If you’ve succumbed to the hype around machine learning, you’ve likely heard hundreds of ML evangelists claim that data-driven decision-making is inevitable for companies that want to thrive in the near future. And a number of questions will arise as you consider how to employ the technology in your business. Can it significantly aid in reducing costs or increasing revenue? How can you estimate return on investment? Can you leverage the existing data to yield game-changing insights? Should you even try to get on that train right now?
What’s so special about machine learning
The concept of machine learning was conceived about 50 years ago with the idea of making computers learn as humans do. As the field evolved, it gave us a means to find useful patterns in large amounts of data.
The way to address this is to apply an algorithm which would differ from the diligent but narrow “if-then” programs that we’re used to dealing with. Machine learning isn’t limited to narrow-task execution. An engineer doesn’t have to compose a set of rules for the program to follow. Instead, a machine can devise its own model of finding the patterns after being “fed” a set of training examples. Dealing with a “black box” of that sort–where a human is only concerned about inputs and outputs–brings almost unlimited variety of application opportunities, from recognizing cats in pictures to tracking body functions that yield individual treatment programs.
The reason machine learning is only now topping the list of tech buzzwords is that just recently we’ve achieved computational power enough to process big data: huge and unstructured data sets with possibly thousands of variables instead of small and well-filtered ones. Much talked-about AlphaGo, which has recently beaten a human grandmaster at the ancient game of Go, is just one of the examples.
Defining how machine learning is going to be the gamechanger for your business isn’t as trivial a task of simply putting the data into the black box and waiting for a magical insights sheet to roll into your printer tray. While you can utilize the approach to get insights about one or a handful of operations in a company, tangible changes happen only if the adoption is backed by a strategy. The strategy should be introduced and guided at the C-suite level, and a number talent acquisitions should be made to support this strategy adoption.
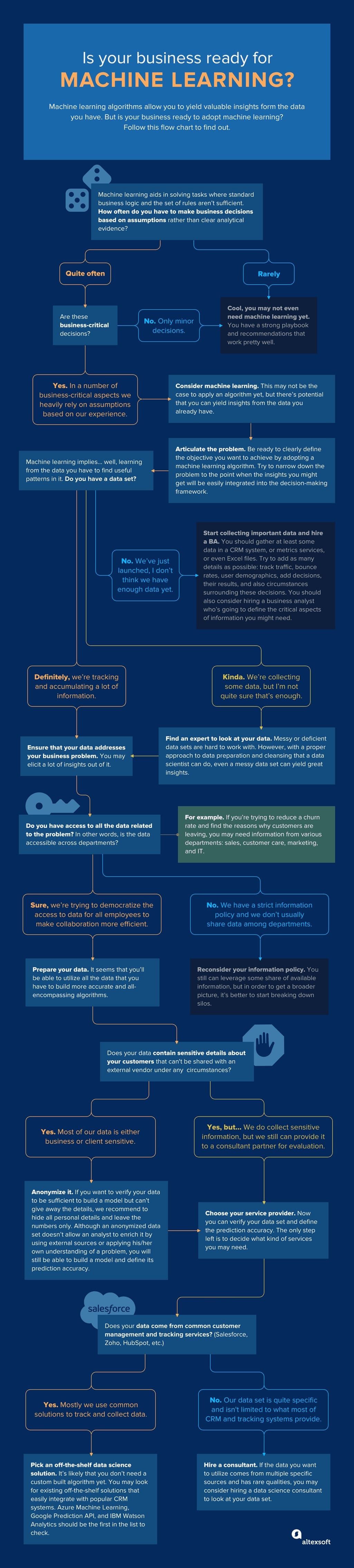
Step 1. Articulate the problem
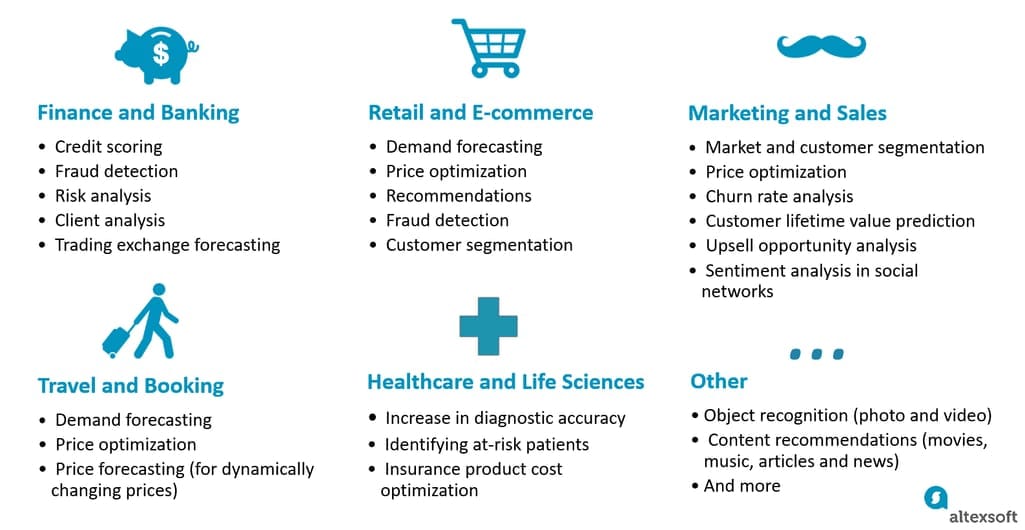
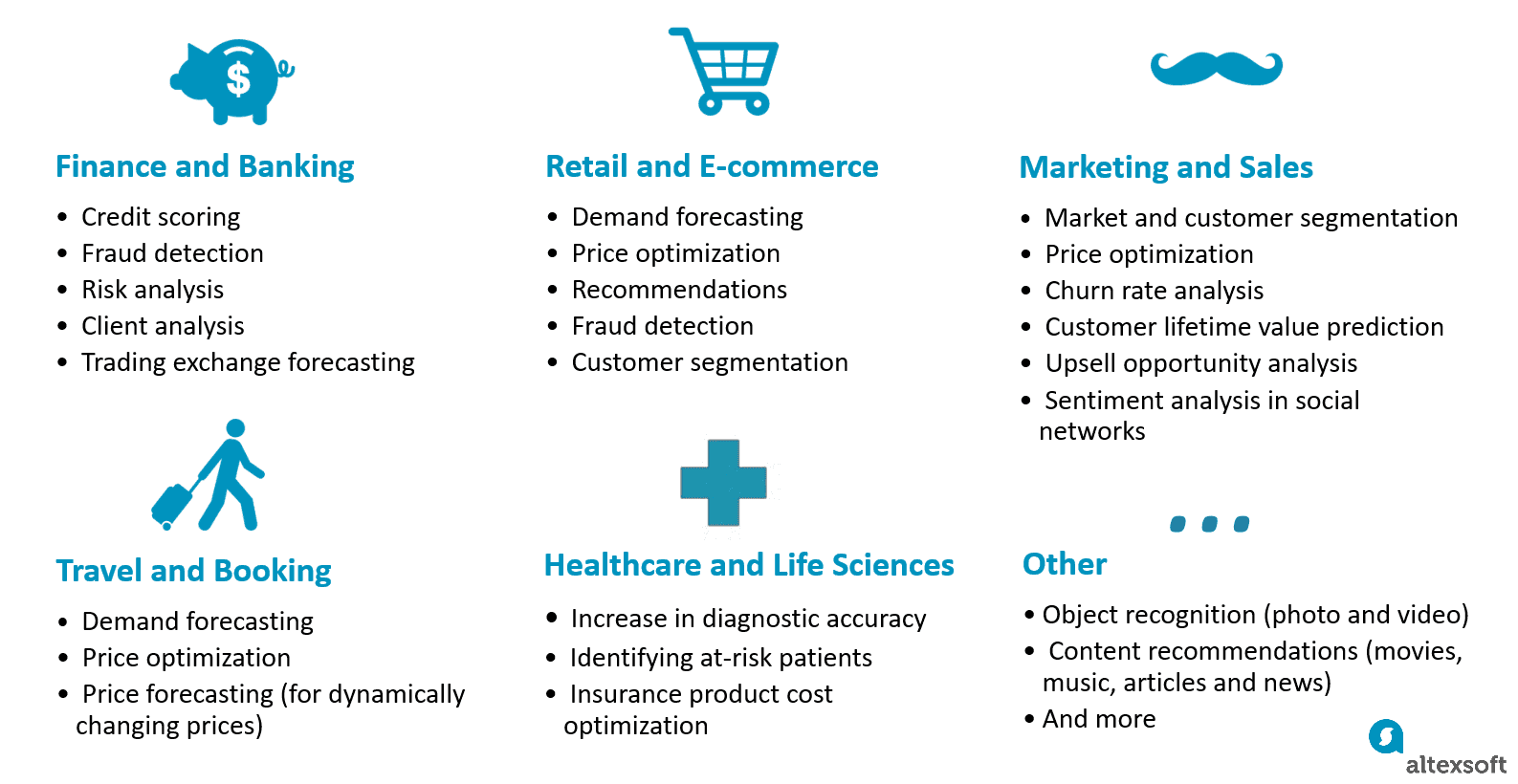
There are generally two types of companies that engage in machine learning: those that build applications with a trained ML model inside as their core business proposition and those that apply ML to enhance existing business workflows. In the latter case, articulating the problem will be the initial challenge. Reducing the cost or increasing revenue should be narrowed down to the point when it becomes solvable by acquiring the right data.
