

The enterprise data landscape is fragmented. According to Flexera’s 2022 State of the Cloud Report, 89 percent of respondents have a multi-cloud strategy with 80 percent having a hybrid cloud approach in place. Organizations have data stored in public and private clouds, as well as in various on-premises data repositories.
How organizations embrace multi-cloud. Source: Flexera
Some would say that it’s not a big deal, however, these mixed environments have resulted in the complexities of managing disjointed data and business processes. With these challenges in enterprise data management, there has to be an approach to overcoming them, right?
Gartner claims that there is such a solution capable of enabling companies to have advanced, flexible, and reusable data management across all environments. The solution is called a data fabric. What’s more, Gartner identifies data fabric implementation as one of the top strategic technology trends for 2022 and expects that by 2024, data fabric deployments will increase the efficiency of data use while halving human-driven data management tasks.
In this post, we’ll attempt to explain the idea behind a data fabric, its architectural building blocks, the benefits it brings, and ways to approach its implementation.
What is data fabric?
A data fabric is an architecture design presented as an integration and orchestration layer built on top of multiple, disjointed data sources like relational databases, data warehouses, data lakes, data marts, IoT, legacy systems, etc., to provide a unified view of all enterprise data.
In layman’s terms, a data fabric says that you don’t need to centralize data, but put things in order where this data resides. So, instead of replacing or rebuilding the existing infrastructure, you add a new, ML-powered abstraction layer on top of the underlying data sources, enabling various users to access and manage the information they need without duplication.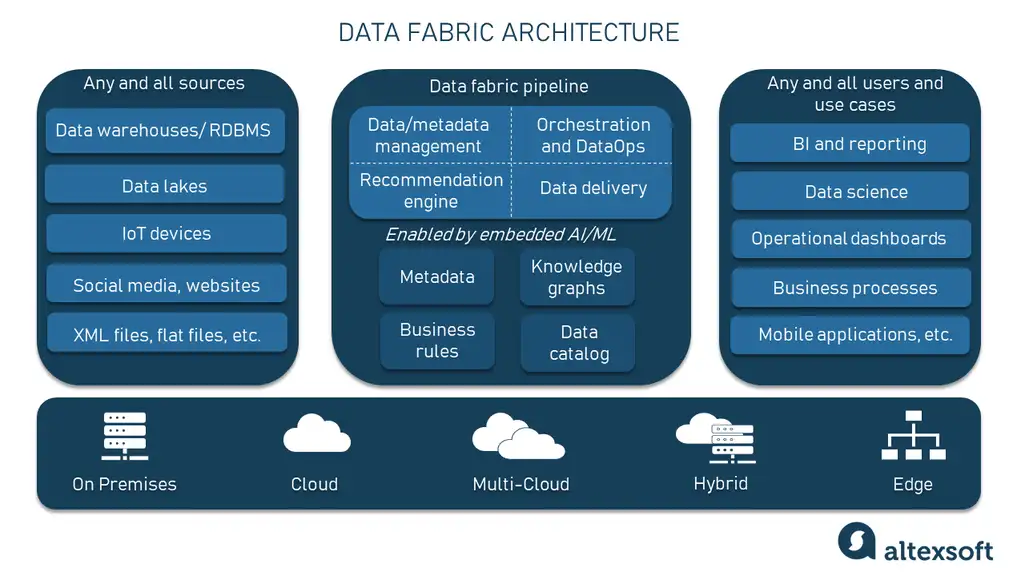
Data fabric architecture example
Remember that a data fabric is NOT a single software tool you can buy and deploy overnight. It is a general design approach that leverages data virtualization principles. It also applies artificial intelligence (AI) and machine learning (ML) to streamline integrations, deliver trusted and reusable data assets, and provide self-service analytics capabilities to different consumers, including business users, analysts, data scientists, etc.
Some of the tech companies pioneering the data fabric initiative are
- Denodo,
- IBM with their IBM Cloud Pak for Data,
- Tibco Software, and
- NetApp, to name a few.
