Machine learning evangelizes the idea of automation. On the surface, ML algorithms take the data, develop their own understanding of it, and generate valuable business insights and predictions — all without human intervention. In truth, ML involves an enormous amount of repetitive manual operations, all hidden behind the scenes.
Citing Microsoft’s principal researcher Rich Caruana, "75 percent of machine learning is preparing to do machine learning… and 15 percent is what you do afterwards." This leaves only 10 percent of the entire flow automated by ML models. The rest is done by data engineers, data scientists, machine learning engineers, and other high-trained (and high-paid) specialists. But at least part of their work can be speeded up and simplified by AutoML.
What is AutoML and how does it relate to MLOps?
Automated machine learning or AutoML is the process of reducing manual work in the machine learning pipeline with the help of special software tools. It boosts the performance of ML specialists relieving them of repetitive tasks and enables even non-experts to experiment with smart algorithms. Namely, AutoML takes care of routine operations within data preparation, feature extraction, and model optimization during the training process, and model selection.
In brief, AutoML promises to
save time and resources needed to solve ML problems,
allow data scientists to concentrate on specialized tasks and research,
simplify ML adoption for businesses,
eliminate human errors and
increase the accuracy of predictions.
AutoML objectives and benefits overlap with those of MLOps — a broader discipline with focus not only on automation but also on cross-functional collaboration within machine learning projects.
Also called DevOps for machine learning, MLOps is a mix of philosophy and practices that facilitates mutual understanding between a data science team and operations specialists. Similar to DevOps, it exploits methods of continuous integration and delivery (CI/CD) to get ML models live in the fastest possible, automated way.
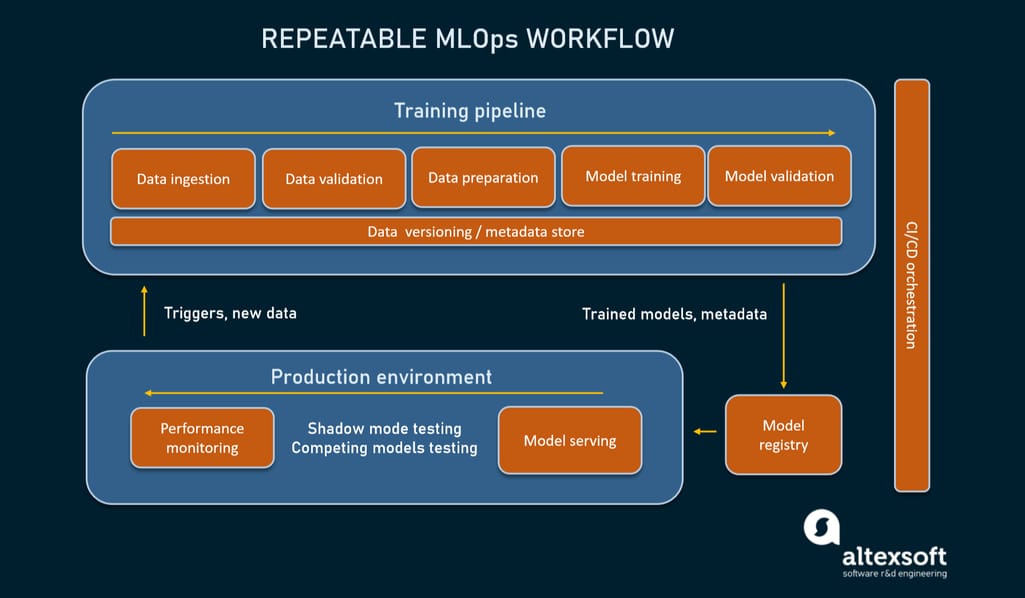
MLOps cycle.
To grasp how DevOps principles can be integrated into machine learning, read our article on MLOps methods and tools. In the meantime, we’ll focus on AutoML which drives a considerable part of the MLOps cycle, from data preparation to model validation and getting it ready for deployment.
AutoML use cases
Before diving deeper into technological aspects, let’s take a closer look at key AutoML use cases. Currently, it helps businesses with anomaly and fraud detection, pricing and sales management, planning and scheduling, research and analysis, and other tasks. Below are several real-life examples, proving the practicality of automated machine learning across different industries.
Healthcare: identifying transplant candidates
The University of Pittsburgh Medical Center, UPMC for short, sprawls across 40 hospitals and provides services in various specialty areas, including living donor liver transplants (LDLT.) To be more specific, UPMC has the largest LDLT practice in the US.
