

The larger the company, the more data it has available to generate actionable insights. Yet, more often than not, businesses can’t make use of their most valuable asset — information. Why? Because it is scattered across disparate systems, not really available for analytical apps.
Clearly, common storage solutions fail to provide a unified data view to meet the needs of companies for seamless data flow. One of the innovative ways to address this problem is to build a data hub — a platform that unites all your information sources under a single umbrella.
This article explains the main data hub concepts, its architecture, and how it differs from data warehouses and data lakes. We’ll also analyze some of the data hub products existing in the market to explore how this technology works and what it actually can do.
What is Data Hub?
A data hub is a central mediation point between various data sources and data consumers.
It’s not a single technology, but rather an architectural approach that unites storages, data integration, and orchestration tools. With a data hub, businesses receive the means to structure and harmonize information collected from various sources.
A data hub serves as a single point of access for all data consumers, whether that’s an application, a data scientist, or a business user. It also allows for managing data for various tasks, providing centralized governance and data flow control capabilities.
Data hubs are often mentioned along with data warehouses and data lakes as different approaches to a data platform architecture. But they are not interchangeable and are often used in conjunction. To give you a clear distinction between these three similar concepts, let’s make a quick comparison.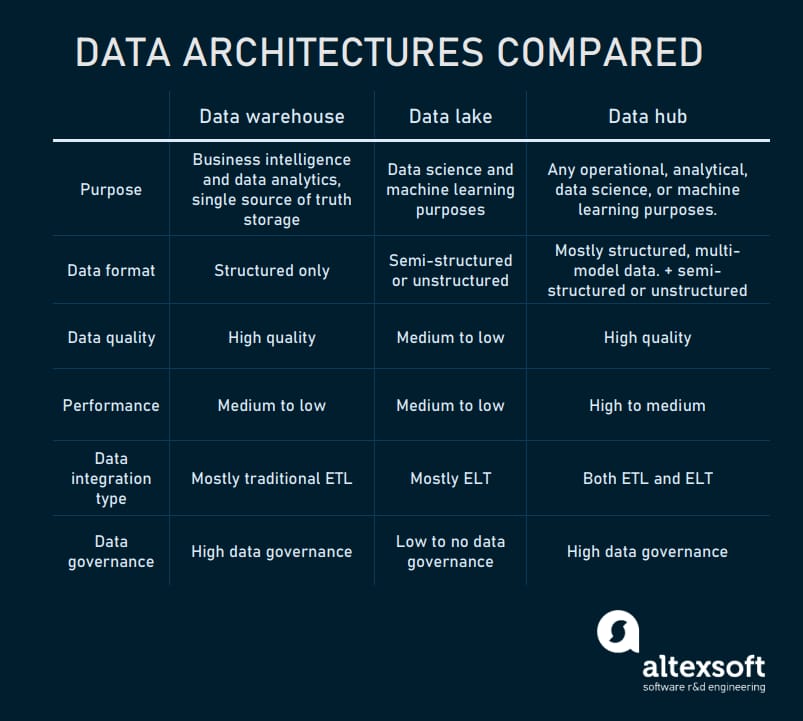
Data warehouse vs data lake vs data hub comparison table
Data warehouse vs data hub
A data warehouse (DW) is a unified storage for all corporate data. The main purpose of a DW is to enable analytics: It is designed to source raw historical data, apply transformations, and store it in a structured format. This type of storage is a standard part of any business intelligence (BI) system, an analytical interface where users can query data to make business decisions.
Data integration in a DW is done using ETL (Extract Transform Load) tools that provide control over data transmission, formatting, and overall management. An ETL approach in the DW is considered slow, as it ships data in portions (batches.) The structure of data is usually predefined before it is loaded into a warehouse, since the DW is a relational database that uses a single data model for everything it stores.
In a nutshell, a model is a specific data structure a database can ingest. It predefines how information is related and how users can query it. Data models are used to unify the structure of disparate information and simplify querying for the end users.
A data hub connects various sources of information, including a DW/data lake, to provide users with the required data, no matter its model or whether it’s structured at all. That said, a DW or data lake can be both a source of data and a destination point. A data hub, in turn, is rather a terminal or distribution station: It collects information only to harmonize it and sends it to the required end-point systems.
Data lake vs data hub
A data lake differs substantially from a DW as it stores large amounts of both structured and unstructured data. It uses ELT (Extract, Load, Transform) that loads data as is and transforms it once it is requested. This approach suggests a swifter way to upload and prepare data, compared to the traditional ETL used in a data warehouse.
