Real-time data is now required by all organizations to make instant business decisions and bring value to customers faster. But this data is all over the place: It lives in the cloud, on social media platforms, in operational systems, and on websites, to name a few. Not to mention that additional sources are constantly being added through new initiatives like big data analytics, cloud-first, and legacy app modernization. To break data silos and speed up access to all enterprise information, organizations can opt for an advanced data integration technique known as data virtualization.
This post is a perfect place to learn about this approach, its architecture components, differences, benefits, tools, and more.
What is data virtualization?
Data virtualization is an approach to integrating data from multiple sources of different types into a holistic, logical view without moving it physically. In simple terms, data remains in original sources while users can access and analyze it virtually via special middleware.
Before we get into more detail, let’s determine how data virtualization is different from another, more common data integration technique — data consolidation.
Data virtualization vs data consolidation
The traditional way of data integration involves consolidating disparate data within a single repository — commonly a data warehouse — via the extract, transform, load (ETL) process. That said, for information to be consumed by end-users, you should first extract it from sources, then transform it into a format and structure (schema) that fits the target system, and finally load it into that system. If the transformation step comes after loading (for example, when data is consolidated in a data lake or a data lakehouse), the process is known as ELT.
You can learn more about how such data pipelines are built in our video about data engineering.
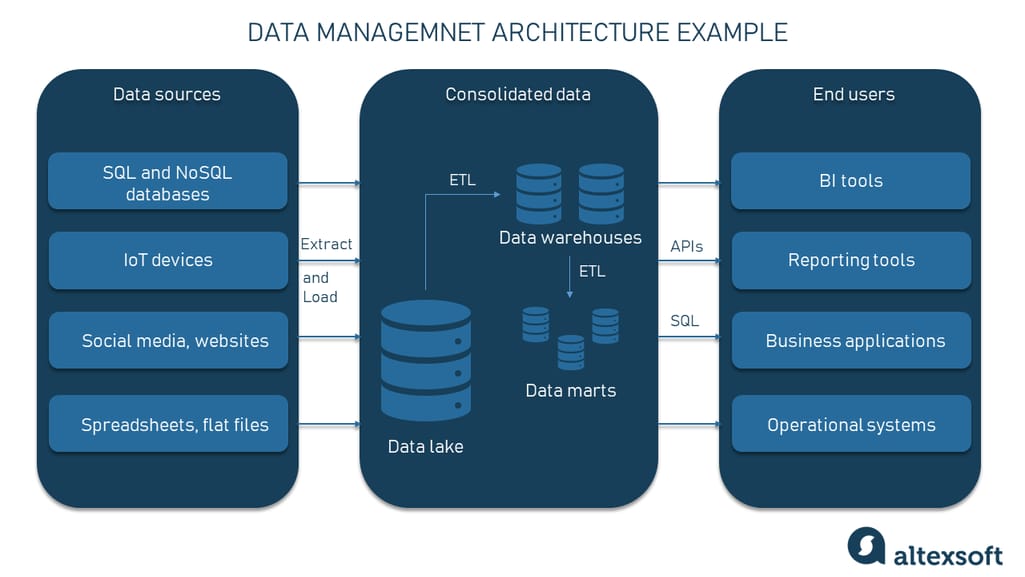
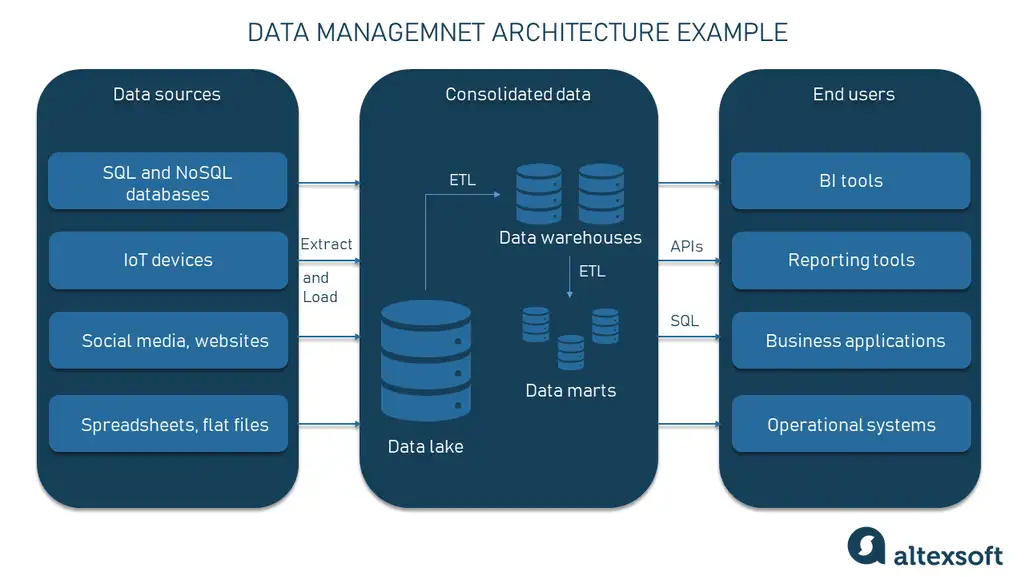
In many cases, companies choose two-tier architectures, in which source data is first extracted and loaded into a data lake and then undergoes several ETLs to reach purpose-built data warehouses and/or data marts. Then a variety of consumer applications and tools, each with its own semantic layer, can make use of that data for BI analytics and other tasks.
