

Data is one of today’s most valuable resources. But collecting real data is not always an option due to the cost, sensitivity, and processing time. But synthetic data can be a good alternative to rely on for training machine learning models. In this article, we will explain what synthetic data is, why it is used and when it's best to use it, which generation models and tools are out there, and what the cases of synthetic data application are.
What is synthetic data?
Synthetic data is artificial data that mimics real-world observations and is used to train machine learning models when actual data is difficult or expensive to get. Synthetic data is different from augmented and randomized data. Let’s demonstrate the distinction of synthetic data from the other methods in a very simplified example of human face generation. Imagine that we have a data set of photos of real people.Data augmentation is basically the process of adding to the data set slightly modified copies of existing elements. Applying data augmentation to our data set we would expand it with almost the same faces but with a bit of difference in eye color or skin tone.
Data randomizers only shift elements within the data pool instead of creating new ones. And so with it, we would shift face characteristics between each of them, for example, the hair of person 1 would be combined with the mouth of person 2 and the eyes of person 3.
Synthetic data gives us totally new faces of people that have the characteristics of the original data set that does not depict the total original real face. Basically, by creating synthetic data we recreate something that exists in the real world, obtains its characteristics but does not depict them directly, i.e., a mash-up.
Synthetic data by itself does not have to be only computer generated. If we think about human history way before computerization, synthetic data existed as well, but it was only generated by humans. For example, the same face generation could be done by a person that creates new faces with drawings.
Numeric data generation also could take place but instead of using computational resources, people would rely instead on mathematical and statistical knowledge. But even with advances in mathematics and probability theory, generating synthetic data without computer resources is very time consuming and generally complicated.
Types of synthetic data related to its composition
Regarding its composition, there are two types of synthetic data: partial and full. The partial type is a data set that includes synthetic data and real data from existing observations or measurements. An example can be a generated image of a car inserted in a photo of a real setting.

An example of the virtual car in the real environment from the webinar Synthetic Data Generation in Machine Learning
The full type refers to data sets with only synthetic data. An example would be a generated image of a car in a simulated environment. When choosing whether the data set is going to be fully or partly synthetic, the decision should depend on the main purpose. For instance, fully synthetic data gives more control over the data set.

An example of the virtual car in the simulated environment from the webinar Synthetic Data Generation in Machine Learning
At the same time, models trained on synthetic input only might not ensure the best quality and safety in certain cases. For example, software for automated vehicles is better when trained on synthetic data and real data as well. Other machine learning models, applications of which involve less potential danger, could be trained on synthetic data only.
When and why synthetic data is used?
Synthetic data can be used for many purposes from research studies of radio signal recognition to training models for robot navigation. In fact, synthesized data can serve basically any goal of any project that would need a computer simulation to predict or analyze real events. There are several key reasons, a business may consider using synthetic data.
- Cost and time efficiency. Synthetic data may be way cheaper to generate than it would be to collect from real world events, if you don’t have a proper dataset. The same with the time factor: Synthesizing can take days to process, while real data collection and processing might take weeks, months, or even years for some projects.
- Exploring rare data. There are cases in which data are rare by or dangerous to accumulate. An example of rare data can be a set of unusual fraud cases. Dangerous real data could be exemplified by road accidents that self-driving vehicles must react to. In that case, we can substitute synthesized accidents.
- Privacy issues resolved. When sensitive data must be processed or given to third parties to work with, privacy issues must be taken into consideration. Unlike anonymization, generating synthetic data removes any identity traces of the real data, creating a new valid data set without compromising privacy.
- Easy labeling and control. Technically speaking, fully synthetic data makes labeling easy. For example, if a picture of a park is generated, it’s easy to automatically assign labels of trees, people, animals. We don’t have to hire people to label these objects manually. And fully synthesized data can be easily controlled and adjusted.
Two ways of generating synthetic data
There are basically two main ways to obtain synthetic data. Use
- generative models or
- conventional ways: special tools and software along with data purchase from third parties.
