

To drive deeper business insights and greater revenues, organizations — big or small — need quality data. But more often than not data is scattered across a myriad of disparate platforms, databases, and file systems. What’s more, that data comes in different forms and its volumes keep growing rapidly every day — hence the name Big Data.
The good news is, businesses can choose the path of data integration to make the most out of the available information. The bad news is, integrating data can become a tedious task, especially when done manually. Luckily, there are various data integration tools that support automation and provide a unified data view for more efficient data management.
In this article, we’re comparing several data integration tools against key criteria to help companies looking for ways to merge and centralize data make an informed choice.
Data integration in a nutshell
Data integration defines the process of collecting data from a number of disparate source systems and presenting it in a unified form within a centralized location like a data warehouse. This often includes such procedures as data profiling (searching for errors and inconsistencies), cleansing (removing duplicates, corrupted items, etc.), and transformation to achieve the format suitable for a target system.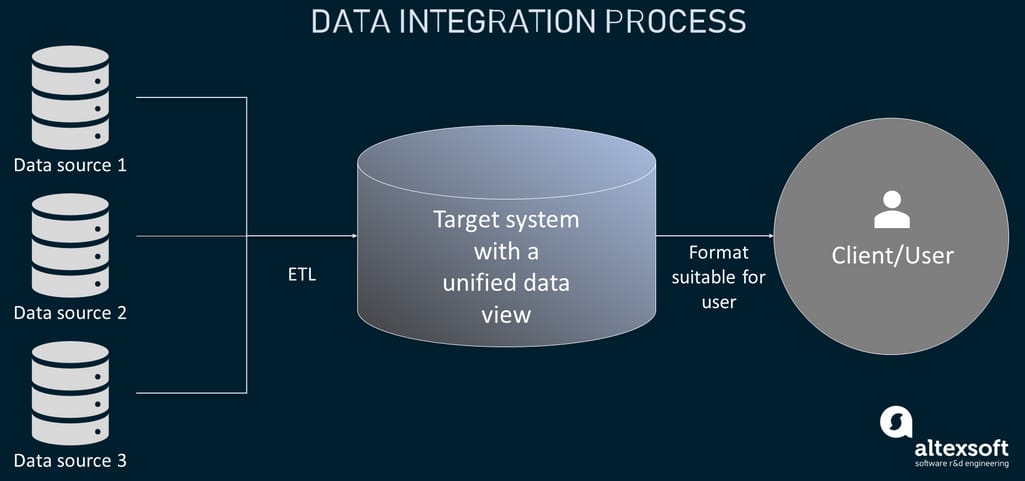
Data integration process
On the enterprise level, data integration may cover a wider array of data management tasks including
- data migration — the process of moving data from one storage system to another;
- data virtualization — the process of creating virtual (logical) views of data without moving it physically;
- data replication — the process of creating a copy (replica) of data from one system in another, and
- application integration — the process of enabling individual applications to communicate with one another by exchanging data.
Whatever the use case, either the ETL or ELT process is an integral part of data integration. Both contain the extract, transform, and load steps but with a different sequence. They are applied to retrieve data from the source systems, perform transformations when necessary, and load it into a target system (data mart, data warehouse, or data lake).
So, why is data integration such a big deal?
Let’s imagine you run a subscription-based business and you want to predict which customers are more likely to churn. For this purpose, you will have to build a 360-degree customer picture. But here’s the thing, even though you receive all the customer data you need, it exists in a bunch of disjointed sources such as CRMs, customer-facing apps, websites, and others. A single analytical report will require logging into numerous accounts, searching for specific pieces of data, copying them, perhaps cleaning some items, and converting data into a fitting form, all before any analysis happens.
That’s a lot of work. With data integration, you have all information available in a single interface resulting in faster, more efficient querying and analytics. At the same time, you get rid of the “data silos” problem: When no team or department has a unified view of all data due to fragments being locked in separate databases with limited access.
While data integration is attractive and fruitful in many ways, building such a solution in-house is a complex, time-consuming task that requires a lot of resources. Instead, companies can opt for automated data integration tools and platforms that often present no-code or low-code environments. With them, it is much easier and faster to comb through numerous data repositories to get the needed information.