For instance, if you want to reduce the churn rate, data might help you detect users with a high “fly risk” by analyzing their activities on a website, an SaaS application, or even social media. Although you can rely on conventional metrics and make assumptions, the algorithm may unravel hidden dependencies between the data in users’ profiles and the likelihood to leave.
Here’s another example. While it’s relatively easy to estimate performance scores in a sphere of production, can you understand, for instance, how salespeople perform? Technically, they send emails, set calls, and participate in conferences, all of which somehow result in revenue or the lack thereof. People.ai is a startup that tries to address the problem by making a machine learning algorithm to track all the sales data, including emails, calls, and conferences, to come up with the most productive sales scenarios.
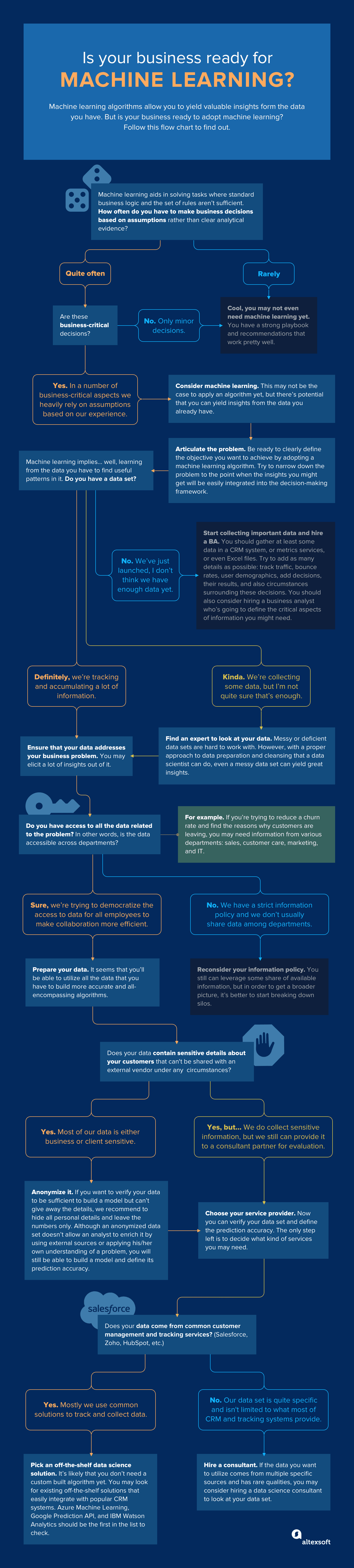
The bottom line here is to define the problem where standard business logic and the set of rules aren’t sufficient to solve it. Use machine learning when decisions heavily rely on a subjective opinion of an analyst or a decision maker.
