In 1901, a woman named Julia Davis Chandler published the recipe that changed the world for good. It was the very first recipe for a peanut butter and jelly sandwich. While either a peanut butter sandwich or a jelly sandwich each have merit on their own, it's hard to argue that together they make the most epic combo complementing each other’s best flavor qualities. And we’re talking about this why?
Well, there’s a new phenomenon in data management known as a data lakehouse. And it’s also an epic combo. Like the PB&J sandwich, it's more than just a new term: Data lakehouses combine the best features of both data lakes and data warehouses and this post will explain this all.
What is a data lakehouse?
A data lakehouse, as the name suggests, is a new data architecture that merges a data warehouse and a data lake into a single whole, with the purpose of addressing each one’s limitations.
In a nutshell, the lakehouse system leverages low-cost storage to keep large volumes of data in its raw formats just like data lakes. At the same time, it brings structure to data and empowers data management features similar to those in data warehouses by implementing the metadata layer on top of the store. This enables different teams to use a single system to access all of the enterprise data for a range of projects, including data science, machine learning, and business intelligence.
So, unlike data warehouses, the lakehouse system can store and process lots of varied data at a lower cost, and unlike data lakes, that data can be managed and optimized for SQL performance.
Let’s elaborate on this and figure out how a data lakehouse is different from its ancestors and name inspirers in more detail.
Data warehouse vs data lake vs data lakehouse: What’s the difference
Prior to the recent advances in data management technologies, there were two main types of data stores companies could make use of, namely data warehouses and data lakes.
Data warehouse
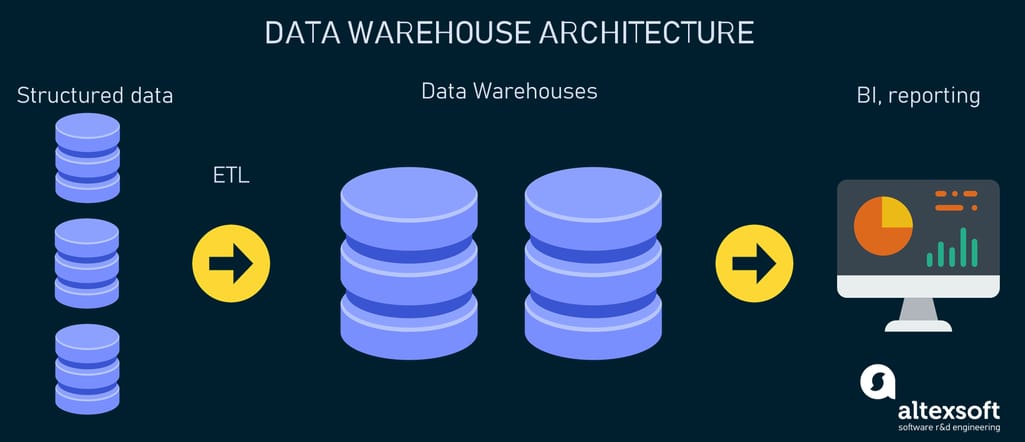
A data warehouse (DW) is a centralized repository for data accumulated from an array of corporate sources like CRMs, relational databases, flat files, etc. Typically used for data analysis and reporting, data warehouses rely on ETL mechanisms to extract, transform, and load data into a destination. The data in this case is checked against the pre-defined schema (internal database format) when being uploaded, which is known as the schema-on-write approach. Purpose-built, data warehouses allow for making complex queries on structured data via SQL (Structured Query Language) and getting results fast for business intelligence.
Traditional data warehouse platform architecture
Key data warehouse limitations:
Inefficiency and high costs of traditional data warehouses in terms of continuously growing data volumes.
Inability to handle unstructured data such as audio, video, text documents, and social media posts.
The DW makeup isn't the best fit for complex data processing such as machine learning as warehouses normally store task-specific data, while machine learning and data science tasks thrive on the availability of all collected data.
Another type of data storage — a data lake — tried to address these and other issues.
