When speaking of machine learning, we typically discuss data preparation or model building. Much less often the technology is mentioned in terms of deployment.
Living in the shadow, this stage, according to a recent study, eats up 25 percent of data scientists' time. In other words, they dedicate a quarter of their efforts to infrastructure — instead of doing what they can do best.
The same survey shows that putting a model from a research environment into production — where it eventually starts adding business value — takes from 8 to 90 days on average. What's worse, up to 75 percent of ML projects never go beyond the experimental phase.
As a logical reaction to this problem, a new trend — MLOps — has emerged. This article
outlines the main concepts and potential benefits of MLOps,
explains how it differs from other popular Ops frameworks,
acts as a guide through key MLOps phases, and
introduces available tools and platforms to automate MLOps steps.
Finally, we’ll consider three levels of MLOps adoption, but let’s not get ahead of the story! So…
What is MLOps and how does it drive business success?
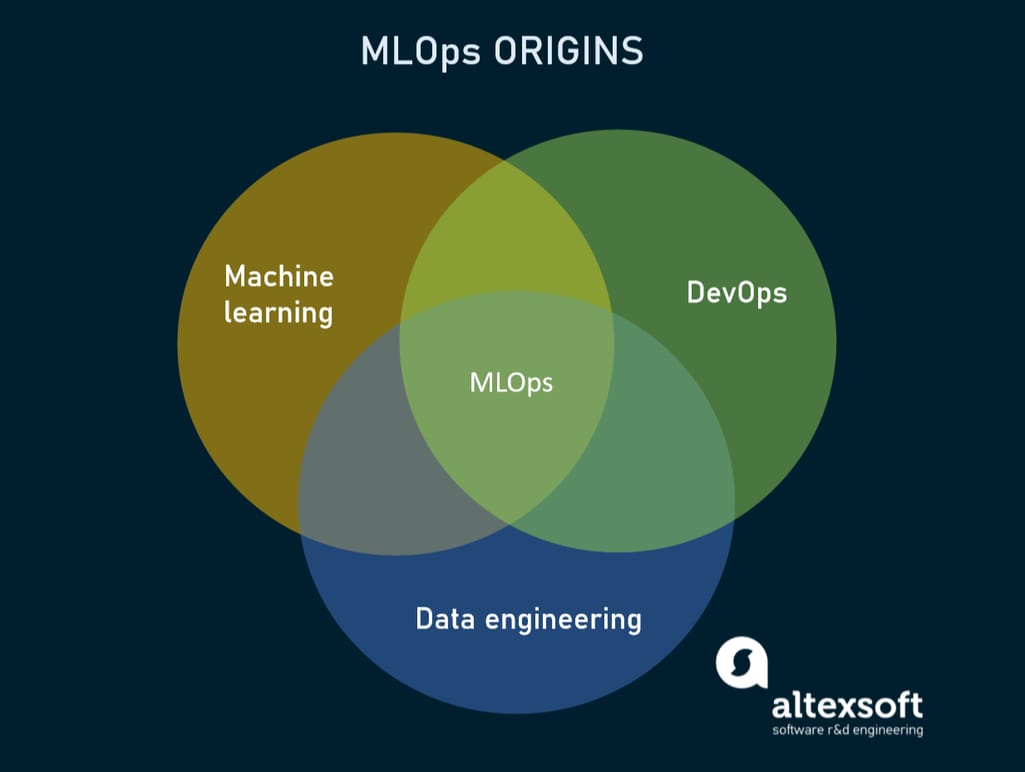
The fusion of terms “machine learning” and “operations,” MLOps is a set of methods used to automate the lifecycle of machine learning algorithms in production — from initial model training to deployment to retraining against new data. It facilitates collaboration between a data science team and IT professionals, and thus combines skills, techniques, and tools used in data engineering, machine learning, and DevOps — a predecessor of MLOps in the world of software development.
MLOps lies at the confluence of ML, data engineering, and DevOps.
Adoption of MLOps promises organizations the following benefits.
More time for development of new models. “Until now, machine learning engineers or data scientists have been deploying models in production by themselves,” — Alexander Konduforov, data science competence leader at AltexSoft, comments. “With MLOps, a production environment is the area of responsibility for operations professionals, while data scientists can focus on their core tasks.”
Shorter time to market of ML models. MLOps brings automation to model training and retraining processes. It also establishes continuous integration and continuous delivery (СI/CD) practices for deploying and updating machine learning pipelines. As a result, ML-based solutions get into production faster.
Better user experience. Due to MLOps practices like continuous training and model monitoring, your AI-fueled app gets timely updates, improving customer satisfaction.
