Lots of organizations store and process protected health information, or PHI for short, which makes them targets of malicious entities or people who want to use sensitive data for personal and monetary gains. According to a report by bitglass, the number of healthcare breaches reached 599 in 2020, a 55 percent increase since 2019.
That is why in this article, we will talk about PHI:
What is PHI and different types of organizations and entities that deal with it
When and how PHI can be disclosed
How to secure PHI to stay HIPAA-compliant
How to detect and de-identify PHI to make it available for research and clinical trials.
What is protected health information (PHI)?
Protected Health Information is any information collected from a patient that can be used to identify this person. It’s created, received, transmitted or maintained by different organizations that render healthcare services and payments.
That said, it’s important to define three related terms to better understand this topic — сovered entities, business associates, and Health Insurance Portability and Accountability Act (HIPAA).
A covered entity (CE) is any individual or organization that processes, transmits, and stores PHI. Some examples are hospitals, insurance companies, doctors, nurses, pharmacists, laboratories, call centers, medical equipment providers, social workers, etc.
On the other hand, a business associate (BA) is an individual or company that provides services to a covered entity which, in turn, grants BAs access to PHI. BAs include cloud service providers, billing companies, data storage, firms, and attorneys.
Finally, HIPAA is the law that governs the access, use, and disclosure of PHI in the US. The penalties for breaking these laws depend on the severity of the violation. It is divided into four levels, where tier 1 violations have the lowest fines, while tier 4 have the highest. To learn more, check the article on common HIPAA violations to be aware of.
PHI relates to an individual’s present, past, or future medical records processed, transmitted, and stored in any form or medium. However, PHI does not include education and employment records. Also, the health information of a person deceased more than 50 years ago is not considered as PHI.
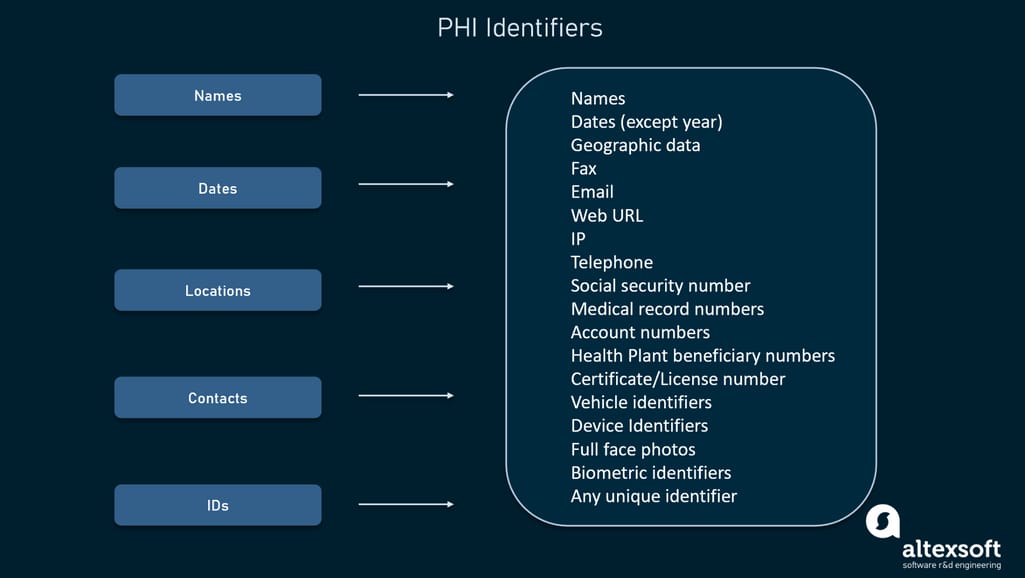
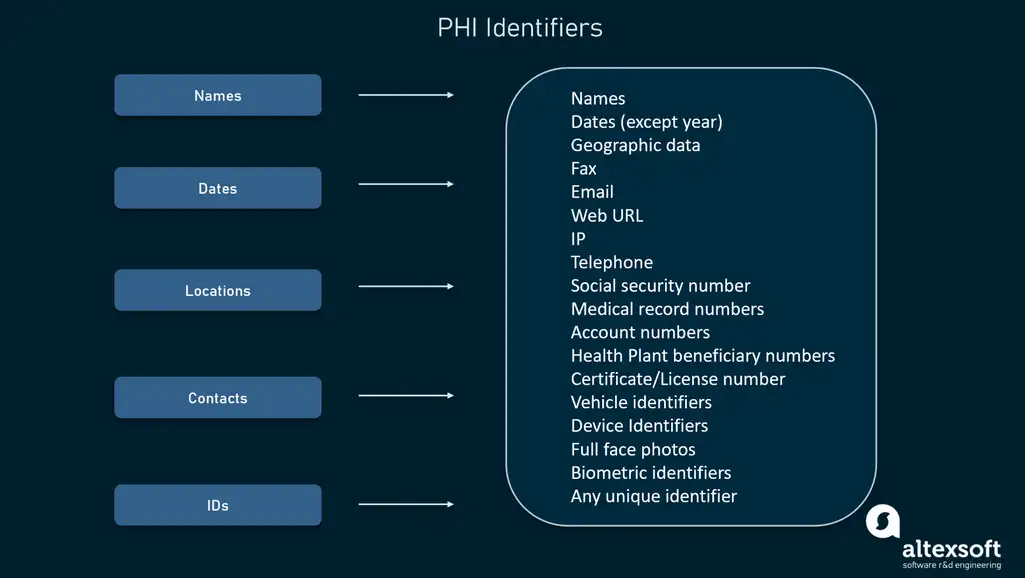
HIPAA specifies 18 identifiers considered as PHI. When these identifiers are removed, then the record no longer contains protected health information. Some of the identifiers include: names, locations, age, dates, contacts, and IDs
Here’s the full list of PHI identifiers
To give you an idea, here are some documents that may have PHI:
Clinical notes. These are notes provided by the doctor and contain the preliminary and final diagnosis of the patient. It also contains the name of the doctor and patient.
Email to the doctor's office. An email to a doctor also contains PHI such as the name of the patient and doctor, clinical diagnosis of the patient, and prescribed drugs that the patient may be taking.
Appointment scheduling note with your doctor's office. An appointment note to see a doctor usually contains the patient's name and contact information.