The example of a typical two-tier architecture with a data lake and data warehouses and several ETL processes
Whether ETL or ELT, the basic concept remains the same: Massive volumes of data from many disjointed sources are copied to a new, consolidated system, experiencing transformations somewhere along the way.
Such structures produce several challenges.
Data is replicated constantly with numerous ETL processes running out there. This often results in data inconsistencies and duplications as users demand more data views.
A new target repository has to be built and maintained, which is both costly and resource-heavy.
Security and governance issues exist as sometimes sensitive data can’t be moved into the cloud or a centralized store, remaining in its native location.
Data is commonly delivered in scheduled batches, not on a demand basis.
Data may still be siloed with certain groups of users having no access to it.
Data virtualization benefits and limitations
Relying on a completely different data integration approach, data virtualization solves these and other problems and offers the following benefits.
Real-time access. Instead of physically moving data to a new location, data virtualization allows users to access and manipulate source data through the virtual/logical layer in real time. ETL in most cases is unnecessary.
Low cost. Implementing data virtualization requires fewer resources and investments compared to building a separate consolidated store.
Enhanced data security and governance. The information doesn’t need to be moved anywhere and access levels can be managed.
Agility. All enterprise data is available through a single virtual layer for different users and a variety of use cases.
Self-service capabilities for all business users. They can design and perform whatever reports and analysis they need without worrying about a data format or where it resides.
It’s not all rosy in the kingdom of data virtualization though. Here are some limitations.
Single point of failure. Since the virtualization server provides a single access point to all data sources, it often results in a single point of failure too. If the server is down, you risk leaving all operational systems without any data feed.
No support for batch data. As opposed to the abovementioned ETL, this integration technique doesn’t support batch or bulk data movement that may be required in a number of cases. Say, a financial firm deals with large volumes of transactional data that need to be processed once a week.
This raises the question — When is it a good idea to opt for data virtualization?
Data virtualization use cases
Data virtualization can be a good alternative to ETL in a number of different situations.
Physical data movement is inefficient, difficult, or too expensive.
A flexible environment is needed to prototype, test, and implement new initiatives.
Data has to be available in real-time or near real-time for a range of analytics purposes.
Multiple BI tools require access to the same data sources.
Let’s take a look at real-world use cases to see how companies operating in different industries leverage data virtualization technology.
Pfizer: Acceleration of information delivery to the company’s research projects
The world’s leading pharmaceutical and biotechnology corporation, Pfizer uses data virtualization software by TIBCO (previously Cisco) to speed up the delivery of data to its researchers. In the past, the company used the traditional ETL data integration approach that often resulted in outdated data. With data virtualization, Pfizer managed to cut the project development time by 50 percent. In addition to the quick data retrieval and transfer, the company standardized product data to ensure consistency in product information across all research and medical units.
City Furniture: Online retailer creates enterprise-wide data fabric to advance analytics
A huge online retail company, City Furniture realized that in the pandemic realities, it is necessary to opt for digital transformation. And data virtualization was the way to facilitate this goal. With the help of the Denodo Platform, the retailer managed to integrate and deliver all business-critical data to its supply chain, marketing, operations, sales, and other departments by virtualizing data sources and creating a unified, semantic layer. As a result, data virtualization enabled the company to conduct advanced analytics and data science, contributing to the growth of the business.
Global investment bank: Cost reduction with more scalable and effective data management
In 2018, a multinational investment bank cooperated with a fintech company to present a digital data management platform. With a logical data layer built, the two organizations got a single source of truth for all data. The platform quickened customer onboarding as well as product and service consulting. As a result, they decreased customer churn rate and reduced costs by deleting nearly 300 TB of useless data.
As you can see, the value brought by data virtualization isn’t a fabrication. So, how do things work with it? Let’s see.
