It’s impossible to count how many patients get mixed up in the healthcare system, but it happens a lot. Just recently, in Ohio, a wrong person was given a kidney transplant. Luckily, an organ happened to be compatible, but an error delayed the surgery of the patient that the kidney was intended for. Less fortunate cases happen too. In 2019, in New York, the woman took her brother off life support to later find out that the man wasn’t her brother, but a person with a similar sounding name.
The 2016 study by ECRI Institute analyzed 7,613 cases of wrong-patient errors in 181 healthcare organizations occurring between 2013 and 2015. And these were only the cases voluntarily submitted. The real number is unknown as they get swept under the rug or go unnoticed.
There’s no single solution to preventing these mistakes, but some actions can improve the situation significantly. For example, it was revealed that 13 percent of identification errors happen during registration, say, when duplicate patient records are created or different people's records get mixed up. By some estimates, these mistakes can cost an average hospital $1.5 million annually. This is one of the problems health information management is aimed to solve. The most popular and accessible solution is implementing a master patient index.
What is a master patient index?
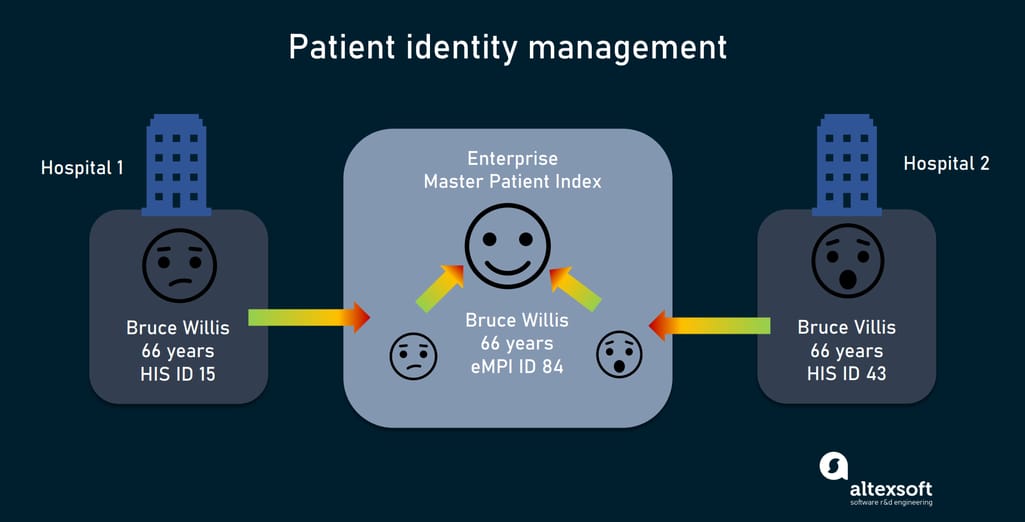
An enterprise master patient index (EMPI) is a database for maintaining and retrieving accurate patient demographic data across departments in a healthcare organization. Its main goal is to ensure that each registered patient is represented in all hospital’s systems only once. This is done not only to prevent disasters mentioned earlier, but also to:
improve the degree to which physicians can rely on computerized patient information,
provide accurate statistics for public health reporting,
serve as a single source of truth.
Patient identity management with Enterprise Master Patient Index
A master patient index is not a new concept by any measure, nor is it unique for the hospital setting. Many businesses are keeping a unified record of their customers in a similar fashion, through a master data management (MDM) platform. Let’s review how it works in relation to patient data.
A patient index stores patient demographic data used specifically for identification. There’s no strict requirement to what data elements should be collected, but it’s universally acknowledged that the key attributes include:
Name
Date of birth
Address
Phone number
Sex/Gender
Each organization integrating and developing an EMPI can also choose to include additional characteristics, such as:
Religion
Occupation
Employer
Next of kin
Ethnicity
Race
Now, an EMPI is not only a place to store the data in. It performs several functions, let’s review them.
Identifier assignment and linkage
A unique patient identifier (UID or UPI) is a code assigned to every person added to the database that’s then used in reference to the patient’s demographic data. An EMPI’s basic function is to manage and house UIDs. In the US, there are currently no standards for what UIDs must look like, so they’re commonly issued according to the logic of a particular EMPI provider. But there have been strides to create a national patient identifier that would be assigned by the government similar to social security numbers.
UID is comprising all patient demographic data in a single code
Source: NextGate
The second part of the feature is linkage, or merging all information about one patient from different sources in a unified record. This is done automatically per business rules. If a matching engine finds a match to a patient record, its ID will change to that of the different record, but its old one will be kept in the system history to easily track the changes.
Matching engine
A data matching engine is the heart of EMPI software. This mechanism can identify matching patient records and link them together into a single record. The accuracy of those matches depend on the type of algorithm the system’s using.
A lucrative nature of duplicate records
Source: JustAssociates
There are two types of matching algorithms – deterministic and probabilistic.