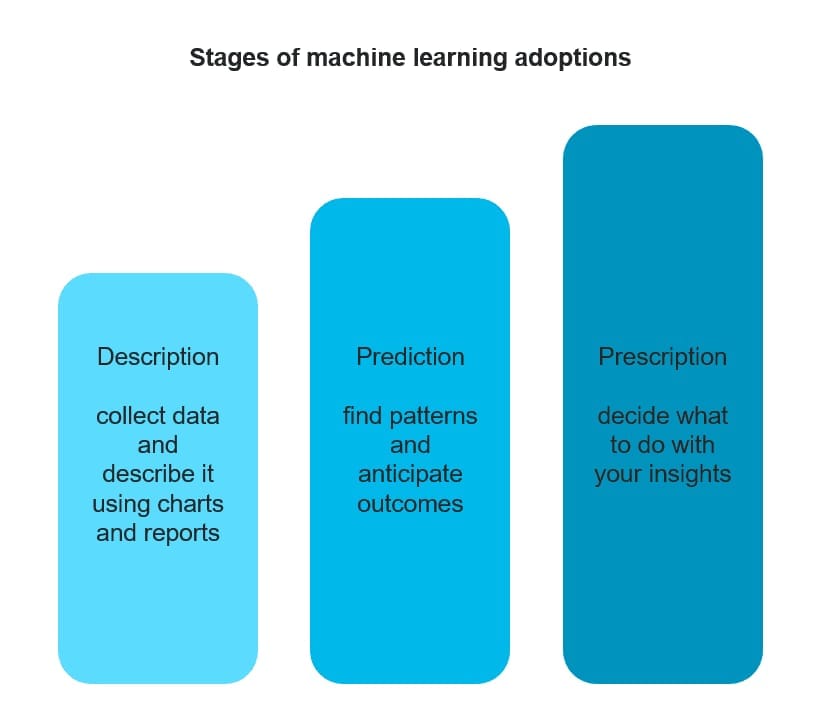
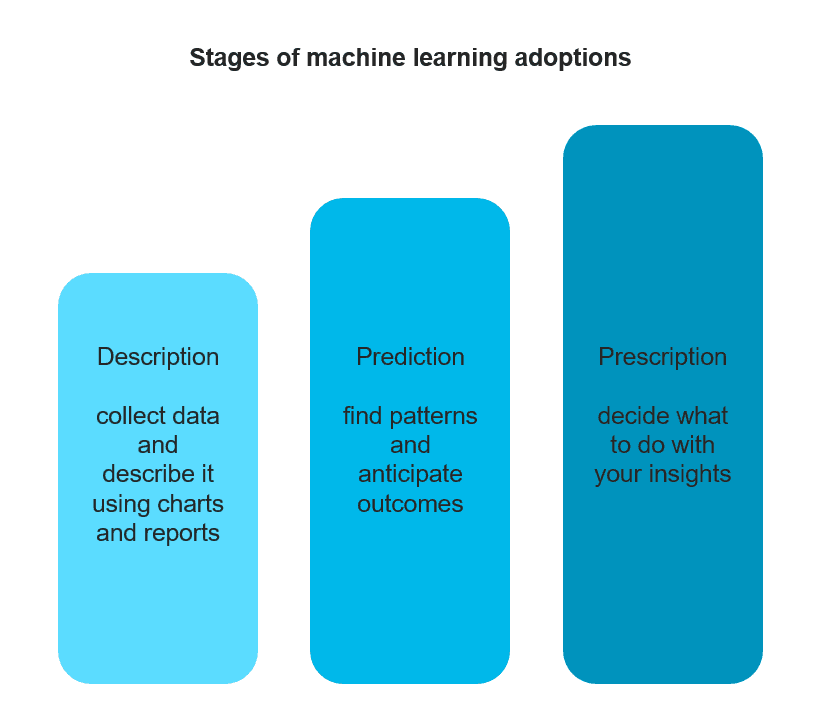
Applied predictive analytics is a broader variety of techniques that anticipate outcomes by leveraging data. While machine learning is one approach to realize predictive analysis, the current landscape of areas where it acts as a strategical reinforcement to business processes is quite broad, from content recommendations to healthcare.
