

As the volume and complexity of data continue to grow, organizations seek faster, more efficient, and cost-effective ways to manage and analyze data. In recent years, cloud-based data warehouses have revolutionized data processing with their advanced massively parallel processing (MPP) capabilities and SQL support. This development has paved the way for a suite of cloud-native data tools that are user-friendly, scalable, and affordable. Known as the Modern Data Stack (MDS), this suite of tools and technologies has transformed how businesses approach data management and analysis.
In this article, we will explore what a modern data stack is, how it’s different from traditional data stacks, the key components composing an MDS architecture, and examples of companies successfully implementing such solutions. Actually, there are even more points, but let's not spoil the surprise.
What is a modern data stack?
A Modern Data Stack (MDS) is a collection of tools and technologies used to gather, store, process, and analyze data in a scalable, efficient, and cost-effective way.
The term stack in computing means a group of technologies working together to achieve a common goal. Software engineers use a technology stack — a combination of programming languages, frameworks, libraries, etc. — to build products and services for various purposes. A data stack, in turn, focuses on data: It helps businesses manage data and make the most out of it.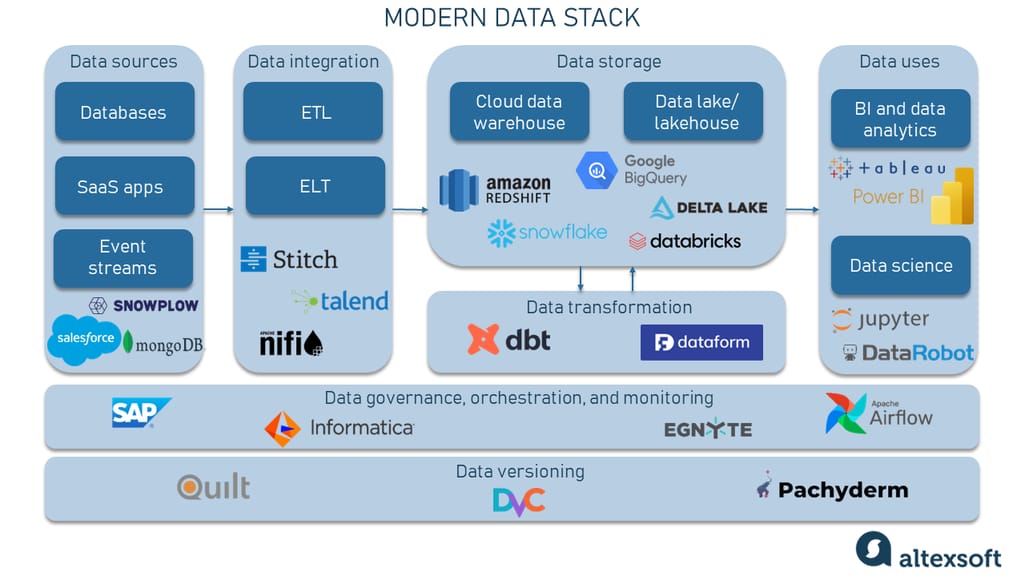
Modern data stack architecture
The image above shows modern data stacks' modularity with the possibility of choosing between different instruments.
Let's say a travel company wants to improve its customer experience by offering personalized travel recommendations. It must collect, analyze, and leverage large amounts of customer data from various sources, including booking history from a CRM system, search queries tracked with Google Analytics, and social media interactions.
A modern data stack can help the company manage and analyze this data effectively by using cloud-based data warehouses like Snowflake, data integration tools like Stitch, and data visualization software like Power BI. The modern data stack can also come in handy with scaling processing capabilities as the data volume grows without rebuilding the whole infrastructure. Having gained insights from the data, the travel company can offer personalized recommendations, improve customer satisfaction, and ultimately drive business growth.
But as we all know, the word modern never comes out of nowhere. There’s always something more traditional preceding it. And our case is no exception.
Modern data stack vs traditional data stack
Traditional data stacks are typically on-premises solutions based on hardware and software infrastructure managed by the organization itself. Often based on monolithic architectures, traditional data stacks are complex and require significant IT infrastructure and personnel investments. Additionally, they may not be easily integrated into cloud-based environments, making them less flexible and less scalable than modern data stacks.
So what about the modern solutions, then?
Six key characteristics define and set a modern data stack apart from traditional (legacy) data stacks.
Cloud-first. MDS tools are cloud-based, allowing for greater scalability, elasticity, and ease of integration with existing cloud infrastructure.
