationships in raw data.Data mining process and use cases
The process of data mining consists of two parts that are called data pre-processing and actual data mining. The first one encompasses such steps as data cleansing, data integration, and data transformation while data mining is about pattern assessment and knowledge representation of data in an easy-to-understand form. Data mining is often viewed as a part of a more extensive field called Knowledge Discovery in Databases or KDD.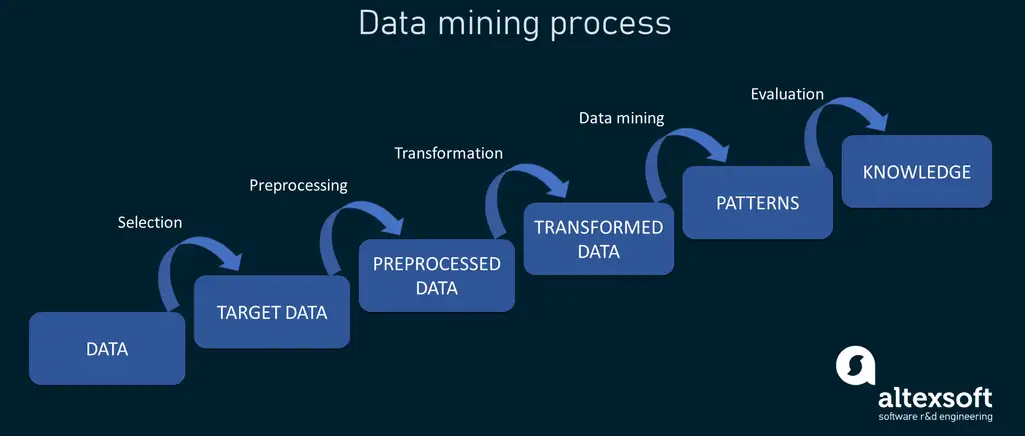
Outline illustrating data mining process steps.
The practical application of data mining is not limited as its techniques are useful for any industry that deals with data. But first of all, data mining methods are applied by organizations deploying projects based on data warehousing. For example, the analysis of shopping cart similarities designed to identify products that customers tend to purchase together is widely employed in eCommerce and retail.
Amazon’s “Frequently bought together” as an example of trends discovered with the help of data mining.
So, if you look at the screenshot of three different items offered by Amazon claiming that people frequently buy these things together, you may find no connection at first. Okay, gloves and a scarf make sense, but a barbed wire baseball bat doesn’t seem to be a good fit. In fact, such a combination of products is super popular because of the TV show The Walking Dead. Owing to data mining, it is possible to determine even such complex relations and odd patterns in buying behavior.What is machine learning?
Machine learning is a set of methods, tools, and computer algorithms used to train machines to analyze, understand, and find hidden patterns in data and make predictions. The eventual goal of machine learning is to utilize data for self-learning, eliminating the need to program machines in an explicit manner. Once trained on datasets, machines can apply memorized patterns on new data and as such make better predictions.Machine learning can be of different types:
In supervised learning, machines are trained to find solutions to a given problem with assistance from humans who collect and label data and then “feed” it to systems. A machine is told which data characteristics to look at, so it can determine patterns, put objects into corresponding classes, and evaluate whether their prediction is right or wrong.
In unsupervised learning, machines learn to recognize patterns and trends in unlabeled training data without being supervised by users.
In semi-supervised learning, models are trained with a small volume of labeled data and a much bigger volume of unlabeled data, making use of both supervised and unsupervised learning.
In reinforcement learning, models, put in a closed environment unfamiliar to them, must find a solution to a problem by going through serial trials and errors. Similar to a scenario found in many games, machines receive punishment for an error and a reward for a successful trial. In this way, they learn to find an optimal solution.
