

In the past few years, machine learning (ML) has revolutionized the way we do business. A disruptive breakthrough that differentiates machine learning from other approaches to automation is a step away from the rules-based programming. ML algorithms allowed engineers to leverage data without explicitly programming machines to follow specific paths of problem-solving. Instead, machines themselves arrive at the right answers based on the data they have. This capability made business executives reconsider the ways they use data to make decisions.
In layman terms, machine learning is applied to make forecasts on incoming data using historic data as a training example. For instance, you may want to predict a customer lifetime value in an eCommerce store measuring the net profit of the future relationship with a customer. If you already have historic data on different customer interactions with your website and net profits associated with these customers, you may want to use machine learning. It will allow for early detection of those customers who are likely to bring the most net profit enabling you to focus greater service effort on them.
While there are multiple learning styles, i.e. the approaches to training algorithms using data, the most common style is called supervised learning. This time, we’ll talk about this branch of data science and explain why it is considered low-hanging fruit for businesses that plan to embark on the ML initiative, additionally describing the most common use cases.
Data labeling can be costly and slow at scale. In these cases, self-supervised learning lets models learn directly from unlabeled data. Read our dedicated article to learn more.
How supervised machine learning works
Supervised machine learning suggests that the expected answer to a problem is unknown for upcoming data, but is already identified in a historic dataset. In other words, historic data contains correct answers, and the task of the algorithm is to find them in the new data.
As an example, let’s have a look at a public dataset gathered by one Portuguese banking institution during a 2012 marketing campaign. The bank aimed at encouraging its customers to subscribe to terms deposits by calling them and pitching the service.
Usually, datasets are in tables having data items (e.g. bank customers) organized in rows with variables (e.g. age, job, education, money balance) in columns. Labeled data sets also have target variables (labels), the values to be predicted in future data. In this dataset, the target variable defines whether customers have subscribed for terms deposit after a call or not.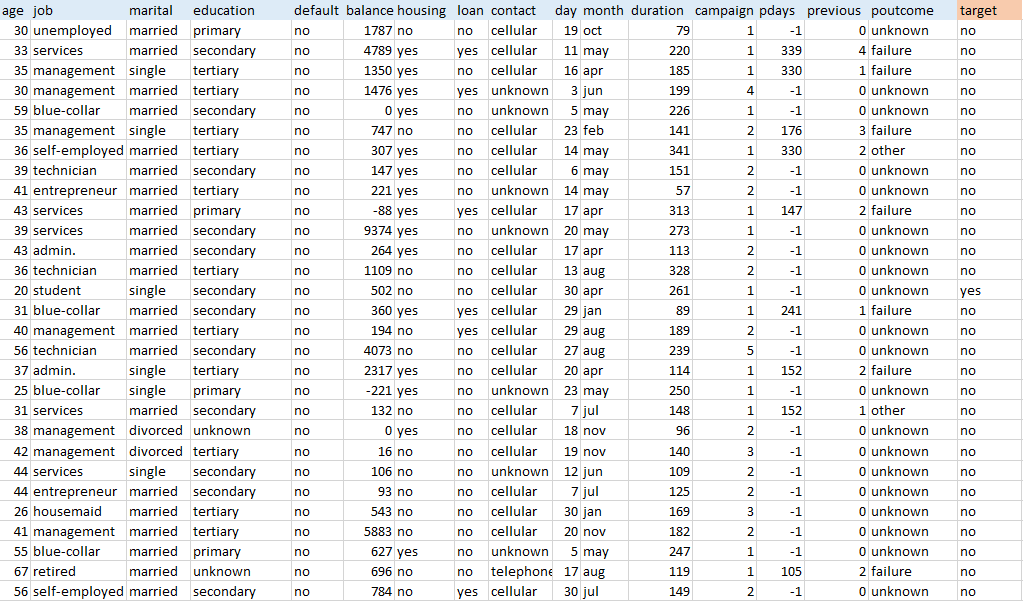
Applying ML to datasets of this kind will help determine the likelihood of other bank clients subscribing to terms deposit.
