

If there was a data science hall of fame, it would have a section dedicated to the process of data labeling in machine learning. The labelers’ monument could be Atlas holding that large rock symbolizing their arduous, detail-laden responsibilities. ImageNet — an image database — would deserve its own style. For nine years, its contributors manually annotated more than 14 million images. Just thinking about it makes you tired.
While labeling is not launching a rocket into space, it’s still serious business. Labeling is an indispensable stage of data preprocessing in supervised learning. Historical data with predefined target attributes (values) is used for this model training style. An algorithm can only find target attributes if a human mapped them.
Labelers must be extremely attentive because each mistake or inaccuracy negatively affects a dataset’s quality and the overall performance of a predictive model.
How to get a high-quality labeled dataset without getting grey hair? The main challenge is to decide who will be responsible for labeling, estimate how much time it will take, and what tools are better to use.
We briefly described data labeling in the article about the general structure of a machine learning project. Here we will talk more about this process, its approaches, techniques, and tools.
What is data labeling?
Before diving into the topic, let’s discuss what data labeling is and how it works.
Data labeling (or data annotation) is the process of adding target attributes to training data and labeling them so that a machine learning model can learn what predictions it is expected to make. This process is one of the stages in preparing data for supervised machine learning.
For example, if your model has to predict whether a customer review is positive or negative, the model will be trained on a dataset containing different reviews labeled as expressing positive or negative feelings.
By the way, you can learn more about how data is prepared for machine learning in our video explainer.


How is data prepared for machine learning?
In many cases, data labeling tasks require human interaction to assist machines. This is something known as the Human-in-the-Loop model when specialists (data annotators and data scientists) prepare the most fitting datasets for a certain project and then train and fine-tune the AI models.
Okay, how do you get labeled data?
Data labeling approaches
Data labeling can be performed in a number of different ways. The choice of an approach depends on the complexity of a problem and training data, the size of a data science team, and the financial and time resources a company can allocate to implement a project.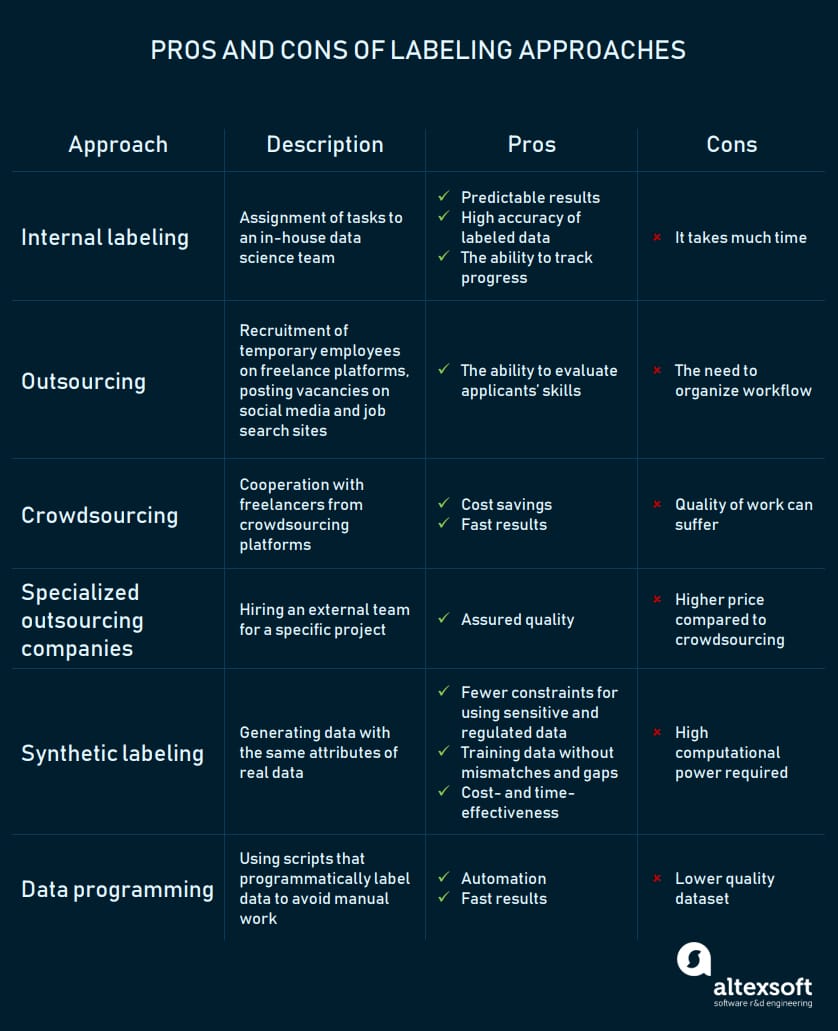
The pros and cons of different data labeling approaches
In-house labeling
That old saying if you want it done right, do it yourself expresses one of the key reasons to choose an internal approach to labeling. That’s why when you need to ensure the highest possible labeling accuracy and have the ability to track the process, assign this task to your team. While in-house labeling is much slower than the approaches described below, it’s the way to go if your company has enough human, time, and financial resources.