Step 2. Consider the prescription
The most advanced issue of developing predictive analytics strategy is whether you can find the right prescription based on the received knowledge. In other words, what are you going to do with the insights you obtain? Can you automate the decision-making in this case? McKinsey disclosed the story of an international bank that was concerned about the number of defaults that some of their clients experienced. By means of machine learning, they managed to detect a group of customers that had suddenly switched from spending money during the day to using their bank cards in the middle of the night. This behavioral pattern closely correlated with the default risk as the bank later discovered that the people from the group were coping with a recent stressful experience. The prescription was to offer financial advice to the people from the risk group and establish new credit limits for these customers. In some cases, coming up with such prescriptions would be much harder or it would involve a course of actions that can’t be automated at all.
Moreover, insights that you will get may inspire the prescription measures that you could never think before unraveling hidden dependencies in your data.
Step 3. Ensure that the quality of your data is good enough
Data science is a broad field of practices aimed at extracting valuable insights from data in any form. And we believe that using data science in decision-making is a better way to avoid bias. However, that may be trickier than you think. Even Google has recently fallen into a trap of showing more prestigious jobs to men in their ads than to women. Obviously, it’s not that Google data scientists are sexist, but rather the data that the algorithm uses are biased because it was collected from our interactions with the web.
Qualify your data and decide the minimum prediction accuracy
Basically, the quality of the data you have or can collect will define whether it may be used to build the algorithm. Data can be noisy; some information can be conflicting, biased, or just missing. To qualify your data set for further model development, you’ll need to involve a technical consultant or a data scientist in the early stages. This will allow for data testing and setting the minimum acceptable prediction accuracy. Here’s something to note: Although business decision makers look for concrete recommendations, data science can only provide relative figures. So, deciding the minimum degree of confidence acceptable for solving a business problem will be on top of the importance list.
In one of our projects involving fare prediction analysis in booking air tickets, we were challenged to design an algorithm which would forecast flight fares, both short and long term forecasts. Seventy-five percent of prediction accuracy was high enough to support customers with booking recommendations.
Be ready to break down silos, anonymize, and share data