Built around a cloud data warehouse, data lake, or data lakehouse. Modern data stack tools are designed to integrate seamlessly with cloud data warehouses such as Redshift, BigQuery, and Snowflake, as well as data lakes or even the child of the first two — a data lakehouse.
Designed to be modular. One of the significant advantages of modern data stacks is their modularity. In traditional data stacks, changing a single component can take considerable time and effort, not to mention the risk of breaking down the entire structure. On the other hand, modern data stacks allow for the components to be swapped in and out as needed without disrupting the entire system. This means that organizations can choose the best tools for their specific needs and make changes as their needs evolve without overhauling their entire data infrastructure. Additionally, this modularity can help prevent vendor lock-in, giving organizations more flexibility and control over their data stack.
Offered as open-source with active support by communities. Many components of a modern data stack (such as Apache Airflow, Kafka, Spark, and others) are open-source and free. This fosters a supportive ecosystem of users and engineers who contribute to tool development, create groups on Slack, Reddit, and other platforms as well as organize meetups and conferences.
Possibility for SaaS or managed services distribution. While the open-source part is definitely a good thing, it requires a high level of expertise as there’s often no GUI. That’s why some MDS tools are commercial distributions designed to be low-code or even no-code, making them accessible to data practitioners with minimal technical expertise. This means that companies don’t necessarily need a large data engineering team.
Data democratization. Rather than having data limited to a select group of individuals, with modern data stack tools, everyone within an organization can query and access the data they need. This promotes data literacy and allows more individuals to make data-driven decisions. It also eliminates the bottleneck of having only a few individuals with expertise in data analysis and encourages a more collaborative and inclusive culture around data within the organization.
So as we were saying, the word stack suggests that there are a lot of components working together to generate modern tech capabilities. Let’s discuss them in more detail.
Components of a modern data stack architecture
The most common framework for a modern data stack comprises six components, each consisting of a specific set of technologies that work collaboratively to enable its functionality. The size and scope of an organization's requirements determine the structure of a modern data stack and whether a component is a single tool or a combination of several tools.
Data sources
The first component of the MDS architecture is a place or — in most cases — places where your data originates from. Data may come from hundreds (or sometimes thousands) of different sources, including computers, smartphones, websites, social media networks, eCommerce platforms, and IoT devices.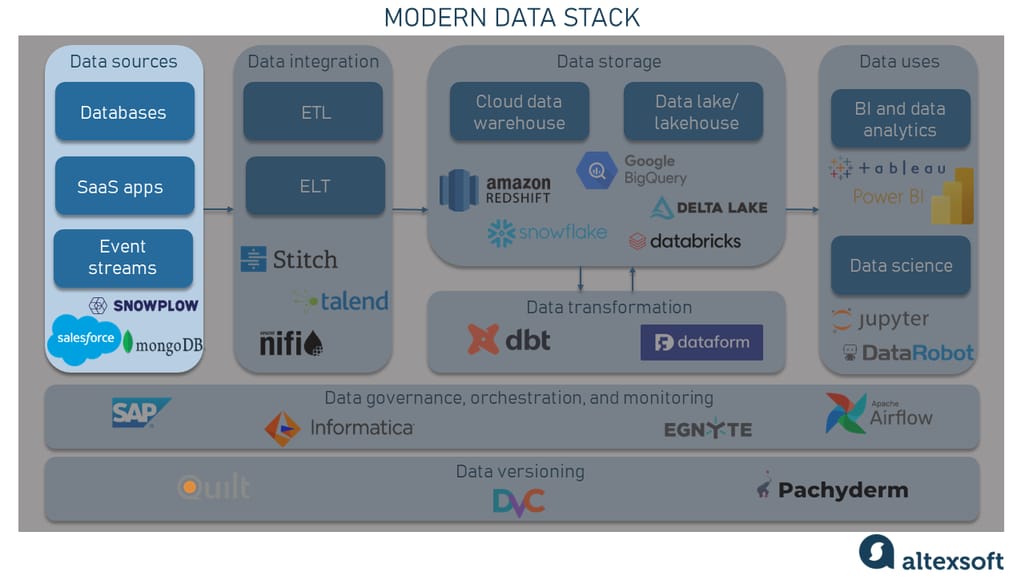
Data sources component in a modern data stack
According to a recent Matillion and IDG Research survey, the average number of data sources per organization is 400. Moreover, greater than 20 percent of surveyed companies were found to be utilizing 1,000 or more data sources to provide data to analytics systems. These sources commonly include databases, SaaS products, and event streams.
Databases store key information that powers a company's product, such as user data and product data. The ones that keep only relational data in a tabular format are called SQL or relational database management systems (RDBMSs). Also, there are NoSQL databases that can be home to all sorts of data, including unstructured and semi-structured (images, PDF files, audio, JSON, etc.)