Both options can be applied to generate different types of synthetic data. But before diving into that, let’s first explain briefly what the most frequently utilized generative models are and which conventional methods can be implemented.
Generative models
Generative adversarial networks or GANs are the class of the most popular models for synthesizing data. They consists of two sub-models: generator and discriminator. The task of the generator is to synthesize the fake data, and the goal of the discriminator is to verify whether it looks like fake or real. Both work against each other, hence adversarial in the name.The discriminator is trained on real data to differentiate the generated fake data from the real data. The generator identifies more realistic data points that the discriminator eventually will classify as real. The process continues until the generator can synthesize data items that the discriminator is not able to differentiate from the real data input.
For example, let’s say our goal is to generate realistic images of dogs with GANs. We fill the training set with real photos that teach a discriminator to understand what real dogs look like. Then, we feed the generator with random noise from which it tries step by step to generate dog pictures. The generator sends those pictures to the discriminator which basically verifies whether the created dogs look real. As time goes on, the generator gets better, until the discriminator labels a synthesized image as a real one. GANs can be used for many data types synthesis such as images, videos, audios, handwriting, tabular data, and more.
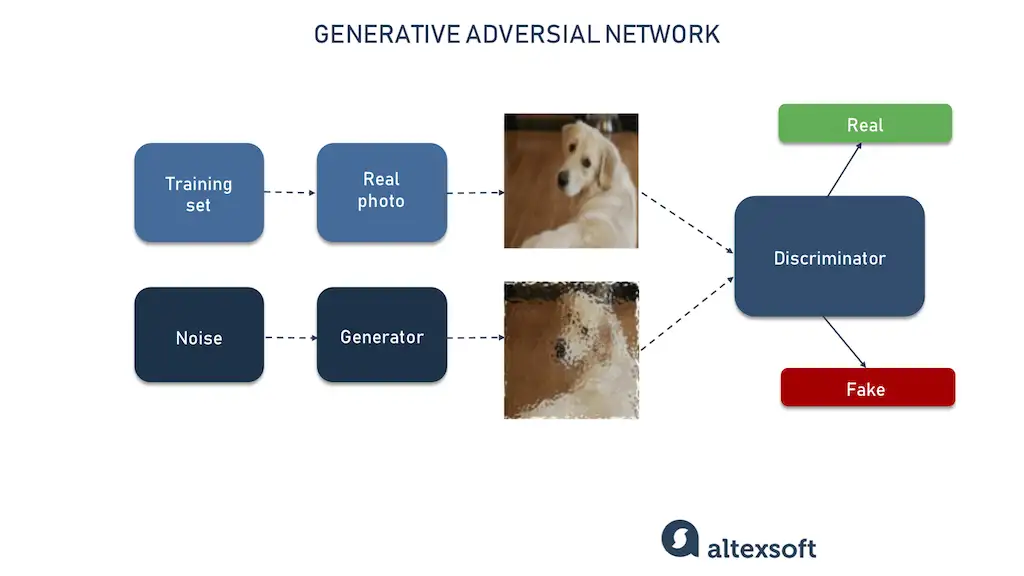
Process of data synthesizing with GANs
Variational autoencoders, also called VAEs, focus on learning dependencies in the data set. They reconstruct data points from the set in a similar way but also generate new variations. The application of variational autoencoders covers generating different types of complex data such as handwriting, faces, images, and tabular data.Autoregressive models or ARs are the class of models that are dedicated to time series and data sets with time-based measurement. AR models create data by predicting future values based on past values. They are widely used for forecasting future events, especially in the fields of economics and the natural environment. They are also commonly used to generate synthetic time series data.
Conventional methods
Conventional methods include obtaining synthetic data by generating it with a software or tool, or by partnering with a third party that offers these kinds of services. Tools and software, which can be found for free, can fulfill the needs of testing but might not be enough for excellent content performance. Also, choosing this method would require having an IT resource in the company.
