

How long does it take an average traveler to pick out a hotel? As far as we know, no scientific research is being done to answer this question. Yet, real-life experience clearly shows that people spend hours and even days sifting through dozens if not hundreds of options.
The number of things to consider and the variety of reviews from previous guests is mind-blowing. This article describes our experience with using sentiment analysis to produce instant snapshots of feedback to allow travelers to compare different options at a glance and make the best choice in no time.
Solutions of this kind can benefit hoteliers, online travel agencies, booking sites, metasearch and travel review platforms seeking ways to put their customers in more relaxed mood.
What is sentiment analysis?
Sentiment analysis is the technique of capturing the emotional coloring behind the text. It applies natural language processing (NLP) and machine learning to detect, extract, and study customers’ perceptions about a product or service. That’s why this type of examination is often called opinion mining or emotional AI.
The goal of opinion mining is to identify the text polarity, which means to classify it as positive, negative, or neutral. For example, we can say that a comment like
“We stayed at this hotel for five days” is neutral,
“I liked staying here” is positive, and
“I disliked the hotel” is negative.
You can learn much more about the types and use cases of sentiment analysis in our dedicated blog post. We also have an overview of 10 best sentiment analysis tools and a post about reputation management and working with onlne reviews in general.
This time, we’ll focus on how exactly we taught machines to recognize emotions across reviews and what lessons we learned from creating an NLP-based tool called Choicy. So, let’s start!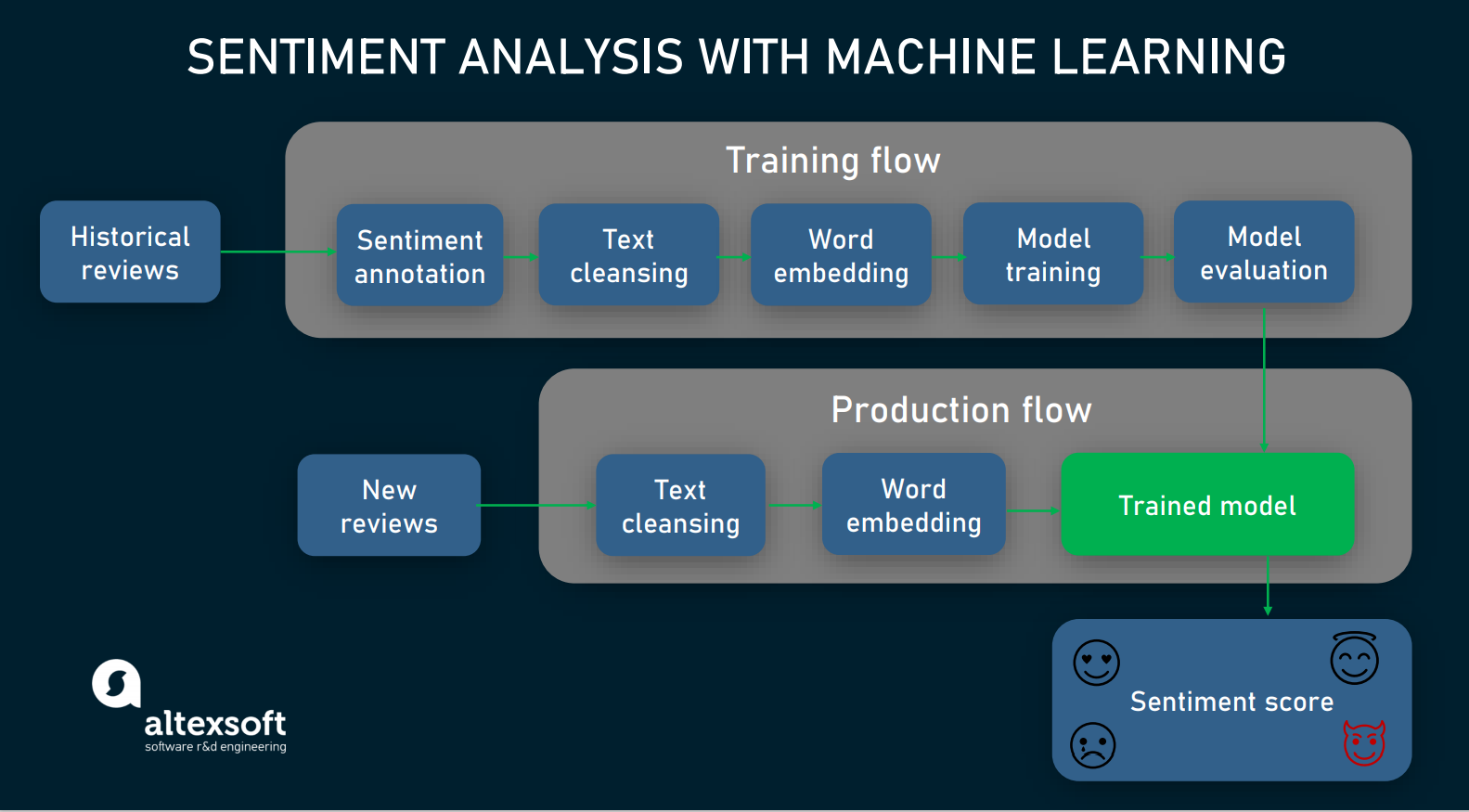
Applying machine learning to sentiment analysis
Sentiment analysis dataset: Tons of good samples are half the battle
The first step in sentiment analysis is obtaining a training dataset with annotations to tell your algorithm what’s positive or negative in there. Here, you have two options: To create it yourself or to get use of publicly available lexicons. To learn more about data preparation in general, check our article or watch our explainer on YouTube:


Data preparation, explained
Do it yourself: when accuracy is a top priority
You don’t need the power of machine learning to predict that a dataset tailor-made for a particular purpose will bring the best results. Yet, the improved efficiency and accuracy comes at a price, as preparing data for sentiment analysis is a time- and labor-intensive process that includes three important steps.