For instance, video streaming platforms like TikTok may have different databases for user registration and uploaded videos. Some popular databases are Postgres and MongoDB.
SaaS apps. Companies also rely on various SaaS products, which often contain critical data like customer information, billing data, and support tickets. Popular examples include Salesforce for customer information and Zendesk for support tickets.
Event streams. To react to data updates as they occur, companies often need to log user interactions as events for analytical purposes. An event refers to a modification or update in the system that prompts other systems to take action. It can range from a sensor input, transaction, or photo upload to a mouse click. Events may differ in size and complexity and can originate from either internal or external sources.
For example, an eCommerce store may fire events for clicks and product additions to analyze popular products. Popular event stream products include Segment and Snowplow.
By the way, event-driven architecture is a complex topic that deserves the special attention that you'll find in our dedicated article.
Okay, data lives everywhere, and that’s the problem the second component solves.
Data integration
Data integration is the process of transporting data from multiple disparate internal and external sources (including databases, server logs, third-party applications, and more) and putting it in a single location (e.g., a cloud data warehouse) to achieve a unified view of collected data.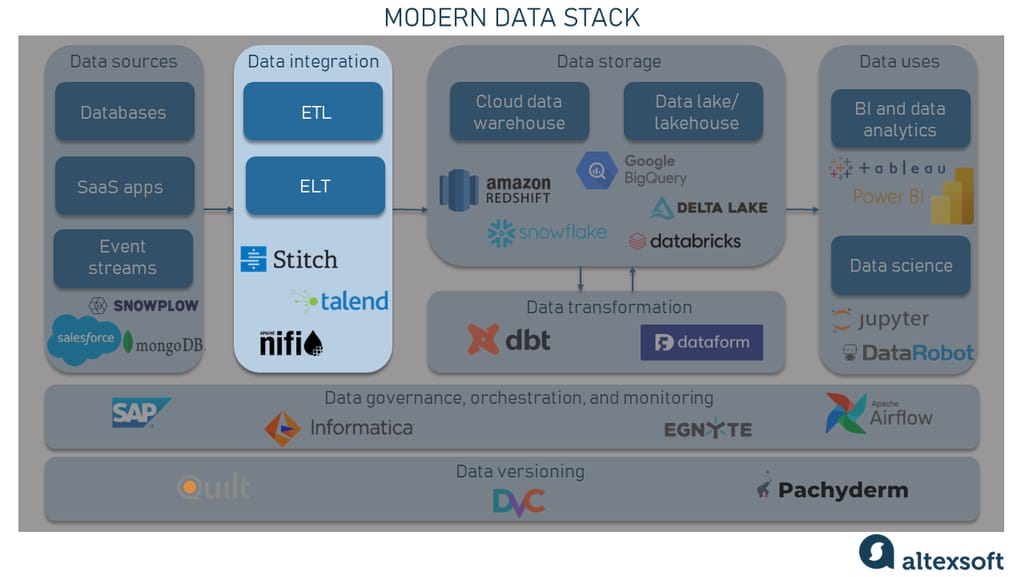
Data integration component in a modern data stack
There are two common approaches, and accordingly tools that support these approaches, to extract, transform, and load data — ETL and ELT.
The traditional ETL (extract, transform, load) approach involves getting data from various sources, converting it to conform to a standardized format, and then loading it into a centralized location.
Today, however, the more modern approach is ELT (extract, load, transform), where data is first extracted and loaded into the data warehouse and then transformed directly within the warehouse. There are tools like Stitch, Talend, and Apache NiFi that offer a lot of connectors to different data sources.
Batch jobs are often scheduled to load data into the warehouse, while real-time data processing can be achieved using solutions like Apache Kafka and Snowpipe by Snowflake to stream data directly into the cloud warehouse.
Data storage
The tools mentioned in the previous section are instrumental in moving data to a centralized location for storage, usually, a cloud data warehouse, although data lakes are also a popular option.
