

Do you have a smartwatch or a fitness tracker? Today, about one out of five Americans uses at least one wearable device, and a forecast by CCS Insight predicts almost 200 million units will be sold worldwide in 2021.
These devices are used to collect tons of various health and fitness-related data, such as daily activity, pulse, temperature, sleep patterns, and so on, all in real time. But what happens to the massive amounts of data from all these wearables and other medical and non-medical devices? Besides informing individual users of their activity level, how can it be used in healthcare?
In this article, we will explain the concept and usage of Big Data in the healthcare industry and talk about its sources, applications, and implementation challenges. Definitely, the topic is way too extensive to be covered in a blog post, so we’re only going to present a succinct overview.
What is Big Data and what are its sources in healthcare?
So, what is Big Data, and what actually makes it Big? Check our article dedicated to big data if you want a detailed explanation of this notion, but in short, this term relates to large amounts of data -- both structured and unstructured -- that are too voluminous or complex to be processed with traditional software tools. It’s typically characterized by 4 Vs:
- Volume -- referring to the huge sizes of datasets,
- Velocity -- meaning that data is constantly being generated in real time,
- Variety -- pointing out the broad range of sources and disparate formats that data comes in, and
- Veracity -- emphasizing the quality of data and the value it can bring.
Having described its main characteristics, it becomes clear that not all health information can be referred to as big data. Let’s see where it can come from.
Wearables and remote patient monitoring (RPM) devices include fitness trackers, smart watches, smart clothes, biosensors, blood pressure monitors, glucose trackers, and any other electronic devices that people can wear on their bodies. They are designed to collect various health information and commonly transfer this data to the user’s smartphone and/or a remote/cloud server where it can be retrieved by medical personnel.![]()
Fitbit activity dashboard
Smartphones and health apps also record some health and activity-related data, and besides, gather information entered manually by the user or transferred from connected devices. Then, they can also share it with the doctor. If used consistently, such apps can be a great help in tracking health conditions and diagnostic procedures.
Medical equipment and other Internet of Medical Things (IoMT) devices such as bedside monitors and under-the-mattress sensors stream billions of various measurements per day, providing a real-time picture of a patient’s condition and warnings of the slightest changes.
Omics data is heterogeneous information generated from genome, proteome, transcriptome, metabolome, and epigenome used to study complex biochemical and regulatory processes of humans and other organisms. It’s referred to as big data, since, for example, just a single complete human genome sequence produces about 200 Gb of raw data.
Other external and internal sources may include anything capable of generating data that can complement further analysis, i.e., social media, search engine data, a hospital’s operational information, insurance claims, clinical records, demographic data, environmental data, and so on.
Now, we know where big data in healthcare originates. But what happens next? How can it be stored and processed? Let’s take a quick look at the big data infrastructure.
Big Data infrastructure in healthcare
In general, a data infrastructure is a system of hardware and software tools used to collect, store, transfer, prepare, analyze, and visualize data. Check our article on data engineering to get a detailed understanding of the data pipeline and its components.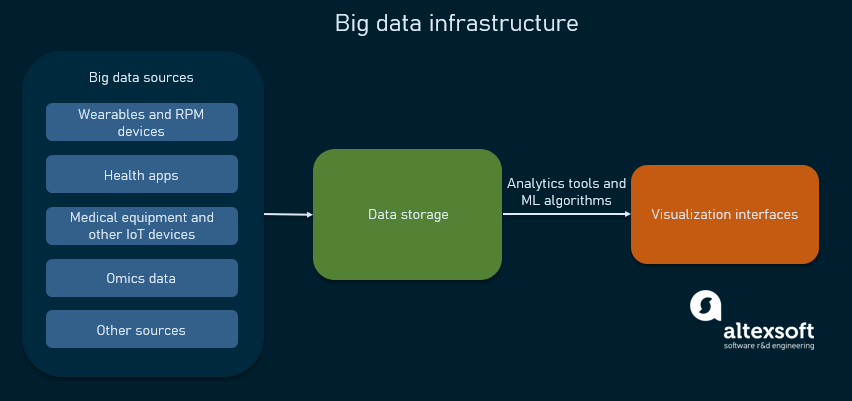
Big data infrastructure in a nutshell
To deliver valuable, applicable knowledge, data has to go through the following stages of a data pipeline.
- Big data sources continuously generate raw, real-world data. Special technologies called stream processors are needed to handle such data flows. We have an article on streaming analytics that comprehensively describes the entire process and necessary tools.
