

Businesses today rely heavily on data. Which is a good thing! When data is subjective and accurate, it gives us a better understanding than we can fathom with our human brains. The important word here is when. Because as withany system, data processing is subject to mistakes. How do you trust data with any transformative decisions when there’s a chance that some of it has been lost, or is incomplete, or is simply irrelevant to your business situation?
Here, we introduce you to ETL testing - checking that the data safely traveled from its source to its destination and guaranteeing its high quality before it enters your Business Intelligence reports. But before you dive in, we recommend reviewing our more beginner-friendly articles on data transformation:
Complete Guide to Business Intelligence and Analytics: Strategy, Steps, Processes, and Tools
What is ETL Developer: Role Description, Process Breakdown, Responsibilities, and Skills
What is Data Engineering: Explaining the Data Pipeline, Data Warehouse, and Data Engineer Role
Or watch a 14-minute explainer on data engineering:


Data engineering explained
If you’re all set, let’s start by understanding the importance of testing your ETL process.
What is ETL testing and why do we need it?
As you probably know, the ETL or Extract, Transform, and Load process supports the movement of data from its source to storage (often a data warehouse) for future use in analyses and reports. And ETL testing ensures that nothing has been lost or corrupted along the way. And there’s a big risk that might happen.
First, it's because data is often collected in myriads of formats from tons of different (heterogeneous) sources. And the data warehouse may be of a different type too.
Second, sometimes the volumes of this data are huge and the number of their sources can keep growing.
And third, the mapping process that connects data fields in sources and destination databases is prone to errors: There are often duplicates and data quality issues.
Basically, the testing makes sure that the data is accurate, reliable, and consistent throughout its migration stages and in the data warehouse -- along the whole data pipeline. The terms data warehouse testing and ETL testing are often used interchangeably and that’s not a huge mistake. Because in its essence, we’re confirming that the information in your Business Intelligence reports address the exact information pulled from your data sources.
Here are some common errors that can be found during ETL testing:
- invalid values in source databases that result in missing data at a destination
- dirty data that doesn’t conform to data mapping rules
- nonstandard formats and inconsistent formats between source and target databases
- input/output bugs when invalid values are accepted and valid ones are rejected
- system performance bugs when multiple users or high data volumes are not supported, and so on.
Now, how do we ensure that data was safely mapped, transformed, and delivered to its destination?
Testing the ETL process is different from how regular software testing is performed. It’s virtually impossible to take the process apart and do unit testing (checking each piece of code). Here, you focus on testing the end-to-end process. Tons of planning are involved and a tester should have an intimate knowledge of how this particular pipeline is designed and how to write complex test cases for it. This means that ETL testing is mostly done manually, though we will talk about automation tools further in the article.
So, where does ETL testing start?
ETL test preparation
The main idea behind test preparation is analyzing the ETL process logic and transformation rules and then designing a test strategy based on it. A test strategy is a document that lists information about why we’re testing, what methods we’re going to use, what people or tools we will need for it, and of course, how long it will take. This information is then compiled into detailed test cases - step-by-step instructions for running a test.
Analyze ETL process documentation. To prepare for test case creation, developers and testers should study ETL process documentation - business requirements, technical specifications, and mapping specs to learn:
- what data elements will be integrated, their sources, types, destinations, and formats
- what transformation rules will be used for transforming and cleaning the data
- how and where the data will be loaded
That’s why ETL testing is commonly performed by ETL engineers themselves - you must understand the ETL process rules and be technically skilled at the second big task: preparing SQL queries.
Generate test data. Testers often can’t use sensitive and limited production data so they need real-time synthetic data to run tests against. And in ETL, the quality of input data plays an important role in understanding the quality of the data migration process. So, testers would either create this data manually or use test data generation tools like Mockaroo and Upscene.
Prepare test cases and scripts. Test cases describe what you want to check and how the testing will be performed. ETL test cases are usually written in SQL and have two queries: one that will extract data from its source and the other to extract it from the target storage. For example, a test case for completeness check would looking something like this:
- Check that all expect data is loaded into target database.
- Compare the number of records between source and target tables.
- Check if there are any rejected tables.
- Check that the data is displayed in full in target database.
- Check boundary value analysis.
- Compare unique values of key fields between source and target tables.
So, what tests are these cases written for?