Imaging and test results. X-rays images, CT scans, MRI, and other test results performed in the lab carry the patient’s name and diagnosis.
When and how can PHI be disclosed?
The HIPAA Privacy Rule is the main regulation that governs the use of PHI. It also provides information on when and how PHI can be disclosed. Normally, it happens when the patient agrees to it. However, when the person does not provide consent, PHI use and disclosure are allowed:
For treatment purposes. For example, when the PHI is required by another doctor to treat the patient
If it is required by law. For example, where the patient is involved in a criminal offence
For public health purposes. For example, in case the patient has an infectious disease that could be a threat to a large part of the population.
However, even in these circumstances, the disclosure of PHI must follow the Minimum Necessary Rule. This rule states that the covered entities are allowed to disclose only the minimum necessary information. The exception is when the doctor needs full access to the patient’s medical history to provide treatment in a healthcare setting.
How to secure PHI to stay HIPAA-compliant
Covered entities and their business associates need to meet a set of requirements and perform all risk assessments to stay HIPAA-compliant and secure PHI.
Regularly perform HIPAA risk assessments
Companies that deal with PHI should frequently carry out risk assessments to detect vulnerabilities in their systems. Here is what the Health & Human Services (HHS) suggest organizations should be doing:
Identifying where PHI is stored, received, maintained or transmitted
Detecting and registering vulnerabilities and potential threats
Ensuring that the security measures put in place to protect PHI are used properly and up to date
Assigning risk levels for vulnerability, determining the possibility of a threat, and the impact of a PHI breach.
Documenting the results of the assessment to make changes and take action where necessary
Implement technical safeguards
This refers to all the technology used to protect and encrypt PHI. Here are the technical safeguards that companies can implement to ensure that their data is secure:
Ensure that access to PHI is limited. This can be done by providing a unique ID and password to each user. So, if there is a violation, it can be easily traced back to a specific user.
Introduce security systems and activity logs. The security system will document any attempted breach and record what is done with the information if it is accessed.
Install tools for encryption and decryption. There are lots of tools like GnuPG, Stunnel, and OpenSSL that can be used to encrypt and decrypt data going in and out of your system.
Automatic log-off devices. This option ensures that an authorized user is logged off their device if left unattended after a predefined period.
Implement physical Safeguards
These safeguards limit the physical access to PHI stored in the premises of a HIPAA covered entity.
Regulate the positioning and use of workstations. Ensure that devices that contain PHI are placed in locations that can be constantly monitored. For example, keep the workstations in a room that has surveillance cameras and a security officer.