Dataset credit: S. Moro, P. Cortez, and P. Rita. A Data-Driven Approach to Predict the Success of Bank Telemarketing. Decision Support Systems, Elsevier, 62:22-31, June 2014
Training an ML algorithm means feeding this data into a machine using one of the mathematical methods. The process allows for building a model able to define the target variable in future data. In this case, the task of an algorithm would be to classify data items into two categories (yes/no). Generally, supervised learning operates with three main tasks:
Binary classification. The case of binary classification is described above. The algorithm classifies data into two categories.
Multiclass classification. This requires the algorithm to choose between more than two types of answers for a target variable.
Regression. Regression models predict continuous values, while classification models consider categorical ones. For instance, predicting net profit as a measurement of the customer lifetime value is a standard regression problem.
3 main problems that should be considered for supervised learning
That said, business executives should consider three main aspects to justify decisions about adopting supervised learning techniques.
Collecting data
Data is the backbone of machine learning: The more records you have, the higher the chance to build accurate models. We’ve described the main data collection and preparation techniques in one of our previous articles. Collecting and organizing your data the right way is a form of art. Not only you do have to set a coherent data collection mechanism, but also ensure that your variables are relevant for prediction.
Labeling data
In the bank case mentioned above, labeling doesn’t seem like a challenge. If the data collection was done right, the labels were assigned straightaway after the marketing call or after the campaign was finished. But, usually, things are more complex than that.
Imagine that you want to automatically sort out rotten apples from good ones on a packaging line. And if you apply image recognition techniques, you will have to make a large set of images containing various apples, both rotten and good ones. Then you’ll have to manually assign labels to them (good/rotten). Considering that image recognition is only possible if you have thousands of examples, labeling may take too much time.
In 2006, Google crowdsourced their image labeling by suggesting to its users a game-like experience that asked people to simply label images thus contributing to the company’s AI-development. Another leading AI company, Amazon, also crowdsourced their labeling duties through creation of the mechanical turk platform where people can earn money by assigning data labels.
Guru Banavar, the IBM data scientist behind the Watson AI platform, assumed that about 70 percent of complex analytical tasks today are related to data preparation and suggested the term “data labeler.” There have to be people who are preparing and labeling data for machines to understand. Here’s a situation in which human labor automation driven by ML creates new job opportunities.
Prediction accuracy
The prediction accuracy of coin flipping is 50 percent for binary classification, according to the probability theory. Good prediction accuracy in machine learning is about 90 percent. This number can vary depending on the task. But the point is clear. You can’t achieve the same level of precision if you used a standard rules-based approach to make critical decisions. There’ll always be a chance that your prediction is wrong.
That’s exactly the issue behind the new FaceID technology used in iPhoneX. Apple claims that FaceID uses machine learning to adapt image recognition to constant changes in human appearance, whether you’ve grown a beard or worn Hunter-Thompson-type glasses. The company doesn’t disclose the ML algorithms under the hood, but the rising concerns basically address this prediction accuracy problem. Can we delegate to the machine – that can’t be 100 percent right – such important decision-making tasks? While Apple thinks they can, we recommend understanding that ML solutions don’t always present the right answers.
However, even these challenges don’t prevent supervised learning from being the most business-oriented style of ML. It’s less independent than unsupervised learning, where data isn’t labeled as analysts may not know target variables. (Unsupervised learning is used to find anomalies in data or cluster data items to groups that humans can’t assume themselves.) It’s also more practical than reinforcement learning, which currently thrives in closed game-like systems only.
Have a look at our machine learning basics whitepaper to know more about the learning styles.
