

One of ML’s most inspiring stories is the one about a Japanese farmer who decided to sort cucumbers automatically to help his parents with this painstaking operation. Unlike the stories that abound about large enterprises, the guy had neither expertise in machine learning, nor a big budget. But he did manage to get familiar with TensorFlow and employed deep learning to recognize different classes of cucumbers.
By using machine learning cloud services, you can start building your first working models, yielding valuable insights from predictions with a relatively small team. We’ve already discussed machine learning strategy. Now let’s have a look at the best machine learning platforms on the market and consider some of the infrastructural decisions to be made.
What is machine learning as a service
Machine learning as a service (MLaaS) is an umbrella definition of various cloud-based platforms that cover most infrastructure issues such as data pre-processing, model training, and model evaluation, with further prediction. Prediction results can be bridged with your internal IT infrastructure through REST APIs.Amazon Machine Learning services, Azure Machine Learning, Google AI Platform, and IBM Watson Machine Learning are four leading cloud MLaaS services that allow for fast model training and deployment. These should be considered first if you assemble a homegrown data science team out of available software engineers. Have a look at our data science team structures story to have a better idea of roles distribution or watch a video:


Roles in data science teams
Within this article, we’ll first give an overview of the main machine-learning-as-a-service platforms by Amazon, Google, Microsoft, and IBM, and will follow it by comparing machine learning APIs that these vendors support. Please note that this overview isn’t intended to provide exhaustive instructions on when and how to use these platforms, but rather what to look for before you start reading through their documentation.
Cloud ML services compared
If you’re looking for a drag-and-drop interface, first check Microsoft ML Studio. In terms of platforms for custom modeling, all four providers above suggest similar products
Amazon Machine Learning and SageMaker
Amazon has two major products dedicated to machine learning. The earlier platform called Amazon Machine Learning and SageMaker, the newer one.
Amazon Machine Learning
Amazon Machine Learning for predictive analytics is one of the most automated ML solutions on the market and the best fit for deadline-sensitive operations. The service can load data from multiple sources, including Amazon RDS, Amazon Redshift, CSV files, etc. All data preprocessing operations are performed automatically: The service identifies which fields are categorical and which are numerical, and it doesn’t ask a user to choose the methods of further data preprocessing (dimensionality reduction and whitening).
Prediction capacities of Amazon ML are limited to three options: binary classification, multiclass classification, and regression. That said, this Amazon ML service doesn’t support any unsupervised learning methods, and a user must select a target variable to label it in a training set. Also, a user isn’t required to know any machine learning methods because Amazon chooses them automatically after looking at the provided data.
Keep in mind that for 2021 Amazon no longer updates either the documentation or the Machine Learning platform itself. The service is still functional but doesn’t accept new users. This is because SageMaker and all of its corresponding services are superior to AML, and basically deliver the same functionality to users.
Predictive analytics can be used in the form of real-time or on-demand data with two separate APIs available. The only thing you have to consider is that currently Amazon seems to capitalize on its more powerful ML-based services, like SageMaker, discussed below.
This high automation level acts both as an advantage and disadvantage for Amazon ML use. If you need a fully automated yet limited solution, the service can match your expectations. If not, there’s SageMaker.
SageMaker
SageMaker is a machine learning environment that’s supposed to simplify the work of a fellow data scientist by providing tools for quick model building and deployment. For instance, it provides Jupyter, an authoring notebook, to simplify data exploration and analysis without server management hassle.
In 2021, Amazon launched SageMaker Studio, the first IDE for machine learning. This tool provides a web based interface that allows us to perform all the ML model training tests within a single environment. All development methods and tools, including notebooks, debugging instruments, data modeling, and its automatic creation is available via SageMaker Studio.
Amazon also has built-in algorithms that are optimized for large datasets and computations in distributed systems. These include:
- Linear learner is a supervised method for classification and
- Factorization machines is for classification and regression designed for sparse datasets.
- XGBoost is a supervised boosted trees algorithm that increases prediction accuracy in classification, regression, and ranking by combining the predictions of simpler algorithms.
- Image classification is based on ResNet, which can also be applied for transfer learning.
- Seq2seq is a supervised algorithm for predicting sequences (e.g. translating sentences, converting strings of words into shorter ones as a summary, etc.).
- K-means is an unsupervised learning method for clustering
- Principal component analysis is used for dimensionality reduction.
- Latent Dirichlet allocation is an unsupervised method used for finding categories in documents.
- Neural topic model (NTM) is an unsupervised method that explores documents, reveals top ranking words, and defines the topics (users can’t predefine topics, but they can set the expected number of them).
- DeepAR forecasting is a supervised learning algorithm used for forecasting time series that employs recurrent neural networks (RNN).
- BlazingText is a natural language processing (NLP) algorithm built on the Word2vec basis, which allows it to map words in large collections of texts with vector representations.