On the other hand, partnering with companies that provide synthetic data obviates the need of a business to have its own IT personnel. Plus, normally third parties specialize in one precise type of synthetic data generation, which makes them more experienced in the specific field.
Types of synthetic data
As we said before, machine learning generative models and conventional ways of generation apply to any type of synthetic data. Here we have listed five main types describing which model, tool, and software should be used for the generation along with synthetic data providers.
Tabular data generation
Usually, tabular data includes way more sensitive and private details than other types. Exactly for these reasons, it must not just be anonymized but synthesized. Anonymization of data requires removal from data set characteristics by which a person can be identified. But this process is tricky.
In order to anonymize the data, some identification points in the set should be removed like name, address, and sex. The more data we erase, the less valuable information we have for future analysis. And even deleting a lot of private data of the same person still makes it possible to identify someone, just with the little information available. Such cases are closely monitored by the GDPR, a privacy law that affects all EU citizens and those doing business in the EU.
In order to generate tabular data, we should use GANs and their specific models such as CTGAN, WGAN, and WGAN-GP that all focus on tabular synthesis. There is a platform called The Synthetic Data Vault that offers libraries for easy learning of tabular data synthesizing. And there are providers of tabular synthetic data: MOSTLY AI, GenRocket, YData, Hazy, and MDClone. The last one specializes in medical synthetic data.
There are many applications of tabular data synthesis: in the fields of finance for fraud detection and economical prediction, healthcare and insurance for clients and events studies, social media for user behavior, streaming services for behavior and set of recommendations, marketing and advertising campaigns for customers behavior and reactions.Models: GANs, CTGAN, WGAN, WGAN-GP, VAEs
Tools: The Synthetic Data Vault
Services: MOSTLY AI, GenRocket, YData, MDClone, Hazy
Time series data generation
Time series synthetic data in some ways can be regarded as tabular data, but the main difference between these two is that time series is specialized on data that is attached to the time factor. To generate it with models anyone can use autoregressive models (AR) as they specialize in time series data. Likewise, there are GANs and a more temporal-oriented version of it TimeGAN for synthesis.
Most frequent applications of time series synthetic data are in the fields of financial predictions, demand forecasting, trade, market predictions, transaction recording, nature forecasts, component monitoring in machines and robotics.
In short, time series data is valuable for algorithms to learn patterns, predict the future, and detect anomalies. Concerning time series synthetic data providers, most of them are the same as tabular data providers as the two features usually work symbiotically and so providers offer both options.
Models: GANs, TimeGAN, ARServices: Gretel, MOSTLY AI, Hazy, Statice
Image and video data generation
Regarding image and video synthetic data, there are simply an endless number of ways in which it can be applied and be useful. But we can define two massive branches in which visual data synthesis is required. They are computer vision and face generation.
In the computer vision process, a machine learns how to understand what it sees for the purpose of taking a specific action. It is in high demand in the robotics and automotive industries. Both which require a computer to distinguish between objects and background, distances between them, and their sizes.


Computer vision, explained
NVIDIA Omniverse is a 3D simulation tool for various project purposes. The company launched the Isaac Sim robotic simulation application that facilitates testing machines in real-life environments. And there is another platform created by MIT ThreeDWorld that offers 3D world creation based on real world physics. OneView offers tools for synthesizing geospatial data. CVEDIA and Parallel Domain both produce data for computer vision training.
Face generation is basically synthesizing faces of humans that do not exist. This Person Does Not Exist is a service that offers for free fake, realistic photos of people. Generated human faces can be used to train machine learning models to recognize human faces, for example, for security purposes or robotics. Datagen is a provider that focuses on the face, and human and object data synthesis.
General methods to synthesize images and videos include GANs models that we have mentioned before, along with such tools like Unity, Unreal Engine, and Blender. These software solutions not only facilitate the generation but also offer reusable 3D data sets.