Let’s assume your team needs to conduct sentiment analysis. Sentiment analysis of a company’s reviews on social media and tech site discussion sections allows businesses to evaluate their reputation and expertise compared with competitors. It also gives the opportunity to research industry trends to define the development strategy.
You will need to collect and label at least 90,000 reviews to build a model that performs adequately. Assuming that labeling a single comment may take a worker 30 seconds, he or she will need to spend 750 hours or almost 94 work shifts averaging 8 hours each to complete the task. And that’s another way of saying three months. Considering that the median hourly rate for a data scientist in the US is $36.27, labeling will cost you $27,202.5.
You can streamline data labeling by automating it with semi-supervised learning. This training style entails using both labeled and unlabeled data. A part of a dataset (e.g. 2000 reviews) can be labeled to train a classification model. Then this multiclass model is trained on the rest of the unlabeled data to find target values — positive, negative, and neutral sentiments.
The implementation of projects for various industries, for instance, finance, space, healthcare, or energy, generally require expert assessment of data. Teams consult with domain experts regarding principles of labeling. In some cases, experts label datasets by themselves.
AltexSoft has built the “Do I Snore or Grind” app aimed at diagnosing and monitoring bruxism for Dutch startup Sleep.ai. Bruxism is excessive teeth grinding or jaw clenching while awake or asleep. The app is based on a noise classification algorithm, which was trained with a dataset consisting of more than 6,000 audio samples. To define recordings related to teeth grinding sounds, a client listened to samples and mapped them with attributes. The recognition of these specific sounds is necessary for attribute extraction.
The advantages of the approach
Predictable good results and control over the process. If you rely on your people, you’re not buying a pig in a poke. Data scientists or other internal experts are interested in doing an excellent job because they are the ones who’ll be working with a labeled dataset. You can also check how your team is doing to make sure it follows a project’s timeline.
The disadvantages of the approach
It’s a slow process. The better the quality of the labeling, the more time it takes. Your data science team will need additional time to label data right, and time is usually a limited resource.
Crowdsourcing
Why spend additional time recruiting people if you can get right down to business with a crowdsourcing platform?
Amazon Mechanical Turk (MTurk) is one of the leading platforms that offer an on-demand workforce. Clients register there as requesters, create and manage their projects with one or more HITs (Human Intelligence Tasks) on the Mechanical Turk Requester website. The website provides users with an easy-to-use interface for creating labeling tasks. MTurk representatives claim that with its wide community of workers, labeling thousands of images can take a few hours instead of days or weeks.
Another global online marketplace, Clickworker, has more than 1 million contractors ready to be assigned to image or video labeling and sentiment analysis tasks. The first stages of workflow are similar to the ones on MTurk. Task processing and allocation phases differ. Registered employers place their orders with predefined specifications and demands, the platform team drafts a solution and posts a required set of work on the order platform for freelancers, and the magic begins.