Step 1 — data collection. First, you have to gather real reviews left by hotel guests. The best way to do it is to use feedback from your website. If this option is unavailable, you may try to partner with resources that have ownership of such data. The common method of collecting datasets — scraping — is not recommended as it may entail legal issues. Under the GDPR and CCPA rules you can’t apply this technique to personal data. You also may unwittingly violate property rights of website owners.
Step 2 — sentiment annotation. To make opinions hidden in a review visible to machines, you need to manually assign sentiment labels (positive, neutral or negative) to words and phrases. Data labeling for sentiments is considered reliable when more than one human judge has annotated the dataset. The rule of thumb is to engage three annotators.
Step 3 — text cleansing. Raw hotel reviews contain tons of irrelevant or just meaningless data that can badly affect model accuracy. So, we need to clean them up, which includes:
- removing noise — or things like special characters, hyperlinks, tags, numbers, whitespaces, and punctuation;
- removing stop words which include articles, pronouns, conjunctions, prepositions. etc. One of the most popular NLP libraries, NLTK (acronym for Natural Language Toolkit) lists 179 stop words for the English language;
- lowercasing to avoid lower case/upper case differences between words with the same meaning;
- normalization — or transforming words into a canonical form. For example, a normalized form of 2morrow and 2mrw is tomorrow;
- stemming or reducing each word to its stem by chopping off endings (prefixes and suffixes). The technique often produces grammatically incorrect results — for example, having will be stemmed to hav; and
- lemmatization — meaning returning a word to its dictionary form. Say, the lemma for swimming, swum, and swam is swim.

Comparison of stemming and lemmatization. Source: Kaggle
Stemming and lemmatization are interchangeable techniques, as they solve the same task: to filter the variations of a word and reduce them to the basic unit. Still, when choosing between them, keep in mind that stemming is simpler and faster while lemmatization produces more accurate results.
It’s worth noting that all these routine tasks are typically performed by freelancers or trainees — not by data scientists themselves. The latter only supervise the process, instructing what to collect and how to pre-process and annotate raw data so that it becomes usable for machine learning.
Use an annotated corpus: when time and money are tight
So, we’ve taken you through the canonical way of dataset creation — which is really the best option providing that you have enough time and personnel. In our case, we faced strict deadlines along with budget limitations. So we took the second approach and chose among available labeled corpora that most closely corresponded to our requirements. Luckily, sentiment tagging is a common practice, with numerous datasets developed over years.