Data integration tools and their main types
Data integration tools are software products that carry out the process of moving data from source systems to destinations. These tools are often equipped with the functionality to clean, transform, and map data all the way. Also, they can monitor the integration flow by searching for errors, generating reports, and performing other tasks. Usually, data integration software is divided into on-premise, cloud-based, and open-source types.
On-premise data integration tools
As the name suggests, these tools aim at integrating data from different on-premise source systems. Commonly deployed in the local network or private cloud, they contain specifically configured connectors to load data from multiple local sources as a batch operation. The local sources tend to include legacy databases that are difficult to work with.
Cloud-based data integration tools
Cloud-based tools make up another category. This software is often presented as integration platforms as a service (iPaaS) — a set of automated tools and services to develop, deploy, and maintain integration flows. Often equipped with APIs and Webhooks, these solutions help network data from various sources (including newer, web-based ones that stream data) to achieve a unified view of it. All of this enables iPaaS solutions to integrate data quickly — in real or near real time. At the same time, iPaaS support both more modern ELT and traditional ETL processes.
On-premises and cloud-based tools can sometimes be offered on an open-source basis, giving us the third category.
Open-source data integration tools
There are also open-source solutions that allow users to view source code and make changes to it. This software can be a good fit for companies that want to have greater control over the integrating process in-house and also avoid buying expensive enterprise software. It’s worth remembering though that open-source projects may entail hidden costs related to purchasing hardware, building networks, training staff, etc. Not to mention that they require a decent level of expertise to develop, deploy, and maintain data integration flows.
Now that you have a general picture of what data integration tools are, let’s compare popular vendors.
How to choose data integration software: key comparison criteria
Even if you know exactly which type of data integration software fits your needs, you may be blown away by the number of options available. Besides, there are a lot of additional factors that need to be taken into account before making a choice.
As a rule, good data integration products have
- easy-to-use interfaces;
- capabilities to examine, clean, and transform data;
- native connectors for different data integration use cases;
- scalability and elasticity to fit the changing landscape of data; and
- high security.
Please note: We aren’t promoting any of the software presented in the list. The idea is just to compare popular providers against the same criteria. To make a more informed decision, enquire about demos and do your own in-depth research.
Here, we’ll be comparing such vendors as
- Oracle Data Integrator,
- IBM InfoSphere,
- SnapLogic,
- Xplenty, and
- Talend Open Studio.
Before we start comparing these solutions face to face, it’s worth noting that all of them support extract, transform, load (ETL) and extract, load, transform (ELT) patterns. Connections to both data warehouses and data lakes are possible in any case. Also, the tools can work with different data types whether they are structured, unstructured, or semi-structured.
Another common functionality is the ability to schedule jobs. Once you have built your data integration pipeline, you can attach the needed jobs to a scheduler so that they run on their own. Also, solutions provide automated data mapping. As such, you can bridge the differences between data models of source systems and destinations by matching data fields and defining data transfer frequency.
With Big Data becoming a big deal in any industry, all tools provide a scalable data integration architecture and utilize powerful parallel processing technology for better scalability and performance.
Last but not least, all vendors present customers with the capability of secure data integration operations. Sensitive data can be protected using a combination of access controls and encryption. They comply with such standards as GDPR, HIPAA, SOC, CCPA, and many more.