Determine how PHI is handled on mobile devices. You should determine how PHI on mobile devices will be handled if the user leaves the organization or in the cases of device theft and loss.
Limit physical access to PHI. Regulate those who can physically access the location where devices that contain PHI are kept.
Implement administrative safeguards
These safeguards put in place policies and procedures that help protect PHI. It also requires that an administrator is assigned to enforce the rules, govern the conduct of employees, and ensure that the data is safe. Here is what the administrator should be doing:
Carrying out risk assessments. Identify all the departments of your organization where PHI is used, and anticipate ways in which breaches or violations may occur.
Implementing risk management policies. Risk assessments should be done frequently and impose sanctions on employees that break HIPAA protocol.
Raising the awareness of employees. Companies can raise the awareness of their employees by scheduling regular training on how to access PHI and identify breaches.
Creating contingency plans. A contingency plan ensures that your organization continues to operate and protect the integrity of PHI even in cases of emergencies.
Business associates should sign an agreement. Ensure that you have a signed agreement with your business associates before they can use the data.
Implement the Breach Notification Rule
The Breach Notification Rule requires you to notify patients within 60 days if their PHI is breached and inform them of how they protect themselves. Also, if the breach affects more than 500 patients, you need to promptly notify the department of Health and Human Services and the media.
For a breach affecting less than 500 people, you need to report it via the OCR web portal. These reports should be made only once a year after an investigation has been conducted. So, you need to include the following information in your report:
The type of PHI involved;
Individuals involved in the violation
Information on whether the data was accessed or not
How the damage has been contained
Okay, we have talked about keeping PHI safe, but about making this data useful? How do you make it available for third-party use and scientific research?
Detection and de-identification of PHI
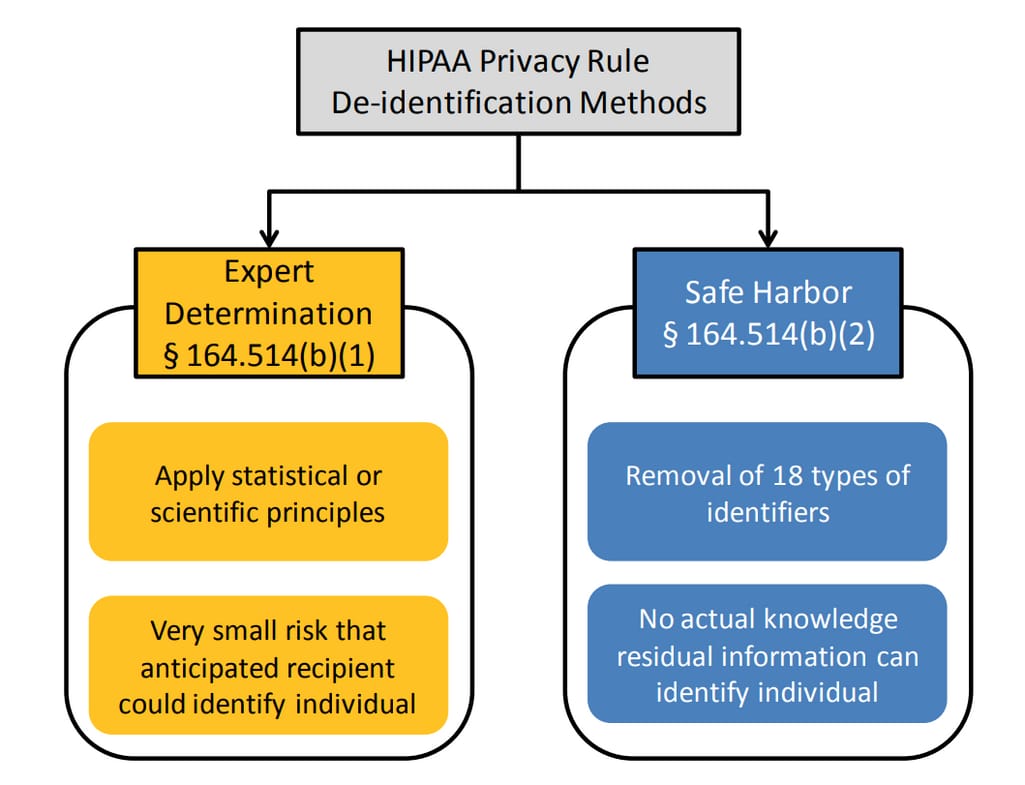
De-identification is the process of removing specific identifiers of the patient to ensure the data can not be linked to them. This makes the data no longer subjected to HIPAA Privacy Rule. So, companies can share the information freely without the fear of violations for research and public health purposes and clinical app development. De-identification doesn’t provide a 100 percent guarantee that the data can not be used to identify a person. Still, it significantly reduces the possibility to an acceptable level. There are two methods suggested by HIPAA to de-identify PHI -- Safe harbor and expert determination methods.