Data lakes were a preferred option back in the day as they could store raw data in different formats, like unstructured and semi-structured data, while data warehouses were used for storing structured data. But this distinction has been blurred with the era of cloud data warehouses.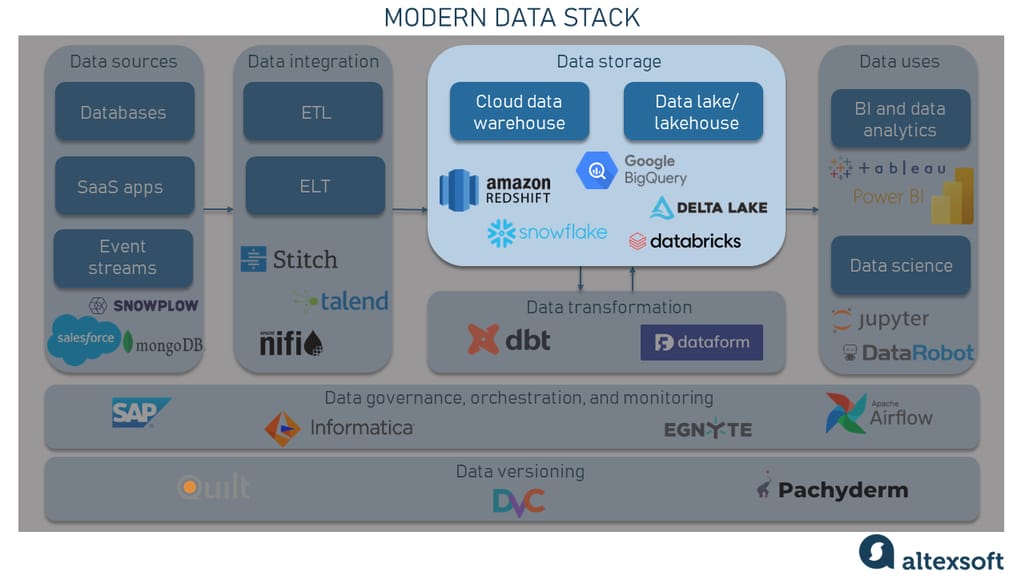
Data storage component in a modern data stack
Cloud data warehouses serve as the central component of modern data stacks, and they offer powerful analytics capabilities allowing for direct querying of the data stored within them. Some popular solutions include Snowflake, Google's BigQuery, and Amazon Redshift. In addition, Databricks, with their Delta Lake, is a well-known option frequently used in MDSs.
Also, Databricks are pioneering the lakehouse concept that makes it possible to use data management features inherent in data warehousing on the raw data stored in a low-cost data lake owing to its metadata layer.
Data transformation
To be valuable, data stored in the data warehouse must undergo a transformation process. It involves converting the raw data into user-friendly models that can be queried by analysts or data scientists to extract insights, build dashboards, or even ML models.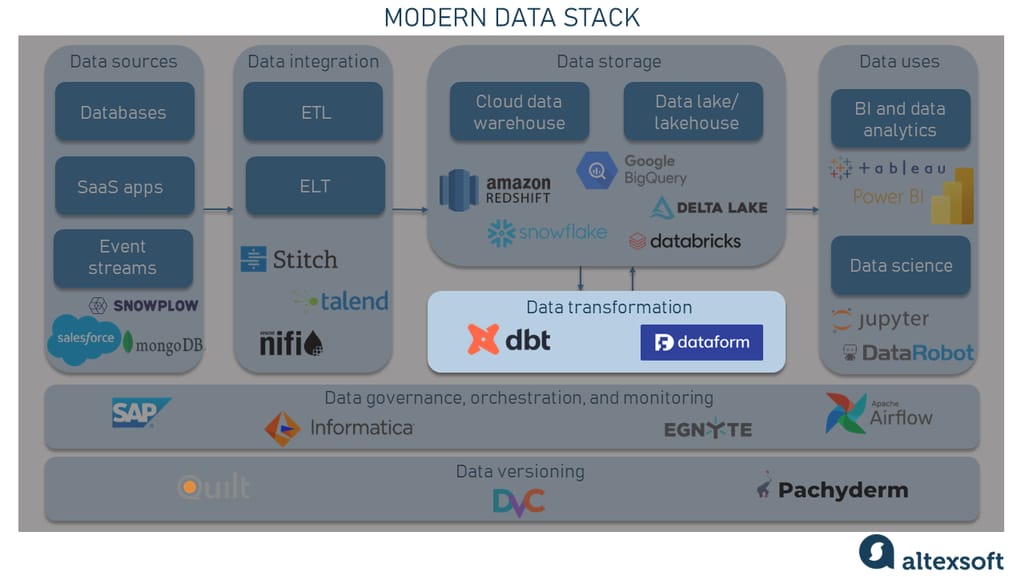
Data transformation component in a modern data stack
Transformations may include the following aspects.
- Cleaning: removing or correcting inaccurate, incomplete, or irrelevant data in the dataset.
- Normalizing: organizing the data in a standard format to eliminate redundancy and ensure consistency.
- Filtering: selecting a subset of data based on certain criteria or conditions.