Common use cases for supervised learning
In November 2016, Tech Emergence published the results of a small survey among artificial intelligence experts to outline low-hanging-fruit applications in machine learning for medium and large companies. While there were only 26 respondents who could vote multiple times, they confirmed what was evident already.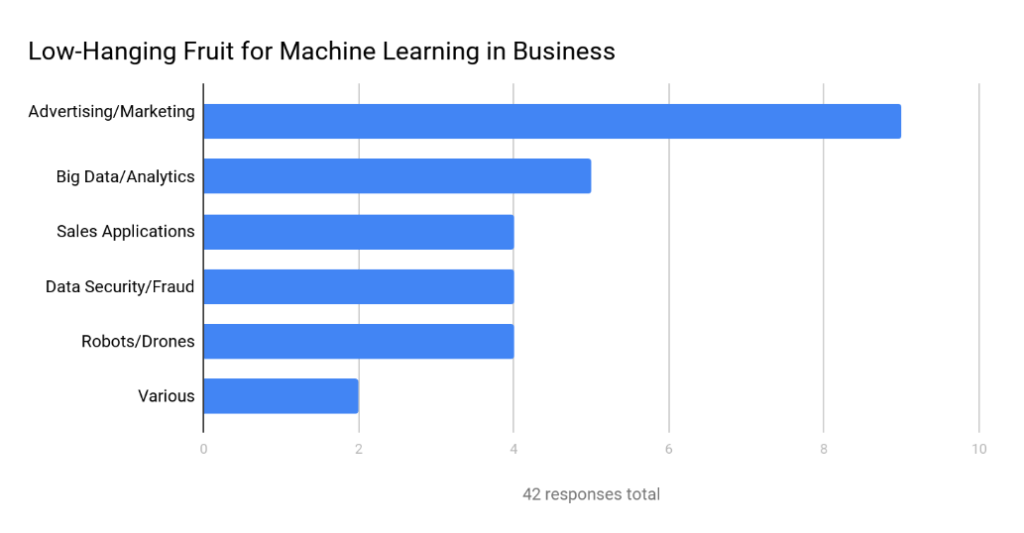
Please note that the survey covered both supervised and unsupervised learning. While supervised learning covers the lion's share of ML applications, in data security the unsupervised style is dominant.
Source: Where to Apply Machine Learning First in Your Business: Expert Consensus
Interestingly, the groups used by Tech Emergence provide only a vague understanding of how use cases are distributed among different machine learning tasks. For example, Big Data can be applied to any of the mentioned groups, given that the algorithms process large and poorly structured datasets, regardless of the industry and operations field this data comes from. Also, sales tasks usually intersect marketing ones when it comes to analytics. That’s why we suggest a slightly different breakdown of the most common use cases.
Marketing and Sales
Digital marketing and online-driven sales are the first application fields that you may think of for machine learning adoption. People interact with the web and leave a detailed footprint to be analyzed. While there are tangible results in unsupervised learning techniques for marketing and sales, the largest value impact is in the supervised learning field. Let’s have a look.
Lifetime Value. A customer lifetime value that we mentioned before is usually measured in the net profit this customer brings to a company in the longer run. If you’ve been tracking most of your customers and accurately documenting their in-funnel and further purchase behavior, you have enough data to make predictions about most budding customers early and target sales effort toward them.
Churn. The churn rate defines the number of customers who cease to complete target actions (e.g. add to cart, leave a comment, checkout, etc.) during a given period. Similar to lifetime value predictions, sorting “likely-to-churn-soon” from engaged customers will allow you to 1) analyze the reasons for such behavior, 2) refocus and personalize offerings for different groups of churning customers.
Sentiment analysis. Skimming through thousands of feedback posts in social media and comments sections is painstaking work, especially in B2C after a new product or feature rollout. Sentiment analysis backed by natural language processing allows for aggregating and yielding analytics on customer feedback. You may play with sentiment analysis using Google Cloud Natural Language API to understand how this works and what kinds of analytics may be available.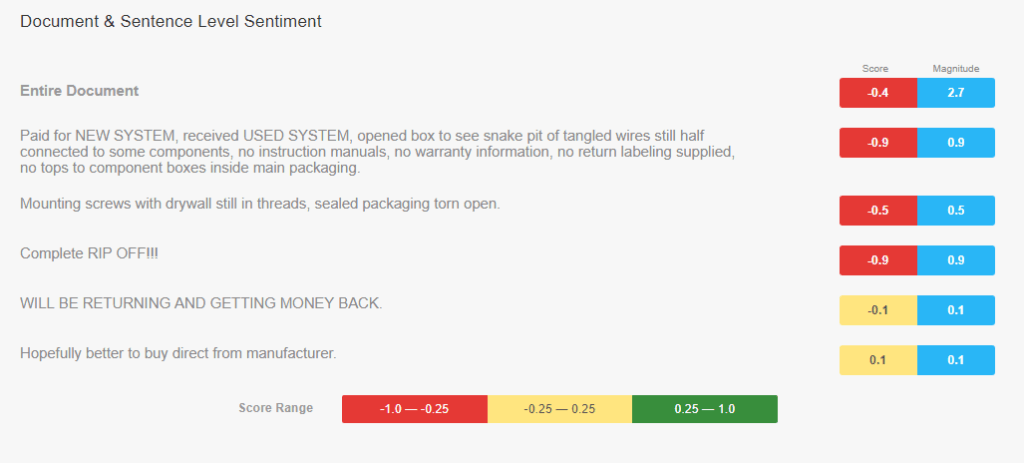
Here’s how the API analyzes an angry comment by a person who purchased HTC Vive, a virtual reality headset, on Amazon. Score defines sentiment itself, ranging from very negative to very positive. Magnitude shows the strength of a sentiment regardless of its score.