ETL test types
As we already said, at any given point during ETL testing, we’re checking how the whole pipeline works and whether data remains consistent with its mapping instructions. That said, we can divide different types of tests into three groups:
- data quality and completeness, metadata
- data transformation process compliance
- performance and integration testing
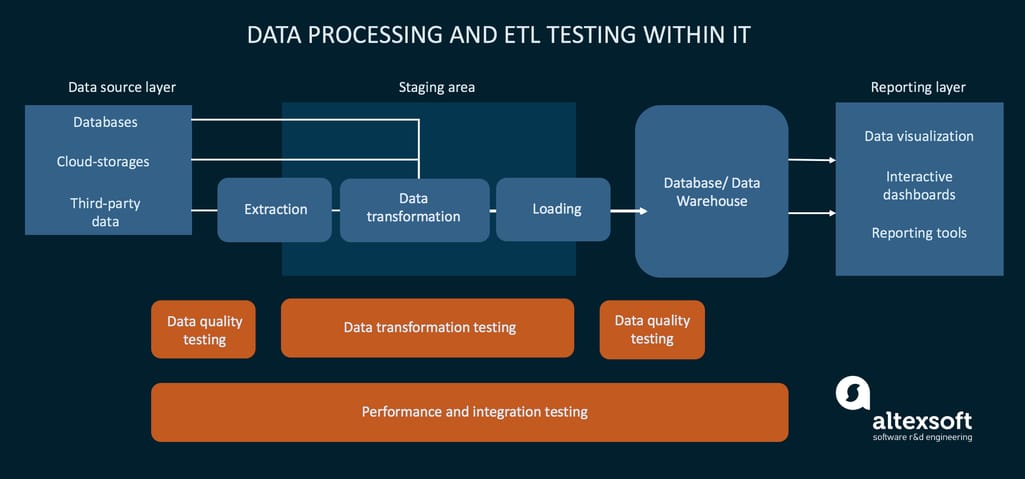
Testing operations within the ETL workflow
Data quality and completeness
Here, we need to confirm that data was extracted properly, hasn’t been lost, and there are no duplicates as source data will keep changing. This includes such tests as:
Checking duplicate data - making sure that there are no rows with the same unique key column or combination of columns. For example, if two rows have the same combination of first name and last name, those are duplicates.
Validating data according to rules - finding whether any fields violate validation rules: wrong symbols, incorrect dates, or input errors that make data invalid.
Metadata testing - verifying that definitions in tables and columns conform to the data model and application design: checking data types, lengths, namings, and how consistent they are across environments.
Reference testing - checking the data against the required attributes, for example, if data in a field contains numbers or dates and doesn’t have null values.
Data transformation success
Data transformation testing verifies that data were transformed as intended. This is where the preparation comes in handy because we compare transformation results to business requirements described in the documentation. There are two approaches to this: white box testing and black box testing.
White box transformation testing. Generally, white box testing entails testing application code. In the case of data transformation, it means checking the transformation logic and mapping design. So, a developer reviews how the source to target transformation happens on paper, then implements this logic in code and compares the transformed data to the one in the documentation. This method allows you to rerun the coded logic on any volume of data but requires a skilled developer to test.
Black box transformation testing. In black box testing, you check how the system functions, not how it’s designed. So here, a developer doesn’t have to learn the mapping design, but rather prepare the test data to reflect different transformation scenarios listed in the documentation. This is a classic manual testing method that allows you to test codeless.
ETL performance and integration testing
During the end-to-end (E2E) testing also called data integration testing, the entire application is tested in the environment that closely imitates production. Functions like communication to other systems, network, database, interfaces, and so on are all tested against the growing volumes of data.
Testing the performance of the whole ETL operation, we can identify bottlenecks and make sure the process is ready to scale with the growing volumes of data. This is usually done by checking the following:
- if data loads and queries are executed within the expected timeframe
- if the maximum data volume is loaded within the expected timeframe
- load times for different data volumes.
The end-to-end testing goes as follows:
- Developers start by estimating the expected data volume in all sources for the next few years.
- They then generate the expected volume of data either by scrubbing the production data or using data generation tools.
- They load test data and execute the process.
- Developers then review the run times for every individual tasks and execute task dependencies to see how they run in parallel.
- They review task load times to identify bottlenecks.
Information about CPU usage and execution time can be in ETL monitoring tools that create logs for each load process or are calculated manually.
Performance and E2E testing is the biggest candidate for automation. Let’s talk about it in detail.