The two main methods of de-identification
Safe harbor method. This method is very straightforward and it implies removing the aforementioned 18 identifiers from patient records. Safe harbor is determined and restrictive. One of the key drawbacks is that once the data is de-identified, it gets hard to match different records that belong to the same patient for research purposes. Another problem is that Safe harbor is less context-sensitive, as data entries that fall under the HIPAA’s list can’t necessarily be used as identifiers in all scenarios. But they still can bring a lot of analytical value. For instance, dates reduced to years don’t allow for granular analysis of patient condition.
However, Safe harbor is used by off-the-shelf providers for data de-identification as it’s easier to automate at scale, when you have a large variety of datasets and you can’t keep track of specifics.
Such off-the-shelf tools are for instance Amazon Comprehend Medical and Dicom Systems powered by machine learning to automatically extract and de-identify data.
Expert determination. Another way that companies can use to de-identify protected health information is by hiring an expert. This person or organization must be knowledgeable in using statistical methods to alter data so it can not be used to identify an individual. The expert must ensure that the information left after de-identification has only a very small risk of re-identification even when combined with data from other sources.
Also, the covered entity must document all the methods used by the specialist, which will then be presented to regulators when necessary. The experts can come from any field or educational background. However, regulators require that they have proven experience in de-identifying PHI. This approach doesn’t provide definitive answers as to how this expert must approach the determination of PHI.
Expert determination is quite common among analytical specialists in the field as it gives more control over data and allows for deciding whether a given data point has analytical value. Expert determination method also works better with matching different documents on the same patient to combine those records for research purposes.
Both safe harbor and expert determination methods can be automated to reduce manual effort and process large datasets. Let’s talk about the most common approaches to automatically detect and remove PHI data from healthcare records.
Template-based de-identification for structured data
The most basic way to remove identifiers is to process documents that have a standard template for formatting data. This way, it’s enough to define the fields where PHI appears and automatically remove or change data in them.
Unfortunately, a lot of data used in healthcare is unstructured or doesn’t conform to strict templates, like radiology imagery or physicians notes in EHRs. So, there are other methods of de-identifying information.
Automated rule- and dictionary-based de-identification systems
One of the more straightforward approaches is to use available dictionaries and sets of rules to identify PHI in records and redact them.
Rule-based identification. A set of rules defines the characteristics of PHI. For example, the rule may be programmed to recognize the format for dates (e.g., DD-MM-YYYY). So, data the system finds in this format will be tagged and classified depending on the type of PHI. The rules can be applied to find standard orthographic hints of PHI like the use of words with mixed capitals (e.g. AltexSoft, as in worked in AltexSoft) or semantic clues like street, lane, avenue in addresses.
Dictionary-based identification. Another approach used in combination with rules is to recognize common entities found in dictionaries and encyclopedias. These allow for finding states and cities, professions, some organizations, etc.
Still, rule- and dictionary-based identification may be imprecise as they can miss all the information that doesn’t strictly follow the formats and dictionary terms. This is especially the case with unstructured data like emails, scans, and notes. For this reason, they can be enhanced with machine learning systems.
Machine-learning-based and hybrid de-identification systems
The machine learning approach entails using labelled data to train models to identify PHI. In this case, ML engineers mostly use supervised methods of machine learning such as Support Vector Machines (SVM), Conditional Random Fields (CRF), and Decision Trees.
This approach is more technically challenging as it requires a data science team with natural language processing expertise. Similar to finding the rules that describe PHI patterns, with an ML-based approach it takes a lot of effort to do feature engineering. It’s the process of identifying the variables in data that the model will be trained with and those that it will need to recognize PHI in new data. Such features may be orthographic (e.g. does the word or phrase contain special characters or acronyms?), semantic (e.g. does this word or phrase contain dates, names, professions?), the position of the given line (e.g. dates may be written at the beginning or the end of the document), etc.
Some practitioners suggest training individual models for each type of PHI identifier.