- Random Cut Forest is an anomaly detection unsupervised algorithm capable of assigning anomaly scores to each data point.
- Learning to Rank (LTR) is a plugin for Amazon Elasticsearch that allows for ML ranking the search results queries.
- K-nearest neighbor (k-NN) is an index-based algorithm that can be used in conjunction with a Neural Topic Model to build custom recommender services. Also, there is a separate Amazon Personalize engine for real-time recommendations used by Amazon.com itself.
Built-in SageMaker methods largely intersect with the ML APIs that Amazon suggests, but here it allows data scientists to play with them and use their own datasets.
If you don’t want to use these, you can add your own methods and run models via SageMaker leveraging its deployment features. Or you can integrate SageMaker with TensorFlow, Keras, Gluon, Torch, MXNet, and other machine learning libraries.
Generally, Amazon machine learning services provide enough freedom for both experienced data scientists and those who just need things done without digging deeper into dataset preparations and modeling. This would be a solid choice for companies that already use Amazon cloud services and don’t plan to transition to another cloud provider.
The popularity of DevOps among the software development community gave birth to the term “MLOps.” DevOps is an approach to software development that suggests merging devs and ops teams to optimize software development processes by focusing on short and fast releases. This is achieved by applying a high level of automation to routine tasks. MLOps, in turn, applies the same principles to machine learning, which led to the emergence of automated data management, model training/deployment, and monitoring.

DevOps explained
That’s why in 2021, MLaaS providers offer tools for MLOps practitioners to manage these machine learning pipelines. In Amazon’s case, they released an MLOps framework for building and managing MLOps infrastructure. It comes with a template architecture containing common AWS services to start building your own on top of it faster.
Microsoft Azure AI Platform
Azure AI platform represents a unified platform for machine learning with its APIs and infrastructural services. So here we’ll mention every major service Azure suggests in terms of machine learning solutions.
Azure Machine Learning
Azure Machine Learning is the main environment for dataset management, model training, and deployment.
The platform provides a Machine Learning Studio, a web-based and low-code environment, to quickly configure machine learning operations and pipelines. Generally, Azure Studio has the means for data exploration, preprocessing, choosing methods, and validating modeling results. The Studio supports around 100 methods that address classification (binary+multiclass), anomaly detection, regression, recommendation, and text analysis. It’s worth mentioning that the platform has one clustering algorithm (K-means).
As with Amazon, Azure offers integration with Jupyter and it’s to write and run your code in ML Studio. It also provides an ONNX Runtime to accelerate ML models across a range of OSs, hardware platforms, and frameworks. The runtime can also be used to run interoperability between different ML frameworks. Azure supports such popular ones as TensorFlow, PyTorch, scikit-learn, and others.
There are a number of features in ML Studio you’ll want to know about.
- Azure Machine Learning designer is a graphic drag-and-drop UI for ML studio that provides access and controls to the platform’s features. Here, you can modify our data, apply ML methods, and deploy solutions on the server.
- Automated ML is an SDK that provides no-code to low-code model training. Basically, Automated ML complements ML studio with a high degree of automation for routine tasks, and support for data exploration, model customization, and deployment. Azure specifies classification, regression, and time-series forecasting tasks as applicable for training with Automated ML tools.
- Azure ML Python and R language SDKs are fully integrated in ML Studio.
- Support for ML frameworks like PyTorch, TensorFlow, and scikit-learn, additionally, Azure offers interoperability between the frameworks using ONNX Runtime.
- Modular pipelines are built in and that allows your team to construct a custom data pipeline for your machine learning project.
- Support for data labeling projects including data and team management, labeling progress, incomplete labeling tracking, and exporting labeled data tools.
- Customizable compute targets for model deployment supports various cloud services such as Azure Kubernetes services, Container instances, and compute clusters
- MLOps tooling exists for managing, deploying and monitoring models within the automated pipelines.
Both ML Designer and Automated ML provide the means for inexperienced users to build ML solutions. In turn, Azure Machine learning studio includes a number of features that can be used by tech-savvy data scientists and enterprise-grade solutions. But this doesn’t limit these tools, as Azure ML is meant to be used as a single platform with all its capabilities.
Approaching machine learning with Azure entails some learning curve. But it eventually leads to a deeper understanding of all major techniques in the field. The Azure ML graphical interface visualizes each step within the workflow and supports newcomers. Perhaps the main benefit of using Azure is the variety of algorithms available to play with.
Azure AI Gallery
Another big part of Azure ML is Azure AI Gallery. It’s a collection of machine learning solutions provided by the community to be explored and reused by data scientists. The Azure product is a powerful tool for starting with machine learning and introducing its capabilities to new employees.