The advantages of the approach
Fast results. Crowdsourcing is a reasonable option for projects with tight deadlines and large, basic datasets that require using powerful labeling tools. Tasks like the categorization of images of cars for computer vision projects, for instance, won’t be time-consuming and can be accomplished by staff with ordinary — not arcane — knowledge. Speed can also be achieved with the decomposition of projects into microtasks, so freelancers can do them simultaneously. That’s how Clickworker organizes workflow. MTurk clients should break down projects into steps themselves.
Affordability. Assigning labeling tasks on these platforms won’t cost you a fortune. Amazon Mechanical Turk, for instance, allows for setting up a reward for each task, which gives employers freedom of choice. For example, with a $0.05 reward for each HIT and one submission for each item, you can get 2,000 images labeled for $100. Considering a 20 percent fee for HITs consisting of up to nine assignments, the final sum would be $120 for a small dataset.
The disadvantages of the approach
Inviting others to label your data may save time and money, but crowdsourcing has its pitfalls, the risk of getting a low-quality dataset being the main one.
Inconsistent quality of labeled data. People whose daily income depends on the number of completed tasks may fail to follow task recommendations trying to get as much work done as possible. Sometimes mistakes in annotations can happen due to a language barrier or a work division.
Crowdsourcing platforms use quality management measures to cope with this problem and guarantee their workers will provide the best possible services. Online marketplaces do so through skill verification with tests and training, monitoring of reputation scores, providing statistics, peer reviews, audits, as well as discussing outcome requirements beforehand. Clients can also request multiple workers to complete a specific task and approve it before releasing payment.
As an employer, you must make sure everything is good from your side. Platform representatives advise providing clear and simple task instructions, using short questions and bullet points, and giving examples of well and poorly-done tasks. If your labeling task entails drawing bounding boxes, you can illustrate each of the rules you set.
A clear illustration of image labeling dos and don’ts
You must specify format requirements and let freelancers know if you want them to use specific labeling tools or methods. Asking workers to pass a qualification test is another strategy to increase annotation accuracy.
Outsourcing to individuals
One of the ways to speed up labeling is to hunt for freelancers on numerous recruitment, freelance, and social networking websites.
Freelancers with different academic backgrounds are registered on the UpWork platform. You can advertise a position or look for professionals using such filters as skill, location, hourly rate, job success, total revenue, level of English, and others.
When it comes to posting job ads on social media, LinkedIn, with its 500 million users, is the first site that comes to mind. Job ads can be posted on a company’s page or advertised in the relevant groups. Shares, likes, or comments will ensure that more interested users see your vacancy.
Posts on Facebook, Instagram, and Twitter accounts may also help find a pool of specialists faster.
The advantages of the approach
You know who you hire. You can check applicants’ skills with tests to make sure they will do the job right. Given that outsourcing entails hiring a small or midsize team, you’ll have an opportunity to control their work.
The disadvantages of the approach
You have to build a workflow. You need to create a task template and ensure it’s intuitive. If you have image data, for instance, you can use Supervising-UI, which provides a web interface for labeling tasks. This service allows the creation of tasks when multiple labels are required. Developers recommend using Supervising-UI within a local network to ensure the security of data.
If you don’t want to create your own task interface, provide outsource specialists with a labeling tool you prefer. We’ll tell more about that in the tool section.
You are also responsible for writing detailed and clear instructions to make it easy for outsourced workers to understand them and make annotations correctly. Besides that, you’ll need extra time to submit and check the completed tasks.
Outsourcing to companies
Instead of hiring temporary employees or relying on a crowd, you can contact outsourcing companies specializing in training data preparation. These organizations position themselves as an alternative to crowdsourcing platforms. Companies emphasize that their professional staff will deliver high-quality training data. That way a client’s team can concentrate on more advanced tasks. So, partnership with outsourcing companies feels like having an external team for a period of time.
Outsourcing companies, such as CloudFactory, LQA, and DataPure, mostly label datasets for training computer vision models.
CloudFactory allows for calculating service price according to the number of working hours
Appen and CapeStart also conduct sentiment analysis. The former allows for analyzing not only text but also image, speech, audio, and video files. In addition, clients have an option to request a more complex method of sentiment analysis. Users can ask leading questions to find out why people reacted to a product or service in a certain way.