Higher quality of predictions. MLOps takes care of data and model validation, evaluation of its performance in production, and retraining against fresh datasets. All these eliminate risks of false insights and ensure that you can trust results produced by your algorithm when making important decisions.
MLOps and other Ops: what is the difference?
The very nature of machine learning shapes the specificity of MLOps that differentiates it from closely related “Ops” practices like DevOps, DataOps, and AIOps. Below, we’ll explore the core distinction between them to avoid confusion and better grab the essence of each approach.
MLOps vs DevOps
MLOps is frequently referred to as DevOps for machine learning, and this is kind of hard to argue with. MLOps inherits a lot of principles from DevOps. To learn more, watch our recent video explaining DevOps.
How DevOps bring together development and operations specialists.
In spite of the similarity, we can’t just take DevOps tools and apply them to operationalize ML models. And here are the main reasons why.
1. Besides code versioning, you need a place to save data and model versions. Machine learning involves a lot of experimenting. Data scientists train models with various datasets, which leads to different outputs. So, in addition to code version control utilized in DevOps, MLOps requires specific instruments for saving data and model versions to be reused and retrained.
2. Unlike code, models degrade over time, which requires monitoring . After a trained model reaches production, it starts generating predictions from real data. In a stable environment, its accuracy wouldn't ever decline. But, alas, “Life changes and so does live data our model takes in,” — Alexander Konduforov acknowledges. “This results in so-called model degradation — in other words, its predictive performance decreases over time. To prevent errors, we need continuous model monitoring which is not typical for DevOps practices.”
3. Training never ends. Once the drop in performance is spotted, the model must be retrained with the fresh data and validated before rolling out into production again. Thus, in MLOps, continuous training and validation replace continuous testing, performed in DevOps.
MLOps vs DataOps
DataOps or Data Operations came into play almost simultaneously with MLOps, and also borrowed a lot of patterns from DevOps. But its core sphere of application is data analytics.
DataOps covers all steps of the data lifecycle, from collection to analyzing and reporting, and automates them where possible. It aims at improving the quality and reliability of data while minimizing the time needed to deliver an analytics solution.
The approach is especially helpful for organizations that work with large datasets and complex data pipelines. DataOps may facilitate ML projects as well — but only to a certain extent as it doesn’t provide solutions to manage a model lifecycle. So MLOps can be thought of as an extension of DataOps.
MLOps vs AIOps
The youngest of all the above-mentioned Ops, AIOps is often used interchangeably with MLOps, which is, put simply, quite incorrect. According to Gartner, who coined the term in 2017, AIOps — or Artificial Intelligence for IT Operations — “combines big data and machine learning to automate IT operations processes.”
In essence, the goal of AIOps is to automatically spot issues in day-to-day IT operations and proactively react to them using AI. Gartner expects that by 2023 up to 30 percent of large enterprises will adopt AIOps tools to monitor their IT systems.
And now, it’s time to get back to our core theme and explore the entire MLOps cycle in more detail.
MLOps concepts and workflow
The end-to-end MLOps workflow is directed by continuous integration, delivery, and training methodologies that complement each other and shorten the way of AI solutions to customers.
Continuous integration and continuous delivery (CI/CD). MLOps lives within a CI/CD framework advocated by DevOps as a proven way to roll out quality code updates at frequent intervals. However, machine learning expands the integration stage with data and model validation, while delivery addresses complexities of machine learning deployments. Totally, CI/CD brings together data, model, and code components to release and refresh a predictive service.
Continuous training (CT). A concept unique for MLOps, CT is all about the automation of model retraining. It embraces all steps of model lifecycle from data ingestion to tracking its performance in production. CT ensures that your algorithm will be updated at the first signs of decay or changes in the environment.
To better understand how continuous integration, delivery, and training translate into practice and how duties are shared between ML and operations specialists, let’s study key components of MLOps. This includes:
model training pipeline,
model registry,
model serving (deployment),
model monitoring, and
CI/CD orchestration.
Key components of an MLOps cycle.
Of course, steps and the entire workflow may vary in different cases — depending on the project, company size, business tasks, machine learning complexity, and other factors. So, here we’ll describe the most common scenario and suggest available tools to automate repetitive ML tasks.
Model training pipeline
Tools to build end-to-end model training pipelines:TFX (TensorFlow Extended), MLflow, Pachyderm, Kubeflow
Who does what at this stage:
ML specialists create training pipeline, engineer new features, monitor training process, fix problems.
Ops specialists test components of the pipeline and deploy them into a target environment.
A model training pipeline is a key component of the continuous training process and the entire MLOps workflow. It performs frequent model training and retraining while data scientists can focus on developing new models for other business problems — rather than on fine-tuning existing ones.