Azure Percept
As of 2021, Azure opened a preview for Azure Percept. The main idea behind Percept is to provide an SDK for creating models that can be integrated with Microsoft-partnered hardware devices. This entails an easy way of building and integrating computer vision or tools for speech recognition. Additionally, there is a whole range of APIs that can be connected to the system. We’ll cover them in a dedicated section.
2019’s platform updates focus mainly on the Python Machine Learning SDK, and the launch of Azure ML Workspaces (basically a UI for an ML platform). It allows developers to deploy models, visualize data, and work on dataset preparation in one place.
Google AI Platform (Unified)
Google AI Platform (Unified) united tools for ML that previously existed separately. The platform comprises AI Platform (Classic), AutoML, frameworks, and APIs under the hood of AI Platform Unified. So let’s look at each of them.
AI Platform (Classic)
Understand that AI Platform Classic is a tool that includes a number of features for machine learning experts and data scientists. AI Platform Classic suggests the following services for building custom models:
Training Service provides the environment to build models, using built-in algorithms (currently in beta) or using your own algorithms. Users can submit their own training methods or create custom containers to install the training application.
Predictive Service allows you to integrate generated predictions into your business applications or any other service.
Data Labeling Service is a tool that requests a human team to label your data. The service supports labeling for video, text, and images that will be processed by your instructions.
Deep Learning Image provides a virtual machine image for deep learning purposes. The image comes preconfigured for ML and data science tasks with popular frameworks and tools preinstalled.
AI Platform Notebooks is where a user can create/manage virtual machine instances and configure data processing memory types (CPU or GPU). It also comes pre-integrated with TensorFlow and PyTorch instances, deep learning packages, and Jupyter notebook.
The management of models, jobs, and endpoints can be done via a dedicated REST API, gcloud command line, or Google Cloud Console.
AI Platform Classic is designed for experienced users.
Google Cloud AutoML
Google Cloud AutoML is a cloud-based ML platform that suggests a no-code approach to building data-driven solutions. AutoML was designed to build custom models for both newcomers and experienced machine learning engineers. But the platform also suggests a set of prebuilt models available via a set of APIs. We’ll cover them in dedicated sections.
The main concept of Google’s platform is described via its AI building blocks. These are essentially different tools like AutoML, TensorFlow, and APIs that are meant to be used together to build ML solutions. This means you can combine a custom model and pretrained models in a single product.
Further, ML solutions can be deployed on your website or a dedicated AI Infrastructure that includes different methods of data processing on GPU or CPU. Needless to say, AutoML is fully integrated with all Google's services and it stores data in the cloud. Trained models can be deployed via the REST API interface.
So, thinking of a platform as a whole entity, there are two types of solutions that are meant to be used by different users. AI Platform (Classic) provides more options to build custom models and manage algorithms and training processes manually. And it’s best suited for experienced machine learning developers. In contrast, AutoML suggests a no-code way to build models, apply data, and integrate predictions whenever you need.
TensorFlow framework
TensorFlow is another Google product, which is an open source machine learning library of various data science tools rather than ML-as-a-service. It doesn’t have a visual interface and the learning curve for TensorFlow would be quite hard. However, the library is also targeted at software engineers that plan transitioning to data science. Google TensorFlow is quite powerful, but aimed mostly at deep neural network tasks.
Basically, the combination of TensorFlow and Google Cloud service suggests infrastructure-as-a-service and platform-as-a-service solutions according to the three-tier model of cloud services. We talked about this concept in our whitepaper on digital transformation. Have a look, if you aren’t familiar with it.
MLOps solution by Google offers similar capabilities to AWS for building and managing machine learning pipelines. But since Azure suggests a modular system preconfigured for use in ML Studio, their solution appears superior among these three vendors.
IBM Watson Machine Learning Studio
IBM Machine Learning platform is organized like the previous providers. Technically, the system offers two approaches: automated and manual – for expert practitioners.
Watson Studio and AutoAI
Watson Studio has an AutoAI that brings a fully automated data processing and model building interface that needs little to no training to start processing data, preparing models, and deploying them into production.
The automated part can solve three main types of tasks: binary classification, multiclass classification, and regression. You can choose either a fully automated approach or manually pick the ML method to be used. Currently, IBM has ten methods to cover these three groups of tasks:
- Logistic regression
- Decision tree classifier
- Random forest classifier
- Gradient boosted tree classifier
- Naive Bayes
- Linear regression
- Decision tree regressor
- Random forest regressor
- Gradient boosted tree regressor
- Isotonic regression
Besides AutoAI, there are two other services that you can use for building models.
SPSS Modeler
SPSS Modeler. SPSS is a software package used to transform data into statistical business information. Acquired by IBM in 2009 and integrated as a stand-alone ML service, now its a product without a graphic user interface that allows you to upload the data set, use SQL statements to manipulate data, and train models to operate with business information.