Now that similarities are clear, it’s time to talk about distinctive tool features in more detail.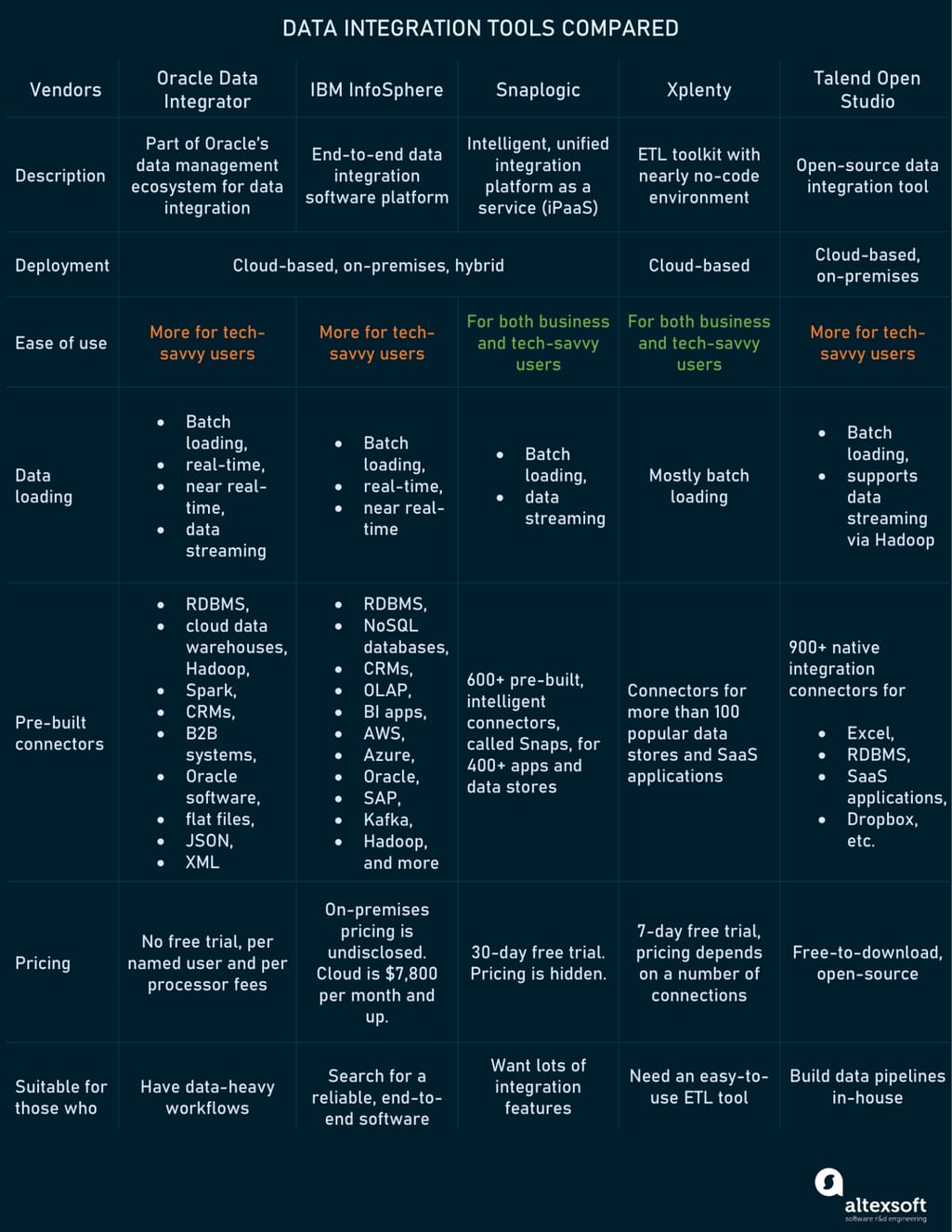
Comparison of data integration tools
Oracle Data Integrator: high-performance tool to handle Big Data
Considered to be a leader in the field of data integration, Oracle Data Integrator (ODI) is a multi-functional solution that is part of Oracle’s data management ecosystem. The platform provides features for event-based, data-based, and service-based integration styles. It works in the cloud, on-premise, and hybrid environments. While supporting ETL, its enterprise-level edition allows for ELT as well. As such, the tool is capable of moving and transforming Big Data.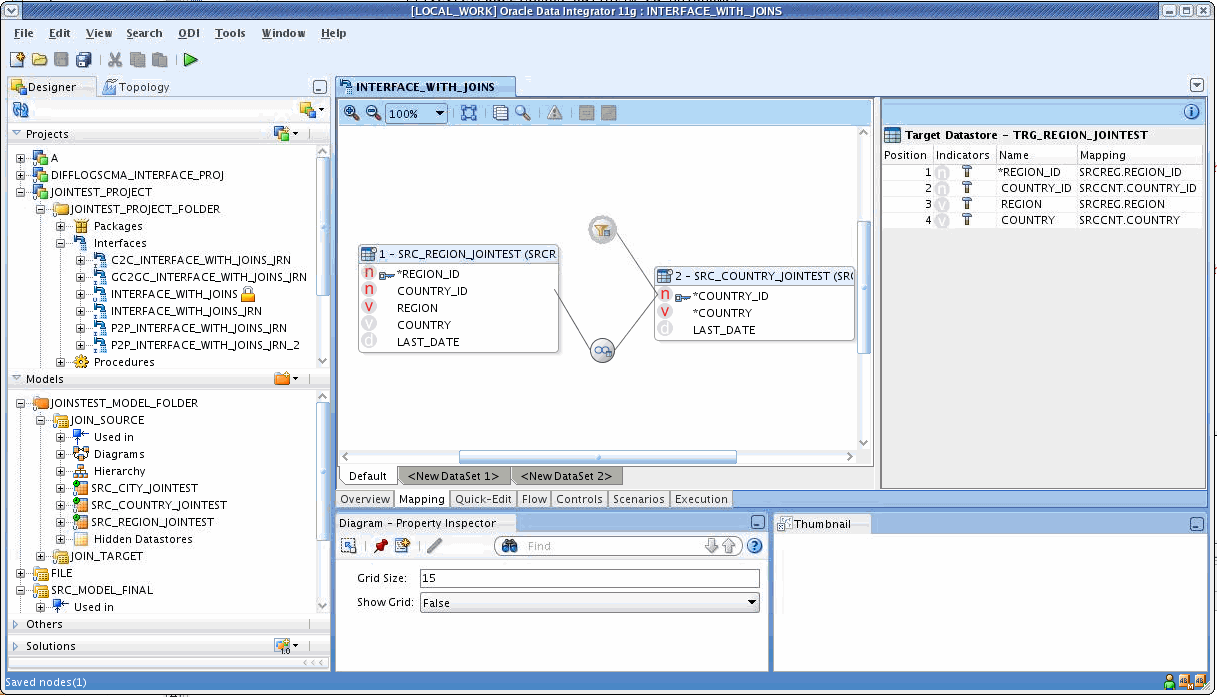
ODI interface editor. Source: Oracle
Ease of use. The prevailing number of users claim that it is quite easy to configure and manage data flows with Oracle’s graphical tools.
Data profiling and cleansing. Oracle Data Integrator automatically analyzes metadata from various data stores, detects patterns, generates, and then applies data quality rules to identify any issues among actual values. This works for both batch and real-time jobs. Data with errors can be then corrected, recycled, or accepted. The platform’s advanced features ensure that all information is accurate and consistent across an organization's different systems.
Data transformation. Based on the requirements, there are plenty of transformation operations available to manipulate data including split, join, filter, and others. As ODI supports both ETL and ELT data infrastructures, transformations can happen either in the staging area before data is loaded into a destination or after loading.
Data loading. The tool supports all sorts of data loading and processing: real-time, batch, streaming (using Spark), etc.
Pre-built connectors. ODI has a wide array of connections to integrate with relational database management systems (RDBMS), cloud data warehouses, Hadoop, Spark, CRMs, B2B systems, while also supporting flat files, JSON, and XML formats. The product integrates with other Oracle applications including Oracle GoldenGate, Oracle Fusion Middleware, Oracle Database, and others.
Pricing model. Oracle offers transparent pricing models but there’s no free trial. Companies can pay for ODI functionality in two ways: per named user or per processor. The costs are $900 per named user (plus $198 for a software update license and support) or $30,000 per processor (plus $6,600 for a software update license and support.)
Suitable for. Oracle Data Integrator can be a great help for huge enterprises that need to handle Big Data integration jobs effectively. Also, it is an option for those already using other Oracle products.
