How many days will a particular person spend in a hospital? Healthcare facilities and insurance companies would give a lot to know the answer for each new admission. Today, we can employ AI technologies to predict the date of discharge. This article describes how data and machine learning help control the length of stay — for the benefit of patients and medical organizations.
Why is the length of stay important?
The length of stay (LOS) in a hospital, or the number of days from a patient’s admission to release, serves as a strong indicator of both medical and financial efficiency. A shorter LOS reduces the risk of acquiring staph infections and other healthcare-related conditions, frees up vital bed spaces, and cuts overall medical expenses — to name just key advantages.
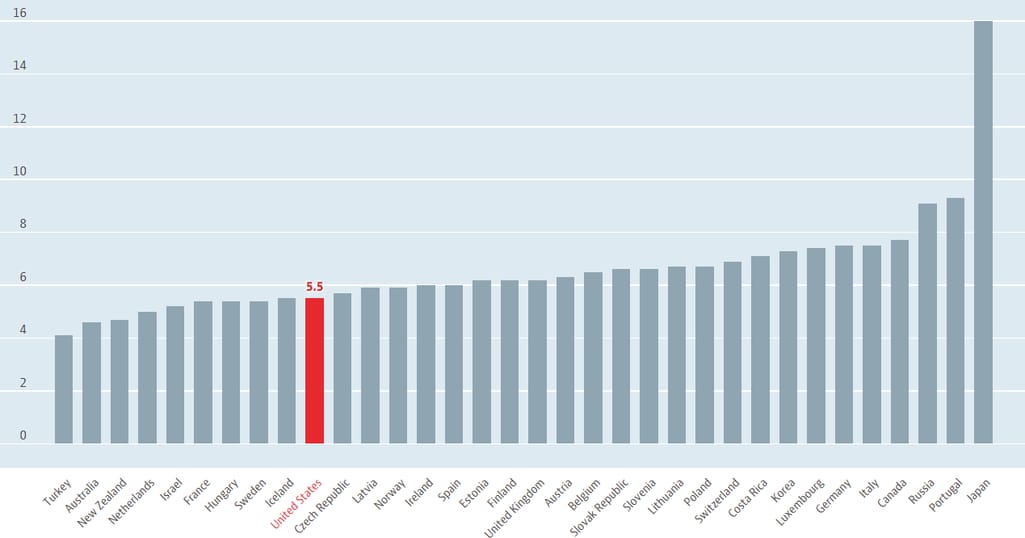
It’s worth noting that the average LOS has dropped significantly over the past decades. In the US, the duration of hospitalization changed from an average of 20.5 days in 1960 to just 5.4 days. This is one of the shortest periods of inpatient treatment globally, with Turkey at one extreme (4.1 days) and Japan — at another (16 days).
The average length of hospital stay across countries. Source: OECD Data
Even given such a reduction, the hospital stay remains extremely expensive, costing around $2,873 per inpatient day. While it’s not always possible to cut costs by decreasing LOS, hospitals still can save money by allocating personnel and resources in a more efficient way. But to improve planning, they need to accurately forecast the LOS value at admission time.
Length of stay calculation for hospitals: how machine learning can enhance results
Traditionally, to predict the date of release, hospital administrators rely on the facility's average length of stay (ALOS). For monthly ALOS calculation, add bed days for each discharged patient and divide the sum by the number of discharged patients. The final prediction is made taking into account a several-day margin of error.
Yet, such an approach generates rough results that have a lot of room for improvement. More and more hospitals are considering replacing old methods with machine learning tools to achieve better accuracy. Here is a сouple of examples proving that ML-based predictions are worth investing in.
Intel and Cloudera saved a hospital system millions of dollars
A large hospital group partnered with Intel, the world’s leading chipmaker, and Cloudera, a Big Data platform built on Apache Hadoop, to create AI mechanisms predicting a discharge date at the time of admission. In collaboration, they trained random forests — ensemble algorithms consisting of many decision trees — to generate individual forecasts. Results were based on medical histories, the condition being treated, and socioeconomic factors that chiefly impact LOS.