Neural Network and Deep Learning
Neural network and deep learning service is a little different from SPSS Modeler. It's a tool for modeling neural networks via a dedicated GUI. The service is integrated in Watson Studio allowing for data management with its inbuilt data integration tool. The main focus of the service is deep learning capabilities and training on big data. Additionally, neural network services are integrated with a bunch of ML frameworks such as Keras, PyTorch, or TensorFlow.
Separately, IBM offers deep neural network training workflow with flow editor interface similar to the one used in Azure ML Studio.
If you’re looking for advanced capabilities, IBM ML has notebooks such as Jupiter to program models manually using popular frameworks like TensorFlow, scikit-learn, PyTorch, and others.
To wrap up with machine learning as a service (MLaaS) platforms, it seems that Azure has currently the most versatile toolset on the MLaaS market. It covers the majority of ML-related tasks, provides two distinct products for building custom models, and has a solid set of APIs for those who don’t want to attack data science with their bare hands.
One of the latest updates made in 2019 is the discontinuation of the old model builder, which was replaced by AutoAI. The models trained with model builder are still operable within the ML Studio, but new models now can be trained in AutoAI. Other updates concern supports for the latest versions of TensorFlow and Python.
Machine learning APIs from Amazon, Microsoft, Google, and IBM comparison
Besides full-blown platforms, you can use high-level APIs. These are the services with trained models under the hood that you can feed your data into and get results. APIs don’t require machine learning expertise at all. Currently, the APIs from these four vendors can be broadly divided into three large groups:
1) text recognition, translation, and textual analysis
2) image + video recognition and related analysis
3) other, that includes specific uncategorized services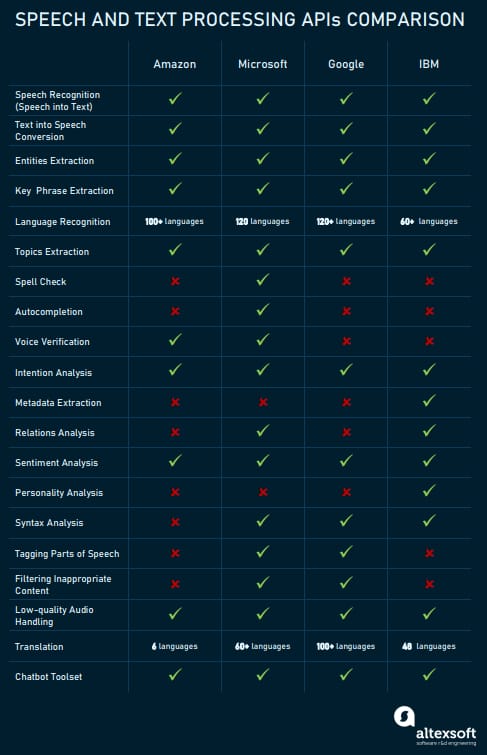
Microsoft suggests the richest list of features. However, the most critical ones are available from all vendors
Speech and text processing APIs: Amazon
Amazon provides multiple APIs that aim at popular tasks within text analysis. These are also highly automated in terms of machine learning and just need proper integration to work.
Amazon Lex. The Lex API is created to embed chatbots in your applications as it contains automatic speech recognition (ASR) and natural language processing (NLP) capacities. These are based on deep learning models. The API can recognize written and spoken text and the Lex interface allows you to hook the recognized inputs to various back-end solutions. Obviously, Amazon encourages use of its Lambda cloud environment. So, prior to subscribing to Lex, get acquainted with Lambda as well. Besides standalone apps, Lex currently supports deploying chatbots for Facebook Messenger, Slack, and Twilio.
Amazon Transcribe. While Lex is a complex chatbot-oriented tool, Transcribe is created solely for recognizing spoken text. The tool can recognize multiple speakers and works with low-quality telephony audio. This makes the API a go-to solution for cataloging audio archives or a good support for the further text analysis of call-center data.
Amazon Polly. The Polly service is kind of a reverse of Lex. It turns text into speech, which will allow your chatbots to respond with voice. It’s not going to compose the text though, just make the text sound close to human. If you’ve ever tried Alexa, you’ve got the idea. Currently, it supports both female and male voices for 30 languages, mostly English and Western European ones. Some languages have multiple female and male voices, so there’s even a variety to choose from. Like Lex, Polly is recommended for use with Lambda.
Amazon Comprehend. Comprehend is another NLP set of APIs that, unlike Lex and Transcribe, aim at different text analysis tasks. Currently, Comprehend supports:
- Entities extraction (recognizing names, dates, organizations, etc.)
- Key phrase detection
- Language recognition
- Sentiment analysis (how positive, neutral, or negative a text is)
- Topic modeling (defining dominant topics by analyzing keywords)
This service will help you analyze social media responses, comments, and other big textual data that’s not amenable to manual analysis, e.g. the combo of Comprehend and Transcribe will help analyze sentiment in your telephony-driven customer service.