Data lake
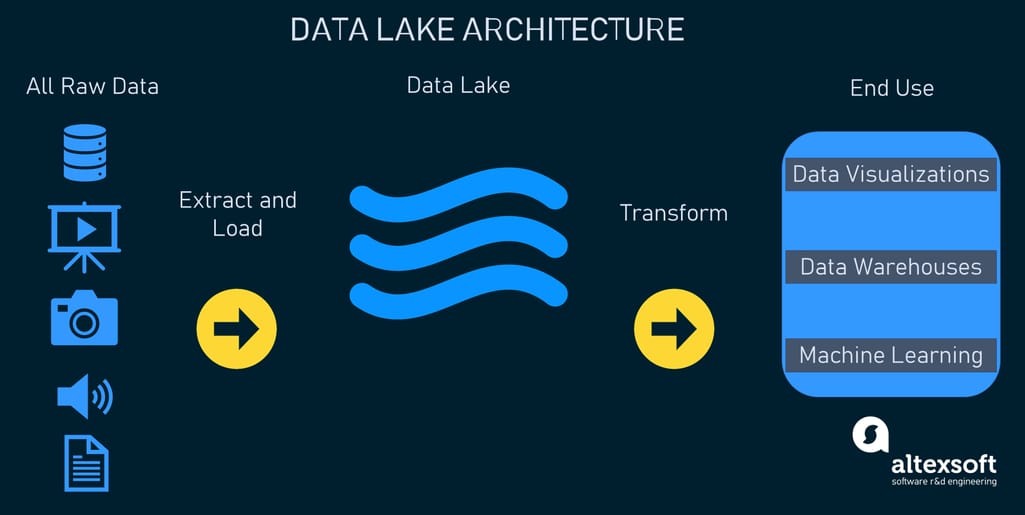
A data lake is a repository to store huge amounts of raw data in its native formats (structured, unstructured, and semi-structured) and in open file formats such as Apache Parquet for further big data processing, analysis, and machine learning purposes. Unlike data warehouses, data lakes don’t require data transformation prior to loading as there isn’t any schema for data to fit (to learn more, read our dedicated article about ETL vs ELT). Instead, the schema is verified when a person queries data, which is known as the schema-on-read approach. All of this makes data lakes more robust and cost-effective compared to traditional data warehouses.
Data lake architecture example
Key data lake limitations:
Business intelligence and reporting are challenging as data lakes require additional tools and techniques to support SQL queries.
Poor data quality, reliability, and integrity are problems.
Issues with data security and governance exist.
Data in lakes is disorganized which often leads to the data stagnation problem.
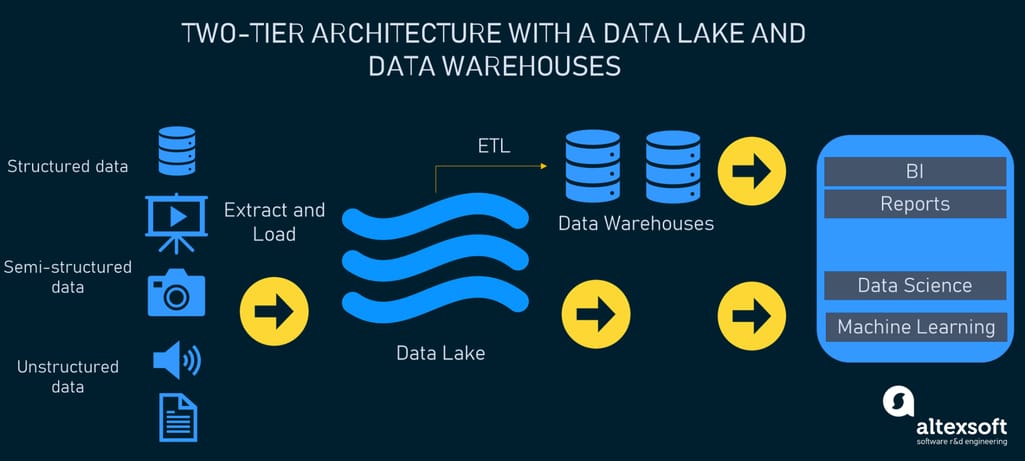
Since none of the above-mentioned options was a silver bullet, many organizations faced the need to use both together, e.g., one big data lake and multiple, purpose-built data warehouses. This often resulted in increased complexity and costs as data should be kept consistent between the two systems.