- Data storage is a physical or cloud repository of data and would most probably require a data warehouse and a data lake to handle massive amounts of data.
- Analytics tools apply various statistical and data mining techniques to classify and interpret data, as well as identify trends, patterns, and dependencies. As for big data, its processing requires the use of machine learning (ML) algorithms to generate predictions and determine probabilities of possible outcomes.
- Visualization interfaces give end-users access to data and results of analysis in a convenient visual form of dashboards and reports.
Having gone through the basics, we finally get to the pivotal question -- why bother at all? How can all this big data be used and what are its real-life applications and benefits?
In an intensely multi-faceted industry like healthcare, data and analytics can be beneficial in many different ways. We have touched on the topic before, in our previous articles on analytics in healthcare, how data science impacts healthcare, and deep learning in medical diagnosis. Here, we’ll discuss some areas where big data can be a game-changer.
Big Data for real-time monitoring and diagnostic support
The most obvious benefit of big data usage is its assistance with monitoring the patients’ conditions with the help of medical equipment and IoT. Traditionally, we rely on a snapshot of information received during a doctor’s visit or a planned check-up. Now, we can monitor health continuously and in real time. Also, alerts of possible changes can be set up, allowing for early intervention and treatment. In this case, the patient gets timely care and might avoid visiting the doctor or hospitalization which reduces healthcare expenses.
Besides, data obtained continuously from IoT devices and mobile health apps is a major support for remote patient monitoring and telemedicine in general. It allows medical personnel to obtain the necessary health information for further risk assessment and treatment prescription.
As for choosing the optimal treatment course, we have discussed decision support systems before and explained how the nonknowledge-based systems use ML models to help doctors find the optimal course of action. However, they are still rare, considering multiple implementation challenges, giving way to simpler, rule-based systems that use historic non-streaming data.
Let’s discuss some examples of using big data to monitor health in the real world.
Apple Watch ECG to detect A-Fib
Apple launched the ECG app that allows consumers to take an electrocardiogram (ECG) anytime using the electrical heart sensor on Apple Watch Series 4, Series 5, or Series 6 to record heartbeat rate and rhythm. By analyzing heart signals with the help of an ML algorithm, the ECG app can help detect an anomaly called atrial fibrillation (A-Fib). It’s a form of arrhythmia, or irregular heartbeat, and is associated with an increased risk of heart failure, dementia, and stroke. In the case of A-Fib classification, a user gets a notification prompting them to consult a doctor.
The ECG app was created using a deep learning technology that is known as a convolutional neural network (CNN) that resembles the way the human brain works. This deep neural network was trained extensively on heart data from both healthy patients and those with A-Fib so that it’s capable of distinguishing between healthy and unhealthy patterns. After deploying this pre-trained network in the Apple Watch, over 400,000 users participated in a study validating the ability of the ECG app to accurately detect A-Fib.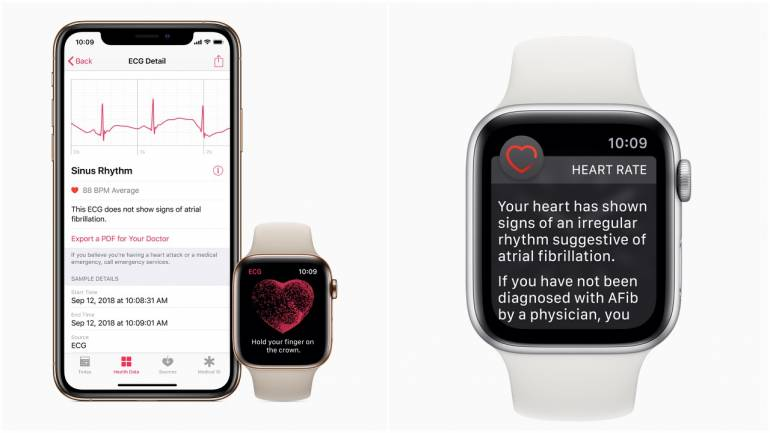
Apple Watch ECG feature
Predicting asthma or respiratory problems
The wearable Automated Device for Asthma Monitoring and Management, or ADAMM, developed by Health Care Originals, Inc., provides “Intelligent Asthma Management” by monitoring respiratory signals. It’s a small wireless device that the patient can wear unnoticed on his or her body that has sensors detecting such important symptoms as respiratory rate, cough patterns, heartbeat, temperature, etc. Measurements are then sent via Bluetooth to the connected smartphone or via Wi-Fi to the cloud storage to be accessed by medical professionals.