One of the hurdles that our data science team regularly faces is the access to data at the stage of project negotiation. While understanding the initial costs are critical for any business that decided to embark on predictive analytics, it’s nearly impossible to estimate the accuracy level and price without seeing actual data. That’s the point when negotiations can be paralyzed by the catch-22 problem. Business executives can’t give away the sensitive customer or business-related information to a technical consultant, while a consultant can’t give definitive answers before seeing data.
We usually offer to provide a subset instead of the whole database and anonymize it beforehand. Even for the companies having a data scientist on board, it’s a common management challenge to share data among different departments. An overregulated information policy or just hoarding of data across departments can really slow down the process. That’s why data science adoption should be introduced and guided on the higher management level.
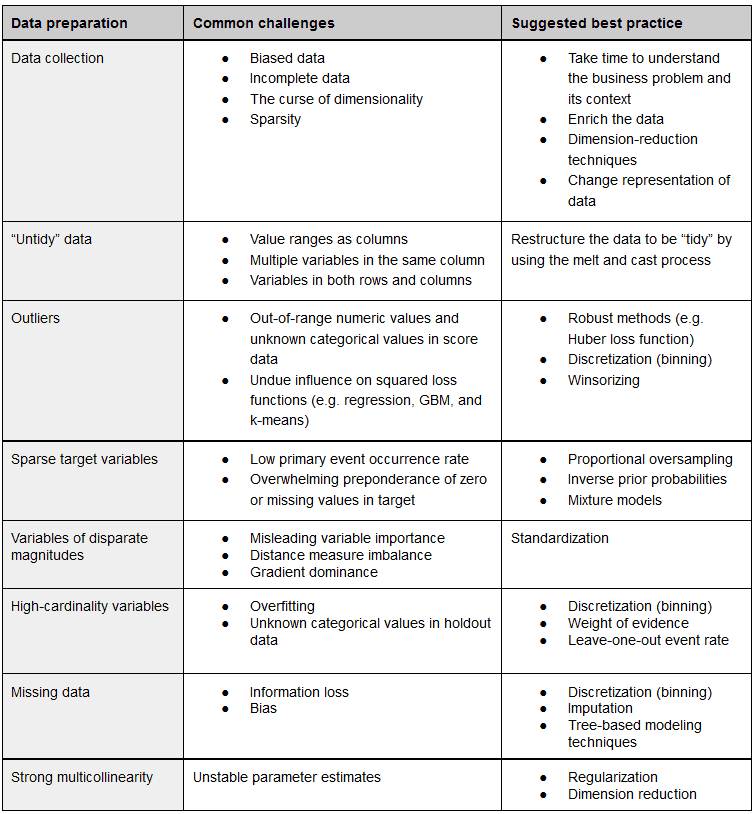
Good news: Data can be fixed
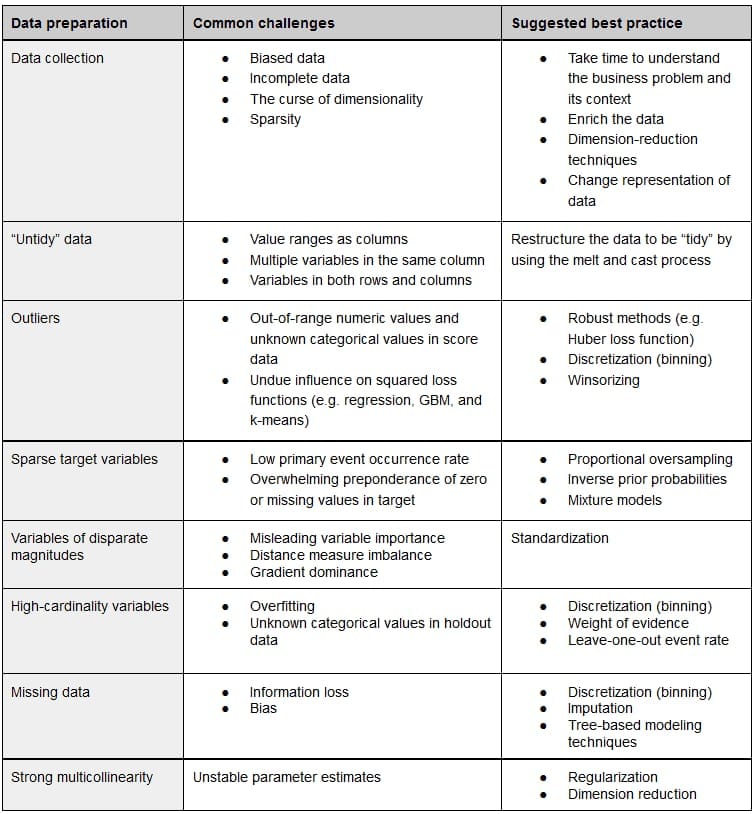
Even if your data set is messy and unstructured, it’s not necessarily a death sentence for your data science initiative. Today, data scientists are well equipped with a number of practices to apply during the preparation stage to restructure, clean your data set, and further optimize it for the efficient modeling.
Source: O'Reilly, The Evolution of Analytics
The bad news here is that a data scientist may require quite a while to complete data cleansing and proceed to the modeling stage. Should you try handling it yourself in advance without having proper expertise? The general answer is no. It’s very likely that your data set will need refactoring anyway.
Step 4. Prepare to bridge the gap between technical and business vision
If you ask data scientists about their favorite and most useful algorithms, you’ll likely hear something about boosted decision trees, artificial neural networks, kernel methods, principal component analysis, etc. Thus, you may hire a brilliant data scientist who’s still going to have a hard time translating complex results into concrete business language. On the other hand, a chief marketing officer (CMO) may lack technical background to convert figures given as probabilities into monetary terms.
According to a recent SAS paper, many organizations have already recognized the need to introduce a chief analytics officer to their corporate frameworks. The person should have both business and tech expertise to lead the data science initiatives, envision the options to scale the machine learning application and reconcile business and technical vision.
Otherwise, your data scientists should be ready to educate decision makers on the opportunities and limitations that different ML models present.
Step 5. Explore the options to hire the right talent
One of the most popular courses at Stanford is machine learning. And back in 2012, the Harvard Business Review regarded a data scientist to be “the sexiest job of 21st century.” Yet there have been a lot of talk about the shortage of data-science talent over the past few years. McKinsey theorizes that by 2017 the demand for this expertise will be 60 percent higher than supply. No matter whether this prediction is true, the profession is extremely hyped. If you operate from New York City or Silicon Valley, the starting salary for a data scientist will be about $200,000, as stated by Bloomberg.