Companies offer various service packages or plans, but most of them don’t give pricing information without a request. A plan price usually depends on a number of services or working hours, task complexity, or a dataset’s size.
The advantages of the approach
High-quality results. Companies claim their clients will get labeled data without inaccuracies.
The disadvantages of the approach
It’s more expensive than crowdsourcing. Although most companies don’t specify the cost of works, the example of CloudFactory’s pricing helps us understand that their services come at a slightly higher price than using crowdsourcing platforms. For instance, labeling 90,000 reviews (if the price for each task is $0.05) on a crowdsourcing platform will cost you $4500. To hire a professional team of 7 to 17 people not including a team lead, may cost $5,165–5200.
Find out whether a company staff does specific labeling tasks. If your project requires having domain experts on board, make sure the company recruits people who will define labeling principles and fix mistakes on the go.
Synthetic labeling
This approach entails generating data that imitates real data in terms of essential parameters set by a user. Synthetic data is produced by a generative model that is trained and validated on an original dataset.
There are three types of generative models: Generative Adversarial Networks (or GANs), Autoregressive models (ARs), and Variational Autoencoders (VAEs).
Generative Adversarial Networks. GAN models use generative and discriminative networks in a zero-sum game framework. The latter is a competition in which a generative network produces data samples, and a discriminative network (trained on real data) tries to define whether they are real (came from the true data distribution) or generated (came from the model distribution). The game continues until a generative model gets enough feedback to be able to reproduce images that are indistinguishable from real ones.
Autoregressive models. AR models generate variables based on a linear combination of previous values of variables. In the case of generating images, ARs create individual pixels based on previous pixels placed above and to the left of them.
Variational Autoencoders. VAEs produce new data samples from input through encoding and decoding methods.
Synthetic data has multiple applications. It can be used for training neural networks — models used for object recognition tasks. Such projects require specialists to prepare large datasets consisting of text, image, audio, or video files. The more complex the task, the larger the network and training dataset. When a huge amount of work must be completed in a short time, generating a labeled dataset is a reasonable decision.
For instance, data scientists working in fintech use a synthetic transactional dataset to test the efficiency of existing fraud detection systems and develop better ones. Also, generated healthcare datasets allow specialists to conduct research without compromising patient privacy.
The advantages of the approach
Time and cost savings. This technique makes labeling faster and cheaper. Synthetic data can be quickly generated, customized for a specific task, and modified to improve a model and training itself.
The use of non-sensitive data. Data scientists don’t need to ask for permission to use such data.
The disadvantages of the approach
The need for high-performance computing. This approach requires high computational power for rendering and further model training. One of the options is to rent cloud servers on Amazon Web Services (AWS), Google’s Cloud Platform, Microsoft Azure, IBM Cloud, Oracle, or other platforms. You can go another way and get additional computational resources on decentralized platforms like SONM.
Data quality issues. Synthetic data may not fully resemble real historical data. So, a model trained with this data may require further improvement through training with real data as soon as it’s available.
Data programming
Managing approaches and tools we described above require human participation. However, data scientists from the Snorkel project have developed a new approach to training data creation and management that eliminates the need for manual labeling.
Known as data programming, it entails writing labeling functions — scripts that programmatically label data. Developers admit the resulting labels can be less accurate than those created by manual labeling. However, a program-generated noisy dataset can be used for weak supervision of high-quality final models (such as those built in TensorFlow or other libraries).
A dataset obtained with labeling functions is used for training generative models. Predictions made by a generative model are used to train a discriminative model through a zero-sum game framework we mentioned before.
So, a noisy dataset can be cleaned up with a generative model and used to train a discriminative model.
The advantages of the approach
Reduced need for manual labeling. The use of scripts and a data analysis engine allows for the automation of labeling.
The disadvantages of the approach
Lower accuracy of labels. The quality of a program labeled dataset may suffer.
Data labeling tools
A variety of browser- and desktop-based labeling tools are available off the shelf. If the functionality they offer fits your needs, you can skip costly and time-consuming software development and choose the one that’s best for you.
Some of the tools include both free and paid packages. A free solution usually offers basic annotation instruments, a certain level of customization of labeling interfaces, but limits the number of export formats and images you can process during a fixed period. In a premium package, developers may include additional features like APIs, a higher level of customization, etc.