- Joining: combining data from multiple sources based on a common key or attribute.
- Modeling: transforming the data into a format that is suitable for analysis, including creating data structures, aggregating data, and adding derived fields.
- Summarizing: creating condensed and simplified views of the data, often through aggregation or grouping.
With the shift to ELT, it’s become more common for all the transformation jobs to be performed after the data is loaded into a centralized repository. Tools such as dbt and Dataform are commonly used for data transformation and modeling within a modern data stack. All these instruments allow for the conversion of raw or lightly-processed data stored in a data warehouse into user-friendly models. They simplify data transformation by reducing redundancy, enabling consistent data model design, and promoting code reuse and testability.
Data uses
And – drumroll, please! – this is the reason you need this whole MDS thing in the first place — the data use component, or how the data is actually utilized. There are two main areas of use within this component: The first is data analytics and business intelligence and the second is data science.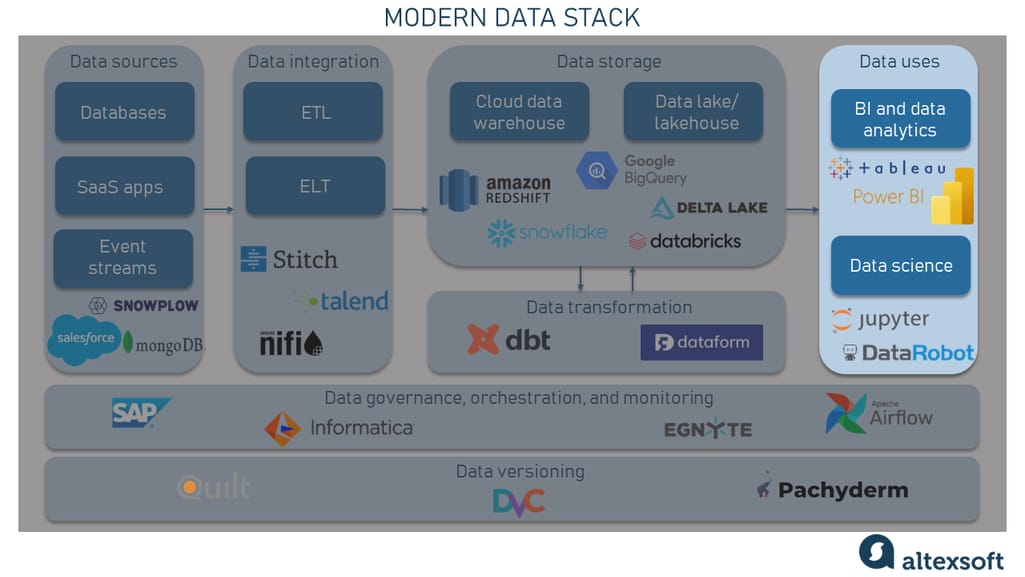
Data use component in a modern data stack
BI and analytics involve using data to gain insights that inform business decisions. This includes creating reports and visualizations to help stakeholders understand trends and identify areas for improvement. Tools commonly used in this area include Tableau and Power BI.
Data science, on the other hand, involves using data to build predictive models for automating decision-making or informing more complex analyses. This area requires a deep understanding of statistics and machine learning algorithms, as well as the ability to program in languages such as Python or R. Popular tools for data science and machine learning include Jupyter Notebooks, the DataRobot autoML tool, Scikit-learn, and TensorFlow.
It's worth noting that these two areas are not mutually exclusive, and many organizations will make use of tools and techniques from all of them. In fact, having a well-rounded understanding of each of these areas can be a valuable asset for data professionals.