A deterministic algorithm looks for an exact match between attributes. Such a system will compare two records if they agree on some of the elements, like name, date of birth, and address. But if elements don’t match exactly – for example, there is the difference between a person’s last name and a maiden name, the system will reject it.
This system works well if you expect that all data is collected and standardized with utmost quality, but this is not realistic in the healthcare setting and with such varied data as name, address, and date of birth. This is why it makes sense to match those attributes separately and come up with a final match score in the end.
This is what a probabilistic algorithm does, looking for an approximate match with the help of statistics. It compares the same fields of two records (name and name) and assigns a weight indicating how closely those fields match. Say, Sarah and Sara have a pretty close match, so this field is given a high weight. The same is done to all other fields, and then all weights are summed up. The final match score is compared against a set of predefined thresholds and automatically categorized into one of three groups – Yes, No, and Maybe.
The Maybe records will have to be reviewed manually. A person must do the research, such as contacting the people in question for more data.
But false positives and false negatives can still happen. For example, the system may match people named Oliver Kinsey and Olivia Kinsey because they have similar-sounding names and the same last name, date of birth, and address. But this could actually be a pair of twins. To prevent such mistakes, add-on solutions are used. Apart from biometric technologies and RFID, which are expensive and lucrative to implement, you can apply referential matching.
Referential matching software gives the EMPI access to public and semi-public demographic data outside of your facility, for example, from credit reporting databases. Cross-referencing records from various systems allows the EMPI to make more accurate matches. This method, however, has limitations when it comes to children or other populations with lacking information, such as homeless people and undocumented immigrants.
Data cleansing
In data processing, there’s a principle called “garbage in – garbage out”, meaning that if you feed the system bad data, the output won’t be good as well. That’s why data quality issues have a negative impact on EMPI accuracy. This includes such problems as:
Inconsistent data formatting: phone numbers entered with and without a hyphen (12345678 and 1-234-5678)
Invalid or default data: 9-999-9999 inserted as default
Missing data
These issues can either restrict the system from automatically verifying records, so they have to be reviewed by a specialist, or create false positives and false negatives. To reduce the amount of “garbage out”, EMPI solutions often include data cleaning, profiling, and standardization tools. They typically perform the following tasks.
Revealing current data quality. The system analyzes the quality of data as you get it from the source to identify the values that should be considered in matching. For example, it can determine equivalent values such as nicknames (Ellie and Ellen) and anonymous values (using non-existent phone numbers and addresses).
Correcting inaccurate records. Based on predefined or custom rules, the system will validate the record values and standardize them. For example, it can check if the entered address is mailable or modify how it’s written to make it consistent with other addresses across the system.
Handling data completeness. Sometimes not all data fields are occupied and it can be problematic to contact every patient asking for missing values. In this case, the system can analyze how this particular value impacts searching and matching processes. If that data element is available in one record, but not in the other, would you consider it a match or not a match? The system will suggest matching rules based on absent data.
As a result, data cleansing saves two records: one containing information that was transformed and standardized, the other having initial entries. The latter one is used to write subsequent rules and improve the system accuracy.
Choosing an EMPI provider
There’s a difference between a master patient index and an enterprise master patient index. Both terms are often used interchangeably, but an MPI is typically handling records from a single registration system and is located within an EHR.
An EMPI is a standalone, cross-platform solution that links records from diverse systems and settings: physician practices, outpatient clinics, rehabilitation facilities, and more. So, even if a person received care at a different clinic, their records can be easily transferred and continuously updated. In one of the following sections of this article, we’ll give examples of solutions in both categories.
Here we’re covering enterprise products since they boast better matching accuracy and support true interoperability. Though many EHRs, such as Epic and Allscripts, assign patient IDs and do patient matching. So, ask your EHR provider what they can offer and compare it to the capabilities of EMPIs.
Apart from the features and pricing, make sure to take into account the following factors when choosing an EMPI vendor.
Certification and compliance. Ask providers what certifications they can show. Though this is not required by any government body, an EMPI product that’s certified by one of the following organizations provides proof that the product complies with modern healthcare guidelines.
Integrating the Healthcare Enterprise (IHE) is an organization that promotes the use of interoperability standards and provides frameworks for their coordinated use. IHE certification is a safe bet that an EMPI system is interoperable.
HITRUST certification is respected in the industry organization, which certification verifies that a company uses strict risk management and data security policies. It’s not a must by no means, but may help persuade your EMPI users that patient data will be kept safe in the system.
HIPAA compliance is a complicated one, because there’s no HIPAA certification that would matter: after all, these are just guidelines and the company enforces its own policies to adhere to HIPAA rules and principles. If an EMPI provider claims to be HIPAA-compliant, ask them what policies they set in place. This should give you a good idea of how serious they actually are about this “title.”