IBM InfoSphere: reliable enterprise-grade data integration software
IBM InfoSphere Information Server, as the company describes it, is “a leading data integration platform that helps you more easily understand, cleanse, monitor and transform data”. The solution fits different deployment options — on-premise, private/public cloud, and hybrid environments. The platform's main capabilities comprise data integration, data quality assurance, and data governance.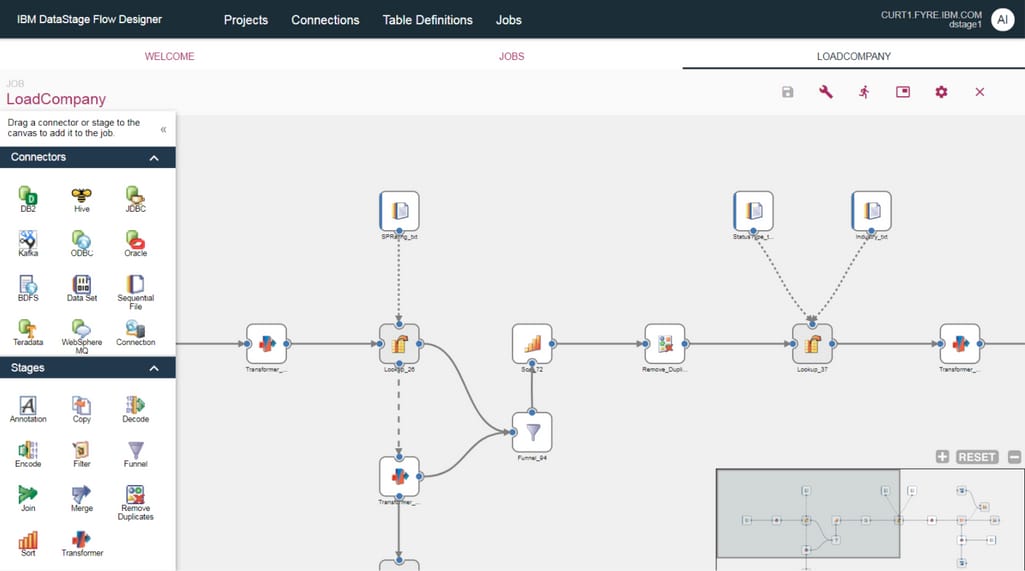
IBM DataStage Designer interface. Source: G2
Ease of use. The software includes InfoSphere DataStage Designer — a tool with an easy-to-use web-based graphical interface that is suitable for both tech-savvy specialists and non-programmers.
Data profiling and cleansing. The platform’s services called Information Analyzer and Business Glossary are responsible for data profiling. With them, you can model source data and comb through it to find whatever anomalies, issues, and inconsistencies exist. Then QualityStage and AuditStage take care of data quality processing by cleaning it and fixing problems.
Data transformation. With IBM’s advanced ETL and ELT processes, you can transform data according to the requirements of a target data source before it gets there or directly in it. There are built-in transformation functions available in DataStage to standardize, match, filter, and enrich integrated information.
Data loading. With IBM, you can develop jobs for real-time, near real-time, and batch data integration. Data can also be delivered through virtualization and replication options.
Pre-built connectors. IBM InfoSphere Information Server is equipped with plenty of connectors that cover most relational and non-relational databases, CRMs, OLAP software, and BI applications. There are also out-of-the-box connectors for such services as AWS, Azure, Oracle, SAP, Kafka, Hadoop, Hive, and more.
Pricing model. InfoSphere Information Server has a transparent pricing model for the cloud version: The price starts at $7,800 per month. The cost of an on-premises version is undisclosed.
Suitable for. Mid-sized and large-sized businesses that need a reliable data integration solution.
Snaplogic: great tool for configuring integration of any kind
SnapLogic is an intelligent, unified integration platform as a service (iPaaS), which the company itself calls the Elastic Integration Platform. The toolkit provides robust self-service functionality and allows for networking data sources in the cloud, on-premises, and in a hybrid manner. All of this is possible owing to a collection of computing resources known as Snaplex. The latter is divided into types based on where computing resources are run: Cloudplex (public cloud), Groundplex (on-premises or private cloud), and Hadooplex (Hadoop cluster).
SnapLogic iPaaS architecture. Source: SnapLogic
Ease of use. SnapLogic offers a powerful, intuitive interface to build data integration pipelines on a so-called clicks-not-code basis. Users can leverage the Designer, Manager, and Monitoring Dashboard to govern data integration and all associated processes including orchestrations, connections, and schedules.
