

There has been a lot of buzz around data science, machine learning (ML), and artificial intelligence (AI) lately. As you may already know, training a machine learning model requires data. Lots of data, to be more precise. Lots of quality data, to be even more precise.


To save time, watch our 14-minute video on how data is prepared for machine learning
So, where were we? Oh, right, you need data to build intelligent machines that will take over the world one day ????. While huge amounts of information are generated daily, a large portion of this valuable asset remains inaccessible to AI projects due to privacy concerns. Addresses, healthcare or financial details, and other personal info make data subject to legal restrictions. That’s where the new approach called federated learning comes into play.In this post, we’ll take you down the road of federated learning by explaining what it is, how it differs from more traditional approaches, and how it works in general. Also, you will find info about where federated learning can be applied and what limitations it may have. Let’s dive in.
What is federated learning?
Federated learning or FL (sometimes referred to as collaborative learning) is an emerging approach used to train a decentralized machine learning model (e.g., deep neural networks) across multiple edge devices, variously from smartphones to medical wearables to vehicles to IoT devices, etc. They collaboratively (hence the second name) train a shared model while keeping the training data locally without exchanging it with a central location.This creates an alternative to the traditional centralized approach to building machine learning models where data from different sources is collected and stored on one server, and then the model is trained on a single server too.
In simple terms, with federated learning, it is not data that moves to a model but it is a model that moves to data, meaning training is happening from user interaction with end devices.
A relatively new and continuously researched topic, federated learning has been actively driven by scientists from Google during recent years. The tech giant has applied this approach to improve next-word prediction models in their Gboard on Android.
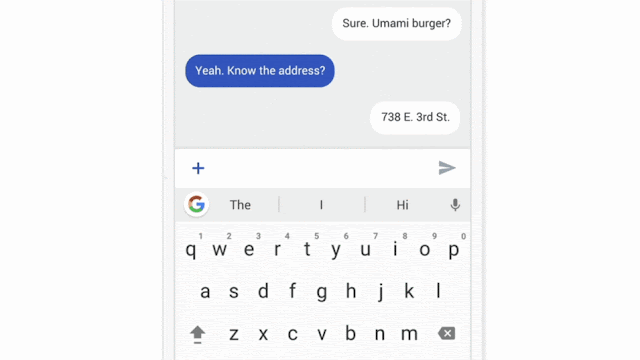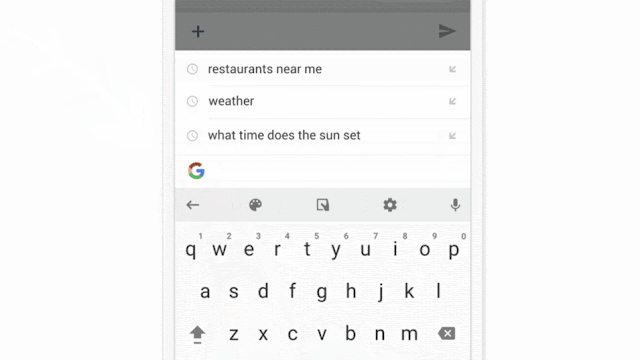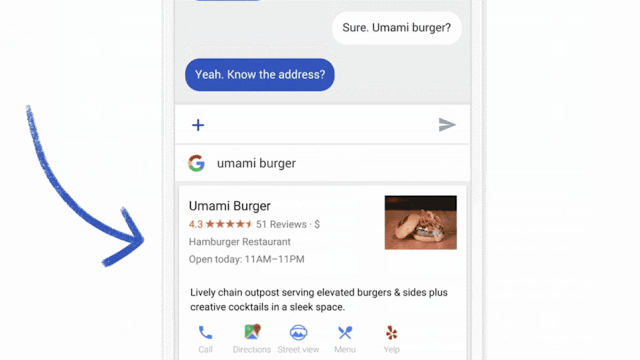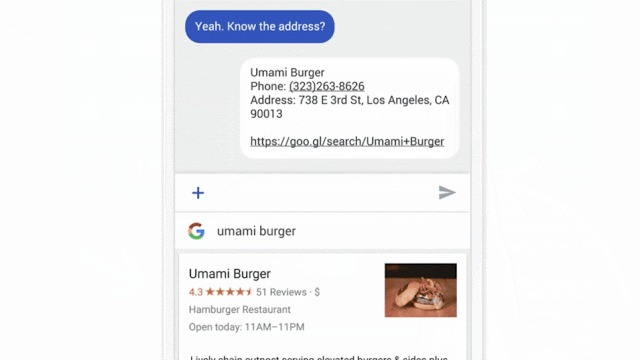
Google's federated learning in action. Source: Google AI blog
Owing to federated learning, the company takes advantage of data from millions of smartphones while keeping users' private text messages safe. Quoting Google, "Federated Learning processes that history on-device to suggest improvements to the next iteration of Gboard’s query suggestion model."Sounds pretty interesting. But how does this new ML paradigm actually work?