Image and video labeling
Image labeling is the type of data labeling that deals with identifying and tagging specific details (or even pixels) in an image. Video labeling, in turn, involves mapping target objects in video footage. Let’s start with some of the most commonly used tools aimed at the faster, simpler completion of machine vision tasks.
Annotorious. Annotorious is the MIT-licensed free web image annotation and labeling tool. It allows for adding text comments and drawings to images on a website. The tool can be easily integrated with only two lines of additional code. Users can learn about the tool’s features and complete various annotation tasks in the Demos section.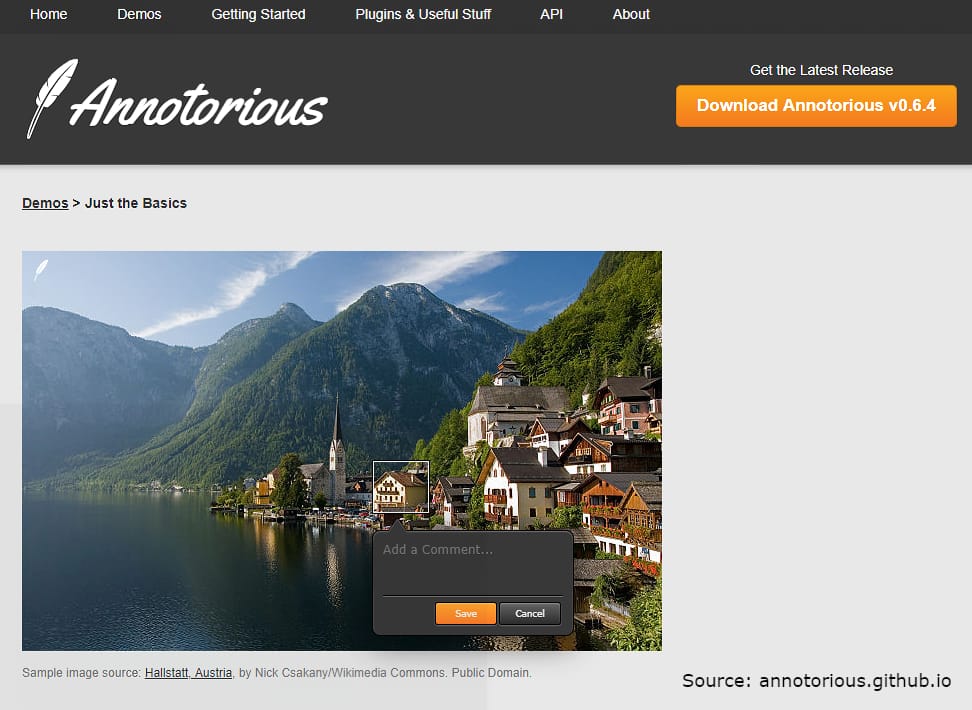
Demo where a user can make a rectangular selection by dragging a box and saving it on an image
Just the Basics demo shows its key functionality — image annotation with bounding boxes. OpenLayers Annotation explains how to process maps and high-resolution zoomable images. With the beta OpenSeadragon feature, users can also label such images by using Annotorious with the OpenSeadragon web-based viewer.
Developers are working on the Annotorious Selector Pack plugin. It will include image selection tools like polygon selection (custom shape labels), freehand, point, and Fancy Box selection. The latter tool allows users to darken out the rest image while they drag the box.
Annotorious can be modified and extended through a number of plugins to make it suitable for a project’s needs.
Developers encourage users to evaluate and improve Annotorious, then share their findings with the community.
LabelMe. LabelMe is another open online tool. Software must assist users in building image databases for computer vision research, its developers note.
When we talk about an online tool, we usually mean working with it on a desktop. However, LabelMe developers also aimed to deliver to mobile users and created the same name app. It’s available on the App Store and requires registration.
Two galleries — the Labels and the Detectors — represent the tool’s functionality. The former is used for image collection, storage, and labeling. The latter allows for training object detectors able to work in real time.