Data lakes are typically intended for data exploration and machine learning purposes. This means a user has to decide what queries and scripts can be suitable to work with data. The result of experimentation supplies downstream applications with prepared data.
A data hub serves as a gateway to dispense the required data. So the use of unstructured or semi-structured data is also available in a data hub since a data lake can be a part of it. But its main purpose is to harmonize various data, so it can be queried and digested by multiple systems such as transactional applications, analytical interfaces, and machine learning models.
Data integration in a data hub is implemented through a set of custom ETL/ELT and orchestration tools. This is the main part of data hub functionality since it gives administrators control over information used for different tasks. Sitting on top of the storages, the data hub acts as a dashboard for the data platform, enabling data management and delivery.
Data hub architecture
To understand the basic concepts of a data hub, we need to break the whole process of data transmission into layers. Here is a short view of these layers and tasks they resolve.
- The source system layer is responsible for the extraction of data from its original source and integration of sources with the data hub.
- The data integration layer holds any transformations required to make the data digestible for end users. This often involves such operations as data harmonization, mastering, and enrichment with metadata.
- The storage layer corresponds to the needs of database management and data modeling.
- The data access layer unites all the access points connected to the data hub (transactional application, BI systems, machine learning training software, etc).
- The orchestration layer provides control over data integration, flows, transformations, and data governance.
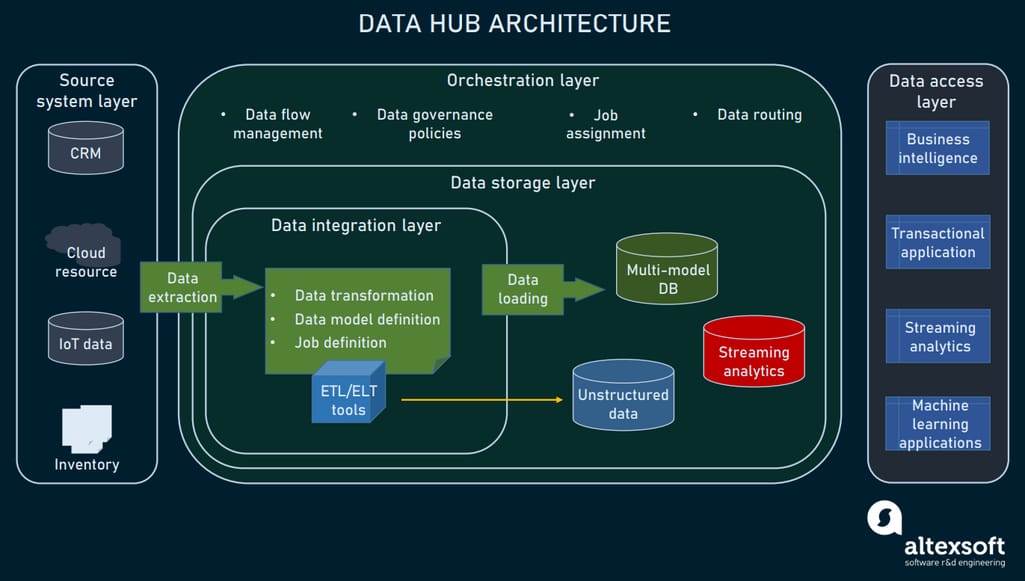
Data hub architecture
Now, let’s discuss the specific tasks a data hub performs and the tools used in its architecture logic.
Source system layer: data extraction
The source layer is usually represented by distributed storages that form information silos. These sources can be an ERP, CRM, web resource, IoT device, data warehouse, or even a data lake. Because of the difference in data structures and storage types, it is difficult to integrate sources with the data end points, such as business applications, analytical systems, data science sandboxes, etc.
So, first of all, a data hub consists of a set of connectors that transmit data from its original storage to the destination point. These can be APIs or dedicated data integration tools that allow custom configuration of connected sources. Here are a few solutions that address connectivity tasks:
All of the mentioned tools provide capabilities to integrate distributed data sources, manage data, and assign data transmission rules.
Since data extraction is a large part of data hub architecture, we separate the source system layer from the data integration layer. But keep in mind that technologically these layers are inseparable as storage connectors are often a part of ETL/ELT technologies.
Data integration layer: data harmonization, enrichment, and mastering
Considering a specific job an end-point system will run with data, we need to structure and format it accordingly. All the transformations are applied via a custom set of ETL/ELT tools. These tools can also automate the process of transformation when a data model is defined.