Such continuous monitoring helps detect and notify users and their caregivers about any deviations, predicting asthma conditions before they occur. Or, in the case of in-hospital monitoring, decompensation can be immediately detected and addressed.
Other functions include medication reminders, voice journaling, and generating convenient reports.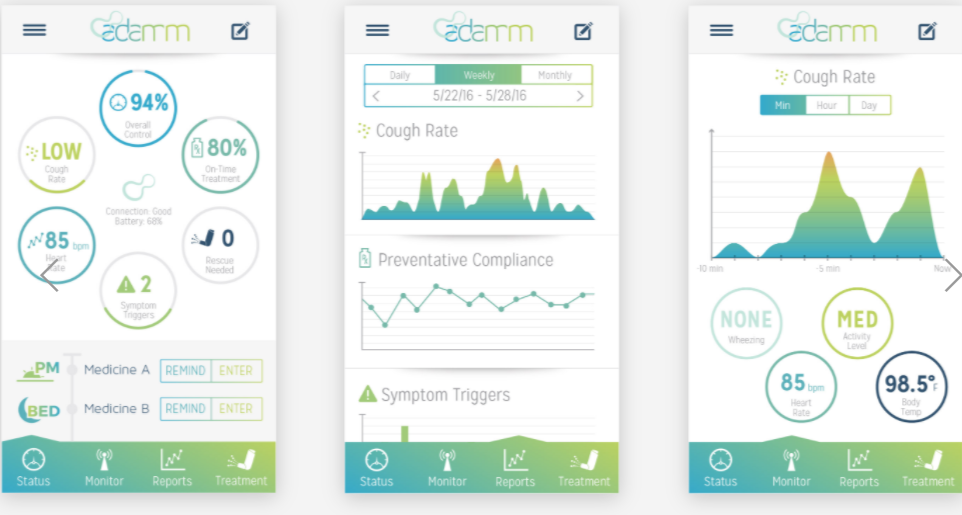
ADAMM dashboards
Monitoring babies in neonatal intensive care
A few years ago, the Irish Centre for Fetal and Neonatal Translational Research (INFANT) at University College Cork (UCC) announced its partnering with IBM to create a platform for “early and accurate detection of neurological problems” and enabling better long-term outcomes for at-risk babies.
IBM’s stream computing platform captures data received from the multiple sensors monitoring the babies such as electroencephalogram (EEG) recordings, heart rate, blood pressure, oxygenation, and brain activity. Then, this information is processed using ML algorithms, and the surveillance results are sent to the personnel monitor, alerting of any dangerous conditions.
Such continuous tracking of vital physiological signals can help with timely detection of seizures and other conditions that require immediate intervention and treatment.
Big Data in epidemiology
Big data creates many potential opportunities for epidemiology. As more sources of various data become available for analysis, surveillance and forecasting of disease outbreaks become possible, leading to faster, more effective response and improved public health. Let’s take a look at some examples.
Social media and mobile data for epidemics forecasting
In 2008, Google Flu Trends was established in an attempt to predict flu outbreaks by analyzing users’ queries in search engines. Researchers created a model using millions of search queries and historic flu data. However, time proved the resulting predictions to be very inaccurate so the project was terminated in 2015.
In spite of its failure, the project inspired other attempts to predict flu with the help of social media data. For example, a team from Osnabrück University used IBM Bluemix and Watson cognitive services to analyze millions of tweets to create a model capable of successfully predicting outbreaks.
Other researchers also used Twitter posts to estimate and forecast the spread of Dengue as well as complement traditional surveillance methods to track and predict Zika virus spread.
Lately, mobile phone data presents a source of information that allows for tracking population movements and predicting where various disease outbreaks are likely to occur. People traveling around the country contact others and transmit infection. Monitoring such relocations helps understand areas of higher risk and permits preventative actions and improved response.
Multiple studies aimed at managing the spread of pathogens have been conducted using anonymized mobile operators’ data, i.e., attempting to predict the spread of malaria in Senegal, cholera in Haiti, malaria in Bangladesh, and so on.
UNICEF’s projects to detect epidemic crises
The Ebola crisis of 2014 showed that the world is not prepared for emergencies. The United Nations’ Magic Box is one of the projects that was created at that time to support future responses to such situations.
It’s an open-source platform that collects real-time data from multiple sources (a lot of it provided by private sector partners) that include “high-resolution population estimates, air travel from Amadeus, regional mobility estimated using aggregated anonymized mobile phone records and geotagged social media traces, temperature data from IBM, and case data from WHO reports, such as Zika, Dengue, and Ebola.”