How data virtualization works: Main architecture layers
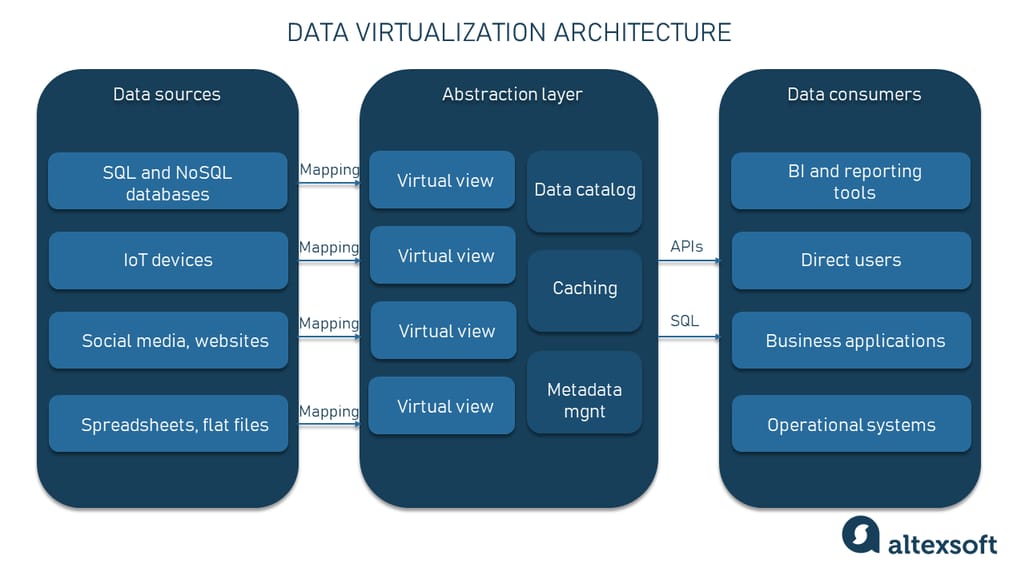
In a nutshell, data virtualization happens via middleware that is nothing but a unified, virtual data access layer built on top of many data sources. This layer presents information, regardless of its type and model, as a single virtual (or logical) view. It all happens on demand and in real time. Let’s elaborate on the data virtualization architecture to get the complete picture of how things work here.
Typically, there are three building blocks comprising the virtualization structure, namely
Connection layer — a set of connectors to data sources in real time;
Abstraction layer — services to present, manage, and use logical views of the data; and
Consumption layer — a range of consuming tools and applications requesting abstract data.
Data virtualization architecture example
Connection layer
This layer is responsible for accessing the information scattered across multiple source systems, containing both structured and unstructured data, with the help of connectors and communication protocols. Data virtualization platforms can link to different data sources including
When connecting, data virtualization loads metadata (details of the source data) and physical views if available. It maps metadata and semantically similar data assets from different autonomous databases to a common virtual data model or schema of the abstraction layer. Mappings define how the information from each source system should be converted and reformatted for integration needs.
Abstraction layer
The cornerstone of the whole virtualization framework is the abstraction (sometimes referred to as virtual or semantic) layer that acts as the bridge between all data sources on one side and all business users on the other. This tier itself doesn’t store any data: It only contains logical views and metadata needed to access the sources. With the abstraction layer, end users only see the schematic data models whereas the complexities of the bottom data structures are hidden from them.
So, once the data attributes are pulled in, the abstraction layer will allow you to apply joins, business rules, and other data transformations to create logical views on top of the physical views and metadata delivered by the connection layer. These integration processes can be modeled with the help of a drag-and-drop interface or a query language like SQL, depending on the data virtualization tool. Usually, there are various prebuilt templates and components to do all the modeling, matching, converting, and integration jobs.
The essential components of the virtual layer are
Metadata management — to import, document, and maintain metadata attributes such as column names, table structure, tags, etc.
Dynamic data catalog — to organize data by profiling, tagging, classifying, and mapping it to business definitions so that end-users can easily find what they need.
Query optimization — to improve query processing performance by caching virtual entities, enabling automatic joins, and supporting push-down querying (pushing down request operation to the source database).
Data quality control — to ensure that all information is correct by applying data validation logic.
Data security and governance — to provide different security levels to admins, developers, and consumer groups as well as define clear data governance rules, removing barriers for information sharing.
Consuming layer
Another tier of the data virtualization architecture provides a single point of access to data kept in the underlying sources. The delivery of abstracted data views happens through various protocols and connectors depending on the type of the consumer. They may communicate with the virtual layer via SQL and all sorts of APIs, including access standards like JDBC and ODBC, REST and SOAP APIs, and many others.
