

In early 2018, Pedro Domingos, who’s a professor of computer science at the University of Washington, tweeted: Starting May 25, the European Union will require algorithms to explain their output, making deep learning illegal. He was referring to GDPR Article 15 that says:
The data subject shall have the right to obtain [...] confirmation as to whether or not personal data concerning him or her are being processed, and [...] access to the personal data [...] and [...] meaningful information about the logic involved.
And yet, here we are in 2020. Deep learning is doing absolutely fine, unlike society. The tweet sparked debate in the professional community and in the comment section, where some fellow data scientists tried to placate Domingos, while the others joined his sentiment.
Domingos referenced a common truth about complex machine learning models, where deep learning belongs. Since they are trained rather than directly programmed, you can hardly tell how exactly they arrive at decisions. We may evidently see great results, but there’s nobody you could ask why the decision was made. The same goes for bad results.
The clash between human and machine comprehension becomes even more pronounced in… mission-critical cases
It’s not that we can’t explain the design of these models. But rather it’s challenging to grasp all factors and causations that lead to individual decisions. Because that’s what makes ML great in the first place -- an ability to consider hundreds or thousands of factors in data. And that’s what actually makes ML trump traditional programming -- it can surpass humans by many times in devising intricate logic. People, on the other hand, crave simple explanations.
This black box nature of ML raises a lot of concerns, from the privacy and, for that matter, legal standpoint -- do we know how our personal data is processed? -- to safety -- can Tesla autopilot run over a pedestrian wearing camouflage? -- and to ethics -- how would a self-driving car solve the trolley problem?
In this article, we’ll talk about the interpretability of machine learning models. Why should we care about that? Where does science stand in solving the problem? And what can be done from a business standpoint?
What is the model interpretability?
A commonly cited definition says that interpretability is the degree to which an observer can understand the cause of a decision, suggested by Tim Miller. In other words, not only do we want to understand the what part of a decision, the prediction itself, but also the why, the reasoning and data that the model uses to arrive at this decision.
We usually discuss machine learning models in terms of justification -- is this model accurate enough when tried against the ground-truth data? The accuracy measure is a common benchmark defining the viability and ROI of an ML project. But justification and interpretability factors are inversely related. The more accurate and advanced the model is, the less interpretable it is, the more it looks like a black box.
As soon as ML became a household technology and developed enough, the problem of interpretability (or explainability, both used interchangeably) emerged.
Why model interpretability is important
As mentioned before, there are several main reasons why a data scientist and a stakeholder would care about the interpretability of the models they use.
Safety and domain-specific regulations
Traditionally, interpretability is a requirement in applications where wrong decisions may lead to physical or financial harm. First of all, these are healthcare applications and devices. Interpretability has long been considered a major blocker to the wide adoption of deep learning models for medical diagnosis and other advanced ML systems in healthcare.
Here’s a telltale case. It was described by a team of researchers working with Columbia University to predict the probability of death from pneumonia. As scientists were exploring different approaches, they found a counterintuitive rule learned by one of the models from patient care data. It claimed that having asthma was a factor that lowered the risk of death for patients, instead of increasing it! Turns out, patients with asthma who got pneumonia were usually admitted directly to ICU (intensive care unit), receiving so much medical attention that it actually lowered the risk of death for them compared to regular patients with pneumonia. So, the model considered asthma a powerful predictor of better survivability. That’s what the data said.
If it weren’t for the interpretable model that they used, this association rule may have never become noticed with a more black-boxy model.
Regulations in healthcare aren’t all-encompassing yet, but some already consider interpretability a pass to approval. For instance, the current draft guidance by the FDA for Clinical Decision Support Software says: In order to describe the basis for a recommendation [...] the software developer should describe the underlying data used to develop the algorithm and should include plain language descriptions of the logic or rationale used by an algorithm to render a recommendation. The sources supporting the recommendation or the sources underlying the basis for the recommendation should be identified and available to the intended user [...] and understandable by the intended user (e.g., data points whose meaning is well understood by the intended user).
Regulators in finance remain unchanged and may reject complex AI systems for the lack of interpretability. But the financial world is actively looking for solutions. Capital One back in 2017 assembled a research team that would address the problem and, currently, they are still experimenting with different approaches.