Data governance, orchestration, and monitoring
Data governance is a crucial component of modern data stacks as it ensures that data is managed appropriately and complies with relevant regulations. Data governance encompasses a range of processes, policies, standards, and guidelines that govern the collection, storage, use, and dissemination of data within an organization.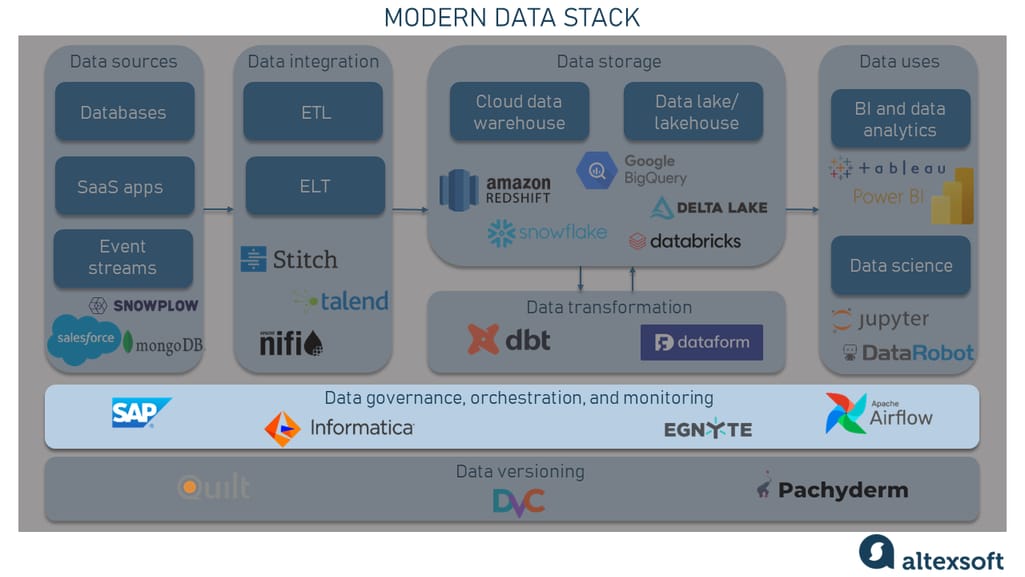
The data governance, orchestration, and monitoring component in a modern data stack
Data governance takes care of several vital aspects, such as data privacy, security, quality, and compliance. It ensures that data is managed in a way that aligns with regulatory requirements and organizational standards, and that data is protected from unauthorized access or misuse.
A robust data governance framework should involve a multidisciplinary team comprising stakeholders from different organization areas. This team will establish policies and procedures for data management, monitor data usage, and enforce compliance with data standards. Data governance policies and procedures must be updated and reviewed regularly to meet an organization's needs effectively.
Popular tools for data governance include Informatica Cloud Data Governance and Catalog, Egnyte, and SAP Master Data Governance.
Data orchestration involves managing the scheduling and execution of data workflows. As for this part, Apache Airflow is a popular open-source platform choice used for data orchestration across the entire data pipeline. It provides a user-friendly interface to schedule batch jobs, chain tasks together, and monitor the progress of data workflows.
Data versioning
Data versioning is the practice of tracking changes made to data over time, much like version control systems in software development. In the context of modern data stacks, it refers to the ability to track and manage changes to data as it flows through various stages of the data pipeline.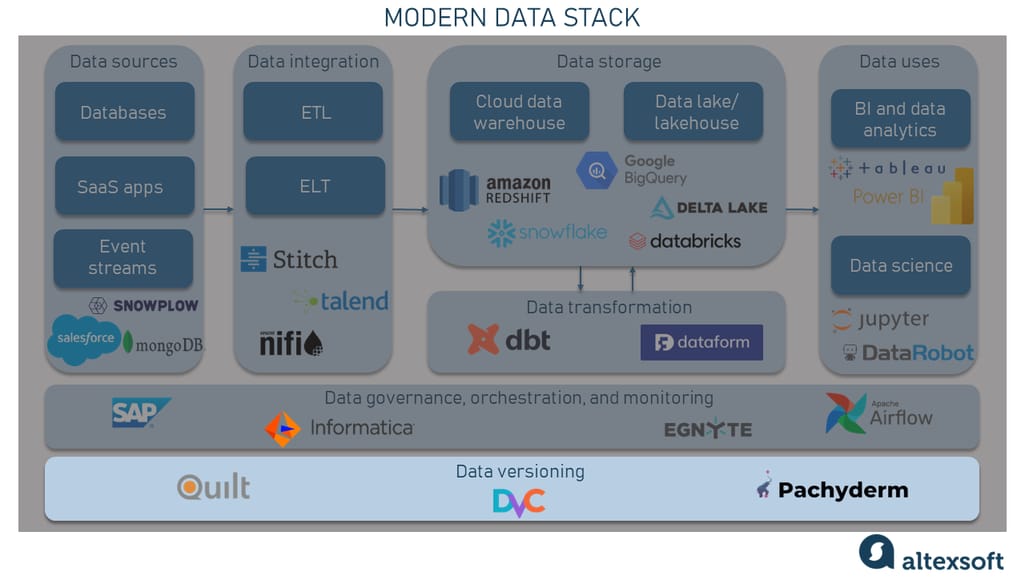
Data versioning component in a modern data stack
Some popular data versioning tools include DVC, Quilt, and Pachyderm. These tools are typically compatible with other components of the data stack, such as the data warehouse or lake.