This information serves as an input for models that create epidemiological forecasts about the possible spatiotemporal spread of infections, especially in the remote areas with the most vulnerable populations.
Monitoring and resisting COVID-19
Fast forward to the COVID-19 pandemic that developed at breakneck speed and demanded a prompt response from all nations. Some managed to make use of data and effectively resist the outbreak. A bright example is South Korea. It was able to flatten the curve of virus spread shortly after it was first detected, all due to immediate, data-based actions. These included:
- smart contact tracing with the help of GPS data, street cameras, credit card transactions, etc.;
- express testing and remote monitoring, collecting data from IoT and wearable devices and allowing doctors to identify people needing medical attention;
- mobile AI-based apps that provide details of the infected person’s activities and travel details for all people in the vicinity;
- increased awareness and prompt medical services in the areas defined by analytical technologies as possible virus clusters or those prone to risk, and so on.
On a much smaller scale, here’s how analyzing real-time patients’ data helped Albany Med get a better picture of the situation, accelerate decisions, and improve response to the virus spread. They developed dashboards for monitoring all COVID-19-related activity which allowed clinicians to track all patients with confirmed cases and conduct contact tracing. Besides, they used person-matching algorithms to keep the workforce safe and ensure timely symptoms assessment.
Big Data in research
As we already mentioned, tapping into data generated by popular fitness trackers provides numerous research opportunities. To support research initiatives, Apple introduced its ResearchKit, a framework for building apps, enrolling participants, and conducting medical studies.
We already described the Apple Heart Study conducted to find out more about A-Fib conditions by obtaining heart information from smart watches. Similarly, the ASSIST Study encourages people to share health data from their wearable devices to learn about Alzheimer’s disease, and DETECT Study uses wearable sensor data in an attempt to detect early COVID-19 symptoms.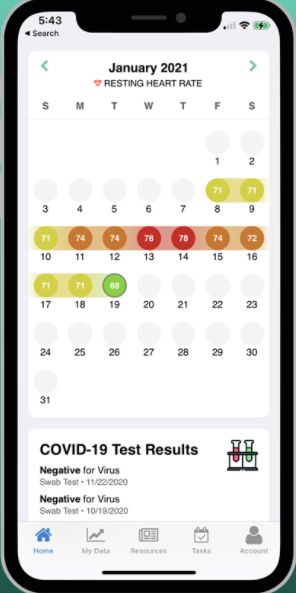
MyDataHelps App Calendar used for DETECT Study data collection
Multiomics data in research
Genomics, being the basis for precision medicine and drug discovery, offers more accurate, personalized treatments, but requires significant computing powers. Just looking at the genome information is not enough. Here, a multidimensional, or multi-omics approach is necessary, comparing genome with data from other sources -- in amounts too big to be processed without data science methods. That is why, even though technically genomics doesn’t operate big data, its volumes and related technological challenges allow us to put it in the same category and mention it in this article.
The World Health Organization initiative on Human Genomics in Global Health unites numerous organizations around the world in genomics research and information-sharing. Such companies as BGI and Genomics England conduct large-scale studies to discover reasons behind diseases, identify individual responses to various agents, and get a better understanding of our bodies.
As a result, today newborn babies are tested for phenylketonuria, or PKU, which is an inherited genetic disorder resulting in intellectual disabilities or other problems caused by the inability to convert excess phenylalanine. If discovered early, it can be managed easily. Genetic tests are also performed to detect potentially fatal cystic fibrosis that affects the lungs and digestive system.
In total, over 6,000 genetic disorders are known today, and new ones are being added constantly. As genome and DNA sequencing technology advances and becomes more cost-effective, genetic tests can detect more heredity deviations (even at the prenatal stage) to be addressed early.
Diabetes prediction
The DeepHeart project aims at using data from wearable devices to predict diabetes and other medical conditions. It’s a semi-supervised deep neural network that analyzes a patient’s wearable device measurements and can accurately detect cardiovascular conditions such as A-Fib, which we mentioned before, as well as hypertension and sleep apnea. It’s also suggested that diabetes may impact heart rate variability, but the accuracy of obtained predictions is unreliable, so more research is needed.
Cancer studies
Cancer being one of the leading causes of death worldwide and one of the most serious modern clinical challenges is obviously the focus of numerous studies. Hundreds of organizations explore different aspects of the problem in an effort to find a workable solution for earlier diagnosis and improved treatments. Today, data coming from oncogenomics provides new opportunities so its aggregation and sharing are vital for cancer studies.