Support for data exchange standards. Interoperability is an important topic for the whole healthcare industry, but for an EMPI, it’s one of the main features. An EMPI must be integrated with a variety of disparate systems and the process is typically supported by the following healthcare data standards.
IHE standards. Namely, IHE creates Profiles, specific solutions to interoperability problems in healthcare. For EMPI, this includes such standards as PIX, PDQ, PDQm, XCPD, and more.
HL7 standards. HL7 is a standard developing organization behind FHIR – the main interoperability specification aimed to fill the gaps in health information exchange. Most EMPI systems support HL7 version 2 and 3, as well as HL7 CDA Release 2.
Now, let’s give a quick overview of popular providers.
NextGate EMPI: a flexible solution for every need
Available both on-premise and in cloud, NextGate EMPI allows you to check a person’s UID at the time of registration, before a new record is created, thus immediately preventing some duplicates from happening. They use both deterministic and probabilistic matching and help with API development if you need custom integration.
You can separately acquire AUGMENT, their referential matching module, that uses address verification technology. It standardizes address information and compares records to third-party data such as previous phone numbers and addresses.
IBM Initiate: robust and tech-heavy
IBM Initiate is a service included in IBM InfoSphere – master data management platform used across a variety of organizations, healthcare as well. It can be deployed on cloud, on premises, and on IBM Cloud Pak for Data – their data virtualization platform. This robust tool is typically used to perform data governance for AI applications, business analytics, or powerful knowledge bases, all supported by a self-service data pipeline.
Initiate keeps the master data registry, performs record matching and linking, and supports data integration using industry-specific standards. They also provide an integration suite consisting of an SDK and XML/HL7 APIs package.
InterSystems HealthShare: easy migration and reporting features
HealthShare is InterSystems’ EMPI solution that can be deployed on cloud, on premise, and on their AWS data platform. Apart from the Patient Index module, HealthShare has Provider Directory, Personal Community, and Health Insight modules, which can be combined per your requirements.
Other handy features include batch import, allowing for easy data migration from an existing database, detailed dashboards with record linkage info, a manual record viewer for simple validation, and more.
Just Associates EMPI Suite: modular and comprehensive
Just Associates offers a whole suite of patient identification tools:
ID Resolve, a quality assurance tool, used to review your current data integrity and suggest the best approach to correct duplicate records.
ID Analyze, their matching algorithm that searches for duplicates and data overlaps, as well as provides statistical reports.
ID Manage that provides a dedicated team for validation and eradication of duplicate records.
ID Sentry, designed specifically for acute care hospitals and integrated delivery networks using basic EHRs. It’s offered as a subscription.
Verato Universal MPI: a lightweight tool with ML capabilities
Verato’s main product is Universal MPI – a cloud-based enterprise system that uses a combination of a probabilistic algorithm and a machine learning-powered referencial matching technology. It’s modular and versatile, so you can easily integrate any of its features with an EHR or your existing EMPI and customer data platform (CDP). This can be their referential matching tech or an analytical add-on Enrich.
You can also expect flexible pricing, training resources as well as detailed API documentation, and maintenance included in your subscription.
How to prepare for EMPI and maintain data quality
There are two main scenarios a healthcare provider may find itself in:
An existing legacy MPI with low matching accuracy and subpar interoperability options
No dedicated E/MPI apart from simple features found in an EHR
What can you do in those cases?
Firstly, you can purchase an EMPI from a provider. While in the case of no E/MPI you won’t require additional setup, if you already have a system in place, you will need to perform data migration. Some vendors help with that, some don’t. Make sure you know a good tech partner to help you move to a new system safely.
Secondly, you can do digital transformation of your legacy MPI. There are different approaches to digital transformation, but the transformation process will allow you to fully control the safety of data during migration, as well as customly realize features that you’re seeking for. You can go creative with identity management, implement much more detailed matching algorithms, including the one incorporating machine learning, and align it with your practice’s workflow.
Either way, we want to give you a groundwork for preparing to implement or upgrade your EMPI.
Document policies and specifications. A client index must first and foremost respond to the context of your healthcare practice and the community it works for. A pediatric or maternity center should consider how kids are recorded and create rules that put weights on specific values. Besides, analyze what environment an EMPI must exchange information with: map out all health information systems, data sources, and point of service applications that will access an EMPI.
Provide training. Train your registration staff how information should be entered into an EMPI. For example, they must type the patient’s name from their driver’s license rather than by sound. Or, if a patient arrives unconscious, there must be a set of reminders to update the John Doe information with their real name. EMPI providers often have training available for clients.
Create a support team. An EMPI is not a fully automated tool – you will need to update rules and occasionally verify record matching manually. That’s why you must prepare to assign EMPI management roles either to your current staff or outsource these tasks.
Evaluate the effectiveness of approaches. Develop a reporting practice and set up KPIs. An EMPI is a living and constantly changing product that may work differently depending on the workflow, rules, and your algorithm success.