Two key factors are to be considered when choosing a collection of annotated data:
- the length of texts. If sentiment labeling was applied to longreads (articles or blog posts), such a dataset won’t be relevant for short texts like tweets or comments — and vice versa.
- the topic or domain. Acceptable by size, a corpus of labeled political tweets still will give poor results for training a model that will analyze hotel feedback. Annotated samples of restaurant or airline reviews are a better option that will produce a satisfactory level of accuracy in the hospitality domain. However, the best match for hotel reviews is ...well, a dataset generated from hotel reviews.
Below are several free to download datasets to train machine learning models for sentiment analysis. We’ve experimented with a couple of them.
Stanford Sentiment Treebank contains almost 12,000 sentences extracted from movie reviews on Rotten Tomatoes. Each sentence is represented through a parse tree with annotated words and phrases, capturing the sentiment behind a particular statement. Totally, the dataset includes over 215, 000 unique phrases, labeled by three human judges.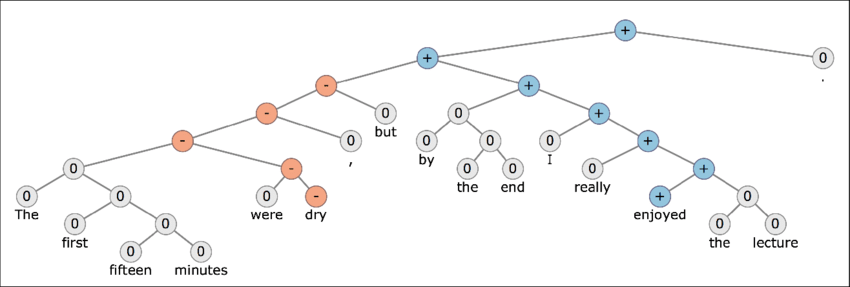
A sample of a parse tree with annotated words and phrases from Stanford Treebank
Sentiment140 includes over 1,6 million tweets pulled out via Twitter API. All tweets are annotated as positive or negative and can be used to detect the sentiment behind a brand, product, or topic on Twitter.
Restaurant Review Dataset stores a total of 52,077 reviews with ratings and mentions of pros and cons.
Trip Advisor Hotel Reviews accumulate nearly 20,000 pre-processed hotel reviews with ratings.
OpinRank Data is a collection of over 300,000 hotel and car reviews gathered from the world's largest travel feedback platform TripAdvisor and the US online resource for car information Edmunds.
Anyway, how many data samples are enough?
Whether you build a dataset yourself or look for an off-the-shelf corpus, the question is: What size should it be to train a machine learning model?
“The more data you have the more complex models you can use,” says Alexander Konduforov, Data Science Competence Leader at AltexSoft. “Deep learning models that achieve the highest level of accuracy require tens or even hundreds of thousands of samples. There is just no point in training them on small datasets.”
For simpler algorithms, fewer samples will do. But, that said, we’re talking of thousands — not hundreds — of annotated reviews. “The first thousand will give you, for example, 70-percent accuracy,” opines Alexander, explaining how the quantity contributes to the quality. “Every additional thousand will still produce accuracy growth, but at a lower rate. Say, with 15,000 samples you may achieve 90 percent while 150,000 will result in 95 percent. Somewhere, the growth curve will flatten, and from this point, adding new samples will make no sense.”
To train a model behind Choicy, we prepared a dataset of over 100,000 review samples extracted from public sources.
Word embedding: making a natural language understandable to machines
No machine learning models — even the smartest ones — can understand natural languages. So, before feeding data to an ML algorithm, we must convert words and phrases into numeric or vector representation.
This process is called word embedding. After exploring several techniques, we finally went with one of the most advanced of them. But to put our decision into context, let’s consider three popular options.
TF-IDF: measuring importance
Term Frequency-Inverse Document Frequency (TF-IDF) calculates the frequency of words in the collection of textual data and assigns higher weights to rarer words or phrases. In other words, it measures how important a particular word is and serves as a straightforward method to extract keywords.