The two-tier architecture with a data lake and data warehouses commonly used by organizations
How lakehouses address the challenges of data warehouses and lakes
Basically, it was only a matter of time when the new architecture combining the best of the two worlds would be suggested. In the paper introduced by experts from Databricks, UC Berkeley, and Stanford University at the 11th Conference on Innovative Data Systems Research (CIDR) in 2021, a lakehouse officially became a thing.
It’s claimed that a lakehouse mitigates major limitations of data warehouses and data lakes by offering:
Improved data reliability: Fewer cycles of ETL data transfers between different systems are needed, reducing the chance of quality issues.
Decreased costs: Data won’t be kept in several storage systems simultaneously and ongoing ETL costs will be reduced too.
Data deduplication: The lakehouse system unifies data, eliminating redundancies that are possible if an organization uses a data lake and several data warehouses.
More actionable data: The structure of a lakehouse helps organize big data in a data lake, solving the stagnation problem.
Better data management: Not only can lakehouses keep large volumes of diverse data, but they also allow multiple use cases for it, including advanced analytics, reporting, and machine learning.
Key features of a data lakehouse
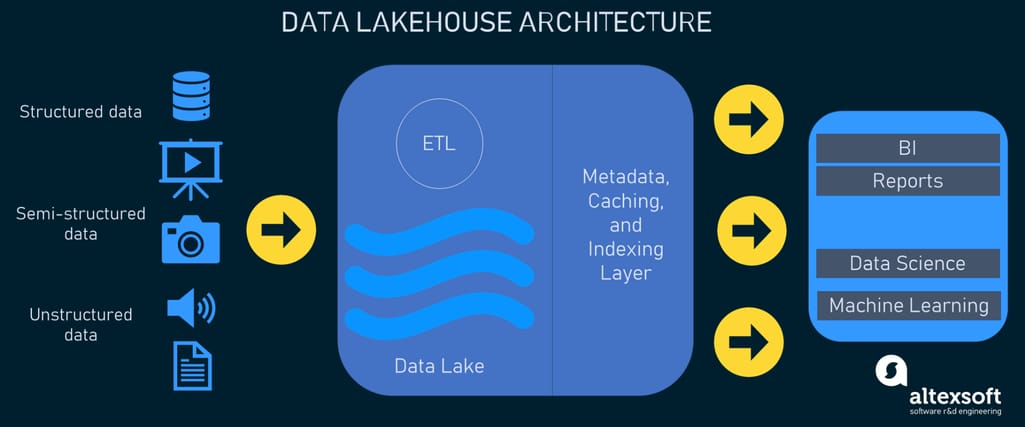
According to the aforementioned paper, the lakehouse architecture is defined as “a data management system based on low-cost and directly-accessible storage that also provides traditional analytical DBMS management and performance features such as ACID transactions, data versioning, auditing, indexing, caching, and query optimization.”
Lakehouse architecture
In simple terms, a lakehouse makes it possible to use data management features that are inherent in data warehousing on the raw data stored in a low-cost data lake owing to its metadata layer.
Let’s go into more detail on the key features of a data lakehouse and problems this concept solves as suggested by Databricks.
ACID transaction support. ACID stands for atomicity, consistency, isolation, and durability — key properties that define a transaction and ensure data consistency and reliability. Such transactions have long been available only in data warehouses, but the lakehouse presents the capability to apply them to data lakes too. This solves the issue with low data quality of the latter when many data pipelines involve concurrent data reads and writes.
Schema enforcement and data governance. With the lakehouse design, users will be able to control the schema of their tables thanks to the support of schema enforcement (to prevent the accidental upload of garbage data) and evolution (to enable automatic adding of new columns). The system is also packed with data governance features including access control and auditing.
Unstructured and streaming data support. Unlike warehouses that can only deal with structured data, lakehouses allow for a wider choice of data formats including video, audio, text documents, PDF files, system logs, etc. Moreover, they support real-time data, e.g., streams from IoT devices.