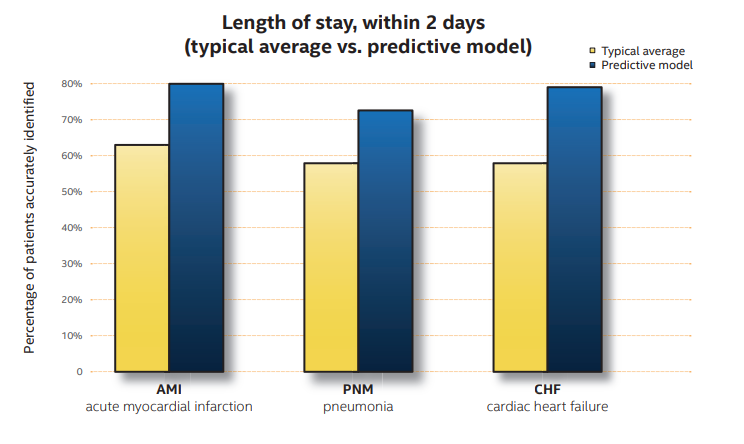
The accuracy of LOS prediction: typical ALOS calculations vs predictive model. Source: Intel
Cloudera-based predictive models enhanced the accuracy of LOS forecasts by 25 to 40 percent — if compared with traditional calculations (ALOS plus a two-day margin of error.) And though new technologies didn’t reduce LOS, they enabled better planning which, in turn, led to
$15 million of annual savings in medical services,
$120 million of annual savings in total expenses, and
the ability to serve extra 10,000 patients per year.
Besides improved resource allocation, the hospital group uses individual predictions to identify patients at risk of an extended LOS and optimize their treatment plans.
An AI-fueled tool reduced LOS by 3,500 patient days per year
Texas’s largest not-for-profit healthcare system, Baylor Scott & White Health, performed research in one of their smaller-to-mid-size hospitals and discovered that the staff spent 900 man-hours a year on daily LOS-related efforts. To address this issue, the organization implemented ReLOS (Reduction of LOS) — an AI-fueled solution from Pieces.
The tool processes both structured and unstructured data associated with patients to evaluate the likelihood of their going home within 24 hours. Later, the system continues to monitor patients, regularly assessing their readiness for discharge and risks of readmission (hospitals may face penalties for readmissions within 30 days.) The built-in algorithm learns from every case, enhancing its results over time.
The technology reduced the LOS by three to ten percent which amounts to 3,500 patient days annually and as a result saved 850 nursing review hours.
Data preparation for LOS prediction
As with any ML initiative, everything starts with data. You need a robust amount of inpatient information to teach an algorithm to produce accurate forecasts. The main sources of such data are electronic health record (EHR) systems that capture tons of important details. Yet, there’re a few essential things to keep in mind when creating a dataset to train an ML model.
Factors impacting LOS
LOS is a complex metric that depends on multiple factors and significantly varies across conditions and healthcare facilities. So, you have to carefully select elements that determine the length of stay in your particular case. For example, variables used to predict LOS in the cardiac surgery intensive care unit include
age,
gender,
oxygen delivery index (the amount of oxygen tissues receive),
hematocrit (the percentage of red blood cells in your blood), and
serum creatinine level, reflecting how well your kidneys work.
Other factors contributing to the duration of inpatient treatment range from vital signs to marital status. In general, demographics and medical history remain relevant, no matter the facility or disease. But you still have to decide what other aspects are to be considered in your dataset, depending on the service or diagnosis in question.
Inpatient data anonymization
To legally use patient data in any research or business projects, you must first de-identify it — in other words, remove all elements of protected health information (PHI) linking a record to a particular individual. This includes names, emails, and phone numbers — to name just a few of 18 personal identifiers specified as PHI by the Health Insurance Portability and Accountability Act (HIPAA.) Anonymization prevents HIPAA violations resulting in million-dollar penalties.
Even without a de-identification step, preparing a dataset for machine learning is a resource-intensive process. If you lack time and experts, take advantage of ready-to-use, anonymized data available over the Internet. Here are several popular options for LOS model development.
MIMIC database
MIMIC, standing for Medical Information Mart for Intensive Care, is a free database containing medical data collected from intensive care unit (ICU) patients. It consists of several modules.
The Core module contains patient tracking data — demographics, hospital admissions, and in-hospital transfers.
The HOSP module provides data extracted from hospital EHRs including lab test results, medications, and billed diagnoses.
The ICU module is a collection of data from clinical information systems used by intensive care units.
The ED module focuses on data captured in emergency departments — like vital signs and reason for admission. And there are
several others.
Overall, the MIMIC database features health data from over 40,000 critical care patients and embraces multiple variables. But to get access to this treasure, you must сomplete a training course in human subjects research and sign a data use agreement.
eICU Collaborative Research Database
eICU Collaborative Research Database became publicly available thanks to Philips Healthcare and the MIT Laboratory for Computational Physiology. It contains de-identified data associated with over 200,000 ICU patient stays and covers
vital sign measurements,
lab test results,
patient history,
care plan documentation,
APACHE severity of illness scores,
diagnosis information, and
treatment details.
As with MIMIC, you have to complete a training course and sign the data use agreement for the project. Only under these conditions, will you be able to get credentialed access.
Syntegra synthetic data
Syntegra is a commercial provider of healthcare datasets. Among other products, they offer synthetic data built upon information from US-based EHR systems. It accurately reflects the original EHR content tracking a patient journey during a hospital stay, but without any identity traces. The data is cleaned and ready for immediate use in ML projects.