The machine learning process and use cases
To showcase how machine learning works, we’ll take spam email filtering as a classic example. So, if you open the spam folder in your email account, you may find all kinds of messy and annoying messages. Spam detection systems help with filtering out irrelevant messages from those important to users.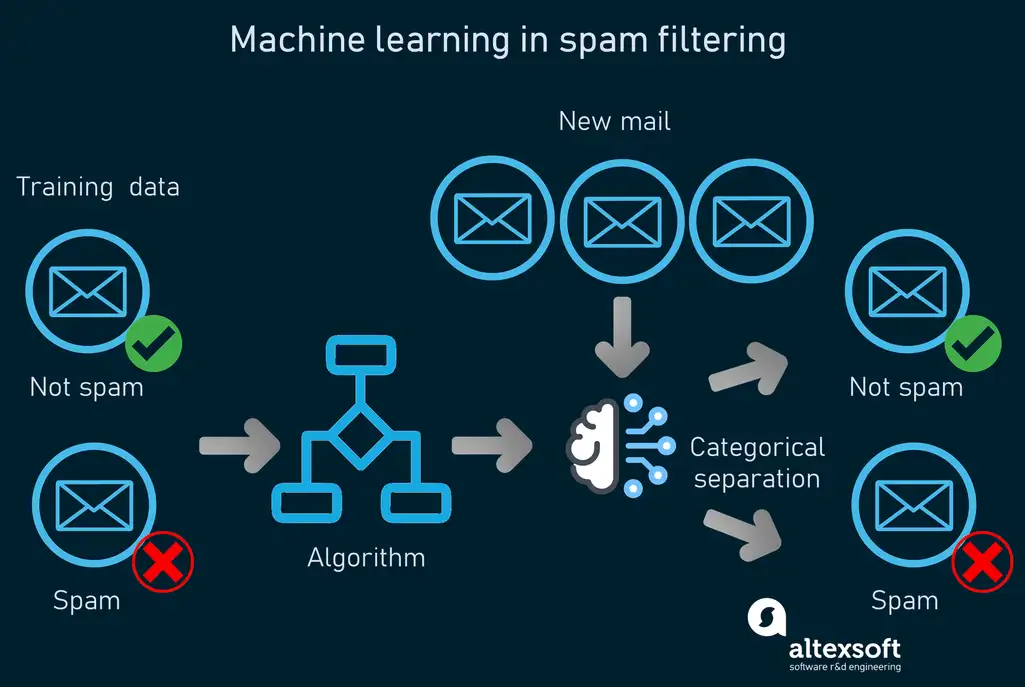
How machine learning works in spam detection.
The systems analyze the content of emails and classify data by using machine learning algorithms. The task of such ML-based models is to determine whether an incoming message is “spam” or “not spam” (in other words “ham”). As spam detection is a subject for supervised machine learning, the model is first trained with labeled datasets – examples of spam and ham emails carefully defined by people. Learn more about data preparation in ML from our article or watch a video:
Data preparation for ML 101
One popular method to train a model is the naïve Bayes algorithm that calculates the probability of events or results based on prior knowledge. The method correlates some features with spam messages and other features with legitimate email. The features are words or phrases found in the email body and its header. Then it calculates the probability that a given incoming message is spam.You know that if a message is titled "You won $1,000,000", it's likely to be spam, but a machine needs to learn this prior. As the model learns the patterns, it can accurately assign each new email a score. Passing scores get to the inbox and scores below a certain threshold are marked as junk. When using email services, people manually mark some inbox messages as spam adding new data to the training data set of the system. This is the part of a machine learning pipeline called model retraining that ensures a system stays up-to-date and provides accurate results.
Other distinctive machine learning examples are presented by medical applications that can predict which patients have a higher probability of getting sick by analyzing their electronic medical records and claims. ML-based fraud detection systems also make a great example of machine learning. They help with signaling possible frauds by analyzing suspicious user behavior
What is deep learning?
Deep learning is a subset of machine learning, but it is advanced with complex neural networks, originally inspired by biological neural networks in human brains. Neural networks contain nodes in different interconnected layers that communicate with each other to make sense of voluminous input data.There are various types of neural networks such as convolutional neural networks, recursive neural networks, and recurrent neural networks. A typical neural network consists of the input layer, multiple hidden layers, and the output layer that are piled up on top of each other.

Illustration of deep learning neural networks with three hidden layers.
The deep learning process and use cases
If we take a look at the pictures below, we will easily distinguish between corgis and loaves of bread. Machines, on the other hand, can’t do the same thing so effortlessly. They need to learn from huge amounts of data, create algorithms, and transform input data into machine-readable forms before they can identify what’s shown in the pictures and present accurate results.