Open formats support. Open formats are file formats with specifications openly published and usable in multiple software programs. Lakehouses are said to be able to store data in standardized file formats like Apache Parquet and ORC (Optimized Row Columnar).
DataFrame API support. With a data lakehouse, an array of different tools and engines can access the raw data in an object store directly via the DataFrames application programming interface (API). This enables instant data optimization and presentation based on the needs of a certain workload, say machine learning.
Decoupled storage and compute. Similar to some cloud data warehouses, the lakehouse architecture denotes the use of separate clusters for storage and compute. This ensures greater scalability: Various apps and users can run concurrent queries on separate computing nodes while having direct access to the same storage.
Business intelligence support. BI apps can be used directly on the data in a data lake, which eliminates the need of having a copy in a fitting form in a data warehouse.
With this in mind, we’ll move on to describe the architecture layers of data lakehouses.
Data lakehouse architecture designs
The two major proponents championing the idea of a data lakehouse are Databricks (originator and creator of their Delta Lake concept) and AWS. That’s why we will rely on their expertise and vision to explain the architectural pattern of lakehouses.
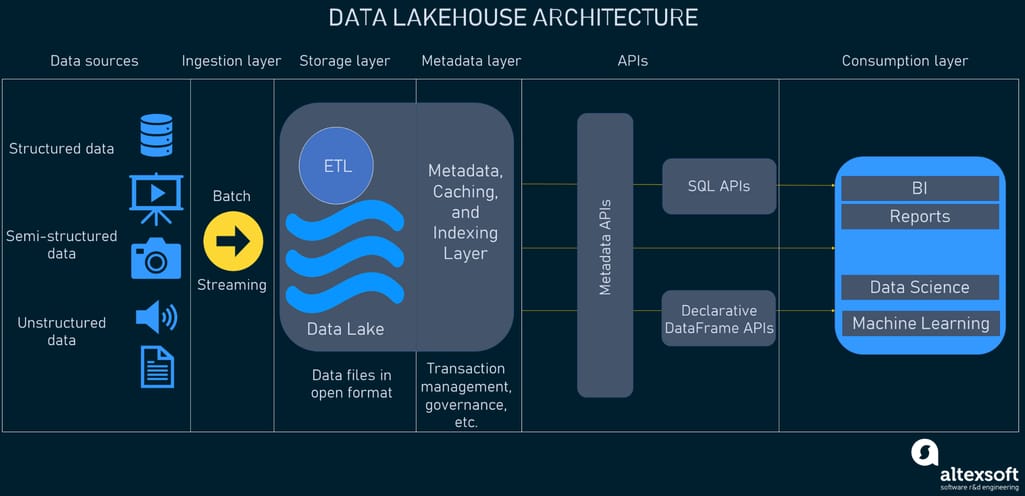
In general, a data lakehouse system will consist of five layers.
Ingestion layer
Storage layer
Metadata layer
API layer
Consumption layer
The multi-layered data lakehouse architecture
Ingestion layer
The first layer in the system takes care of pulling data from a variety of sources and delivering it to the storage layer. Unifying batch and streaming data processing capabilities, the layer may use different protocols to connect to a bunch of internal and external sources such as
Components used at this stage may include Amazon Data Migration Service (Amazon DMS) for importing data from RDBMSs and NoSQL databases, Apache Kafka for data streaming, and many more.
Storage layer
The lakehouse design is supposed to allow keeping all kinds of data in low-cost object stores, e.g., AWS S3, as objects. The client tools then can read these objects directly from the store using open file formats. Thanks to this, multiple APIs and consumption layer components can get to and make use of the same data. The schemas of structured and semi-structured datasets are kept in the metadata layer for the components to apply them to data while reading it.
Lakehouses are best suited for cloud repository services that separate compute and storage, but they can be implemented on-premise, for example over the Hadoop Distributed File System (HDFS) platform.
Metadata layer
The foundation of a data lakehouse that sets this architecture apart is the metadata layer. It’s a unified catalog that provides metadata (data giving information about other data pieces) for all objects in the lake storage and gives users the opportunity to implement management features such as
ACID transactions to ensure that concurrent transactions see a consistent version of the database;
caching to cache files from the cloud object store;
indexing to add data structure indexes for faster query-making;
zero-copy cloning to create copies of data objects; and
data versioning to save specific versions of the data, etc.