All in all, safety and regulation limits remain among the main reasons product managers and data scientists should refresh their memory about the regulations in their industry. They have to make sure that their deep learning state-of-the-art model isn’t subject to legal barriers. If it is, this may be a case to consider existing interpretability options.
GDPR -- the Right to Explanation
As for GDPR regulations and the somewhat famous right to explanation stated in Article 15, the discussion is ongoing: Which technical approaches should we choose? Is it even possible to meet the requirement? It’s definitely a thing to care about.
A recent article by Maja Brkan, Associate Professor of EU law, and Gregory Bonnet, Associate Professor of Artificial Intelligence, explores the feasibility of the right to explanation both from a legal and technical standpoint. In this joint cross-disciplinary effort, they tried to match the existing approaches to model interpretability with GDPR explanation requirements.
The bad news is, yes, you should care about GDPR when rolling out a model that processes personal data. The good news is, it’s relatively feasible to meet the requirement and deep learning is far from being prohibited. We’ll talk about the existing approaches in a minute.
More good news is that GDPR doesn’t require the providing of explanations for all decision-making cases, only for those with legal or significant effects. For instance, this means that a person can’t require an explanation as to why they were shown a targeted advert. But they definitely can do so if you refuse to make a loan based on your algorithmic decision.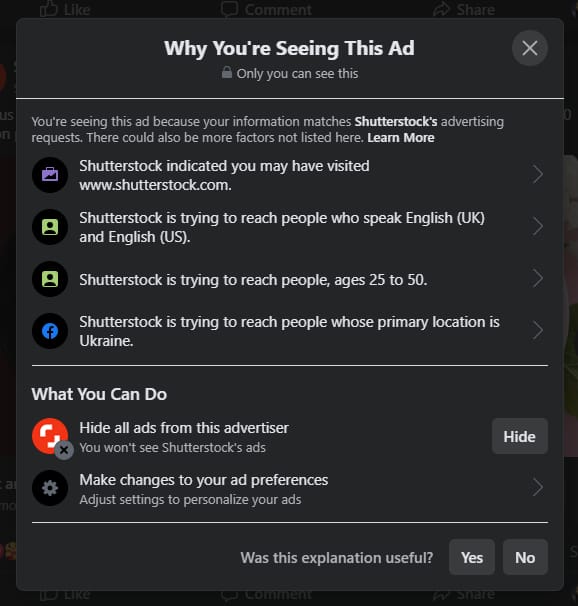
From the GDPR standpoint, Facebook doesn’t necessarily have to give this explanation
And, finally, GDPR only considers personal data. If your model makes decisions, even with legal or significant effects, but you don’t employ any personal data -- say, you’re building a self-driving car -- GDPR doesn't control.
Avoiding bias and discrimination
Bias is a very human thing. It’s embedded in our behavior and gets captured in our digital footprint, in data itself. And models that learn from data can easily contract human flaws. Theoretically bias can be avoided at dataset preparation stage. In practice, it’s not that easy.


Dataset preparation, well... explained
There are numerous -- albeit partially unconfirmed -- reports of discrimantion againts black people in EHR, educational, and criminal justice software. A team of researchers from Berkeley, who were examining patient records from one of large hospitals found that patients who identified themselves as black received generally lower risk scores than white people with equally dangerous health conditions.
So, you should have clear understanding which data points act as powerful predictors to catch bias inherited from humans. Consider this recommendation if your data models have social impacts and are based on human-generated data.
Social acceptance and insights
Interpretability shouldn’t be considered a restrictive matter only. It’s also an enabling one. There’s no grave need for “frequently bought together” on Amazon or “because you watched” on Netflix.
The streaming platform gives seemingly unnecessary explanations
But even in scenarios when a machine learning algorithm makes non-critical decisions, humans look for answers. Tim Miller, in his paper Explanation in Artificial Intelligence: Insights from the Social Sciences, analyzes AI interpretability from the human vantage point. He summarizes prior research to give key reasons why people ask for explanations:
- People strive for control and predictability, they try to find meaning in events and reconcile inconsistent or contradictory information.
