

When you talk about API design, the first thing that probably comes to mind is Representational State Transfer (REST). A standard for data retrieval from the server, it’s based on accessing data by URLs.
In 2000, when REST was developed, client applications were relatively simple, development pace wasn’t nearly where it is today, and, as a result, REST was a good fit for many applications. REST gave us important concepts for API design - stateless servers and structured access to resources. However, since that time APIs have gotten more complex and data-driven affected by the following factors:
- Increased mobile usage created a need for more efficient data loading.
- A variety of different clients: REST makes it difficult to build an API that satisfies their needs, as it returns a fixed data structure.
- Expectations for faster feature development: To make a change on the client side in REST, often we have to adjust the server side to support it, which slows product iterations.
GraphQL, a modern alternative to the REST-based architecture, aims at solving its shortcomings. Unlike REST, GraphQL allows for requesting specific data that a client needs, departing from the fixed data structure approach.
This article introduces the GraphQL toolset and its key features; elaborates on how GraphQL is taking API design architecture to a new level, and in what ways it is still losing to REST.
Read our dedicated article to learn about WebSockets, a communication protocol for creating real-time applications.
What is GraphQL
At its core, GraphQL is a language for querying databases from client-side applications. On the backend, GraphQL specifies to the API how to present the data to the client. GraphQL redefines developers’ work with APIs offering more flexibility and speed to market; it improves client-server interactions by enabling the former to make precise data requests and obtain no more and no less, but exactly what they need.
Initially created by Facebook in 2012, GraphQL was used internally for their mobile applications to reduce network usage by means of its specific data-fetching capabilities. Since GraphQL specifications and reference implementation in JavaScript were open-sourced in 2015, major programming languages now support it, including Python, Java, C#, Node.js, and more. The GraphQL ecosystem is expanding with libraries and powerful tools like Apollo, GraphiQL, and GraphQL Explorer.
Currently, the GraphQL vendor-neutral foundation is emerging. It’ll empower the GraphQL community by:
- increasing financial and intellectual investment for developing infrastructure
- handling legal issues
- providing marketing support to the project
- organizing events, training, and working groups
- enabling widespread adoption and encouraging more contribution.
While GraphQL is still powering API calls at Facebook, it’s used in production by hundreds of other organizations like Credit Karma, GitHub, Yelp, PayPal, The New York Times, and more.
GraphQL basics
A GraphQL server provides a client with a predefined schema - a model of the data that can be requested from the server. In other words, the schema serves as a middle ground between the client and the server while defining how to access the data.
Written down in Schema Definition Language (SDL), basic components of a GraphQL schema - types - describe kinds of object that can be queried on that server and the fields they have. The schema defines what queries are allowed to be made, what types of data can be fetched, and the relationships between these types. You can create a GraphQL schema and build an interface around it with any programming language.
Having the schema before querying, a client can validate their query against it to make sure the server will be able to respond to the query. While the shape of a GraphQL query closely matches the result, you can predict what will be returned. This eliminates such unwelcome surprises as unavailable data or a wrong structure.
Once a GraphQL operation reaches the backend application, it’s interpreted against the entire schema there, and resolved with data for the frontend application.
Query execution in GraphQL
Based on the graph data modeling with the schema at its core, GraphQL has three primary operations:
- Query for reading data
- Mutation for writing data
- Subscription for automatically receiving real-time data over time.
In a nutshell, mainly the progress GraphQL has made is querying in one request, while retrieving only the necessary data instead of the complete set. The main reason for GraphQL being so attractive to developers is its client-driven approach. Handing over control of the data to the clients GraphQL allows them to decide which data to return. Contrarily, REST with its concept everything is a resource faces the problem of over-fetching. Here, the server defines the data available for each resource, while the client has to request all the information in a resource through multiple network requests, even if it needs only a part of it.
GraphQL advantages and disadvantages compared to REST
As they are both specifications for building and consuming APIs, GraphQL and REST have things in common. They both retrieve resources by sending queries, can return JSON data in the request, and be operated over HTTP. Also, REST endpoints are similar to GraphQL fields, as they are entry points into the data that call functions on the server.