A graph of a Kubeflow pipeline. Source: Google Cloud
Depending on the a use case, a training cycle can be restarted:
manually,
on schedule (daily, weekly. monthly),
once the new data is available,
once significant differences between training datasets and live data are spotted, or
once model performance drops below the baselines.
Each time the pipeline performs the following sequence of steps.
Data ingestion. Any ML pipeline starts with data ingestion — in other words, acquiring new data from external repositories or feature stores, where data is saved as reusable “features”, designed for specific business cases. This step splits data into separate training and validation sets or combines different data streams into one, all-inclusive dataset.
Data validation. The goal of this step is to make sure that the ingested data meets all requirements. If anomalies are spotted, the pipeline can be automatically stopped until data engineers fix the problem. It also informs if your data changes over time, highlighting differences between training sets and live data your model uses in production.
Data preparation. Here, raw data is cleansed and gets the right quality and format so your model can consume it. At this step data scientists may intervene to combine raw data with domain knowledge and build new features, using capabilities of DataRobot, Featuretools, or other solutions for feature engineering.
Model training. At last, we come to the core of the entire pipeline. In the simplest scenario, the model is trained against freshly ingested and processed data or features. But you can launch several training runs in parallel or in sequence to identify the best parameters for a production model as well.
Model validation. This when we test the final model performance across the dataset it has never seen before to confirm its readiness for deployment.
Data versioning. Data versioning is the practice of saving data artefacts similar to code versions in software development. The popular way to do it is to use DVC, a lightweight CLI tool on top of GIT, though you can find similar functionality in more complex solutions like MLflow or Pachyderm.
DVC allows data scientists to save experiments and later reuse them.
Why is this practice so important for the entire MLOps lifecycle? In the course of training, model outputs differ significantly depending on the training dataset and parameters you choose. Versioning tools store configurations used in a particular training run, which means you can reproduce the experiment with the same results wherever necessary. This helps you easily switch between datasets and models to look for the best combination.
Who does what at this stage: ML specialists may share models and collaborate with Ops specialists to improve model management.
When the right candidate for production is found, it is pushed to a model registry — a centralized hub capturing all metadata for published models like
identifier,
name,
version,
the date this version was added,
the remote path to the serialized model,
the model’s stage of deployment (development, production, archived, etc.),
information on datasets used for training,
runtime metrics,
governance data for auditing goals in highly regulated industries (like healthcare or finance), and
other additional metadata depending on the requirements of your system and business.
The registry acts as a communication layer between research and production environments, providing a deployed model with the information it needs in runtime. It also enables tracking changes and shadow mode testing, which we’ll talk about a bit later.
Who does what at this stage: Ops specialists control model deployment, while ML specialists may initiate testing in production.
There are three main ways to launch models in production:
on an IoT edge device,
embedded in consumer application, and
within a dedicated web service available via REST API or remote procedure call (RPC).
The latest approach called Model-as-a-Service is currently the most popular of all as it simplifies deployment, separating the machine learning part from software code. This means you can update a model version without redeployment of the application. Besides, in this case, the predictive service can be accessed by multiple consumer apps.
Tools like Kubeflow, TFX, or MLflow automatically package models as Docker images to be deployed on Kubernetes or special model servers like TensorFlow Serving and Clipper. What's more, you can roll out more than one model for the same service to perform testing in production.
Shadow mode testing. Also called “dark launch” by Google, this method runs production traffic and live data through a fresh model version. Its results are not returned to end users, but only captured for further analysis. Meanwhile, the old version continues to produce predictions for customers.
Testing competing models. This technique involves simultaneous deployment of multiple models with similar outputs to find out which is better. The method is similar to A/B testing except that you can compare more than two models. This testing pattern brings additional complexity, as you must split the traffic between models and gather enough data for the final choice.
Who does what at this stage: ML specialists analyze metrics and capture system alerts.
Upon release to production, the model performance may be affected by numerous factors, from an initial mismatch in research and live data to changes in consumer behavior.
At some point, when the accuracy becomes unacceptable, the algorithm must be retrained. But it’s not easy to detect when exactly the so-called model drift happens. Usually, machine learning models don’t demonstrate mistakes immediately, but their predictions do affect the end results. Inaccurate insights can lead to bad business decisions and, consequently, financial losses. To avoid such troubles, companies should employ software solutions to automatically detect anomalies, make early alerts, and trigger machine learning pipelines for retraining.
Who does what at this stage: operations specialists unify multiple processes and automate the entire release process.
With all components of MLOps flow in place, we need to orchestrate numerous activities like execution of a training pipeline, running tests and validations, and deployments of new model versions. For this purpose, employ CI/CD tools thay can visualize complex workflows and manage the application lifecycle. This allows you to tie together pipelines in a relatively simple manner. It’s worth noting that many MLOps solutions easily integrate with mainstream CI/CD tools as well as with Git.