Many Americans requiring liver transplantations aren’t aware of the LDLT option. To define one potential patient, UPMC previously had to contact 10,000 candidates, selected against 1,500 parameters. Things changed with employment of the Squark platform that focuses on low-code AutoML solutions. Now, a basic knowledge of statistics is enough to build and train ML models identifying people interested in LDLT services. The number of candidates to be reached shrinks from 10,000 to just 75, while the model development takes hours — instead of months.
Recruitment: removing unsuitable CVs
The world’s second largest HR provider, the Adecco Group relies on machine learning to reduce time-to-fill for jobs. Applying AutoML instead of the conventional, manual approach enabled the company to launch 60 ML projects utilizing 3,000 models in just three weeks. The best performing models filter out up to 37 percent of CVs that don’t match the position, saving time for recruiters and boosting their productivity by 10 percent.
Telecommunications: predicting equipment failure
Standing for Mobile Broadband Network LTD, MBNL is a leading provider of telecommunication services, jointly owned by two British most innovative mobile operators.
The company takes care of 22,000 network towers across the UK. To avoid failures between regular checks, MBNL implemented AI-driven predictive maintenance and benefitted from AutoML. The automated approach allowed for completing proof-of-concept within six weeks while typically it would take one to two years.
ML algorithms forecast over 50 percent of air conditioning failures a month before they actually happen. Such failures can result in overheating and lead to service disruption. MBNL uses predictions to schedule maintenance activities and prevent costly downtimes.
A large Australian company that provides financial services, invested in AutoML to speed up the development of models detecting fraud cases. Due to the automation of the feature extraction and training process, hundreds of models can be generated and assessed within an hour. It takes three hours to complete a production-ready model, capable of detecting a significant amount of additional fraud.
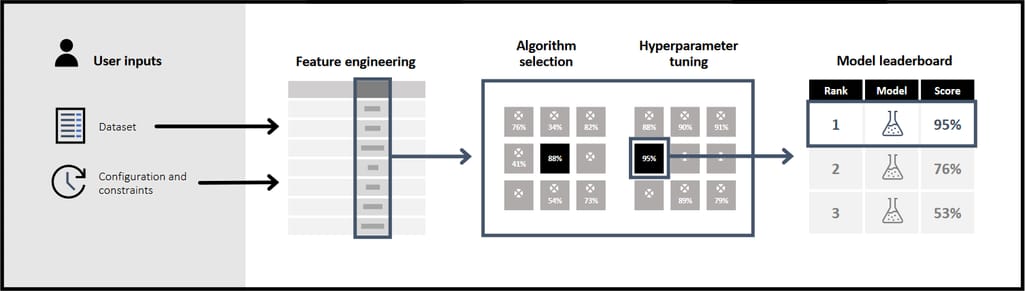
Steps covered by AutoML
Businesses are highly interested in the end-to-end automation of machine learning development. Yet, such a self-sufficient workflow, with no man in the loop, still remains far-fetched. At the same time, the above-mentioned use cases demonstrate that even the available level of AutoML makes a big difference, reducing the ML cycle from years and months to hours. Let’s explore the stages where current AutoML systems already show or at least promise the best results.
ML development phases where AutoML shines.
Data preprocessing
Almost all AutoML systems offer some types of basic data preprocessing, which includes identifying and replacing missing values, scaling, finding and removing duplicates, converting categorical or qualitative variables (like gender, age group, and other attributes) into numerical ones, and so on. This also includes splitting your data into training and validation sets.
Feature engineering and selection
In machine learning, features are important properties or attributes that represent the problem you are going to solve. Say, if you run an online travel agency and want to build an ML-driven flight price predictor to engage more visitors, the set of features will include departure and arrival time, flight distance, seasonality, the operating airline, and many other factors impacting airfares.
The model accuracy dramatically depends on attributes it takes as input. Feeding your algorithm the right food involves two key steps
feature engineering or feature extraction when useful properties are drawn from raw data and transformed into a desired form, and
feature selection when irrelevant attributes are discarded.
Obviously, you need domain expertise to understand what is right or wrong for your case. Yet, besides specific knowledge, the process of feature creation involves a lot of routine operations that can be streamlined without sacrificing any quality. And sometimes, generic features may be extracted entirely automatically to result in predictions of satisfactory accuracy.
Algorithm selection
With AutoML, you don’t need to bother about deciding the right algorithm for your problem. The software will make this choice itself, picking from the existing portfolio of options the one fitting your task best.