- Explanations themselves may be more valuable than mere information that they reveal because we have this learning intention hardwired in our brains.
- Explanations help create a shared meaning of events and facilitate human-AI interactions. You’re more likely to reject a movie recommendation if you know neither the recommended movie, nor the fact that AI thinks that this movie is similar to what you already like.
So, it all boils down to the trust factor. If you have a customer-facing AI and want your customers to trust you, think of interpretability.
It may seem that internal analytics don’t need interpretability that much. But this isn’t true either. As a business, you may be equally interested in predicting customer churn to take actions and the inner reasons your clients decide to churn in the first place. Interpreting true predictions of a model may become a separate analytics branch in an organization.
Debugging a model
Finally, as any software, models need debugging. They can focus on the wrong features, show a great result on testing data, but reveal egregious flaws in production.
A popular anecdote is told about the US military. The researchers trained a neural net to recognize camouflaged tanks in a forest. They had a dataset of images that combined takes both with tanks and with an empty forest. According to internal testing, the model performed great, accurately distinguishing between images with and without tanks. After handing the model to the Pentagon, they soon received it back. The Pentagon officials said the accuracy was no higher than that of a coin flip. After some investigation, the researchers realized that in their dataset all images with tanks were taken on cloudy weather, while the images of the forest without tanks were shot on sunny days. So, the model learned to distinguish between cloudy and sunny days.
While this anecdote may be just that -- an anecdote, the story of asthma being the predictor of better survival is actually a documented case. But they both arrive at the same point -- as long as we don’t know which features are the real predictors, we can’t be sure the model is valid.