Amazon Translate. As the name states, the Translate service translates texts. Amazon claims that it uses neural networks which - compared to rule-based translation approaches - provides better translation quality. Unfortunately, the current version supports translation from only six languages into English and from English into those six. The languages are Arabic, Chinese, French, German, Portuguese, and Spanish.
Speech and text processing APIs: Microsoft Azure Cognitive Services
Just like Amazon, Microsoft suggests high-level APIs, Cognitive Services, that can be integrated with your infrastructure and perform tasks with no data science expertise needed.
Speech. The speech set contains four APIs that apply different types of natural language processing (NLP) techniques for natural speech recognition and other operations:
- Translator Speech API
- Bing Speech API to convert text into speech and speech into text
- Speaker Recognition API for voice verification tasks
- Custom Speech Service to apply Azure NLP capacities using own data and models
Language. The language group of APIs focuses on textual analysis similar to Amazon Comprehend:
- Language Understanding Intelligent Service (LUIS) is an API that analyzes intentions in text to be recognized as commands (e.g. “run YouTube app” or “turn on the living room lights”)
- Text Analysis API for sentiment analysis and defining topics
- Bing Spell Check
- Translator Text API
- Web Language Model API that estimates probabilities of words combinations and supports word autocompletion
- Linguistic Analysis API used for sentence separation, tagging the parts of speech, and dividing texts into labeled phrases
Speech and text processing APIs: Google Cloud ML Services/ Cloud AutoML
While this set of APIs mainly intersects with what Amazon and Microsoft Azure suggest, it has some interesting and unique things to look at. Since the AutoML platform came along instead of Prediction API, now it extends the capabilities of Google Cloud ML services. So, every API concerning automated machine learning from Google is an actual option to train custom models.
Dialogflow. With various chatbots topping today's trends, Google also has something to offer. Dialogflow is powered by NLP technologies and aims at defining intents in the text, and interpreting what a person wants. The API can be tweaked and customized for needed intents using Java, Node.js, and Python.
Natural language API. This one is almost identical in its core features to Comprehend by Amazon and Language by Microsoft.
- Defining entities in text
- Recognizing sentiment
- Analyzing syntax structures
- Categorizing topics (e.g. food, news, electronics, etc.)
Speech-to-Text API. This service recognizes natural speech, and perhaps its main benefit compared to similar APIs is the abundance of languages supported by Google. Currently, its vocab works with over 125 global languages and variants of them. It also has some additional features:
- Word hints allow for customizing recognition to specific contexts and words that can be spoken (e.g. for better understanding of local or industry jargon)
- Filtering inappropriate content
- Handling noisy audio
Cloud translation API. Basically, you can use this API to employ Google Translate in your products. This one includes over a hundred languages and automatic language detection.
AutoML Natural Language API. Basically, what it does is allow you to upload the training data through AutoML UI and train custom models. Available features are:
- Defining content in English
- Defining entities in text
- Analyzing syntax structure
AutoML translation API. The translation API is now in beta and currently contains information only about its custom modeling capabilities. While we mention it, keep in mind that it will be updated in the future.
Speech and text processing APIs: IBM Watson
IBM also competes for the API market. Let’s have a look at their set of interfaces.
Speech to Text. Currently, IBM offers speech recognition for 9 languages, including Japanese, Portuguese, and Arabic. The API can recognize multiple speakers, spot keywords, and handle lossy audio. An interesting feature is capturing word alternatives and reporting them. For instance, if the system spots the word “Boston,” it can assume that there may be an “Austin” alternative. Upon analyzing its hypothesis, the API assigns a confidence score to each alternative.
Text to Speech. Interestingly, 9 text to speech languages only partly match those in the speech to text API. While both products support Western European languages, Text to speech lacks Korean and Chinese. English, German, and Spanish allow you to choose between male and female voices; the rest of the languages come with female voices only. This is in line with the trend toward making voice assistants sound mostly female.
Language translator. This API supports 48 languages for translation from and to English. Additionally, you can add custom models and expand the language coverage. Currently, the Translator API has been rewritten into a separate service with its own pricing model.
Natural language classifier. Unlike most of the APIs mentioned, the classifier by IBM can’t be used without your own dataset. Basically, the tool allows you to train models using your own business data and then classify incoming records. Common use cases are tagging products in eCommerce, fraud detection, categorizing messages, social media feeds, etc.
Natural language understanding. The language understanding feature set at IBM is extensive. Besides standard information extraction like keyword and entity extraction with syntax analysis, the API suggests a number of interesting capabilities that aren’t available from other providers. These include metadata analysis and finding relations between entities. Additionally, IBM suggests a separate environment to train your own models for text analysis using Knowledge Studio.