Automated ETL testing and testing tools
Automated testing, meaning the use of special test automation tools, saves a ton of time and allows you to replace some labor-intensive processes. Automation software can be limiting and expensive, but incorporating at least some will result in better efficiency.
There is some dedicated ETL testing software on the market, some generic QA tools that have useful features, or your ETL platform would have testing add-ons.
Informatica PowerCenter Data Validation Option. One of the most popular data integration tools Informatica PowerCenter allows you to set up the testing environment and create repeatable tests. It’s possible using a combination of PowerCenter’s tools: Data Validation Client to create test case, DVOCmd as your command line program to run the test, PowerCenter Client to connect to data sources and apply tests.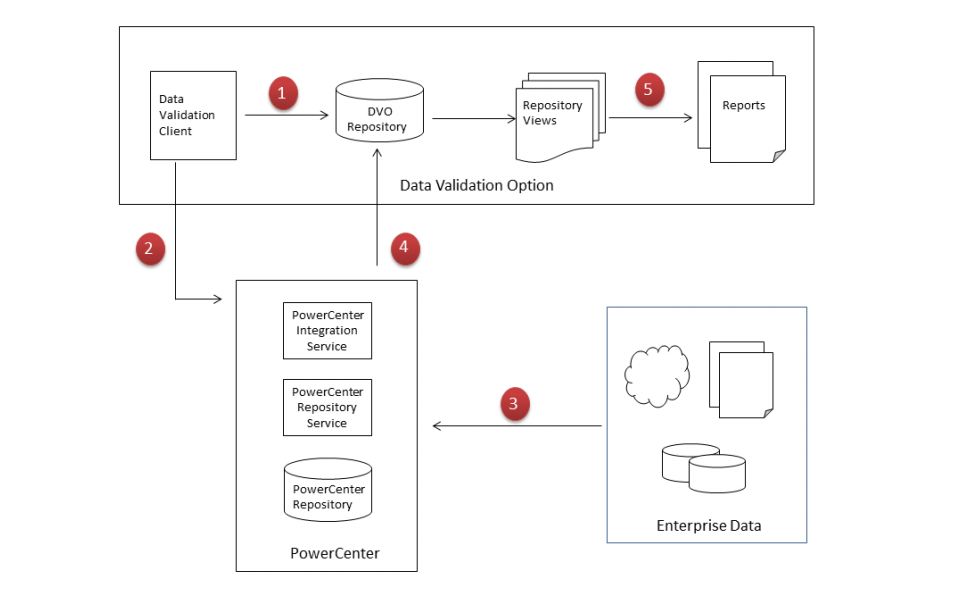
The ETL workflow and PowerCenter’s tools used at each stage
Talend Data Integration. Talend has an open source and a paid enterprise ETL development and testing tools. The free one - Open Studio for Data Integration - supports the Continuous Delivery methodology. The paid version adds teamwork features, ability to run tests on remote servers, and audit tools.
QuerySurge Data Warehouse Testing. QuerySurge is a solution created specifically for ETL testing so it covers most testing needs: data completeness and quality, data transformation, regression testing and so on. It has a trial version and two licensing options - subscription and ownership.
iCEDQ. iCEDQ is another dedicated tool that follows the DataOps pipeline. It has three editions - Standard for complex data validation, HT - a faster version, and Big Data that uses Apache Spark to validate high data volumes.

iCEDQ features demo
Datagaps ETL Validator. This standard data validation tool by Datagaps has a visual test case build with drag and drop features that replace manual query typing. Metadata testing, end-to-end testing, and regular data quality testing are all supported here. They also have a separate tool Test Data Manager to support test data generation - both by creating a synthetic one and by masking your sensitive production data.
Final tips and best practices
Do business test cases. Don’t just check whether your process works. Make sure that it’s compliant with business requirements - each company has specific mapping instructions and data integration needs. If the ETL process doesn’t fulfill the business goal, then what’s the point?
Thoroughly clean source data. This step is unfortunately often done at execution time when the testing uncovers all the issues. We recommend finding errors from the start to save you from spending precious time dealing with processing bugs. Here we have a whole article about data preparation if you want to check it out.
Test for speed. BI operators need constant access to relevant data, so make sure the ETL process not only keeps data complete but also doesn’t take too much time.
Automate. Some automation is better than no automation at all. If investing in a tool is not an option, build some automation functionality yourself: Script scheduling and data comparison can be designed using Microsoft’s SQL Server Integration Services that you’re already using. That would, of course, mean that you need to fiddle with scripts a bit more.