Users can also download the MATLAB toolbox that is designed for working with images in the LabelMe public dataset. Developers encourage users to contribute to a dataset. Even a small input counts, they say.
The tool’s desktop version with the labeled image from the dataset
Sloth. Sloth is a free tool with a high level of flexibility. It allows users to label image and video files for computer vision research. Face recognition is one of Sloth’s common use cases. So, if you need to develop software able to track and exactly identify a person from surveillance videos or to define whether he or she has appeared in recordings before, you can do it with Sloth.
Users can add an unlimited number of labels per image or video frame where every label is a set of key-value pairs. The possibility of adding more key-value pairs allows for more detailed file processing. For example, users can add a key “type” that differentiates point labels from the labels for the left or right eye.
Sloth supports various image selection tools, such as points, rectangles, and polygons. Developers consider the software a framework and a set of standard components. It follows that users can customize these components to create a labeling tool that meets their specific needs.
VoTT. Visual Object Tagging Tool (VoTT) by Windows allows for processing images and videos. Labeling is one of the model development stages that VoTT supports. This tool also allows data scientists to train and validate object detection models.
Users set up annotation, for example, make several labels per file (like in Sloth), and choose between square or rectangle bounding boxes. Besides that, the software saves tags each time a video frame or image is changed.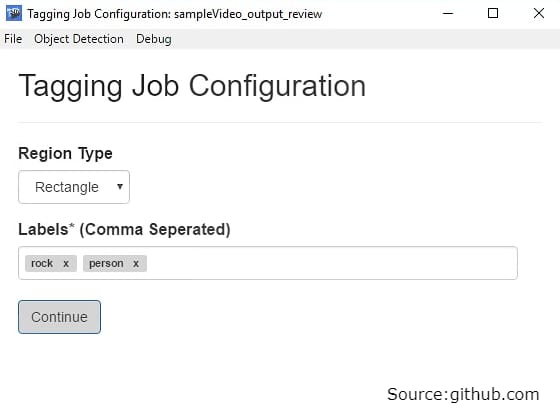
Tagging job configuration
Other tools worth checking out include Labelbox, Alp’s Labeling Tool, imglab, Pixorize, VGG Image Annotator (VIA), Demon image annotation plugin, FastAnnotationTool, RectLabel, and ViPER-GT.
Text labeling
Text labeling is the annotation process during which metadata tags are used to mark the characteristics of a textual dataset such as keywords, phrases, and sentences. These tools will streamline the labeling workflow for NLP-related tasks, such as sentiment analysis, entity linking, text categorization, syntactic parsing and tagging, or parts-of-speech tagging.
Labelbox mentioned above can also be used for text labeling. Besides providing basic labeling options, the tool allows for the development, installation, and maintenance of custom labeling interfaces.
Stanford CoreNLP. Data scientists share their developments and knowledge voluntarily and for free in many cases. The Stanford Natural Language Processing Group representatives offer a free integrated NLP toolkit, Stanford CoreNLP, that allows for completing various text data preprocessing and analysis tasks.
Bella. Worth trying out, bella is another open tool aimed at simplifying and speeding up text data labeling. Usually, if a dataset was labeled in a CSV file or Google spreadsheets, specialists need to convert it to an appropriate format before model training. Bella’s features and simple interface make it a good substitution for spreadsheets and CSV files.
A graphical user interface (GUI) and a database backend for managing labeled data are bella’s main features.
A user creates and configures a project for every labeling dataset he or she wants to label. Project settings include item visualization, types of labels (i.e. positive, neutral, and negative) and tags to be supported by the tool (i.e. tweets, Facebook reviews).