But again, as Gartner points out, there's no single vendor to offer a data structure that can be called a complete data fabric.
Here are a few key characteristics that set the foundation of the data framework.
Unified data access. Any data fabric creates a single point of access to multiple source systems of a company via a set of pre-packaged connectors and components. As such, it helps solve the data silos problem — when the information is stored in different places that only certain users can access.
Self-service data consumption and collaboration. A data fabric quickly routes data to those who need it. The self-service functionality allows the entire organization to find relevant data faster and gain valuable insights.
Support for different data types and use cases. A data fabric supports structured, unstructured, and semi-structured data whether it comes in real-time or generated in batches. It is also driven by metadata, which it uses to recognize patterns, map data, and perform continuous analysis.
Use of artificial intelligence and machine learning. A data fabric opts for the power of machine learning in its recommendation engine module to enhance the search of relevant data for users by providing recommendations. Also, machine learning helps organizations systematically discover patterns between data items in a data catalog, automate the process of mapping existing business terms to new inputs, and establish relationships between data that might otherwise be missed.
Consolidated data protection. A data fabric provides built-in data quality, ensures data integrity, enforces data policies, and offers a high level of data protection and compliance. powered by machine learning.
Compatibility with different deployment environments. A data fabric manages multiple environments including on-premises, cloud, multi-cloud, hybrid cloud, or edge platforms, both as data sources and as data consumers.
Infrastructure resilience. A data fabric separates data management from specific technologies and puts it in a single, dedicated environment. Such a system is more resilient when new technologies or data sources are added.
API support. A data fabric allows for sharing data with internal and external users via APIs.
Due to the existence of different frameworks and approaches used to store and process data, it's easy to confuse some of the terms with a data fabric as they may share similar ideas.
Data fabric vs data mesh vs data virtualization vs data lake
Here we’ll shed some light on the concepts of data mesh and data virtualization that, at first glance, may be mistaken for a data fabric and vice versa.
Data fabric vs data mesh
All in all data mesh is more about organizational and cultural principles for creating a distributed domain-focused architecture that treats data as a product. A data fabric, on the other hand, is more about technology that can help build an integration layer with access to all company data.
Besides, the data fabric approach leaves the organization with a centralized team that is responsible for all the data, while data mesh implies distributed ownership of the data — each team has its own data products and they are responsible for its distribution to other teams. You can learn more about the data mesh in our dedicated article.
Data fabric vs data virtualization
Here things get a bit more complex since data virtualization is one of the fundamental parts of the data fabric architecture. So, these concepts are neither competitors nor interchangeable terms.
The idea behind data virtualization is that data isn’t physically moved from various on-premises and cloud sources using the standard ETL (extract, transform, load) processes. Instead, there’s a virtual (logical) layer that connects to all the sources and creates a single representation of data no matter its location and initial format. As a result, end users can consume the information aggregated from numerous systems in the form of reports, dashboards, and other convenient views.
A data fabric uses a data virtualization approach but takes it to a whole new level by adding to it ML-enabled data catalogs, knowledge graphs, and recommendation systems.
Data fabric vs data lake
In the data fabric vs data lake dilemma, the distinction is simple. Data lakes are central repositories that can ingest and store massive amounts of both structured and unstructured data, typically for future analysis, big data processing, and machine learning. A data fabric, conversely, doesn’t store data. It is a metadata integration layer that can be built on top of a data lake or an architectural ensemble that includes it.
The issue with data lakes is it may be difficult to find a certain piece of information there. The more data is placed there, the greater the chance that a data lake will become a data swamp.
A data fabric allows for dealing with the technological complexities engaged in data movement, transformation, and integration, creating a unified view of all data across the enterprise. It also helps deploy and scale new apps and services while maintaining security concerns.