Of course, there’s always a way to stick with shallow and well-interpretable models. But academia and practitioners are actively exploring the ways to achieve interpretability.
Approaches to model interpretability
Let’s follow the taxonomy suggested by Christoph Molnar in his book Interpretable Machine Learning. By the way, it’s a great read both for those who are product managers or stakeholders and data scientists.
There are four major criteria to structure the approaches, the aspects to look through.
- By model
- By method
- By scope
- By results that you get.
We’ll talk briefly about the first three, but emphasize the results, because they’ll give you a better idea what explanations might look like.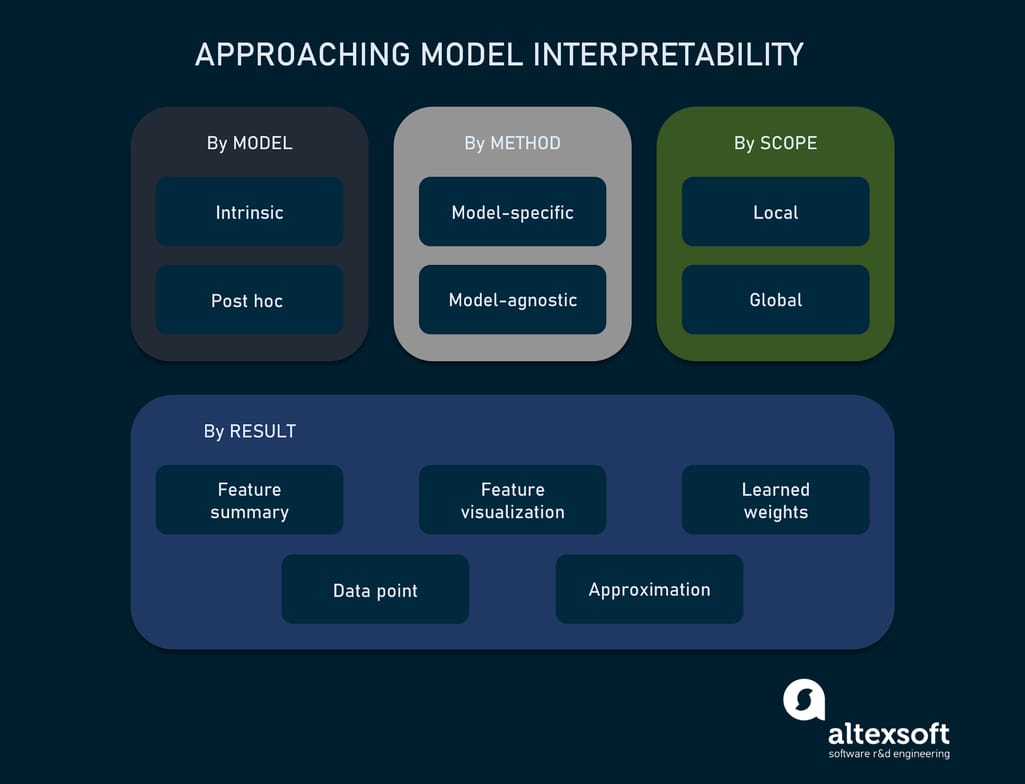
This taxonomy is in line with other sources who structure existing interpretability frameworks
By model: Intrinsic or Post hoc
A straightforward way to achieve interpretability is to use simpler models, those that can be easily understood by humans. This may be a viable option if simple and thus intrinsically interpretable models are enough. For instance, some decision trees may have a limited number of branches and split points to be comprehensible for people.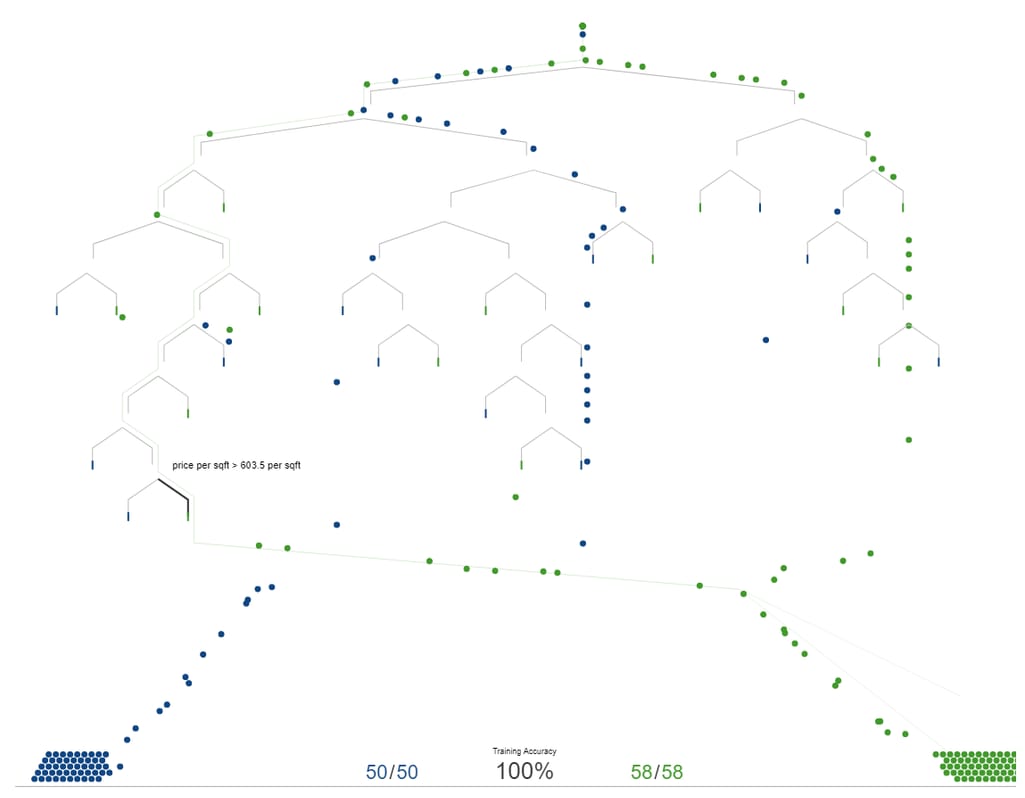
This is a visualized decision tree with a highlighted split point from Visual Introduction to Machine Learning. The model predicts whether the house is in New York (blue) or San Francisco (green). The split point shows that houses that made it to this very point and having price per square foot more than $603.50 are likely to be from San Francisco
But the more complex the model gets, the harder it is for humans to comprehend it, even in case of decision trees. There’s also a conflict between predictive and descriptive power of models. Usually, the more accurate the model is, the less amenable it is to interpretations.
On the other hand, post hoc interpretations happen after the model is trained and aren’t connected to its internal design. Most approaches to complex models are thus post hoc.