Data profiling and cleansing. SnapLogic includes all required capabilities to execute data profiling and cleansing. Data quality controls can be incorporated directly into integration pipelines.
Data transformation. Along with the more traditional ETL, SnapLogic has ELT capabilities that let you load data in a cloud data warehouse (e.g., Snowflake) and transform it in place. With standardization, formatting, and enrichment, data becomes consistent across different systems. Transformations include merging individual data items into one string, filtering data, removing duplicates, and plenty of other operations.
Data loading. The platform offers hybrid batch and streaming support as well as event-based integrations that react to changes in real-time.
Pre-built connectors. SnapLogic uses 600+ pre-built, intelligent connectors, called Snaps, that can integrate data from a wide pool of applications and data stores. Developers can build custom Snaps using an SDK and APIs.
Pricing model. SnapLogic provides a 30-day free trial. Pricing is hidden.
Suitable for. Companies that look for an extensive list of data integration features and a quick way to get a unified view of their data.
Xplenty: convenient low-code environment for data integration
Xplenty is a cloud-based, low-code data transformation and integration platform that helps users organize and prepare their data for advanced business intelligence and analytical purposes. The toolkit allows you to quickly build data pipelines, automate integration tasks, and monitor jobs.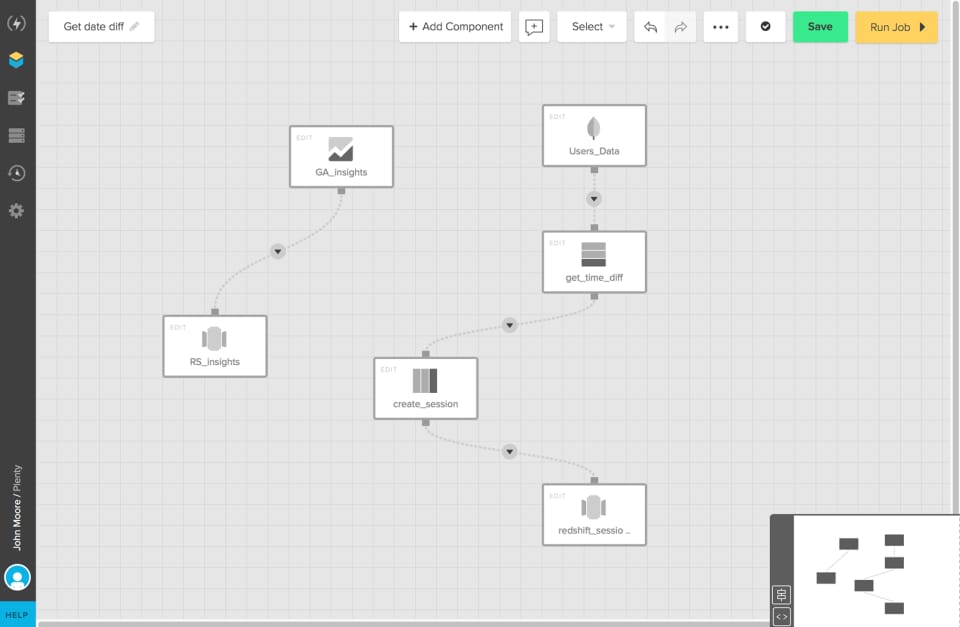
Xplenty interface showing table-level components. Source: SoftwareAdvice
Ease of use. As mentioned, Xplenty provides a low-code environment for building and managing dataflows via a simple, intuitive drag-and-drop interface. It’s well-suited for everyone from data engineers to business users with little or no tech expertise.
Data profiling and cleansing. Xplenty allows organizations that don’t have a data engineering team to perform data profiling and cleansing procedures automatically. Data is gathered from different sources and analyzed to identify data quality issues, inconsistencies, duplicates, etc. with their further correction.
Data transformation. Xplenty has more than a dozen no-code, table-level transformation components such as sort, join, clone, distinct, etc., that are quite simple to set up. Developers can use the API opportunities of the platform to customize transformations if needed.