Personality insights. A relatively unusual API allows for analyzing texts and extracting clues about how the writer engages with the world. This basically means that the system will return:
- personality characteristics (e.g. agreeableness, conscientiousness, extraversion, emotional range, and openness)
- needs (e.g. curiosity, excitement, challenge)
- values (e.g. helping others, achieving success, hedonism).
Based on this data, the API can infer consumption preferences (e.g. music, learning, movies). The most common use case for such a system is user-generated content analysis for precise product marketing.
It’s important to note that Personality Insights was discontinued and will support existing instances using the API until the end of 2021.
Tone analyzer. Tone analyzer is a separate API that focuses on sentiment analysis and is aimed at social media research and various customer engagement analytics. Don’t be confused by its somewhat ambiguous name. The analyzer covers only written text and doesn’t extract insights from spoken ones.
Besides text and speech, Amazon, Microsoft, Google, and IBM provide rather versatile APIs for image and video analysis.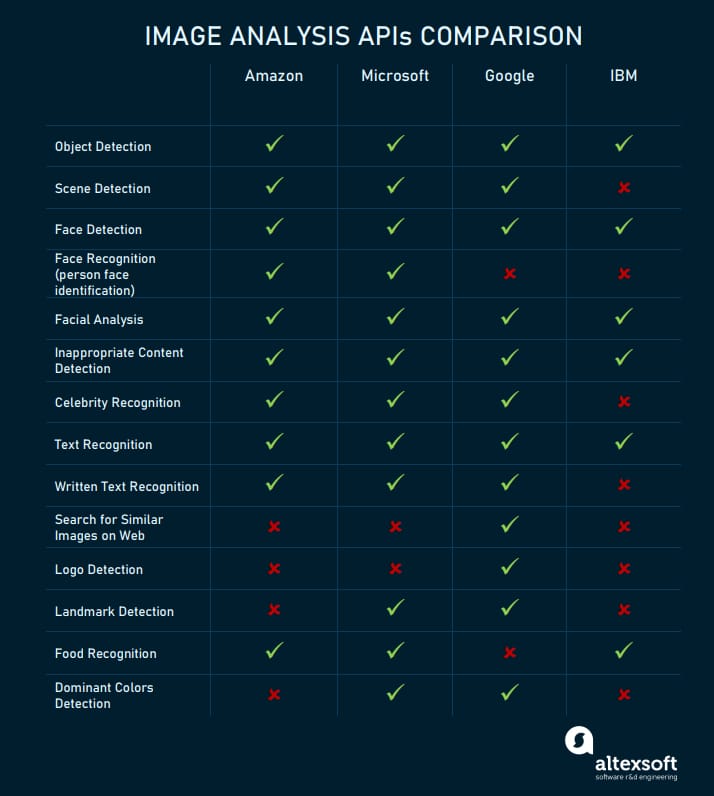
The most versatile toolkit for image analysis is currently available at Google Cloud
While image analysis closely intersects with video APIs, many tools for video analysis are still in development or beta versions. For instance, Google suggests rich support for various image processing tasks but definitely lacks video analysis features already available at Microsoft and Amazon.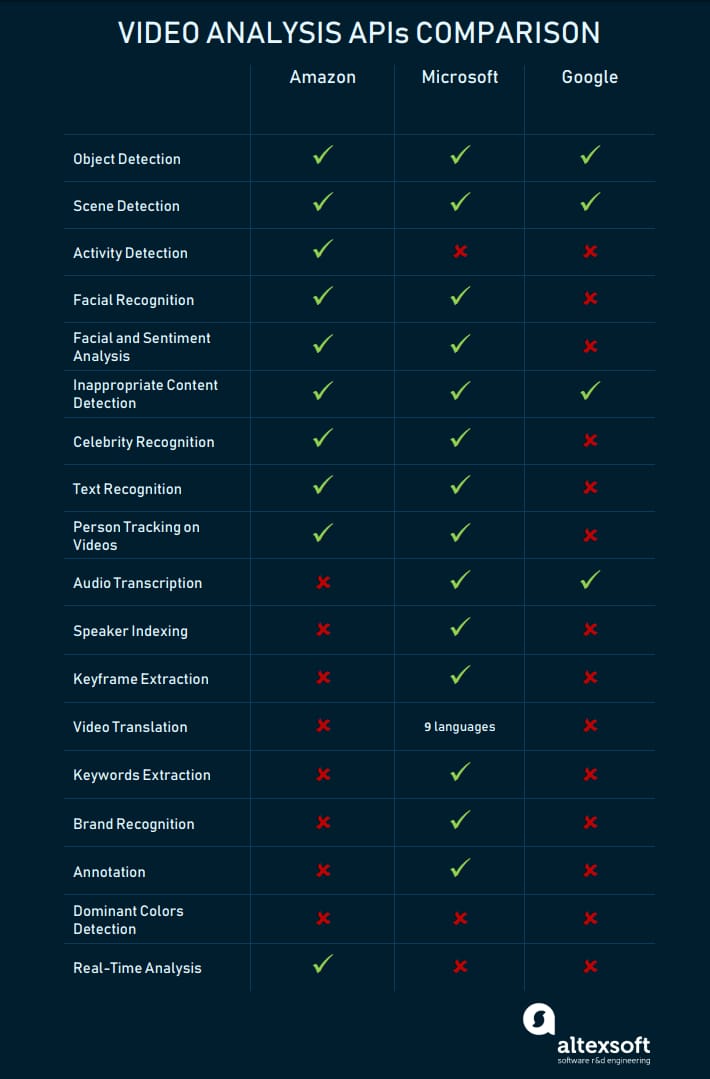
Microsoft looks like a winner, though we still think that Amazon has the most efficient video analysis APIs as it supports streaming videos. This feature tangibly extends the spectrum of use cases. IBM doesn't support video analysis APIs
Image and video processing APIs: Amazon Rekognition
No, we didn’t misspell the word. The Rekognition API is used for image and, recently, video recognition tasks. They include:
- Objects detection and classification (find and detect different objects in images and define what they are),
- In videos, it can detect activities like “dancing” or complex actions like “extinguishing fire”,
- Face recognition (for detecting faces and finding matching ones) and facial analysis (this one is pretty interesting as it detects smiles, analyzes eyes, and even defines emotional sentiment in videos),
- Detecting inappropriate videos,
- Recognizing celebrities in images and videos (for whatever goals that might be).
Image and video processing APIs: Microsoft Azure Cognitive Services
The Vision package from Microsoft combines six APIs that focus on different types of image, video, and text analysis.
- Computer vision that recognizes objects, actions (e.g. walking), written and typed texts, and defines dominant colors in images,
- Content moderator detects inappropriate content in images, texts, and videos,
- Face API detects faces, groups them, defines age, emotions, genders, poses, smiles, and facial hair,
- Emotion API is another face recognition tool that describes facial expressions,
- Custom Vision Service supports building custom image recognition models using your own data,