Hyperparameter optimization and model selection
The accuracy of the forecast depends not only on features but also on hyperparameters or internal settings that dictate how exactly your algorithm will learn on a specific dataset. Hyperparameter optimization (HPO) or tuning aims at finding the configuration that will generate a predictive model of the highest quality.
The manual HPO is quite time-consuming as you need to iterate training for each new set of hyperparameters and explore numerous options one by one. Unlike humans, AutoML tools can run experiments with thousands of candidate models and quickly select the top-performing one. That’s why this phase is considered a core focus of AutoML.
Neural architecture search
Neural architecture search or NAS is a subset of hyperparameter tuning related to deep learning, which is based on neural networks. It pursues the same goal as HPO: to find a configuration that will perform best for a specific task.
NAS automatically tests and assesses a large number of architectures to discover the most fitting one. To tweak neural networks, NAS tools apply techniques like reinforcement learning and genetic algorithms.
How NAS relates to HPO and AutoML.
Today, NAS is developing in leaps and bounds, supported by a significant number of research projects. For example, the Model Search platform developed by Google Research can produce deep learning models that outperform those designed by humans — at least, according to experimental findings.
Yet, it’s worth noting that NAS is still far from widespread adoption as it requires significant computational resources to train, test, and evaluate multiple neural networks.
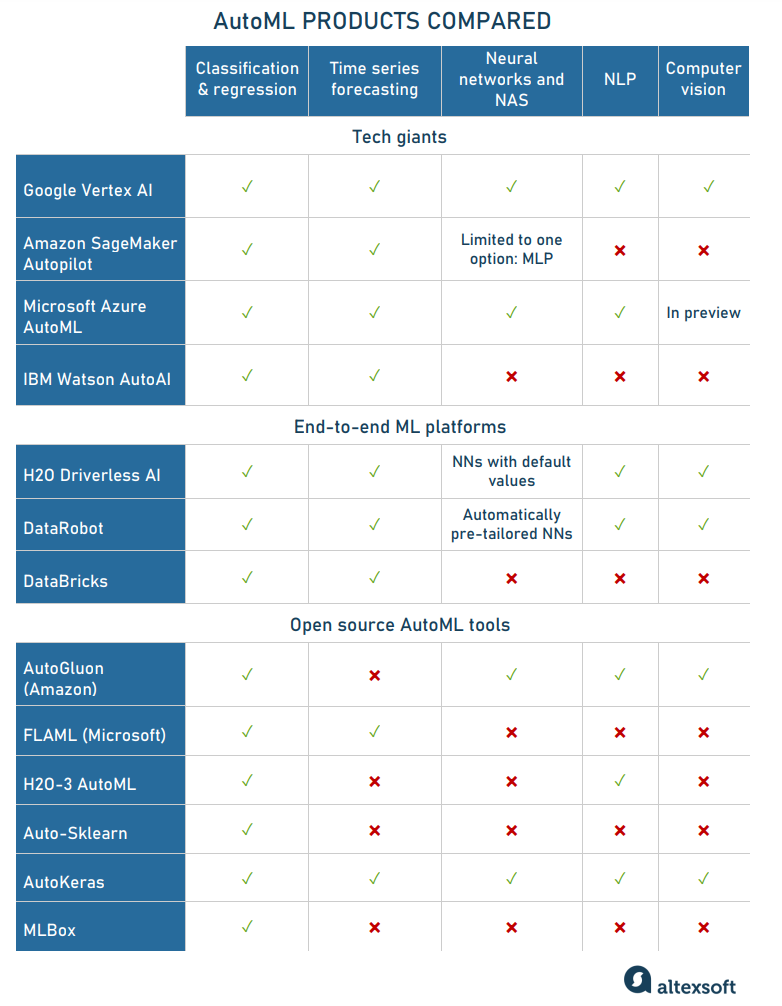
AutoML tools: general overview
The number of tools around AutoML is constantly growing, so it’s easy to get lost amidst the variety of options. The main difference between them lies in the range of tasks and types of data they work with.
By default, AutoML software provides
a drag-and-drop interface or / and Jupyter Notebook environment all data scientists are familiar with,
support for tabular data, and
a set of basic algorithms for two major machine learning tasks — classification to define a category of a given object and regression to predict numerical values.
For better guidance, we’ve divided existing AutoML offerings into three large groups — tech giants, specific end-to-end AutoML platforms, and free open source libraries.