By method: Model-agnostic or Model-specific
This criteria is pretty much self-explanatory. There are methods that are applicable only to specific model types and those that don’t care which type of the model you have.
In these terms, all intrinsic methods are model-specific, while post hoc are model-agnostic as they don’t have access to model structure and weights.
By scope: Global or Local
Scope is a very important factor in defining interpretability logic. Global explanations try to capture the entire model. Local ones focus on individual predictions. Have a look at this image.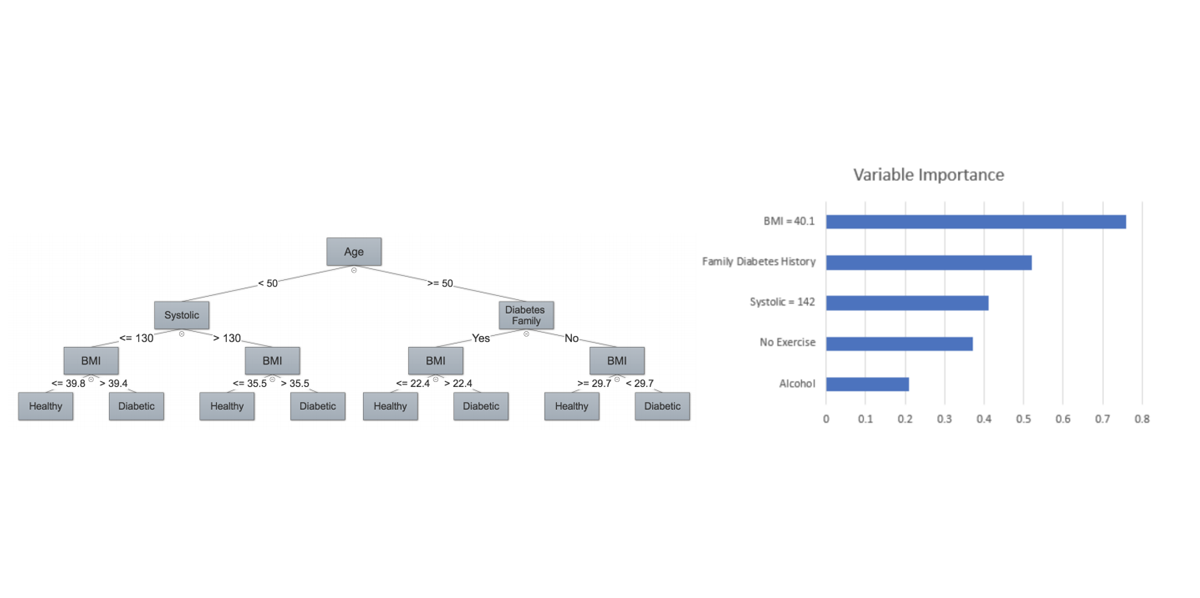
Global (left) vs local (right) explanations of predicting diabetes: Interpretable Machine Learning in Healthcare, IEEE Intelligent Informatics Bulletin
The global explanation shows a decision tree with annotated split points. It can be applied to the entire population. The local one shows the relative importance of each data variable of a given person. For instance, BMI (body mass index) that equals 40.1 has the highest importance in the prediction relative to other features.
When you’re deciding on the interpretability of your system, this criteria must be in the checklist. If a user exercises their right to explanation under GDPR, most likely you need the local approach without revealing the whole logic of the system. And, on the other hand, regulators approving, say, finance or healthcare systems may require global explanations of the models.
This choice can also tip towards local explanations if the model and its weights distribution are a trade secret that can’t be revealed to the public. This is the case of all recommender engines or advertising systems that suggest limited explanations like “because you watched.”
By result: how explanations can be presented
Let’s now have a look at what you may expect from results of different technical methods to interpretation.
Feature summary. This is the most bare-bones way to present how different features impact the result. You may get a single value per feature showing how important it is or get more complex summaries with strength of interactions between different features. A good example is the image above (showing diabetes predictions) with a local explanation of feature importance.