Centralized vs decentralized vs federated machine learning
To help you understand federated machine learning, we’ll compare it to more traditional centralized and decentralized approaches to perform ML.Centralized machine learning approach
Traditionally, the data for machine learning models is first collected from multiple sources into one centralized repository. This central location can be a data warehouse, a data lake, or even a new, combined version of both — lakehouse. You pick an algorithm like the decision tree (or a set of algorithms like the aforementioned neural networks) to train it on the collected data. Then you can run the resulting model right on the central server or distribute it across devices.
The centralized machine learning approach
While it’s a relatively easy, standard approach, it has some disadvantages — especially if applied to modern IoT infrastructures, with new data constantly generated at the periphery of computer networks. The main modern challenges related to centralized ML are as follows:- Network latency. Real-time apps require almost instant response from the model. If it’s run on the server, there is always a risk of delays in data transmission.
- Connectivity issues. Again, you need a stable Internet connection to ensure smooth data exchange between myriads of devices from one side and the central server from the other.
- Data privacy concerns. Some data such as images and text messages may be useful for making intelligent apps but it may contain private information and can’t be freely shared.
Decentralized on-site machine learning approach
One idea to solve some of the problems mentioned above is to do all machine learning on-site. This means that each individual device or local server trains the model on its own data and in its own environment, not communicating with the central location at all. As a result, ML stays independent of the quality of the Internet connection and can use confidential information as it doesn’t have to be sent to the cloud.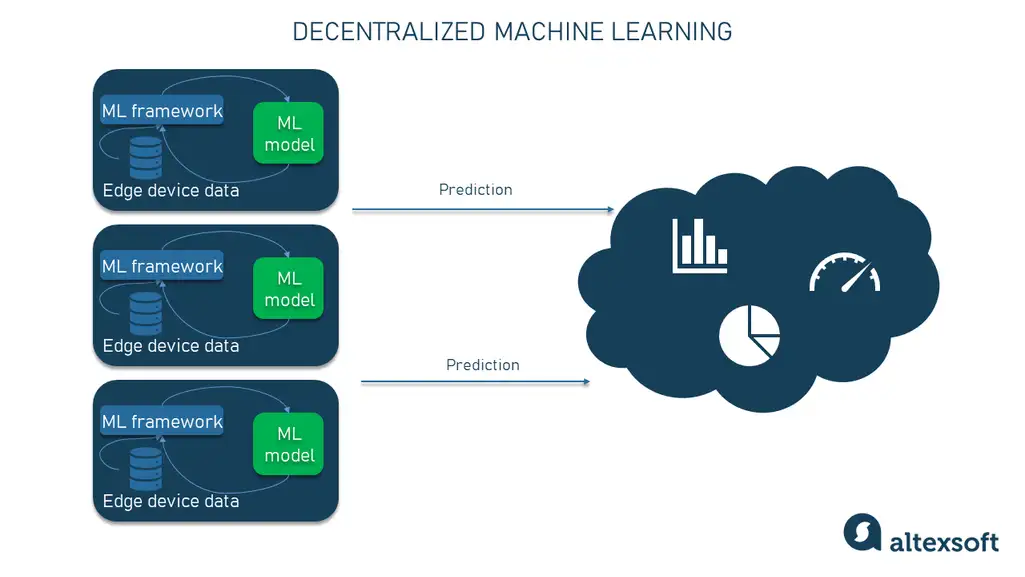
The decentralized machine learning approach with models trained at each edge device
The downside of the approach is that one device doesn’t obtain sufficient data to make accurate predictions and other sources do not contribute to the model training.So, the question is left open. Is there a chance for companies to create an efficient machine learning model while keeping all things on-device? In short, yes. Federated learning is here for those reasons.
Federated machine learning approach
Federated learning also enables learning at the edge, meaning it brings model training to the data distributed on millions of devices. At the same time, it allows you to enhance results obtained at the periphery, in the central location.Let’s see how it works step by step.

Federated machine learning process in steps
- You choose a model that is either pre-trained on the central server or isn’t trained at all.
- The next step would be the distribution of the initial model to the clients (devices or local servers).
- Each client keeps training it on-site using its own local data. The important part is that this training data can be confidential, including personal photos, emails, health metrics, or chat logs. Collecting such information in cloud-based environments could be problematic or simply impossible.
- When locally trained, the updated models are sent back to the central server via encrypted communication channels. Well, here it’s worth noting that the server doesn’t get any real data, but only trained parameters of the model (e.g., weights in neural networks). The updates from all clients are averaged and aggregated into a single shared model, improving its accuracy.