Though still used in sentiment analysis, TF-IDF is quite an old technique that misses a lot of valuable information — such as context around nearby words or their sequence.
Word2Vec: studying neighbors
Word2Vec is a shallow, two-layer neural network that converts words into vectors (hence the name — word to vector). Created in 2013 by Google to work with a large corpora of textual data, Word2Vec places words that are used in the same context close to each other.
World2Vec representation of tweets. Source: Fréderic Godings
The model was pretrained on roughly 100 million words from Google News and can be downloaded here. It learns from data (i.e., — vectors) and improves its ability to predict the word from the context over time.
GloVe: counting word co-occurrence
Similar to Word2Vec, GloVe (Global Vectors) creates vector representations of textual data. The difference is that Word2Vec focuses on neighboring words while GloVe counts word-to-word co-occurrence across the entire text corpus. In plain language, it first builds a huge context matrix that shows how often a certain word is encountered in a certain context. Then, it produces word-to-word vectors, visualizing co-occurrence frequencies.
Co-occurrences of comparative and superlative adjectives, measured by the GloVe model. Source: The Stanford NLP Group
You can download GloVe word vectors pre-trained on tweets, Wikipedia texts, the Common Crawl Corpus from GitHub. The Stanford NLP Group that developed the model also enables data scientists to train their own GloVe vectors.
Both Word2Vec and GloVe can capture semantic and syntactic word relationships. However, the latter outperforms the former in terms of accuracy and training time. That’s why our data scientists finally chose GloVe to “translate” hotel reviews into a machine-understandable form for further analysis.
Sentiment analysis algorithms: evaluating guest opinions
From a machine learning point of view, sentiment analysis is a supervised learning problem. It means that a labeled dataset already contains correct answers. After training on it and evaluating results, a model is ready to classify sentiments in new, unlabeled hotel reviews.
Scoring reviews: from excellent to terrible
There are several models used for sentiment analysis tasks, and our data scientists eventually employed a one-dimensional convolutional neural network (1D-CNN) as one of the most effective options.
CNNs with two or three dimensions proved themselves to be especially good at image recognition — due to their ability to detect specific patterns and consider spatial relationships among them. These properties make them also efficient for sentiment classification— except that for sequential data like texts one-dimensional models are preferable over 2d and 3d alternatives.
Our CNN model is trained to output a sentiment score that considers all words with negative or positive polarity it finds in a review. Based on the resulting value we classify each opinion as ‘Excellent’, ‘Very good, ‘Average’, ‘Poor’ or ‘Terrible’. After all reviews for a particular hotel are processed, it becomes obvious which of five opinions prevail and whether the place is worth consideration at all. The deed is done!
However, we decided to go further than that.
Ranking amenities: how good are a bar and food?
More often than not, feedback contains a mix of positive and negative opinions. Say, a guest appreciates the convenient location, praises the restaurant but complains of the noisiness at night and the absence of air conditioning — all in one review. In such a case, the overall score produced by the model is close to neutral. Moreover, it doesn’t specify exactly why people like or dislike the place.
Not to miss critical information, we developed a mechanism to capture sentiments behind almost thirty individual hotel amenities — such as a bar/ lounge, food, fringe, cleanliness, quietness, comfort, and more. For this, we split each review into sentences and each complex sentence — into simpler ones. Then, we performed two classification tasks.
1. Classification by amenity. Our first task was to place each sentence or its part into one or several amenity categories. Ideally, we should have trained a model on a specially annotated dataset to recognize things like air conditioner or fringe in the real-world reviews.
Alas, there are no ready-to-use datasets labeled for thirty amenities. So, facing time and budget limitations, we took a shortcut approach. Instead of applying machine learning, we created a keyword vocabulary for every amenity to automatically find it in sentences and categorize them accordingly. For example, if a particular sentence contains the words bath, bathroom, or shower, it is categorized as bathroom. Simple but good enough!
2. Classification by sentiment. To find sentiments behind sentences, we applied a hierarchical attention-based position-aware network or HAPN — another advanced model that can capture the context and word dependencies. Thus, it builds a clear picture of what a positive or negative word refers to. As a result, each categorized sentence with an amenity got an individual sentiment score.