Feature visualization. Feature summaries may not work if you present the numbers only. Again, it’s a matter of human comprehension. This is the case when visualizations may be of use. Besides a couple of decision trees shown above, there are other ways to visualize features and their relationships. Among such examples are nomograms, visual representations of numerical relationships. Have a look at this one. It visualizes the probability of passenger survival on the HMS Titanic, learned by a naive Bayesian model.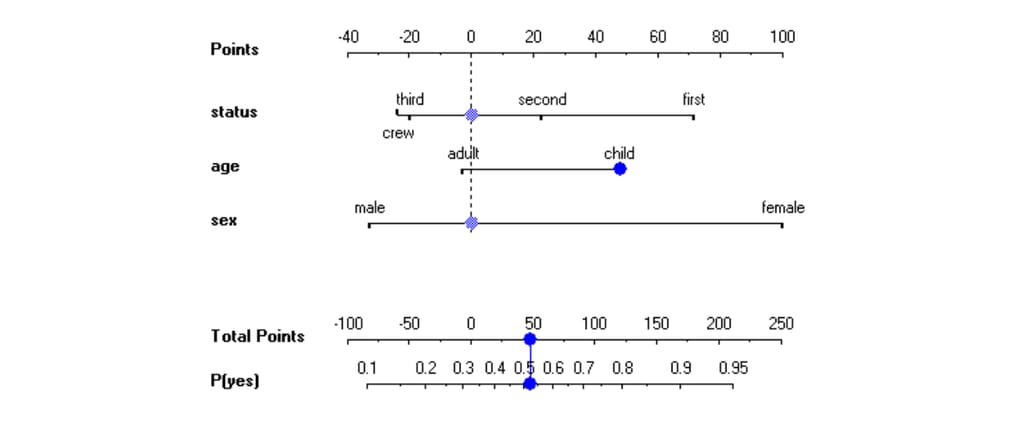
The nomogram is quite easy to read, as you assign points depending on a passenger's features and then match these points with survivability rate. This is the example of a global explanation, by the way. Source: Nomograms for Visualization of Naive Bayesian Classifier
Learned weights. Weights are parameters of a model that it learns to understand how much impact different inputs have on outputs. These parameters are internal to the model, so the approach is model-specific. It tries to understand how weights are distributed depending on input data. There are many variations of this approach. Here’s one of good examples of weight visualizations for MRI scans, where the model must decide whether a given voxel (3d pixel) in MRI is associated with a brain tissue or not.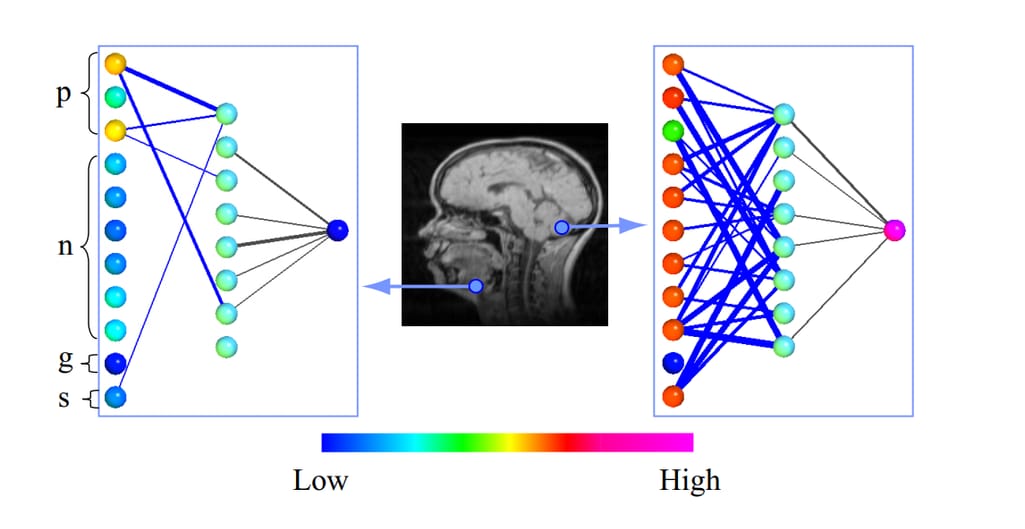
The color grading shows the probability of given voxels being associated with brain tissue. P, N,G,S are input features. The comparison between two images shows how the model reacts to two different inputs. It also allows researchers to see that the G feature has no effect on identifying the brain tissue. Source: Opening the Black Box - Data Driven Visualization of Neural Networks
Data point. This method entails evaluating how different data points impact the final result. For example, removal-based explanations may be used in text classification. One or several words are removed from the text and researchers can understand whether this leads to meaningful changes in prediction. This, for instance, helps in spam or content filtering classification. Another way is to use counterfactual explanations, e.g. changing an input class to see how the model reacts. The use cases of this method are rather limited because models working with tabular data and thousands of features are less susceptible to such interpretations.