Besides basic formatting procedures, there are three critical tasks an ETL/ELT toolset helps with in data hub architecture.
Harmonization of data includes numerous operations such as data cleaning, indexing, mapping, formatting, providing semantic consistency, and many more. As the output, the data collected from various sources becomes consistent and readable for end-point systems like analytics applications.
Mastering relates to managing copies of the same data to establish a single version of truth. Duplicates of data may occur in a separate source system and get loaded to a unified storage.
Usually, we run deduplication to exclude different meanings of the core business entities. But if we deal with copies in data hub architecture, we need to make sure each copy conveys relevant meaning. Mastering applies transformation by assigning a “master copy” as a reference. Related information will be updated according to the current master copy, which helps maintain consistency of data.
Enrichment with metadata is another important component. Metadata is any additional information that provides context to the data in question. For example, it can clarify who the salesperson was for a specific item. Enrichment helps us increase the value of data by adding extra context.
As for the toolset, there are some well-known solutions such as Apache Kafka, a powerful data integration, event-streaming, and data analytics platform. Kafka fuels high-throughput data flows that may be required in event-driven architecture, streaming analytics, or any applications that use constantly updating operational data.
Other Apache tools are also often used for data hub architecture because they are open source and flexible. However, you may also pay attention to similar platform-specific tools for data integration in the data hub:
Since data undergoes preparation for specific tasks, it can be moved to the storage layer.
Data storage layer: storing and applying data models
Storage in a data hub architecture can be anything from a data warehouse or data lake to small storages like data marts. However, the data hub can also take advantage of a specific storage type called a multi-model database that can nest several data models on a single backend.
Relational databases are capable of using a single data model, which means there is only one specific format of data you can upload to it and a couple of ways to query it. In contrast, multi-model databases are suited for storing multiple data structures, or even combining semi-structured and unstructured data.
This gives substantial capabilities for a data hub architecture, as we can upload all of our harmonized and mastered data into a single storage, which can be queried by the data consumers. Here are some of the well-known databases of this type:
Data lakes are often based on multi-model DB and can be met in existing data hub architectures like Cumulocity platform. Depending on how data will be used, it can be loaded in a storage before (in ELT process) or after (in ETL) any transformation.
Data access layer: data querying
Traditionally, the data is prepared to be used for a specific task. But those tasks are significantly different.
For instance, business intelligence users expect sales data to be strictly related to dates, regions, items, sums, etc. This defines a structure of data we need to create, so that a user can run queries and get the expected result. An operational application will require a different logic, since it receives data either when a trigger event occurs, on schedule, or works with an endless stream.
So there are many factors that impact how data can be queried including
- which data a user may require and where it is stored (how many databases relate to a single task);
- how a user will query the data (which query language will be applied);
- whether a user/application needs the data to be extracted by a specific request, trigger event, by schedule, or streamed;
- which operations a user/application will run with data, and whether the user needs a set of fixed queries; and
- which transformations should be applied to data.
A single case of how data will be used and queried is called “job.” And we can preprogram different jobs to guarantee seamless data quality, and desired performance for each specific case. Jobs will define how the data is loaded to the storage, structured, and accessed. Routing the data flow is a task that covers the whole data hub pipeline, since some data will be accessible only in structured format, while another part is queried in its initial form to apply transformations.
Finally, the data hub is integrated with numerous end points, which may be represented by business intelligence tools, a machine learning training application, an operational application, or real-time analytics. Depending on the end point, the integration with data storage may happen via API or a specific tool like Apache Kafka.
Orchestration layer: platform management and data governance
ETL/ELT and other data integration tools represent a set of scripts that semi-automate tasks such as data extraction, API integrations, data transformations, and more. An orchestrator usually comes with built-in data integration tools to supervise the whole process.
You can think of an orchestrator as a control dashboard with numerous capabilities. Since it serves as an administrator panel for the whole data hub. There are several major features in it:
- curate source integration and system end points,
- launch or stop data integration processes,
- define rules for data structuring and data access,
- route data between the instances of a data hub,
- define jobs for the end users or applications, and
- provide data governance via security policies and access rules.
Cloudera data flow management. Source: www.datainmotion.dev
Apache NiFi is an example of an open-source orchestrator. NiFi is used to manage the mediation logic and write routing rules for data platforms. It provides monitoring for the data flows and implements security via standard SSL, SSH, and HTTPS protocols, and data encryption.