The key features of data versioning tools include the ability to:
- track changes to data at different stages of the data pipeline;
- compare different versions of data to identify changes and discrepancies;
- roll back to previous versions of data if needed;
- collaborate on data changes with team members through version control; and
- monitor and audit changes made to data to ensure compliance with data governance policies.
Also, many other instruments offer their built-in versioning features or integrations with version control systems like Git. For example, the aforementioned dbt versions SQL scripts for data transformation.
Now you're probably asking yourself, "Do I need all of these tools to enter the modern data stack game?"
Well, no, you don't :)
Modern data stacks are designed with a modular approach, allowing for compatibility with other components and tools in a plug-and-play manner. This flexibility allows for the swapping of components as an organization requires and for customization to work with existing infrastructure. Unlike traditional monolithic architecture, the modularity of MDS enables adding as many components as needed, avoiding vendor lock-in. For instance, if a particular tool from a vendor is unsuitable for the data storage layer, organizations can easily switch to another vendor that meets their needs better.
For smaller organizations, not all components may be necessary immediately. However, as the organization grows and its needs become more complex, additional tools can be added or swapped in as needed. This allows for scalability and adaptability in the MDS setup.
Modern data stack implementation use cases
Below you will find a few examples of modern data stack setups. Please note that each company makes individual technology choices based on its business objectives and opportunities. So you may find tools that haven’t been mentioned above. Moreover, many enterprises often invest in the custom development of software that will be tailored to their data infrastructure purposes.
Airbnb
Airbnb is an online travel platform that allows people to find and rent short-term lodging in various locations around the world. The company uses a modern data stack to support its operations and business growth. It’s a combination of open-source and commercial tools designed for cloud-native environments.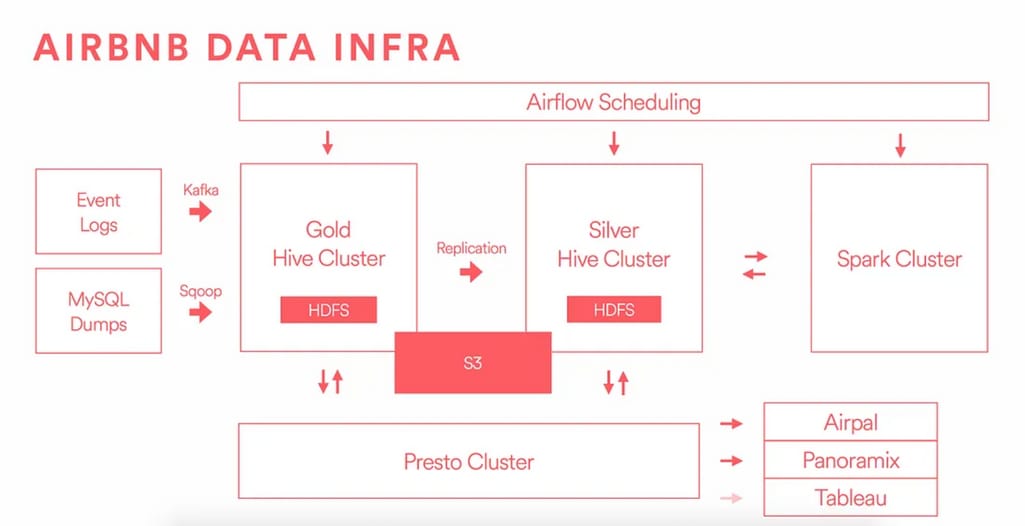
A simplified diagram shows the major components of Airbnb's data infrastructure stack. Source: The Airbnb Tech Blog on Medium
To start, Airbnb has a centralized data warehouse that is built on top of Apache Hadoop and hosted on the Amazon S3 cloud platform. They use Amazon's Redshift for faster query times and to manage their massive amounts of data, Apache Hive for data processing, and Apache Airflow for data orchestration.
Airbnb also relies on data transformation tools such as dbt to convert their raw data into usable formats for business intelligence and data analytics. They opt for Tableau, a popular BI tool, to enable self-service analytics across the organization.
In terms of data governance, Airbnb uses a combination of automated and manual processes to ensure data quality and security. They have a dedicated data governance team that works to establish policies, standards, and best practices for data management. This includes defining data ownership, access controls, and auditing procedures.