Eventually, ML-based and rule-based approaches can be combined. For instance, rule-based algorithms can make an additional run-down on results suggested by a model.
Matching de-identified documents
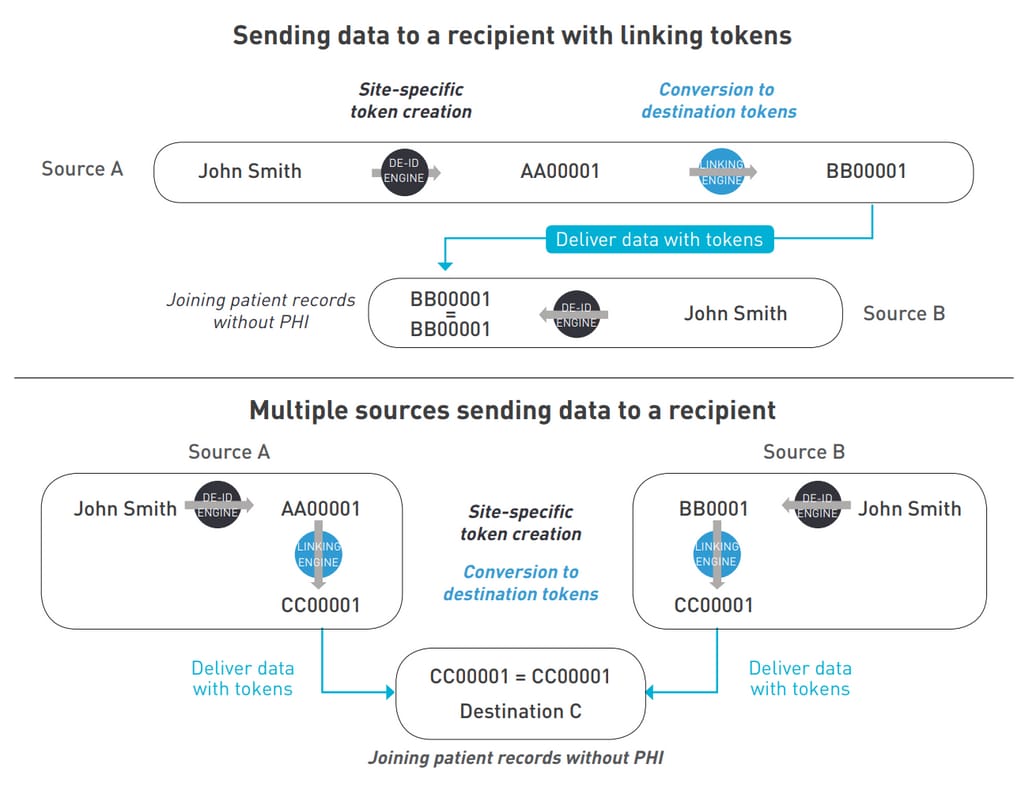
Once the data is de-identified, it becomes difficult to match the documents belonging to a specific person, which hinders research.. However, this problem can be solved by creating a system that is able to merge data sets belonging to the same person. To do this, all of the de-identified data related to a particular patient are encrypted and labeled with the same token.
The same process occurs if the de-identified data of a patient comes from different organizations. Organization A and B can tokenize their specific de-identified PHIs. Both of the data sets undergo a second tokenization process that makes them matchable. So, if these two data sets are sent to a third organization, they will be able to place de-identified data of a specific individual in the same group. Obviously, tokenization must not be reversible.
Tokenization and matching de-identified records suggested by Datavant
De-identified PHI data finds its use across research organizations
Protecting your clients’ information is only one of the many reasons for de-identifying PHI. It also allows your company to share this data among its departments and other third-party organizations for research, marketing, and public health purposes. Here are some ways in which de-identified data use cases:
De-identified PHI is valuable in the medical field, and it is at the center of research that has led to many breakthroughs and discoveries which improve patient care. For example, Kaiser Permanente uses de-identified PHI in partnership with Samsung to improve remote monitoring of cardiac patients in rehab. Results show a lower readmission rate when using a smartwatch-based program as opposed to the traditional rehabilitation regimens.
Also, Mayo Clinic launched a partnership with Massachusetts-based startup Nference to sell algorithms for the early detection of heart diseases.
Innovation partnerships that use de-identified data also have the potential for many other breakthroughs in medical research. McKinsey estimates that AI and machine learning using de-identified health records could save the US medical industry $100 billion annually by improving the efficiency of clinical trials and research.