Data fabric architecture building blocks
Since a data fabric is a design concept with a rather abstract nature, understanding how it works may be challenging. To facilitate this task, we suggest that you get acquainted with the core building blocks of the typical data fabric architecture.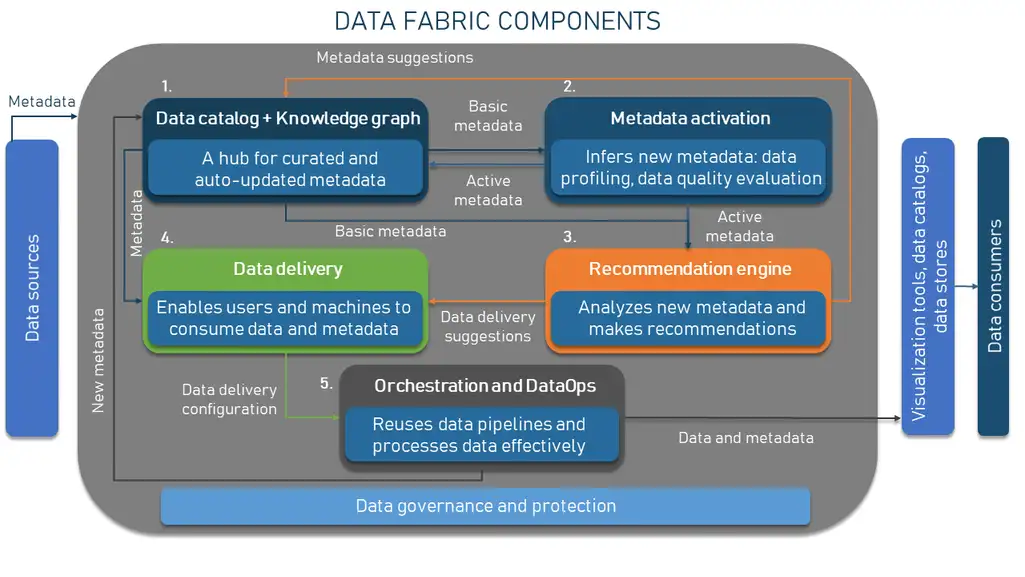
How data fabric works
Data and metadata
The heart and soul of the entire architecture is data that comes in all forms and sizes and lives in many disjointed systems. But what sets the data fabric framework apart is the use of metadata or, in other words, data about data. It contains details about other information, providing a structured reference that helps to sort and identify attributes of the information it describes.
Basic metadata can be structural, descriptive, and administrative.
- Structural metadata describes relationships among different parts of source data such as page numbers or tables of context in a book.
- Descriptive metadata includes elements such as title, author, and subjects and enables discovery, identification, and selection of resources.
- Administrative metadata includes things like technical elements, preservation, rights, and use to facilitate the management of systems.
Data catalog
A starting point in any data fabric design, a data catalog organizes data by profiling, tagging, classifying, and mapping it to business definitions so that end-users can easily find what they need.
Effective data catalogs must be deployed at scale, span all data sources that store sensitive and personal data, and get automatically filled with the right data. They should also distribute business term tags and go beyond purely technical metadata to be able to provide context, required to manage data in a privacy-aware manner. Since metadata fuels the prevailing part of the automation that the data fabric delivers, a data catalog is a must-have part of the data fabric.
You may already have a data catalog with the key business terms and their relations to one another. But there should be an automated metadata discovery and ingestion. When connecting a new data source to your data catalog, the AI algorithms must be able to reuse the knowledge of the existing data sources to infer metadata about the new source. For example, they should automatically map new information attributes to existing business definitions users are already familiar with.
Enabling machine learning classification helps organizations systematically discover relationships between data items, automate the process of associating metadata with data items for activities such as privacy protection and data quality assessment, and establish relationships between data that might otherwise be missed.
Knowledge graph
A knowledge graph is a semantic network that also collects the metadata — the descriptions of real-world entities (objects, events, situations, or concepts) and illustrates the relationship between them. Descriptions provided by the knowledge graph have formal semantics that allows both people and computers (e.g., a recommendation engine) to process them efficiently and unambiguously. The information is usually stored in a graph database and visualized as a graph structure, hence the name.