Tech giants: Google, Amazon SageMaker, Microsoft Azure, and IBM Watson
Google, Amazon, Microsoft, and IBM are four leading providers of machine learning as a service (MLaaS), and you can read more about it in our article dedicated to their MLaaS products. Here, we’ll only briefly highlight their contribution to the AutoML space.
Google Vertex AI: a unified interface for the entire MLOps cycle
Google entered the automated machine learning arena in 2018. Three years later, in 2021, it launched Vertex AI, an end-to-end MLOps platform with a unified interface for both AutoML and custom tools to build models manually.
The technology supports tabular, image, text, and video data, and also comes with an easy-to-use drag-and-drop tool to engage people without ML expertise. For data scientist, it has an integrated Jupyter Notebook environment
Amazon SageMaker Autopilot: building models for one-click deployment on AWS
AWS started adding AutoML capabilities to its SageMaker platform in 2019. Now, it has a separate tool — Autopilot — to automatically build, train, and tune models. Then, selected models can be deployed in one click into the AWS production environment or you may further iterate them in SageMaker Studio.
Autopilot supports only one type of neural networks, a multilayer perceptron (MLP), and is limited to tabular data. To experiment with images and texts, you need another SageMaker tool, JumpStart. In October 2021, Autopilot at last expanded its functionality to time series forecasting.
Microsoft Azure AutoML: a wide range of algorithms and computer vision in preview
Microsoft offers two separate AutoML options. Data scientists and other professionals can develop models with Jupyter notebooks and Python SDK. For non-techs, there is a simple, no-code interface enabling you to start training models on your data with just a few clicks.
Azure AutoML takes advantage of over 30 algorithms to solve classification, regression, and time series forecasting tasks. It’s also capable of processing raw texts, using an advanced BERT deep learning model for NLP. In October 2021, Microsoft also announced the launching of the public preview version of AutoML for images, which allows users to try and test upcoming computer vision features.
IBM Watson AutoAI: achieving business goals with CSV files but no support for images and texts
The AutoAI feature in IBM Watson Studio provides a graphical tool to upload and pre-process training data, choose an algorithm, and calibrate its parameters for achieving business objectives. Keep in mind, though, that AutiAI consumes information in CSV format only and the size of a dataset must be less than 1 GB.
End-to-end enterprise AutoML platforms: H2O.ai, DataRobot, and Databricks
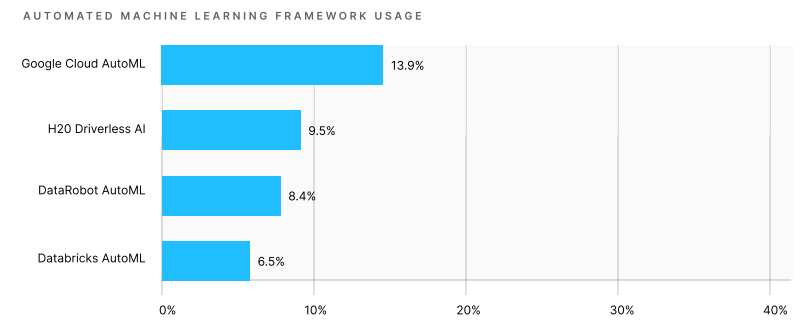
According to the 2020 Kaggle State of ML and Data Science Survey, of all tech giants, only Google hit the top four most used AutoML frameworks. Three other leaders are enterprise ML platforms automating to a certain degree each step of the machine learning cycle.
All these systems natively support big data technologies (Hadoop and Spark) and simplify model deployment — both on-premises or on any cloud, including AWS, Google, and Microsoft Azure. In the case of cloud deployment, your ML product will be wrapped as a REST API endpoint.
H2O Driverless AI: a global ML platform with focus on interpretability
H2O.ai is an open-source AI platform used by over 20,000 companies globally. Its Driverless AI enterprise solution aimed at simplifying each step in ML workflow, from automated detection of data type to creating model documentation. H2O stresses machine learning interpretability providing visual techniques to explain model results.
Besides tabular data, the system performs text and image processing. When it comes to deep learning algorithms, they are used with default parameters or can be tuned manually.
DataRobot AutoML: a pioneer in AI automation generating explainable results
DataRobot markets itself as an AutoML inventor, which introduced the new category of software back in 2013, before anyone else. Currently, the enterprise platform works with both structured and unstructured data and automatically pre-tailored deep learning algorithms, concentrating on AI explainability. DataRobot provides visual insights to make users understand which features impact the prediction.