Models: GANs, VAEsTools: Isaac Sim, This Person Does Not Exist, Unity, Unreal Engine, Blender, ThreeDWorld
Services: NVIDIA Omniverse, OneView, CVEDIA, Datagen, Parallel Domain
Text data generation
Text and sound synthetic data have less frequent use in business, with greater use in research and art projects. Yet, textual data can be used to train for example chatbots, algorithms that check email boxes for spam, or machine learning models that detect abuse.
Talking about synthesized text, it is worth mentioning the text generation model GPT-3. It stands for Generative Pre-trained Transformer 3. GPT-3 is an autoregressive model that generates human-like language written in text that can be used to train machine learning models for text recognition or understanding. There is also the online tool Text Generation API that, using the GPT-2 model, creates short paragraphs of text based on the input.
But generally speaking, there are not that many services that work in the field of synthesizing textual data. Our hypothesis: There is already so much text data on the web for training machine learning algorithms that there is no need for synthesizing.
Models: GPT-3Tools: Text Generation API
Services: Gretel
Sound data generation
Just like with the textual synthetic data, sound is not that commonly offered by services to synthesize. That might be because creating a specific frequency and manipulating it doesn’t require synthesis, as it can be done with special software. There are professional options like Ableton Live and iZotope; more coding-oriented ones like Max and Pure Data; and a really simple one Audacity.
Synthetic sound data has potential in text-to-speech applications for services and general speech management for robotics. There are a lot of opportunities to get this data for machine learning training; one of the most popular is Text-to-Speech by Google. It includes different sexes, languages, and English accents/variants.
Another wide application of synthetic data is in research especially when it comes to physics. As we mentioned before, there can be an example of training models for radar tracking on the synthetic sound dataset. In this case, it is simpler to have a pool of artificial sounds than to record them from real cases. Regarding audio datasets available, there is a DagsHub source that contains labeled data sets with sounds.
Tools: Ableton Live, iZotope, Max, Pure Data, Audacity, DagsHubServices: Text-to-Speech, Replica
Cases of synthetic data application
That said, let’s have a look at some interesting business cases of synthetic data, as it gradually becomes a mainstream approach to acquire training data for machine learning tasks.Fraud prevention
American Express trained AI fraud prevention models on synthetic data. The company used GANs to synthesize fraudulent cases on which they did not have enough data. The goal was to augment the real data set with synthesized data in order to balance the availability of different fraud variations.
American Express card, source iStock
Medical simulations
PREDICTioN2020 research by Charité Lab for Artificial Intelligence in Medicine wanted to create a comprehensive platform for stroke outcome prediction. They used a hybrid model that combined image data and clinical parameters. Synthesized data was used to create biophysiological simulations.

Architecture pipeline of the PREDICTioN2020 research by Charité Lab, source Charité Lab
Face analysis
Fake it till you make it: face analysis in the wild using synthetic data alone, research by Microsoft. Researchers generated diverse human 3D faces including labeling to use as material for training machine learning models in computer vision, landmark localization, and face parsing. Results of the project showed that synthetic data can match real data with high accuracy.

Face parsing results by networks trained with synthetic data (with and without label adaptation) and real data, source article ‘Fake it till you make it: face analysis in the wild using synthetic data alone’
Chatbot development
Moveworks startup developed a chatbot trained on synthetic data to answer customers’ questions about finance, human resources, and especially about IT. Synthetic data was used to train on cases for which real data was limited. Moveworks’ bot helps to solve users' simple tasks such as password resetting, connecting a device, or software installation.