- Finally, this model is sent back to all devices and servers.
Such type of ML can happen
- when a device is offline or idle,
- in real time, and
- on sensitive data without compromising its privacy.
Federated learning frameworks
As with other ML projects, the federated learning paradigm requires frameworks and libraries for training algorithms and enabling the working data pipeline between a server and clients. Below, there’s a shortlist of the most widely-used federated learning frameworks at the moment.Please note: This is the choice of the most popular frameworks as we do not promote any of the participants.
TensorFlow Federated
Developed by Google, TensorFlow Federated (TFF) is a Python-based, open-source framework for training machine learning models on decentralized data. This framework has been pioneering the experimentation with federated learning as an approach.TFF performs in two main API layers:
- Federated Learning (FL) API offers high-level interfaces that enable developers to plug existing machine learning models to TFF without the need to dive deeply into how federated learning works.
- Federated Core (FC) API offers low-level interfaces that provide opportunities to build novel federated algorithms.
OpenFL
Developed by Intel, OpenFL (Open Federated Learning) is an open-source framework that leverages the data-private federated learning paradigm for training ML algorithms. The framework comes with a command-line interface and a Python API. Open FL can work with training pipelines built with PyTorch and TensorFlow while it can go beyond and work with other frameworks.IBM Federated Learning
IBM Federated Learning is a framework that promises data scientists and machine learning engineers an easy integration of federated learning workflows within the enterprise environment. This federated learning framework supports a variety of algorithms, topologies, and protocols out-of-the-box, including- Linear classifiers/regressions,
- Deep Reinforcement Learning algorithms,
- Naïve Bayes,
- Decision Tree, and
- Models written in Keras, PyTorch, and TensorFlow, to name a few.
Federated learning applications
In theory, federated learning sounds like a perfect plan that helps mitigate the major problems often faced when implementing traditional ML models with data residing in one central location. New to the landscape of artificial intelligence, federated learning is still being actively researched. But there already are a few examples of FL practical use.Healthcare
Healthcare is one of those industries that can benefit from federated learning the most, considering that protected health information can’t be shared that easily due to HIPAA and other laws. In this way, masses of diverse data from different healthcare databases and devices can contribute to the development of AI models, while complying with regulations.One of the real-life examples is the use of federated learning for predicting clinical outcomes in patients with COVID-19. The scientists applied data from 20 sources across the globe to train an FL model while maintaining anonymity. The model was called EXAM (electronic medical record chest X-ray AI model) and was aimed at predicting the future oxygen requirements of patients with symptoms of COVID-19. The model was trained on inputs of vital signs, laboratory data, and chest X-rays.
Advertising
Personalization highly relies on each individual user data, that’s obvious. However, more and more people are concerned with how much of the data they would prefer not to share with anyone brings up instances like social media sites, eCommerce platforms, and other places. While depending on the personal data of users, advertising can take advantage of federated learning to stay afloat and keep calm people's fears.Facebook is now rebuilding how its ads work by placing more value on user privacy. The company explores on-device learning by running algorithms locally on phones to find out what ads a user finds interesting. The results are then sent back to the cloud server in an aggregated and encrypted format for marketing teams to review.
Autonomous vehicles
Since federated learning is capable of providing real-time predictions, the approach is used in developing autonomous cars. The information may include real-time updates on the roads and traffic conditions, enabling continuous learning and faster decision-making. This can provide a better and safer self-driving car experience. The automotive industry is a promising domain for implementing machine learning in a federated manner. However, at the moment, there is only research being done in this direction. One of the research projects has proved that federated learning can reduce training time in wheel steering angle prediction in self-driving vehicles.Key federated learning limitations and things to consider
It’s worth remembering that federated learning is still at the stage where more research is being done than real applications. And as with all the benefits brought to the table, the approach has its drawbacks that are not faced in centralized learning. Here are the key ones.Efficiency of communication
Communication effectiveness is the major bottleneck when developing federated learning networks. Since data resides on a ton of local devices, communication in such a framework can be slower than when all interaction between participants happens within one location. Instead of sending the complete dataset only once, more iteration rounds are needed to send every local model update. The potential solutions to this issue can be either reducing the size of transmitted updates at each iteration or reducing the number of iterations.Heterogeneity of systems and data
Due to the distributed fashion of the federated learning approach, another problem arises — the systems and data they generate may vary greatly. The same goes for the storage, computational, and communication capabilities of the devices within the network. Some devices may connect through WiFi while others have 4G and 5G connectivity. Hardware such as a CPU and power supply also have differences from one system to another.If not addressed, heterogeneity makes it impossible to improve the accuracy of the shared model that aggregates results of locally trained algorithms. Different heterogeneity-aware optimization algorithms are developed to solve this problem — including FedProx, FedDANE, and others.