Length of hospital stay prediction models
Predicting length of stay can be viewed either as a regression or a classification problem that will dictate the choice of an algorithm. If we are going to forecast a numerical value — or how many days a particular patient will spend in the hospital — it’s a regression task.
Though it’s common to measure the LOS in days and predict it accordingly, we can also frame it as a classification task. In this case, we’ll deal not with the duration but with being in a certain category.
You may divide all observations into two broad categories (binary classification) — for example, patients who would remain in the hospital for two more days and those who wouldn’t. Or designate several categories (multiclass classification) — such as stays shorter than a day, three-day-long stays, seven-day-long stays, and so on. The model will identify to which group a particular instance relates.
Of course, you must decide on the general approach at the data preparation stage as it will impact data labeling. Yet, both ways are quite popular and make much sense — depending on the project goal. Below, we’ll overview algorithms that showed the best results in different studies.
Random Forest: LOS predictions for COVID-19 patients
We’ve already mentioned Random Forest (RF) in this article when describing a LOS predicting model built by Intel. This ensemble learning algorithm combines outputs of multiple decision trees that cover for each other's weaknesses. Such teamwork allows for achieving better performance and prediction accuracy than with a base model.
RF is one of the most widely-used methods in forecasting mortality, severity, and length of stay in intensive care units. For example, recently, an RF classifier outperformed other options in the prediction of LOS for COVID-19 patients, hitting the accuracy of 94.16 percent. For classification, the range of days from 0 to 58 was divided into nine smaller intervals, each assigned a label from 1 to 9.
As for factors contributing to the length of stay, the study revealed three most important ones — age, the C-reactive protein (CRP) test results (the high level of CRP in the blood signals acute inflammation), and nasal oxygen support days.
The Gradient Boosting Decision Tree (GBDT) is another type of ensemble learning algorithm using numerous decision trees. But unlike Random Forest where trees generate results in parallel, GDBT relies on a sequential approach: Each next tree learns from the mistakes made by its predecessors.
When it comes to LOS, GBDT can show even better results than RF. It was the winner in the prediction of prolonged length of stay in intensive care units among general patients.
Long short-term memory network: modeling the remaining LOS
There are numerous studies describing experiments with deep learning models trained to predict LOS. The most promising results belong to recurrent neural networks (RNN) or, to be more precise, to their specific architecture — long short-term memory (LSTM).
In RNNs, the data flows through feedback loops that “remember” context from previous processes. This context is then combined with the input for the next step. The ability to consider the current input along with results from prior steps makes the neural network a perfect match for sequential data, such as time series, audio data, texts, etc.
The problem is that a regular RNN architecture has a short memory. In other words, it loses a part of the information from earlier layers. LSTMs appeared to overcome this limitation. They basically bring the ability to add or remove information, learning over time what is important and what can be deleted. Such selectivity allows the model to remember significant things from numerous prior steps and understand long-term dependencies.
LSTM proved to perform well for different instances — from a long length of stay prediction (binary classification) to forecasting the remaining time spent in the intensive care unit, which involves 10 possible classes (“less than a day” as the shortest period and “over two weeks” as the longest, with eight more in between.) The architecture also beat other deep learning models when classifying the remaining LOS of newborns admitted to the neonatal ICU.
LOS solutions: what it takes to develop them
In most cases, LOS forecasting tools are custom-made products, with only a few solutions available off-the-shelf. One of such rare tools is Length of Stay Predictor by Virtusa Corporation. Under the hood, it runs a deep learning regression model that forecasts the exact number of days a new patient is supposed to spend in the hospital.
Yet, only an individual approach can guarantee the best possible accuracy. To develop a bespoke model, you need a multi-functional team that combines the expertise of medical specialists, data analysts, and data scientists. Together, they will decide on
what exactly to predict (number of days, one of the multiple duration categories, or just whether the stay is normal or prolonged),
how to annotate the dataset,
which features impact the LOS most of all, and
which of multiple algorithms to choose.
The answers will vary a lot across different healthcare facilities — general and children’s hospitals, intensive care units, rehabilitation centers, departments dealing with specific diseases, and so on.
Once the algorithm is selected, you have to take your time to train models and choose the one producing the best results. The process involves a great deal of experimentation and research and may last longer than you expect. But given the expected benefits, it’s a worthwhile endeavor.
From prediction to reduction
Keep in mind, though, that LOS prediction doesn’t automatically result in LOS reduction. If this is your main goal, you need to consider other advanced technologies — namely,
patient portals that allow people to better manage their health themselves;
Internet of Medical Things devices and digital therapeutics software that help people monitor their conditions and cope with diseases by receiving health-related tips, med intake alerts, and care recommendations; and
Counterintuitive as it may sound, being an inpatient at a healthcare facility instead of getting treatment at home may slow down recovery. Not to mention the significant budget drains it causes.