Tagtog. Tagtog is a startup that provides the same name web tool for automated text annotation and categorization. Customers can choose three approaches: annotate text manually, hire a team that will label data for them, or use machine learning models for automated annotation.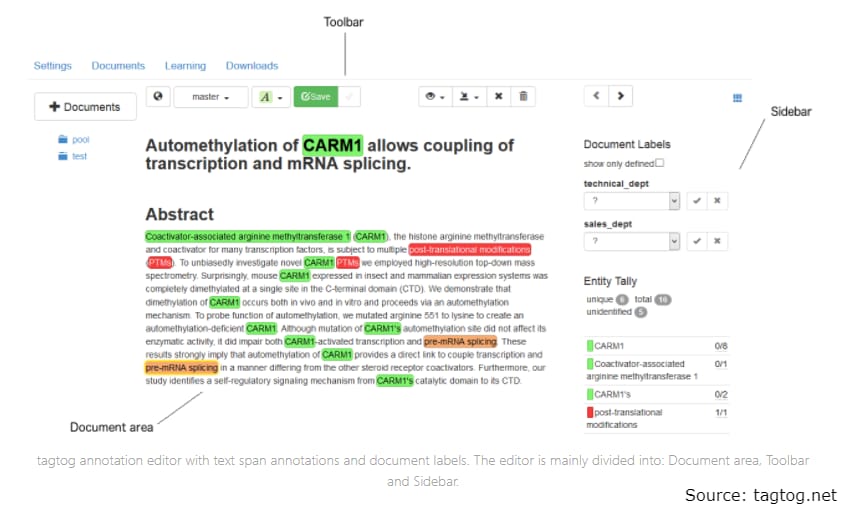
Editor for manual text annotation with an automatically adaptive interface
Both data science beginners and professionals can use Tagtog because it doesn’t require knowledge of coding and data engineering.
Dataturks. Dataturks is also a startup that provides training data preparation tools. Using its products, teams can perform such tasks as parts-of-speech tagging, named-entity recognition tagging, text classification, moderation, and summarization. Dataturks presents “upload data, invite collaborators, and start tagging” workflow and allows clients to forget about working with Google and Excel spreadsheets, as well as CSV files.
Three business plans are available for users. The first package is free but provides limited features. Two others are designed for small and large teams. Besides text data, tools by Dataturks allow for labeling image, audio, and video data.
Specialists also recommend checking such services and tools as brat and YEDDA.
Audio labeling
Speech or audio labeling is the process of tagging details in audio recordings and putting them in a format for a machine learning model to understand. You’ll need effective and easy-to-use labeling tools to train high-performance neural networks for sound recognition and music classification tasks. Here are some of them.
Praat. Praat is a popular free software for labeling audio files. Using Praat, you can mark timepoints of events in the audio file and annotate these events with text labels in a lightweight and portable TextGrid file. This tool allows for working with both sound and text files at the same time as text annotations are linked up with the audio file. Data scientist Kristine M. Yu notes that a text file can be easily processed with any scripts for efficient batch processing and modified separately from an audio file.
Speechalyzer. This tool’s name, Speechalyzer, speaks for itself. The software is designed for the manual processing of large speech datasets. To show an example of its high performance, developers highlight they’ve labeled several thousand audio files in almost real time.
EchoML. EschoML is another tool for audio file annotation. It allows users to visualize their data.
As there are many tools for labeling all types of data available, choosing the one that fits your project best won’t be a simple task. Data science practitioners suggest considering such factors as setup complexity, labeling speed, and accuracy when making a choice.
With a variety of annotation tools available online, the main challenge for a data science team is to estimate which software will work best for a specific project in terms of functionality and cost.
Data labeling best practices
Obtaining high-quality labeled data is a development barrier that becomes more significant when complex models must be built. Yet, there are many techniques to improve the effectiveness and accuracy of the data labeling process.
Clear labeling instructions. You should communicate with the labelers and provide them with clear labeling instructions to ensure the desired accuracy of results.
Consensus. Whether human or machine, there should be a certain rate of agreement to ensure the high label quality. This means sending each dataset to be checked by multiple labelers and then consolidating the annotations.
Verification of labels. It’s important to audit the labels to verify their accuracy and adjust them if necessary.
Active learning. When working on large datasets, it’s recommended to use automated data labeling. This can be accomplished with a machine learning technique called active learning that automatically identifies data that needs to be labeled by humans.
Transfer learning. Another technique to improve the efficiency of data labeling is to re-use prior labeling jobs to create hierarchical labels. Basically, you use the output of pre-trained models as input for another one.
No matter the approach, you can follow these practices for the optimization of your data labeling processes.