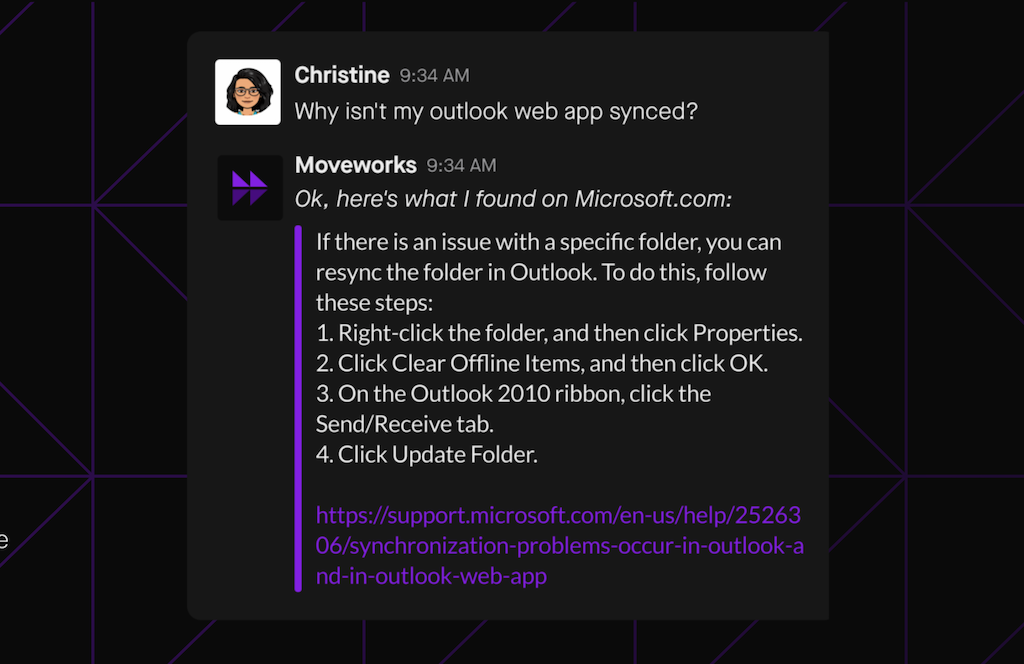
Screenshot of the conversation with AI-powered chatbot of Moveworks, source Moveworks
Churn model simulation
Swiss insurance company La Mobilière used synthetic data to train the churn model. Churn prediction is one of the common machine learning tasks used to identify and forecast customers who are likely to stop using the service. Effective churn prediction gives business time and information to proactively contact customers with better deals to make them stay. The main problem the company solved with synthetic data was privacy issues. From 2017, new compliance for private data usage in Switzerland started to be established, and so it was complicated and expensive to actually base models on real data. With synthetic tabular data, La Mobilière was able to obtain data for compliance model training.
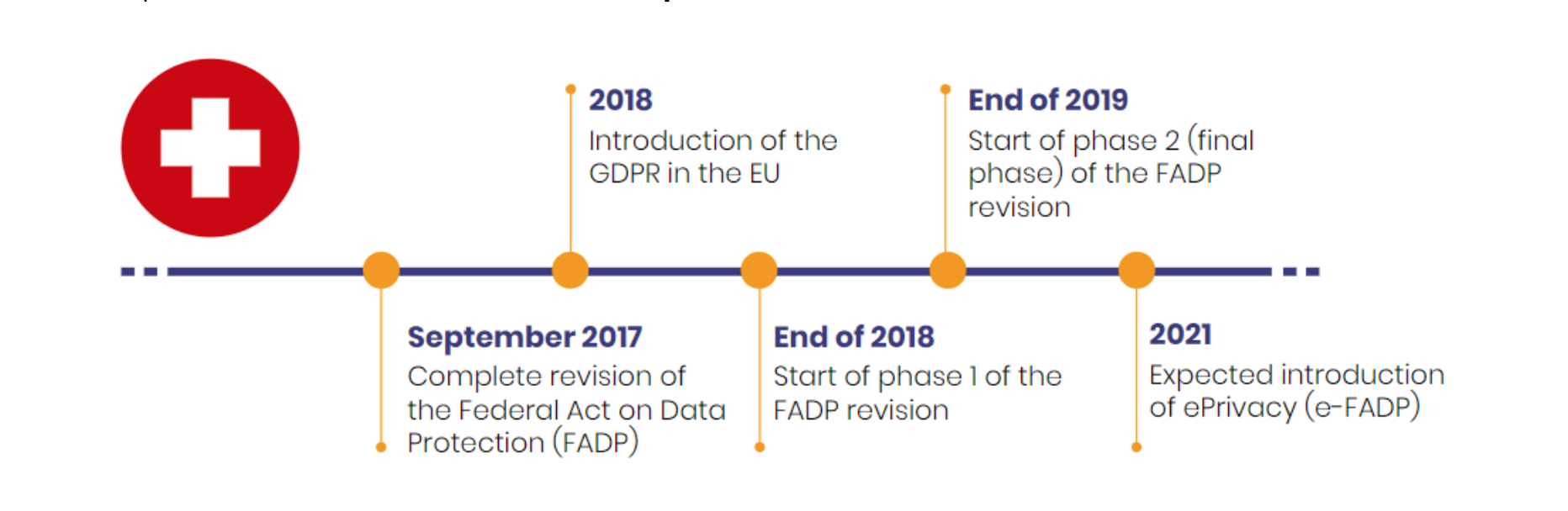
Compliances requirements evolution in Switzerland, source Statice case study
Virtual factory facility
Virtual factory space for robot navigation and production simulation for BMW was designed by NVIDIA. The aim of the simulation was to prototype a future factory facility, creating its digital twin. In the blended reality, BMW’s global teams were able to collaborate using various software packages to test, configure, and optimize the virtual production. Synthetic data was used to train models for robot movements within the virtual environment of the BMW factory.

Virtual BMW factory powered by NVIDIA, source NVIDIA
Dialog processing
Amazon trained Alexa on synthetic data to recognize requests in multiple languages. When a new language is being implemented into the system, the data pool of requests for the machine learning model is extremely poor. In this case, Amazon is utilizing synthetic data in combination with the real data to enrich their sample set and train natural-language-understanding (NLU) models of Alexa.
Alexa device, source Amazon
Self-driving vehicles
Waymo uses synthetic data to train self-driving vehicles. Waymo has created its own deep recurrent neural network (RNN) named ChaufferNet. In this environment, a vehicle is trained on labeled synthetic data along with real data to drive safely, while recognizing objects and following traffic rules. RNN imitates both good and bad road situations for self-driving cars to learn.