A simple example of a knowledge graph. Source: Towards Data Science
Both a data catalog and a knowledge graph aggregate and store basic metadata (schemas, data types, models, etc.) that needs to be activated.
Metadata activation
As far as the topic we’re discussing, another important thing to mention is that metadata can be passive and active. And truth be told, active metadata sounds like another marketing buzzword leaving you with more questions than answers. But let’s try dealing with what it is.
Passive metadata covers some basic technical information such as data types, schemas, models, etc. It can be seen as a way of collecting and storing metadata in its usual sense in a static data catalog that doesn’t capture how those metadata assets have been changed or used.
Active metadata is more complex than passive metadata as it covers operational, business, and social metadata along with basic technical information. Unlike the static nature of passive metadata, the active type can capture the changes in metadata. This means that for each asset like a table column or a dashboard some additional information is included — say, who used it, when, and how often.
Then this info is pushed to all the tools in the data fabrics pool so that when a user accesses the data of a table, they can see this table's augmented metadata.
Switching from manual (passive) metadata to automatic (active) metadata is necessary for data processing and continuous analysis at a massive scale as well as more advanced data governance and security.
Recommendation engine
Enabled by ML algorithms, the recommendation engine is another important component that makes a data fabric such an attractive data framework. It analyzes all the metadata (activated metadata, technical metadata, catalog metadata, etc.) to infer more metadata or make recommendations on how to process your data.
The recommendation engine
- optimizes delivery, including suggestions on how data should be transformed before the delivery happens;
- interprets metadata — finds new relationships in data, performs data classification, and applies data quality rules; and
- detects anomalies in data structure and delivery so that users know when something goes wrong.
To define patterns, relationships, and anomalies in data, you can opt for ML classification and clustering algorithms to analyze existing and new data.
Data delivery
The data fabric approach enables users and systems to consume data and metadata. Users can find data assets in the data catalog and transform (prepare) data in a self-service manner. Software apps can exchange data via APIs.
Thanks to the metadata in the knowledge graph and delivery suggestions from the recommendation engine, the data fabric understands the structure of data and the different intents of data consumers. As such, it can suggest different data preparation or delivery types. For example, it might provide denormalized data for a report but make it similar across all records and fields for data warehousing.
Orchestration and DataOps
This critical layer conducts some of the most important jobs for the data fabric — transforming, integrating, and cleansing the data close to data sources, making it usable for teams across the company. To deliver high-quality data products as rapidly as possible, the data fabric approach follows DataOps — a relatively new methodology that ties together data engineering, data analytics, and DevOps principles.
The overall data governance and security process is centralized and consistent across the framework and all environments.
How to approach data fabric implementation
When planning a data fabric design, remember that there is no single tool for implementing a data fabric. It consists of multiple technical components whose level of maturity differs in every organization. Depending on your goals and considering your budget, the needs of your company may differ significantly from what other organizations have. Data fabric designs should therefore be tailored to your specific needs and challenges.
So, before kicking off a data fabric initiative, it’s important to map out an implementation strategy. Here are a few recommendations that may come in handy as you begin designing your data fabric.
Evaluate your capabilities. Assess your existing data management stack against the technology pillars of the data fabric design. Once you know your maturity level in each component, you can plan your design accordingly and select a technology partner that best supports your technical needs.
Decide on data and metadata sources. Perform "metadata discovery" to identify patterns and associations between users, data, locations, transitions, and usage counts. Understanding these patterns will help you lay the foundation for introducing a data fabric structure.
Start small. Start with the basic path of your data fabric, covering the known data and use cases as well as the technical components. Later, you can move on to a more advanced path where you expand your data management infrastructure design and data delivery.
To sum up, a data fabric is still developing so there might be a lot of confusion and speculation as to what it is and how to implement it. Some people think of a data fabric as another buzzword rather than a mature technology solution. So, the final decision on whether it is worth your attention is up to you.