As we mentioned above, such a structure produces self-service capabilities for all consumers. Instead of making queries directly, they interact with the software used in their day-to-day operations, and that software, in turn, interacts with the virtual layer, getting the required data. In this way, consumers don’t need to care about the format of the data or its location as these complexities are masked from them.
Popular data virtualization tools
For years, companies have been consolidating data from multiple operational systems by copying it into data warehouses, data marts, or data lakes for further analysis and decision making. The process is often time-consuming, costly, and error-prone. Not to mention data sources are diverse in structure and their number increases continuously. That’s why many organizations choose data virtualization software, which allows them to view, access, and analyze data without moving it anywhere or even knowing its location. We’ve rounded up a few popular tools for you to consider.
Please note! We aren’t promoting any vendors. The information is presented to give you a general idea of what features data virtualization tools may provide.
Denodo
With over 20 years on the market, Denodo is considered a key figure among providers offering data virtualization capabilities. The latest version is equipped with the data catalog feature facilitating data search and discovery. The solution can be deployed in the cloud, on-premises, and in hybrid environments. Its query optimization functionality speeds up query performance, decreasing response times. The platform has connectors to pretty much any data source, business tool, or application. For organizations concerned about data privacy and compliance, Denodo offers integrated data governance capabilities.
Who may benefit from using the tool: Denodo is a good fit for small to large companies that want not only to integrate their data through virtualization but also to understand their data and how it can be used.
TIBCO
TIBCO Data Virtualization is another powerful tool in the list to help you build a virtual data layer from multiple types of data sources. To join data together from non-relational databases and other unstructured sources, TIBCO has the built-in transformation engine doing all the jobs. Users are also provided with a self-service UI and business data directory to discover, browse through, and consume information in a friendly manner. In TIBCO, abstracted data can be available as a data service with the help of Web Services Description Language.
Who may benefit from using the tool: Companies that want quick and easy implementation of the data virtualization strategy.
Informatica
As one of the leading data integration platforms, Informatica has numerous powerful features to virtualize data. The platform's core element is the metadata manager equipped with a convenient visual editor that helps see the integration processes through the map of data flows across the environment. Another cool feature is the capability to define the impact a data integration effort may have on an enterprise before implementing any changes. Informatica also gives organizations opportunities to archive data from older apps that aren't used actively.
Who may benefit from using the tool: This data virtualization tool is beneficial for organizations looking for a no-code environment with an easy-to-use GUI to integrate varied data stacks.
IBM Cloud Pak for Data
Known as the IBM Cloud Private for Data until 2018, IBM Cloud Pak for Data is a cloud-native platform that makes it possible to build a data fabric connecting siloed data virtually. In addition to data integration, the tool enables all users to govern and analyze data from a single, drag-and-drop interface. IBM also provides an enterprise-wide data catalog for more effective data discovery and organization. Many users claim that the solution helped them reduce time to market and improve overall business agility.
Who may benefit from using the tool: IBM Cloud Pak for Data is a good choice for those who are looking for a focused solution packed with both data collection and analysis capabilities.
How to get started with data virtualization
According to Gartner research of the data management market presented in 2018, “Through 2022, 60 percent of all organizations will implement data virtualization as one key delivery style in their data integration architecture.”
If you think that data virtualization is the perfect first step for you to take to climb the digital transformation ladder, here are a few useful tips to consider before kicking off the project.
Know your data sources
First things first, decide what and how much data there is to be virtualized. For this purpose, make a comprehensive list of all datasets, applications, services, and systems producing information. Along with that, determine their locations, management demands, and connectivity requirements to enable them to easily communicate with the virtualization layer. Some systems lay on the surface as they are used in your day-to-day operations while others may be in the depths of IoT devices and social media sites. It is a good idea to include all sources that can enhance business analytics.
Identify your consumers
Similar to the previous step, you may want to list all the tools and applications that will reside on the consumer side. Specify what connectors and protocols each of the consumers require for it to have access to the virtual views. Which of the operations in your company will benefit from the virtualization the most? Start with the tools supporting these operations.
Decide on resources and people involved
Data virtualization won't happen by itself. While it is easier and less costly to implement compared to traditional ETL, you will still have to determine your budget and available resources — both tech and human. Along with business analysts, you may need such specialists as data engineers and SQL developers to model data, build transformations, design data services, optimize queries, and manage resources.
With a number of advantages brought to the table by data virtualization, it’s no surprise that more and more companies are eager to take advantage of this new initiative. At the same time, you should keep in mind that data virtualization isn’t a silver bullet and it may not fit your particular use case. That’s why we highly recommend doing your own research and contacting specialists before implementing data virtualization within your business environment.