Approximation. Approximating complex models with simpler and more interpretable ones is a popular way to approach the problem. While there are attempts to interpret the whole models, they usually aren’t that precise. On the other hand, approximations of individual predictions are proven to work. For instance, LIME (Local interpretable model-agnostic explanations) method can be used with texts and images, and a bit less so with tabular data. The idea is to isolate an individual prediction and train an interpretable model for this prediction by changing input values (e.g. turning selected pixels on and off) and capturing how these values impact the decision of a complex model. This way, an interpretable model can learn how the prediction in question works.
LIME for image classification. The model approximates the groups of pixels responsible for individual predictions. Source: “Why Should I Trust You?” Explaining the Predictions of Any Classifier
These approaches summarize what one would expect from explaining a black box model. But not all of them are easily accessible to lay people. In the final section, let’s talk about how people perceive a good explanation.
Making human-friendly explanations
Besides technical and legal challenges, interpretability may also be a struggle in terms of presenting information to people. Let’s get back to Tim Miller’s findings from social sciences. He defines four main characteristics of good explanations.
All why questions are contrastive. People always have some expectations of reality and think of events in relation to other events in the context. We don’t only ask why something happened per se. We ask why event C happened rather than event B. For example, an SEO expert inquires: Why do we have 10k in traffic on this landing page? To answer this question properly, you have to understand the context of the question. What did she mean to ask?
Why has the traffic increased to 10k instead of remaining at 8k? What did we do right?
or
Why has the traffic decreased from 12k to 10k? What went wrong?
These two scenarios have two completely different backgrounds and present different expectations from the explanation.
If you work on the explainability of your system, always consider the contrastive nature of why inquiries and try to understand the context of inquiry and the instead of part of the question.
Explanations are social and cooperative. The following from the contrastive argument is that explanations are a form of a cooperative conversation. One person helps another one fill in the gaps in understanding. This means that both explainer and explainee have the same presupposition to start from -- they both realize the context of the problem -- and they close the gap through communication. Miller argues that the dialog format of explanations is perhaps the most socially acceptable approach to interpretable AI. It considers the conversational nature of explanations, it allows people to ask for further elaboration, and is capable of adjusting explanations depending on the person asking. The dialog format is a technical challenge on its own. But another takeaway from this point is that you should always consider the audience you present explanations to. How well are they technically prepared? What’s their background?
Good explanations are selective. We tend to look at events in a rather simple manner and inflate the importance of some factors, while downplaying others. And we expect simplified explanations, believing that a couple of factors lead to an event, rather than thousands of factors that the model is capable of analyzing. The Netflix “because you watched” feature is a good example. The recommender algorithm that they use is perhaps one the most sophisticated pieces of software ever created. It considers many more factors and their combinations, besides a single movie you watched, to make a decision. But for the sake of convincing explanation, it works.
Probabilities aren’t convincing. This point is a logical successor to the previous one. While experts may rely on such metrics as model accuracy, the number of false negatives and false positives, people don’t think in probabilities. They look for clear cause explanations. Research shows that people are more satisfied with a single strong feature than model confidence.
Eventually, when working on interpretations of your system, you must consider both the underlying technology and people who these explanations are created for.

Oleksandr is a content strategist and editor. He leads (when possible) the team of independent-thinking writers and tech journalists at AltexSoft. With over 10 years of writing and editing tech-related pieces and scripts, he currently focuses on travel tech, data science, and AI. Outside of work, Oleksandr enjoys escapism in video games and game development.
Want to write an article for our blog? Read our requirements and guidelines to become a contributor.