- Video indexer is a tool to find people in videos, define sentiment of speech, and mark keywords.
Image and video processing APIs: Google Cloud Services/ Cloud AutoML
Cloud vision AI. The tool is built for image recognition tasks and is quite powerful for finding specific image attributes:
- Labeling objects
- Detecting faces and analyzing expressions (no specific face recognition or identification)
- Finding landmarks and describing the scene (e.g. vacation, wedding, etc.)
- Finding texts in images and identifying languages
- Dominant colors
Cloud Video AI. The video recognition API from Google is early in development so it lacks many features available with Amazon Rekognition and Microsoft Cognitive Services. Currently, the API provides the following toolset:
- Labeling objects and defining actions
- Identifying explicit content
- Transcribing speech
AutoML Vision API. AutoML has also came up with several products to train models with AutoML Vision being the first one to be announced. Since all AutoML APIs are now in beta, the product currently offers:
- Labeling objects and engaging human labeling service
- Registering trained models in AutoML
AutoML Video Intelligence Classification API. This is a pre-release API for video processing, which will be able to classify specific shots from your video using your own data labels.
While on the feature-list level Google AI services may be lacking some abilities, the power of Google APIs is in the vast datasets that Google has access to.
Image and (no) video processing APIs: IBM Visual Recognition
The Visual Recognition API by IBM currently doesn’t support video analysis, which is already available at other providers (hence the headline of this section). And the image recognition engine suggests a basic set of features, somewhat limited compared to what other vendors offer:
- Object recognition
- Face recognition (the API returns age and gender)
- Food recognition (for some reason, IBM engineered a dedicated model for foods)
- Inappropriate content detection
- Text recognition (this part API of the API is in private beta, so you must request a separate access)
This API was also deprecated, supporting existing instances until the end of 2021. And IBM doesn’t seem to offer any alternative yet. Partially, Visual Recognition API functions were integrated into its Neural Network and Deep Learning service.
Specific APIs and tools
Here, we’ll discuss specific API offerings and tools that come from Microsoft and Google. We didn’t include Amazon here, as their sets of APIs merely match the above-mentioned categories of text analysis and image+video analysis. However, some of the capacities of these specific APIs are also present in Amazon products.
Azure Bot Services. Microsoft has put a lot of effort into providing its users with a flexible bot development toolset. Basically, the service contains a full-blown environment for building, testing, and deploying bots using different programming languages.
Interestingly, the Bot Service doesn’t necessarily require machine learning approaches. As Microsoft provides five templates for bots (basic, form, language understanding, proactive, and Q&A), only the language understanding type requires advanced AI techniques.