A completely synthetic, 8-hour Waymo driving simulation from Tucson, AZ to Austin, Texas, source Waymo
Synthetic data limitations
While using synthetic data has a lot of benefits, there are still cases when it might be better not to. The process of data synthesizing is faster and cheaper than actual data collection, but still it is very complex and requires an experienced human resource. Synthesized in a wrong way data might not represent the events in the real world correctly or still contain bias.Also there are cases in which collecting real data can be more profitable or useful depending on the goal. For instance, sociological research that gathers primarily variations of opinions regarding new events are way more reliable and valid than generating this data by the machine.
Outcome: synthetic data vs real data
Real data is extremely valuable but sometimes there are limitations in its processing such as privacy issues, and sometimes it becomes too precious, which is quickly reflected in the time and cost of obtaining it. And this is when synthetic data can save the day: being generated faster, cheaper, and in a fully controlled environment if needed.If a picture is worth a thousand words, perhaps a moving picture is worth more. So here is video demonstrating a machine’s experience in time compared to human’s for the same experience. Let’s look at the last case of synthetic data usage by OpenAI with the model powered by Unity. The goal of the synthesis was to teach the robotic hand to rotate the cube with letters on each side into specific positions; the perception of the machine was recorded via the camera, catching all the machine hand’s movements.
The human eye can normally perceive visual information at 30 frames per second, meaning that one year with this frame rate equals 1 billion frames. But a computer doesn't have to follow the same slow pattern. In the given example, the robotic hand was trained on 300 billion simulated frames which basically equals 300 years of human life.
Just a Blade Runner meme, source 9GAG