But, for the most part, a data hub will either require a custom orchestrator, or you can use an existing one that comes with an ETL/ELT tool.
Data hub platform providers
Here, we’ll provide a short overview of data hub products. Since all of the platforms suggest relatively similar capabilities in terms of data management, integration, governance, and scalability, we’ll discuss only the main distinctions and extra features in their architecture.
MarkLogic Data Hub
The MarkLogic data hub is one of the largest providers of data hub solutions. Their architectural approach is based upon a multi-model storage called the MarkLogic Server. The data can be uploaded as is and transformed in the storage. While on the output, MarkLogic provides numerous integrations with BI software, application, and transactional storages.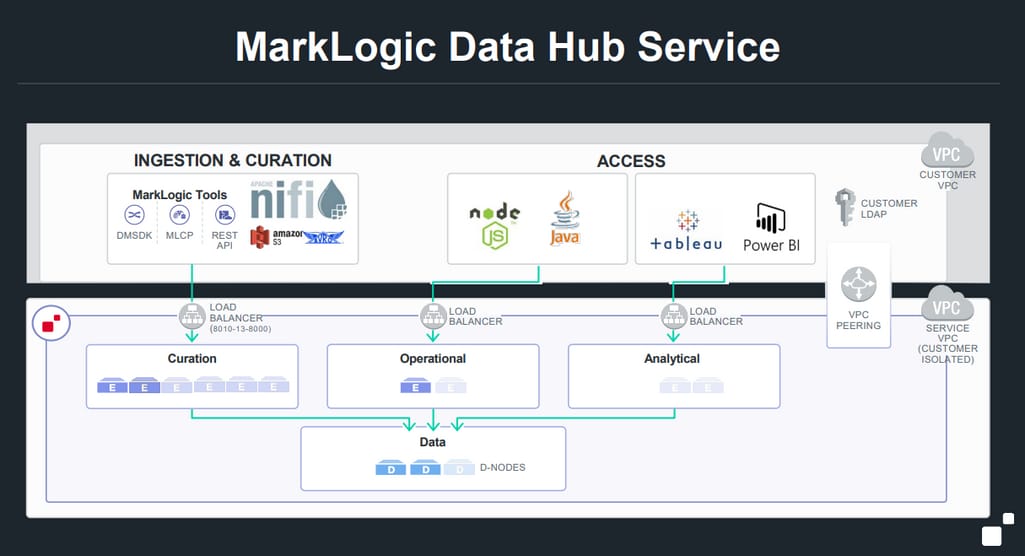
Marklogic data hub architecture. Source: marklogic.com
The MarkLogic platform uses Apache Kafka, a well-known, high-throughput processor for streaming analytics and IoT platforms as a part of its data integration set. So, if you are dealing with data streams or maintain real-time applications, that would be a plus.
Cloudera Data Hub
Cloudera data hub solution applies a different logic to their platform. A central storage where all the data is kept and transformed is implemented as a data lake. The integration of the data is done via a management console that splits collected data into clusters. Clustering unites data by the assigned jobs, meaning that each cluster is the specific data structure required for a certain task.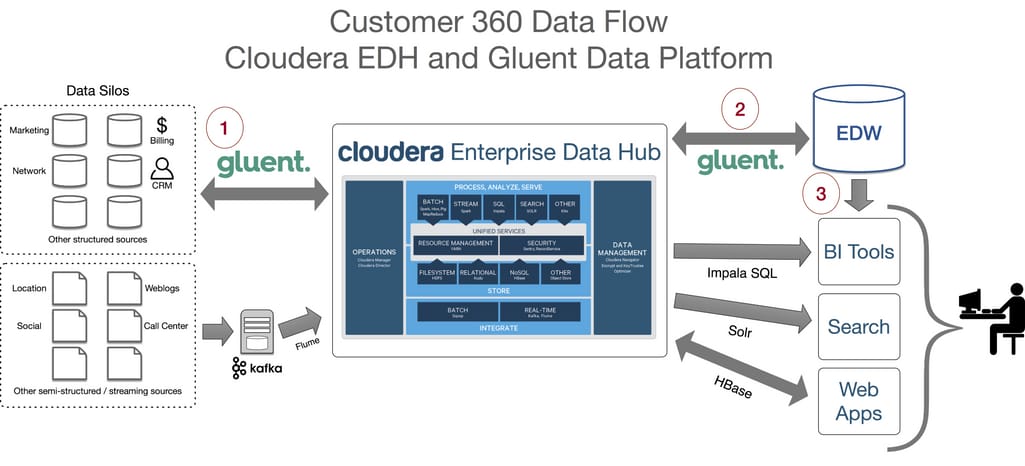
Cloudera data hub. Source: medium.com/@mRainey
In turn, a data lake serves as a single point of access for data consumers, offering data integrity and governance. Additionally, Cloudera also uses Apache Kafka for semi-structured sources and data streams.