Currently, you can use .NET and Node.js technologies to build bots with Azure and deploy them on the following platforms and services:
- Bing
- Cortana
- Skype
- Web Chat
- Office 365 email
- GroupMe
- Facebook Messenger
- Slack
- Kik
- Telegram
- Twilio
AWS ML hardware. Recently introduced physical products by Amazon are packed with dedicated APIs to program hardware with deep/machine learning models. The lineup of ML-algorithm-based-products of Amazon is presented by three units:
AWS DeepLens is a programmable camera that is used to apply ML to the actual hardware. In this case, you can apply Amazon ML services using the camera that can be used for visual data recognition and training ML models on them.
AWS DeepRacer is another hardware piece of the ML pack that is basically a 1/18 radio-controlled car utilizing reinforcement learning.
AWS Inferentia is a chip tailored for deep learning processing and can be used to reduce computing costs. It supports TensorFlow, PyTorch, and Apache MXNet.
Bing Search from Microsoft. Microsoft suggests seven APIs that connect with the core Bing search features, including autosuggest, news, image, and video search.
Knowledge from Microsoft. This APIs group combines text analysis with a broad spectrum of unique tasks:
- Recommendations API allows for building recommender systems for purchase personalization
- Knowledge Exploration Service allows you to type in natural queries to retrieve data from databases, visualize data, and autocomplete queries
- Entity Linking Intelligence API is designed to highlight names and phrases that denote proper entities (e.g. Age of Exploration) and ensure disambiguation
- Academic Knowledge API does word autocompletion, finds similarities in documents both in words and concepts, and searches for graph patterns in documents
- QnA Maker API can be used to match variations of questions with answers to build customer care chatbots and applications
- Custom Decision Service is a reinforcement learning tool to personalize and rank different types of content (e.g. links, ads, etc.) depending on user’s preferences
Google Cloud Talent Solution. Unlike conventional job search engines that rely on precise keyword matches, Google employs machine learning to find relevant connections between highly variative job descriptions and avoid ambiguity. For instance, it strives to reduce irrelevant or too broad returns, like returning all jobs with the keyword “assistant” for the query “sales assistant.” What are the main features of the API?
- Fixing spelling errors in job search queries
- Matching the desired seniority level
- Finding relevant jobs that may have variative expressions and industry jargon involved (e.g. returning “barista” for the “server” query instead of “network specialist”; or “engagement specialist” for the “biz dev” query)
- Dealing with acronyms (e.g. returning “human resources assistant” for the “HR” query)
- Matching variative location descriptions
Watson Assistant. The Watson chatbot platform (formerly Conversation) is rather famous among AI engineers that specialize in conversational interfaces. IBM provides a full-fledged infrastructure for building and deploying bots capable of live conversation leveraging entity and user intent analysis in messages.
Engineers can either use built-in support from Facebook Messenger and Slack deployment or create a client application to run the bot there.
All four platforms described before provide fairly exhaustive documentation to jump-start machine learning experiments and deploy trained models in a corporate infrastructure. There are also a number of other ML-as-a-Service solutions that come from startups, and are respected by data scientists, like PredicSis and BigML.
The next move
It’s easy to get lost in the variety of solutions available. They differ in terms of algorithms, they differ in terms of required skill sets, and eventually they differ in tasks. This situation is quite common for this young market as even the four leading solutions that we’ve talked about aren’t fully competitive with each other. And more than that, the velocity of change is impressive. There’s a high likelihood that you’ll stick with one vendor and suddenly another one will roll out something unexpectedly that matches your business needs.
The right move is to articulate what you plan to achieve with machine learning as early as possible. It’s not easy. Creating a bridge between data science and business value is tricky if you lack either data science or domain expertise. We at AltexSoft encounter this problem often when discussing machine learning applications with our clients. It’s usually a matter of simplifying the general problem to a single attribute. Whether it’s the price forecast or another numeric value, the class of an object or segregation of objects into multiple groups, once you find this attribute, deciding the vendor and choosing what’s proposed will be simpler.
Bradford Cross, founding partner at DCVC, argues that ML-as-a-services isn’t a viable business model. According to him, it falls in the gap between data scientists who are going to use open source products and executives who are going to buy tools solving tasks at the higher levels. However, it seems that the industry is currently overcoming its teething problems and eventually we’ll see far more companies turning to ML-as-a-service to avoid expensive talent acquisitions and still possess versatile data tools.

Oleksandr is a content strategist and editor. He leads (when possible) the team of independent-thinking writers and tech journalists at AltexSoft. With over 10 years of writing and editing tech-related pieces and scripts, he currently focuses on travel tech, data science, and AI. Outside of work, Oleksandr enjoys escapism in video games and game development.
Want to write an article for our blog? Read our requirements and guidelines to become a contributor.