Recommendations. Recommendation sections are something we can’t imagine modern eCommerce or media without. The common practice is to recommend other popular products or the ones you want to sell most. It doesn’t require machine learning algorithms at all. But if you want to engage customers with deep personalization, you can apply machine learning techniques to define the products that this customer is most likely to buy next and put them on top of the recommendation list. Also, Netflix, YouTube, and other video streaming services operate in similar way, tailoring their recommendations to a viewer’s lifetime behavior.
People analytics
Tracking internal operations to get insights is also a powerful task for machine learning. Most digitalized companies today have enough employee tracking software and historic data to make predictions on employee performance, retention, and other fundamental problems of human resource management.
Sales performance. Is there a way to understand why one middle-level sales executive brings twice as much lead conversion than another middle-level exec sitting in the same office? Technically, they both send emails, set calls, and participate in conferences, which somehow result in conversions or lack thereof. Any time we talk about what drives salespeople performance, we make assumptions prone to bias. A good example of ML use here is People.ai, a startup which tries to address the problem by tracking all the sales data, including emails, calls, and CRM interactions to use this data as a supervised learning set and predict which kinds of actions bring better results. Basically, the algorithm aids in developing a playbook for sales reps based on successful cases.
Retention. Similar tracking techniques, the use of text sentiment and other metadata analysis (from emails and social media posts) can be applied to detect possible job-hopping behavior among candidates.
Human resource allocation. You can use historic data from HR software – sick days, vacations, holidays, etc. – to make broader predictions on your workforce. Deloitte disclosed that a number of automotive companies are learning from the patterns of unscheduled absences to forecast the periods when people are likely to take a day off and reserve more workforce.
Time-series market forecasting
Time-series forecasting is a specific branch of machine learning and statistics that addresses predicting time-dependent events. These may be seasonal or cyclic fluctuations in any market figures. In the general case, time-series forecasting considers such time-dependent changes as holidays, seasons, or other events that impact sales, prices, and customer activities. Check our time-series forecasting story to learn more.