The American Association for Cancer Research (AACR), the world's oldest and largest professional association for cancer research, launched Project GENIE (Genomics Evidence Neoplasia Information Exchange) as a registry of cancer genomic sequencing data. It’s freely accessible and can be used for research and drug development.
CancerLinQ is a platform that integrates real-time cancer-related data from over 100 clinics and 1 million patients around the U.S. to support treatment decisions and further studies. It’s a non-profit community that “collaborates with medical organizations, patient advocates, government agencies, health care companies, and others to share and constantly improve data, technology, and insights.”
The Cancer Genome Atlas Program of the National Cancer Institute works with massives of omics data to study 33 cancer types and improve their diagnosis and treatment. Here’s a list of computational tools used for analyzing and visualizing cancer genomics datasets. Applying ML techniques can help predict drug responses and support treatment decisions.
Another huge knowledge base is canSAR -- a multidisciplinary, free data resource that includes ML software to empower drug discovery and druggability assessment.
Big Data for operational efficiency and staffing
Besides the aforementioned health-related areas, big data can also help with non-industry-specific issues concerning any business (including hospitals). Historic and current workforce, administrative, and operational data in combination with external information such as social media and claims become data sources for predictive analytics, which helps hospitals and other healthcare organizations optimize their daily operations. Some of the possible applications are:
- demand planning,
- evaluating efficiency and preventive/predictive maintenance of hospital equipment,
- marketing activities,
- supply chain management,
- business decision support, and so on.
Scheduling and having the right amount of personnel is another operational challenge. Some patterns are quite obvious, such as higher admission numbers around public holidays. But incorporating and analyzing other data sources can give a more holistic view. Read on about some real world examples of big data operational usage.
Forecasting patient loads
Intel partnered with a large French hospital to create an analytic platform that is capable of predicting emergency department visits. They used such data as environmental conditions (weather, temperature), flu rates, demographic information, etc., complemented with historic datasets, current patient behavior, and staff efficiency to forecast patient loads and optimize staffing. That, in turn, helped them reduce costs and ensure timely care.
MRI device failure prediction
Hitachi's Healthcare Business within the Social Innovation Project analyzed historic sensor data to detect fault patterns and identify reasons behind failures of MRI equipment. Then, their exclusive technology, Hitachi's Global e-Service on TWX-21/ Predictive Maintenance Service, was used to monitor devices. This mechanism “diagnoses the system's status remotely and allows early detection of state changes and abnormalities that can lead to failure.” As a result, devices were repaired before failure occurred, reducing downtime by 16.3 percent.
Big Data implementation challenges and possible solutions
In spite of the many benefits big data has in store for the healthcare industry, its implementation is not as simple. Besides the obvious financial challenge that always accompanies innovation and digital transformation, there are a number of other constraints to overcome.
Technological challenges
Handling massive, escalating amounts of various continuously streaming data demands powerful computing technologies. The overwhelming sizes of petabytes and exabytes exceed the capacity of most processing systems, making securely storing, transmitting, and effectively managing big data a major issue.
If you are planning to work with big data, consider building (or moving) your data infrastructure in the cloud. It’s typically cheaper, safer, and will ensure flexibility and scalability. Also, be prepared to need a lot of software such as advanced stream-processing systems to support your data architecture and manage data streams.
Staffing problems
Creating and managing that whole complex system of big data flow and processing requires the efforts of skilled technical specialists. So, data architects and data engineers are needed to build the data architecture. Then, data analysts and data scientists join in for analysis.
Most likely, you already have an IT department in your company to manage your existing technology -- and most likely it won’t be enough for your ambitious plans, so consider hiring specialists having specific expertise related to big data and data science. Here’s a video with a short overview of the main roles and responsibilities of these specialists.


Data aggregation and integration difficulties
Healthcare data is spread across many institutions, hospitals, insurance companies, pharmacological and equipment producers, government agencies, private companies, and so on. It is siloed, disconnected, and comes in different (often non-digital) formats. It requires a lot of effort to arrange collaboration, establish connectivity, pull data out of different systems, and prepare it for further usage, ensuring proper quality and accuracy.Lately, there have been efforts made to implement data standards such as HL7 FHIR to improve interoperability in healthcare. But considering the variety of data formats and technical limitations of the legacy systems used in most healthcare organizations, integrating them into the modern big data ecosystem is still an issue to resolve.