An ML pipeline is combined with an application deployment pipeline in GoCD. Source: MartinFowler.com
End-to-end MLOps with Google, Amazon, and Microsoft
Unlike DevOps, MLOps is still in its infancy and lacks mature solutions. It means that in most cases the framework employs a mosaic of tools and requires frequent human interventions.
However, the approach is quickly evolving, as it gets promoted by Facebook, Amazon, Microsoft, Netflix, Google, and other tech giants that roll out myriads of models on a daily basis. Some of these MLOps evangelists offer to build and manage end-to-end ML lifecycle on top of their platforms, using their infrastructure and services.
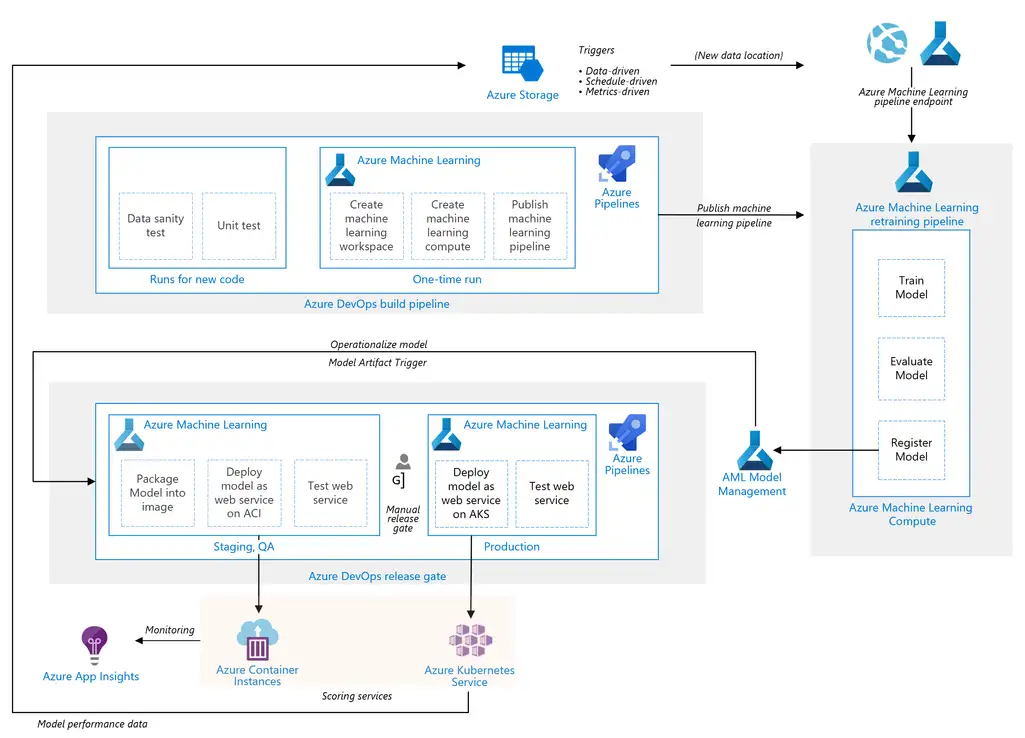
Microsoft Azure grants the opportunity to launch an MLOps using
MLOps on AWS can be achieved via Amazon SageMaker, a suite of tools to build, train, deploy, and monitor machine learning models.
When do you really need MLOps?
If this question comes to your mind, bridging a gap between model building and deployment is probably long overdue. However, it doesn’t mean you have to heavily invest in stitching all steps together and automating every task. Google describes three levels of MLOps, and the choice between them depends on the organization size and the number of machine learning algorithms they need to run.
MLOps level 0 suggests that the company uses machine learning and even has in-house data scientists capable of building and deploying models. But ML workflow is entirely manual. This level may suffice “non-tech companies like banks or insurance agencies,who upgrade their models, say, once a year or when another financial crisis occurs,”— Alexander Konduforov clarifies.
MLOps level 1 introduces a pipeline for continuous training. Data and models are automatically validated, and retraining is triggered each time when the model performance degrades or fresh data is in place. This scenario may be helpful for solutions that operate in a constantly changing environment and need to proactively address shifts in customer behavior, price rates, and other indicators.
MLOps level 2 comes in when a CI/CD pipeline automates deployment of ML models and components of ML training pipelines in production. This level suits tech-driven companies who have to retrain their models daily if not hourly, update them in minutes and redeploy on thousands of servers simultaneously. Without end-to-end MLOps cycle, such organizations just won’t survive.