Databricks AutoML: a smart system revolving around Spark and Big Data
Databricks is created by the developers of Apache Spark and as such focuses on Big Data analytics. Its AutoML feature is built around Spark and MLflow, the company’s open-source tool to manage ML lifecycle. Automation from Databricks comes with certain limitations: For example, it doesn’t support raw texts and image data.
Open-source libraries and frameworks: AutoGluon, FLAML, AutoKeras, and others
Many large AutoML players provide free open-source products to democratize data science. Though they have limited functionality and can’t be directly compared with fully-fledged platforms, each of these tools will be a useful addition to your ML toolbox.
AutoGluon by Amazon requires only a few lines of code to quickly produce deep learning models. It automates tuning and selection of the best candidates for tabular, image, or text classification, and object detection. AutoGluon also enables neural architecture search but doesn’t specifically cover time series forecasting.
FLAML (Fast and Light AutoML) by Microsoft is a lightweight Python package that helps data scientists choose a state-of-the-art ML model at a low computational cost. It’s estimated that in 62 percent of cases, FLAML is capable of achieving the same model performance as enterprise versions, consuming only 10 percent of the computational resources.
H20-3 AutoML library comes with feature extraction and model training functions and an interface similar to Jupyter Notebooks. It supports tabular data and texts but doesn’t tackle problems of time series forecasting and computer vision.
Other popular open-source AutoML tools include the following solutions.
Auto-Sklearn is built around scikit-learn, a free ML library for Python. It embraces 15 classification and 14 feature preprocessing algorithms but doesn’t support text and image data and deep neural networks.
AutoKeras was developed by data scientists from Texas A&M University with the goal of making ML available to everyone. It takes advantage of the popular deep learning library Keras as well as of the end-to-end machine learning platform TensorFlow. The system works with tabular data, images, and texts and employs neural architecture search to tune deep learning models.
MLBox is another widely-used Python library that simplifies data pre-processing and hyperparameter optimization. Yet, it offers only basic feature engineering and still requires a lot of manual work for model training and testing.
When to use AutoML and how to approach its limitations
With all the benefits offered by automation, it’s in no way a valid replacement for data scientists but rather a helping hand for them. And the volume of menial work AutoML tools can take away from humans will depend on the nature of your ML project.
Your project relies on supervised learning and small-to-medium structured datasets
Why and when do you critically need data scientists? To create state-of-the art features.
This is the exact area where AutoML shines. It focuses on supervised learning and works best for structured data and small to medium datasets. The ability to sift through thousands of model options within hours makes it unrivaled for proof of concept and prototyping.
Note, though, that the accuracy of predictions largely depends on the quality of features. When generated automatically, in brute force, they may fall short compared to those manually created. Even the most advanced AutoML platforms can’t incorporate domain expertise and replace human creativity and imagination that play a key role in crafting meaningful attributes.
You are going to explore data, using unsupervised learning
Why and when do you critically need data scientists? To interpret results.
Unsupervised machine learning is an important technique for exploring raw data and identifying hidden patterns without human intervention. Unlike supervised learning, it doesn’t require costly and time-consuming data labeling. Its task is to group your unsorted information into clusters based on similarities and relations a model has found on its own.
Yet, the logic and results of clustering must be accurately interpreted. And this is impossible to do without domain knowledge. Here, human expertise is so critical that it leaves this approach out of the scope of AutoML (though some platforms like H2O have already started experimenting with unsupervised learning algorithms.)
More than often, unsupervised learning is applied to better understand your data. Once clusters are explained by humans, they can be used to create labeled datasets for further processing with supervised algorithms. At this point, AutoML can eventually get into a game.
You are working with deep learning
Why and when do you critically need data scientists? To tune neural networks at less computational cost.
AutoML rapidly expands into the deep learning area but it’s still more about research than practical application, and for a reason. The automated configuring, training, and evaluation of neural networks is high in computational expense and it may take days of computing to find the right architecture (though there are studies promising to reduce search time to seven GPU-hours.) For now, far fewer resources are consumed if tuning of such models is performed by skilled data scientists.
You solve complex problems and do R&D
Why and when do you critically need data scientists? To refine your model after the prototyping phase
AutoML efficiently evaluates a model quality against clear, easy-to-calculate metrics. However, automated tools fail when you need to apply a custom logic or assess results against a set of diverse criteria. And this is inevitable if you run innovations and do research and development (R&D).
In prototype projects, you may reduce the complexity of your problem to simpler measurements. But later, you’ll have to turn to a data scientist who will refine your model manually.