Uber
Uber is a technology company that relies heavily on data to provide its services, and as such, has built a modern data stack to support its operations. Uber uses a cloud-based architecture with a primary focus on a scalable and reliable data processing system. To build its data stack, Uber chose a combination of open-source and proprietary technologies that were tailored to its specific needs.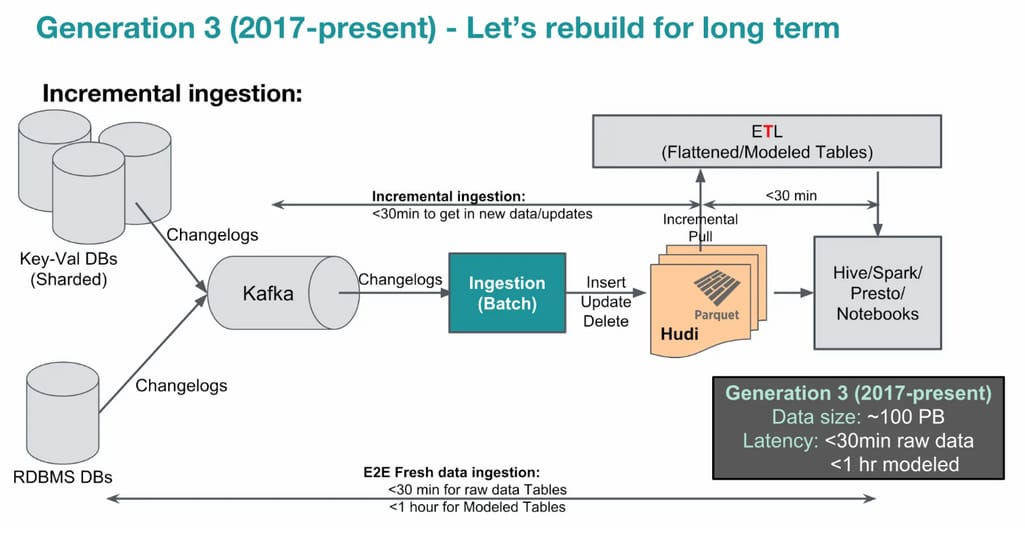
The third generation of Uber's Big Data platform. Source: Uber
At the core of Uber's data stack is Apache Hadoop, which is used for storing and processing large amounts of data. At the same time, Uber developed Apache Hudi (Hadoop Upserts and Incremental) — a storage and data management library to handle large datasets that need frequent updates. This was done to deal with the limitations Uber had when using HDFS (Apache Hadoop Distributed File System). Hudi provides features such as incremental data processing, record-level insert and update, and data partitioning.
To manage data ingestion, Uber uses Apache Kafka, a distributed messaging system that collects and stores data from various sources. The data is then processed with Apache Spark, an open-source analytics engine for large-scale data processing. Uber also takes advantage of other open-source tools such as Presto and Hive to query data in its data warehouse.
Uber's data science team leverages a variety of machine learning and artificial intelligence techniques to analyze data and gain insights. To enable this, Uber has built a platform called Michelangelo for creating, deploying, and managing machine learning models.
To ensure data governance and security, Uber has implemented strict data access controls and auditing mechanisms. It also has a dedicated data privacy team that ensures compliance with laws and regulations.
How to build a modern data stack that will fit your business needs
Now that you have a grasp of the components that make up a modern data stack, let's take a closer look at the step-by-step process involved in setting up your own data stack.
Define your data needs and goals
To build a modern data stack that fits your business needs, start by defining your data needs and goals. Identify the key data sources, the data you need to capture, and the insights you want to generate. This will help you determine the components and tools required in your stack.
Build a strong team of data professionals
With the right team, you can ensure that your modern data stack is optimized for your business needs and delivers actionable insights to drive growth and success. Also, consider hiring a data architect who can help design and implement your data stack, ensure data quality and security, and provide guidance on data governance. This person can work with your IT and business teams to define data needs and goals, choose the right components, and establish a data culture within your organization.
Choose the right components for your organization
Choosing the right components is critical to building an effective data stack. Consider factors such as the size and complexity of your data, the number of data sources you need to integrate, and the skill sets of your team. Choose components that are cloud-native, easy to use, and offer the functionality you need to achieve your data goals.
Ensure data governance and security
Data governance and security should also be top priorities when building your data stack. Ensure that your data is protected from unauthorized access or misuse and that your stack complies with relevant data privacy laws and regulations. This will help you avoid costly data breaches and maintain trust with your customers.
Establish a data culture within your organization
Establishing a data culture within your organization is key to ensuring the success of your data stack. Encourage collaboration between teams, provide regular training and support, and make data accessible to everyone who needs it. This will help ensure that your data is used effectively and that everyone in your organization is on the same page.
Regularly review and update your data stack
Finally, regularly review and update your data stack to ensure that it continues to meet your evolving business needs. Monitor performance, review data quality, and consider new tools or components as your needs change. With the right approach, you can build a modern data stack that drives business value and helps you stay competitive in a data-driven world.