Currently, time-series data can be applied both for internal use to have better planning capabilities and for customer-facing applications as well. For instance, eCommerce websites may be interested in tracking time-series data related to Black Friday to better set discount campaigns and drive more sales. As for the example of customer-facing use, AltexSoft helped Fareboom.com, airfare provider, build a price-prediction feature that allows Fareboom customers to choose the best time to purchase their tickets.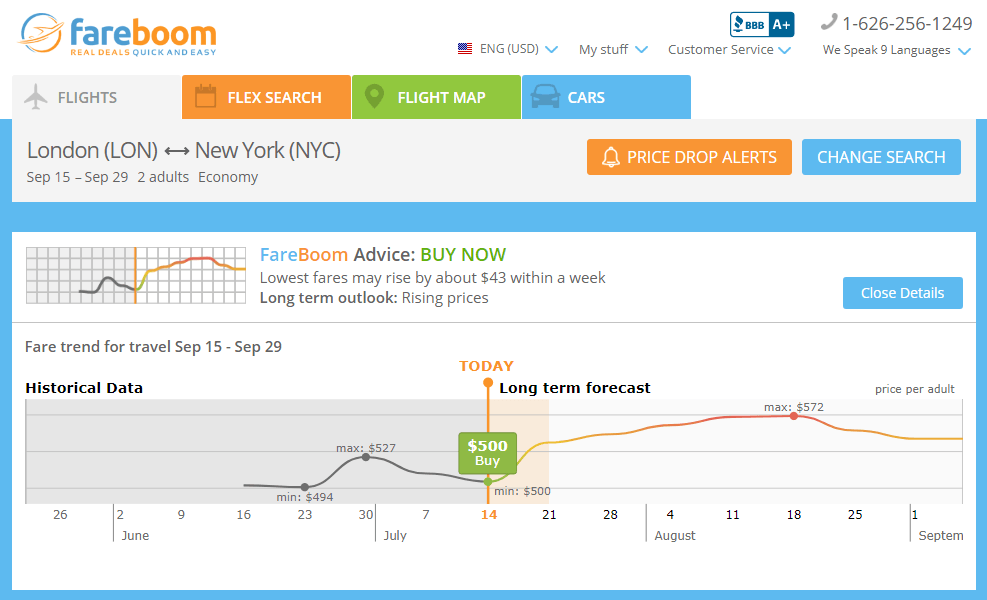
Source: Fareboom.com
Security
As we mentioned above, most cyber-security techniques revolve around unsupervised learning, especially the methods that address anomaly detection, i.e. finding outlying data items that may pose a threat. However, there are several use cases where mostly supervised learning is used.
Spam filtering. According to Statista, 56.87 percent of all emails were spam in March 2017. This number actually keeps dropping – in April 2014 the share of spam was 71.1 percent – as increasingly more email services have adopted spam-filtering algorithms backed by ML models. The abundance of spam examples provides enough both textual and metadata to sort out this type of correspondence.
Malicious emails and links. Detecting phishing attacks becomes critical for all IT departments in organizations, considering the recent case of the Petya virus, which was distributed among corporate infrastructures through email attachments. Currently, there are many public datasets that provide labeled records of malware or even URLs that can be used directly to build classifying models to protect your organization.
Fraud detection. As fraudulent actions are very domain-specific, they mostly rely on private datasets that organizations have. For example, many banks that have fraud cases in their data use supervised fraud detection techniques to block potentially fraudulent money transactions accounting for such variables as transaction time, location, money amounts, etc.
Asset maintenance and IoT
Digitalization goes beyond internal IT infrastructures only. As corporate assets become smart with the Internet-of-Things surge, various smart sensors can gather and stream asset data directly to private or public clouds where it can be centralized and further used for resource management and supply chain optimization.
Logistics. Settling logistics scenarios is a very dynamic task, as managers should account for delivery time, budget, weather factors, driver’s personal characteristics, and other changing data. Given that supply chain management is a common problem for most businesses that have physical assets, the datasets are already there. So, building AI-backed recommendation systems is another opportunity that can be adopted with relative ease.
Outage predictions. Another on-surface opportunity is to use the history of machinery outages to predict failures early. Complex ML algorithms can draw predictions based on unobvious factors that humans may not detect. This allows for providing timely maintenance for lower cost. And this approach fits well for the industries where asset management is highly regulated – like air travel – and assets are usually over-maintained to comply with security protocols.
Entertainment
Last but not the least in the group of supervised machine learning use cases is the entertainment field, where users are directly interacting with algorithms. These can run the gamut from face recognition and different visual alterations to turning camera pictures into artwork-style images.
This path usually belongs to AI startups that plan acquisition and ship software that can be embedded in other large market products. That’s exactly what happened to MSQRD, a video filter app, that was acquired by Facebook. MSQRD was developed in three months.
Jumpstarting ML is all about data
The most approachable fields for supervised learning are those that generate the most data, which can be structured and centralized within a company. If the datasets are already labeled, this makes the adoption even easier.
As businesses gradually become digital, the data they collect also becomes more ML-friendly. In other words, paper ledgers and spreadsheets siloed in departments disappear for good, while CRM/ERP and various tracking systems have reached the plateau of common practice.
So, the first step to jumpstarting the machine learning initiative is to assess your data and think in plain classification and regression terms to realize what kinds of answers you can get.