Corgi or loaf of bread image recognition example. Source: Imgur
So, let’s say you want to create a program that identifies corgis in pictures, or, generally speaking, recognizes certain objects shown on images. Deep learning models are the best fit for image recognition or any data that can be converted into visual formats, like sound spectrograms.Let’s get back to the example. We take multiple images of corgis and loaves of bread with each picture consisting of 30x30 pixels. A bunch of neurons will correspond to each pixel of the input image (900 in total) and each neuron represents its activation (a number that shows the value of a certain pixel). Activations in one layer determine the activations of the next one.
The neurons are connected by lines called synapses and each of these lines has a weight determined by the activation numbers. The bigger the weight, the more dominant it will be in the next layer of a neural net.
In every layer, there are bias neurons that move the activation functions in different directions. The sum of weights, activation numbers, and bias numbers is called the weighted sum of the neural net layer. The weighted sum in one layer makes up the input for another one until it reaches the final, output layer.

Deep learning process depiction.
The activation of neurons of the output layer represents how much a system thinks a given image corresponds to the classification task. In our case, this is the probability of a certain image to represent a corgi, not a loaf of bread. The neural network is considered to be successfully trained when the value of the weights provides the output closest to the reality.
Watch how deep learning algorithms work in image recognition tasks
Deep learning finds lots of practical applications from speech recognition technologies that can convert spoken words into a textual format helping thousands of people who have trouble using buttons and keystrokes to drug discovery systems capable of predicting pharmacological properties of drugs in various biological conditions. Another bright example of successful implementation of deep learning algorithms is Google Translate that provides quality translations of written text into more than 100 languages.
What is artificial intelligence?
In traditional terms, artificial intelligence or AI is simply an algorithm, code, or technique that enables machines to mimic, develop, and demonstrate human cognition or behavior. In the business world, AI is a real life data product capable of carrying out set tasks and solving problems roughly the same as humans do. The functions of AI systems encompass learning, planning, reasoning, decision making, and problem-solving.
The thing is, AI is too broad to be defined accurately and unambiguously.
We are in what many refer to as the era of weak AI or artificial narrow intelligence (ANI), meaning that such tech products can only do things they are trained to do. The strong AI or artificial general intelligence (AGI) can only be seen in sci-fi films or books where machines can generalize between different tasks just like humans do. Think of such movies as I, Robot (2004) or Chappie (2015) and you'll get the idea. There's also the third type of AI ‒ artificial superintelligence (ASI) with more powerful capabilities than humans. Needless to say, this type is way far from realization.
Weak and strong AI.
Just like there's no consensus on what advances are more AI-related than others, the world hasn't agreed on whether AI is a threat or a blessing. Here’s what Bill Gates stated in one of his interviews:
“Google, Facebook. Apple, Microsoft are all moving ahead at great speed in improving their artificial intelligence software [...] artificial intelligence is going to be extremely helpful and the risk that it gets super smart, that’s way out in the future.”
To sleep soundly, have a read of our reality check on whether or not AGI will take over the world.
Artificial intelligence use cases
While there are at least several decades separating us from the human-like robot level of AI, scientists are already doing tons of mind-blowing things with narrow AI. Let’s take chatbots, for example. Owing to understanding speech and text in natural language, AI systems communicate with humans in a natural, personalized way. Other cool examples of AI are self-driving cars, robots used in manufacturing, and email spam filters, to name a few.
Key differences between AI vs ML vs Deep Learning vs Data Science vs Data Mining
Wrapping things up, we'll single out the key differences between data science, data mining, artificial intelligence, machine learning, and deep learning one more time.
- Data science can be seen as an umbrella for all the disciplines used to make sense out of huge volumes of data. Data science research is the foundation for building smart AI products whether they are ML-based or DL-based.
- Unlike data science, data mining is referred to as a set of techniques and tools used for collecting, cleansing, and analyzing data to unfold interesting patterns and trends in it. Data mining is also commonly used when working on AI projects.
- AI is about creating a functional data product that can solve set tasks by itself, which remotely resembles human problem-solving.
- Machine learning falls within an AI system that can self-learn based on algorithms and previously learned patterns.
- Deep learning is a kind of machine learning but this approach uses neural networks for making predictions based on processed data.
- Most AI work involves either ML or DL since the so-called "intelligent" behavior of machines requires massive knowledge, which, in turn, requires data science and data mining research.
The data disciplines we have just described work collaboratively. They already have a myriad of practical applications in various spheres from management and sales to healthcare and finance, and more innovations and advances are yet to come.