What makes data scientists so scarce and valuable is the blistering change in the technological landscape that outstrips educational capacities. Moreover, being a data scientist requires a rare skillset combination at the junction of math, statistics, programming, databases, and domain expertise.
So, here is the challenge. What are the options?
Hire a data scientist and be ready to engage
If you aren’t operating in a metro area such as New York City or Silicon Valley, the median salary will be about $104,000, which is nearly double the average salary for a regular programmer. Not only do experienced data scientists have higher price tags, they will demand creative work to stay engaged, which often conflicts with the siloed department structures of many organizations.
Homegrown specialists
To leverage the talent that you already have, you’ll inevitably need a data scientist to take a leadership role. This also can be addressed by building or acquiring a machine learning platform with a friendly interface that would be approachable to a wider range of specialists within your organization. That way, you’ll be able to scale from one or a handful of people to a larger group of experts. Have a look at our data science team structures guide to get a better idea of roles distribution.
Find a vendor team
Outsourcing several operations to external experts became a common practice a long time ago. But unlike generic programming that so many vendors can do, data science and machine learning outsourcing haven’t yet overcome the threshold of trust. The biggest challenge of outsourcing machine learning tasks is to align corporate limitations of sharing data with external expert assistance. Depending on the type of data you have, you may need to anonymize it in a way that it doesn’t reveal sensitive details, like customer contacts, their location, etc. You should also keep in mind that an anonymized data set doesn’t allow an analyst to enrich it by using external sources or applying his/her own understanding of a problem to build a more efficient model.
Build relationships with educational institutions
In the US, there are about a dozen Ph.D. data science programs available at universities and nearly the same number of computer science programs that are actively emphasizing data science. Another popular way to fill the skills gap is boot camps where attendees take 12-month or so courses. This option seems very promising for companies that aren’t ready to invest into hiring experienced experts, though you should always consider additional internal training to accumulate essential domain expertise.
Step 6. Models become dated, be ready to iterate
Most of the models are developed on a static subset of data, and they capture the conditions of the time frame when the data were collected. Once you have a model or a number of them deployed, they become dated over time and provide less accurate predictions. Depending on how actively the trends in your business environment change, you should more or less frequently replace models or retrain them. There are two basic approaches to that:
Challenger testing. When the existing model is assumed to become less accurate, a new challenger model is introduced and tested against the deployed model. The old model is removed once the new one outperforms it. Then the process is repeated.
Online updates. The parameters of a model are changed under the continuous flow of new data.
So, if you want to retain your predictive analytics on the same level of accuracy, having occasional or short-term data science services is not an option.
Step 7. Decide whether you need a custom-built algorithm
Building custom data models, their deployment, and further iterative development may be a serious financial and management burden for small and midsize businesses. Using algorithms that are shipped off the shelf is a viable option if you’re looking for common prediction tasks. Large product developers like Hitachi are already preparing blueprints and even solutions to support the industries they’re focusing on. Having an out-of-the-box algorithm doesn’t necessarily mean you won’t have to customize it to align with business objectives, but it might greatly reduce the financial difficulties.
Salesforce, for instance, is offering artificial intelligence instruments that can communicate with their existing cloud solutions. The previously mentioned people.ai service along with Azure Machine Learning, Google Prediction API, and IBM Watson Analytics can be integrated with the most popular CRMs like Salesforce, Hubspot, Zoho, and some others. Guesswork offers ecommerce companies better understanding of customers by analyzing various collected data and providing tailored experiences. It integrates with ecommerce sites and can predict which visitors are more prone to conversion or it lets you tailor a newsletter to each customer. Ultimately, you can apply to Algorithmia, a marketplace of pre-built algorithms that communicate with software through REST APIs.
Is it the right time to adopt machine learning?
In one of his novels, Hemingway described how a man goes broke “gradually and then suddenly.” The passage aptly reflects the way machine learning progresses. Today, it’s on the top of the hype cycle, and, consistent with Gartner, the mainstream adoption will happen in 2 to 5 years. Early adopters are already actively testing and iterating to reach a high productivity stage.
In a course of a few years, it’s likely that having a data science department will be the definitive point of competition in a wide range of business verticals, as CRM systems became years ago.