After HAPN evaluated sentences independently, we summed up sentiment scores by categories and built the amenity ranking.
Pretty straightforward, but as they say, “A picture is worth a thousand words.” So, let's proceed to visualization.
Visualizing: all comments at a glance
And this is where we’ve come to — a simple yet clear interface that accommodates hundreds of reviews in a couple of graphics.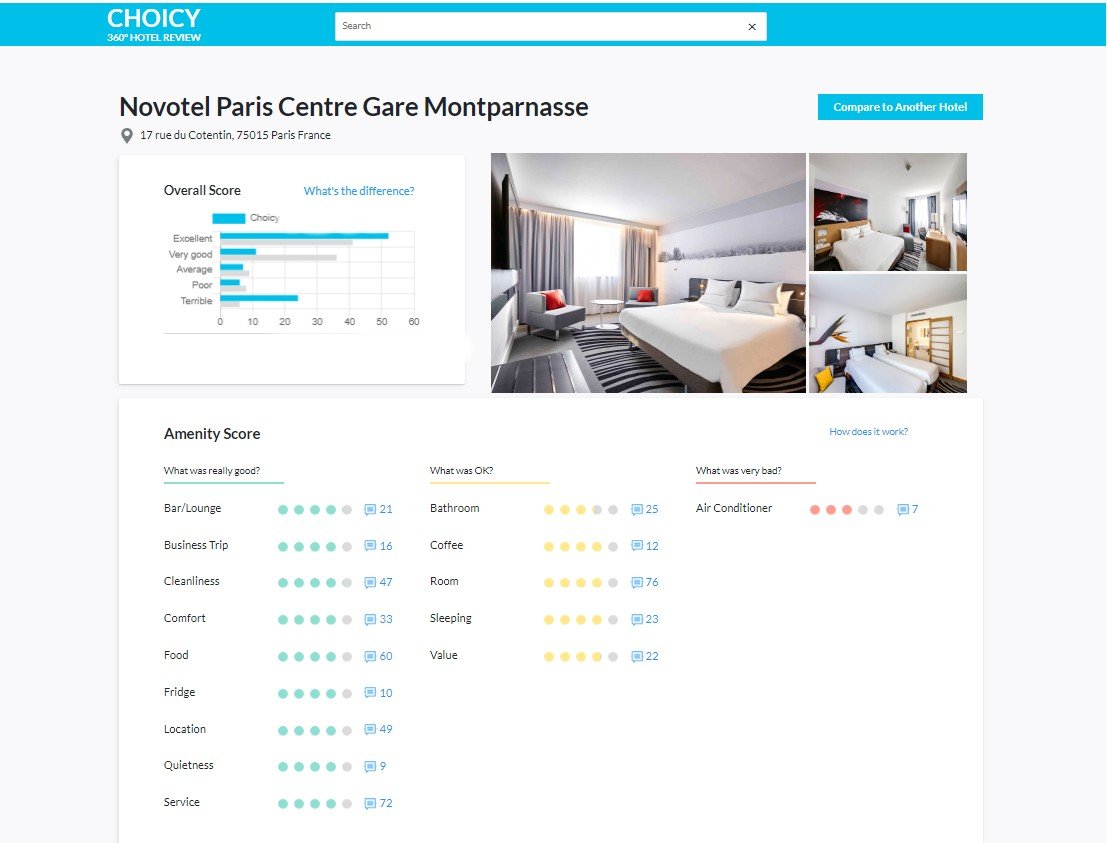
Choicy interface with overall and amenity scores
Reading reviews when choosing a hotel may take hours — or days — depending on an individual level of anxiety. Sentiment analysis cuts the time needed to weigh the pros and cons to a few minutes. Good enough, though we still see room for improvement. No hotel is ideal, no model is perfect, but it’s worth working on.
Just for reference! What sentiment analysis can’t do is understanding sarcasm. Each time a traveler leaves a comment like The best family hotel, yeah right! meaning that they will never stay here again, the chance is some ML model will classify this feedback as positive. Obviously, technologies side with hotels — at least, thus far.