Stambia
Stambia suggests using a traditional relational database as the hub of a platform. But they also mention that a data lake can be combined with a usual database to ingest unstructured data or work with data streams.
The unstructured data also includes any non-hierarchical data such as images, audio, video, graphs, etc., although the possibility to store such data comes with a standard data lake, where structuring happens via metadata enrichment.
Stambia data hub. Source: www.stambia.com
Stambia also mentions that its data hub platform relies on the ELT approach as the way to process high volumes of information. This makes it suitable for big data and streaming data analytics.
Cumulocity IoT DataHub
Cumulocity IoT DataHub is a specific type of data platform that targets IoT devices as its main source of raw data. However, the description of their platform seems to fit common data hub use cases.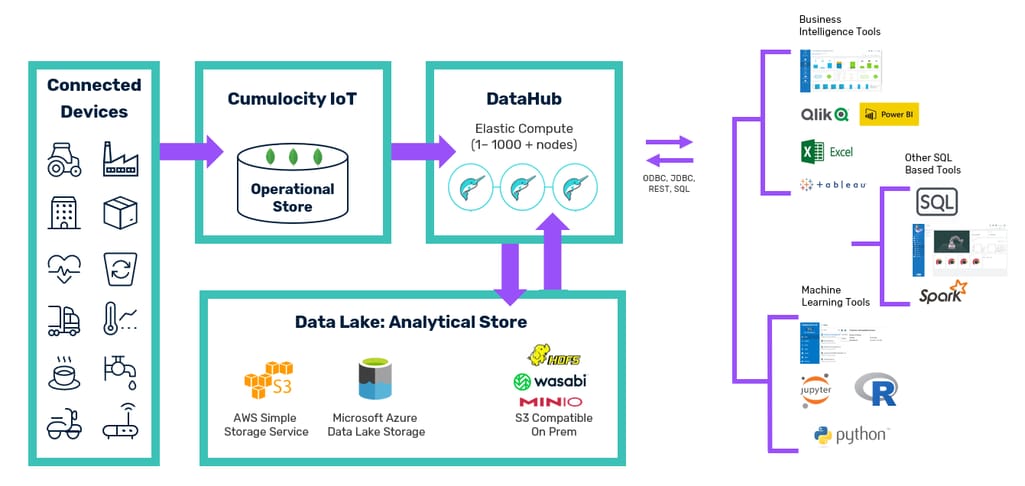
Cumulocity IoT data hub platform. Source: cumulocity.com
Cumulocity applies two types of storages to process data. The first is an operational database that performs data intake from the connected devices and passes it to a data hub. The data hub applies required transformation and passes the data to a data lake, which serves as the main storage of structured and unstructured data.
Whenever an application or a user queries a data hub, it performs an exchange with a data lake to provide data access. Various systems for streaming analytics and business intelligence can be connected to access data via the Cumulocity datahub.
As you can see, the architectural pattern differs from company to company. However, these variations still offer similar capabilities, providing the major data hub benefits.
When do you need a data hub?
Here we’ll try to answer a complex question, since a data hub isn’t a single technology you can install and run for good. A data hub represents a logical architecture of how businesses can implement their own data platform. And it solves specific problems with data management, data integrity, and infrastructure management.
There are a couple of scenarios in which you may need data hub architecture:
- Your existing data infrastructure is difficult to manage and scale. Point-to-point connections obstruct data management, since they require you to control scattered APIs, storages, and data integrations. Whenever you need to scale the platform, you’ll have to develop a new point-to-point connection.
- You need a single point of access for multiple data use cases. Most businesses establish a data platform to work with transactional data and apply business intelligence. If you have more data use cases, such as machine learning needs, pay attention to what a data hub is capable of.
- Your data isn’t properly governed. Maintaining multiple storages imposes a challenge to govern your data, since multiple database management systems require different security policies for its data models, data types, etc.
In case you are considering a data hub as an implementation of your data platform, it makes sense to first look at the market and explore existing solutions. If none of them fit your needs, the decision should be based on your budget and technology knowledge, because switching to a new type of architecture will require partial redevelopment of your data platform.