As we mentioned earlier, the metadata layer also makes it possible to apply DW schema architectures such as star/snowflake schemas, implement schema management, and provide data governance and auditing functionality directly on the data lake, improving the quality of the whole data pipeline.
Schema management includes schema enforcement and evolution features. Schema enforcement allows users to control data integrity and quality by declining any writes that don't fit the table's schema. Schema evolution enables changes of the table's current schema in compliance with dynamic data. There are also access control and auditing capabilities owing to a single management interface on top of the data lake.
Systems like Delta Lake by Databricks and Apache Iceberg have already executed data management and performance optimizations in this way.
API layer
Here comes another important layer of the architecture that hosts various APIs to enable all end users to process tasks faster and get more advanced analytics. Metadata APIs help understand what data items are required for a particular application and how to retrieve them.
When it comes to machine learning libraries, some of them including TensorFlow and Spark MLlib can read open file formats like Parquet and query the metadata layer directly. At the same time, there are more optimization opportunities available with DataFrame APIs, with the help of which developers can set a structure on and transform distributed data.
Data consumption layer
The consumption layer hosts various tools and apps such as Power BI, Tableau, and others. With the lakehouse architecture, the client apps have access to all data stored in a lake and all metadata. All users across an organization can utilize the lakehouse to carry out all sorts of analytics tasks including business intelligence dashboards, data visualization, SQL queries, and machine learning jobs.
This is one possible data lakehouse design: Experts point out that other structures and technical choices may also be viable based on the use case.
Data lakehouse implementation, challenges, and possible future
With the idea of providing a single point of access for all data within an organization, despite the purposes, data lakehouse has quickly earned buzzword status. Two important questions are left though: When to opt for a data lakehouse? and How to bring this new concept to life? Let’s deal with them.
Below we single out a few instances that may help you define whether a lakehouse is a good fit for your organization or not.
You already use a data lake and want to complement it with SQL performance capabilities while saving money on building and maintaining the two-tier architecture with warehouses.
You want to get rid of data redundancy and inconsistency due to the use of multiple systems.
Your company looks for the versatility of data management and analytics use cases from BI to AI.
You want to improve data security, reliability, and compliance while still keeping big data in the low-cost lake storage.
Of course, there may be other motivations behind moving to a data lakehouse. This list isn’t exhaustive.
That said, if you have determined that the lakehouse landscape meets the needs of your business, where should you go from here?
The relatively simple and fast way to implement the lakehouse architecture is to choose the out-of-the-box product offered by industry vendors. This can be the aforementioned Databricks with their Delta Lake platform — an open, transactional layer that can be built on top of the existing data lakes such as AWS S3, Azure Data Lake Storage, or Google Storage. The product already comes with an open data sharing protocol, open APIs, and many native connectors to different databases, applications, and tools, including Apache Spark, Hive, Athena, Snowflake, Redshift, and Kafka. That all makes it much easier for data engineering teams to build and manage data pipelines.
Despite all the hype around data lakehouses, it’s worth remembering that the concept is still in its infancy. So, do consider some drawbacks before completely jumping into this new architecture.
The monolithic structure of the lakehouse may be difficult to build and maintain. Not to mention that one-size-fits-all designs sometimes entail lower quality functionality than those built for specific use cases.
The additional value brought by the new design of lakehouses has been questioned by critics. Some of them claim that the two-tier architecture with a lake and warehouses can be as efficient when combined with the right automation tools.
The lakehouse concept points toward the use of advanced technology while the modern state of tech doesn't unfold its potential and capabilities.
Taking all of this into account, it’s safe to say that there’s still a considerable amount of work awaiting lakehouses before their wide implementation. According to experts from Databricks, one of the horizons in this area is designing new, more flexible open file formats that would fit the lakehouse system better and power next-generation data workloads. Other explorations involve improved data structures and caching strategies. Optimizations of the storage and metadata layers also add to the research field.