Data loading. Xplenty puts a focus on batch processing, meaning data is processed and sent to destinations in batches at scheduled intervals. It is possible to move datasets with incremental loading (when only new or updated pieces of information are loaded) and bulk loading (lots of data is loaded into a target source within a short period of time).
Pre-built connectors. Xplenty has a bunch of native connectors readily available for use. They include NoSQL databases (e.g., MongoDB), SQL databases (e.g., MySQL), file stores (e.g., Hadoop), cloud data warehouses (e.g., Snowflake, Amazon Redshift, BigQuery), and other services like Google Sheets, Facebook Ads Insights, etc. These connectors allow for both extracting from and loading into sources. Xplenty has the REST API component so that it is possible to build custom connections to almost any other RESTful service out there.
Pricing model. The company provides transparent pricing packages and offers a 7-day free trial to users who want a demo. As a client, you will pay a flat rate on a monthly basis depending on the number of your connections.
Suitable for. Xplenty will serve companies that don’t have extensive data engineering expertise in-house and are in search of a mature easy-to-use ETL tool.
Talend Open Studio: versatile open-source tool for innovative projects
Talend Open Studio (TOS) is a free, open-source, unified platform used for data integration and migration between operational systems. It easily combines, converts, and updates data that lives in various sources. TOS supports both on-premise and cloud ELT jobs as well as Big Data implementations using databases like NoSQL, Hadoop, Spark.
The Graphical User Interface (GUI) of Talend with four main sections highlighted. Source: Section
Ease of use. Talend provides both tech and non-tech users with a convenient, self-service graphical design environment where they can perform various data integration jobs effectively. The Graphical User Interface (GUI) is quite easy to navigate: It consists of four main sections — repository, design window with workplace, palette, and configuration — that execute specific functions during data integration.
Data profiling and cleansing. Talend has a special component for data quality and error checks. Its profiling perspective applies out-of-the-box indicators and patterns to data to analyze data, identify any quality issues, and show matching and non-matching items. Data explorer can then be used to examine non-matching data, detect invalid records, and cleanse them.
Data transformation. Talend provides a separate set of components for configuring and executing data transformation operations. With them, it is possible to split, enrich, and convert data, and make other modifications. If a project requires writing a custom code, Talend provides an opportunity to add it.
Data loading. First of all, Talend is an ETL tool for batch data processing. There are also special tools to enable ELT and handle streaming data like Hadoop components, data lake interaction tools, cloud services connectors, and more.
Pre-built connectors. The software is packed with more than 900 native integration connectors for Excel, RDBMS, SaaS applications, technologies like Dropbox, and many more. They can be found in the palette section of the GUI. The required component can be simply dragged into the workplace In this application, components can be dragged from the palette section of the Graphical User Interface (GUI) and connected to run ETL jobs.
Pricing model. Talend Open Studio is available on a free-to-download, open-source basis.
Suitable for. Companies that have in-house tech expertise can greatly benefit from TOS owing to its open-source nature.
Which data integration provider to choose: general selection tips
Unfortunately, it is physically impossible to include all software providers offering data integration services into one comparison list as there are dozens of them available. Anyway, before you decide to go with one of mentioned or any other software solutions, make sure you know all the ins and outs. Here are a couple more tips on how to evaluate data integration technologies.
Gather requirements about data source and target systems. Before you even start combing through variants, list all your requirements for data integration initiatives including such important aspects as source systems, target systems, data types you operate, etc. If you rely on just a couple of relational databases containing structured data, you may go with a simpler and cheaper offering.
Round up must-have, nice-to-have, and can-do-without features. Lots of software products are packed with a great variety of features, but you don’t necessarily need all of them. So, it is a good idea to decide which features must be in a product, which are beneficial yet not
critical, and which ones don’t influence your integration flows at all. For example, if your company needs real-time data for analytics, the tool must support real-time and streaming data jobs.
Make sure you have needed skills and resources in place. Some tools are completely code-free while others require a decent level of technical expertise to handle integration tasks. So, if there are no developers in your company, it will make sense for you to choose a fully managed solution.