However, notable differences start with the conceptual models: While REST is made up of files, GraphQL is constructed of graphs. Further, we’ll talk about how GraphQL differs from REST, and how it changes the developer experience of building and consuming an API.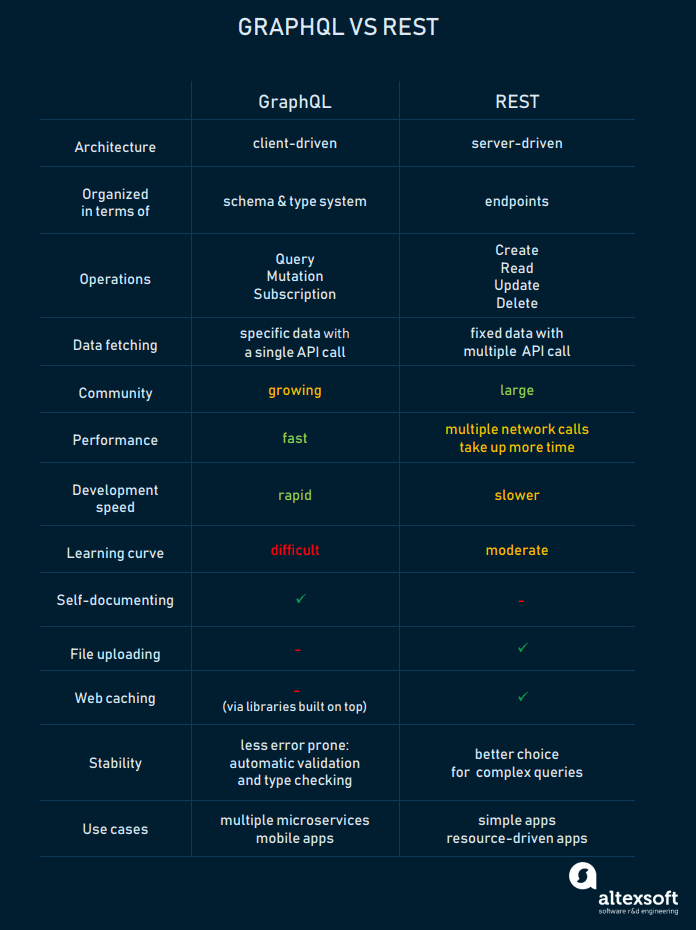
GraphQL and REST technologies compared
GraphQL advantages
Being less “talkative” than REST makes GraphQL way faster, as you can cut down on your request by picking only the fields you want to query. The following list shows other major advantages of using a GraphQL API in an application instead of a REST API.
Good fit for complex systems and microservices. By integrating multiple systems behind its API, GraphQL unifies them and hides their complexity. The GraphQL server is then responsible for fetching the data from the existing systems and packaging it up in the GraphQL response format. This is particularly relevant for legacy infrastructures or third-party APIs that have expanded over the years and now present a maintenance burden.
When migrating from a monolithic backend application to a microservice architecture, a GraphQL API can help handle communication between multiple microservices by merging them into one GraphQL schema. While each microservice defines its own GraphQL schema and has its own GraphQL endpoint, one GraphQL API gateway consolidates all schemas into one global schema.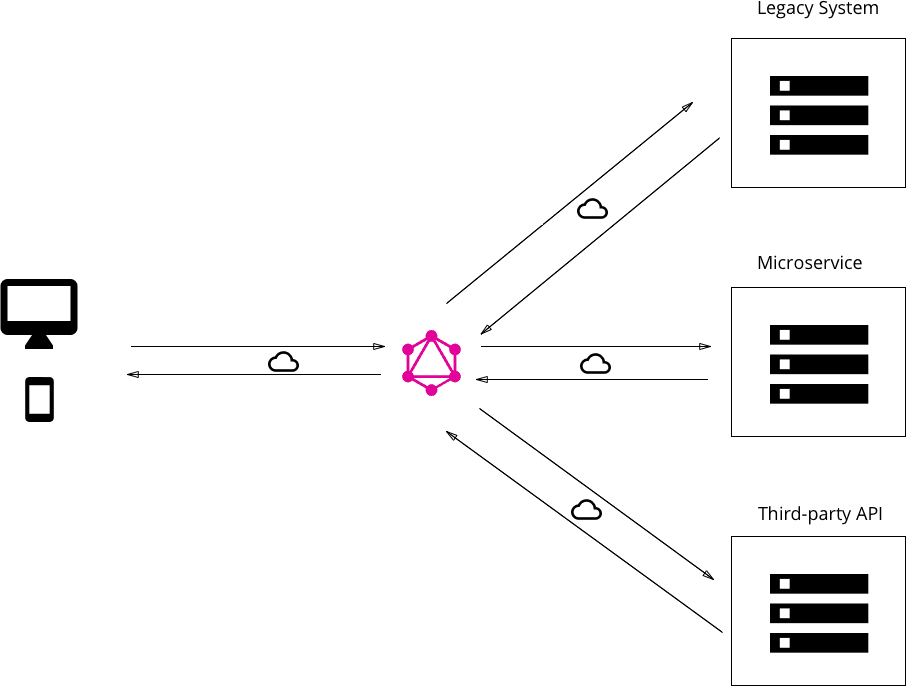
GraphQL aggregating data from multiple places into a single API, Source: How to GraphQL
Fetching data with a single API call. The main difference between GraphQL and REST is that the latter is centered around individual endpoints, so to collect all needed data, a developer has to combine multiple endpoints. Whereas GraphQL focuses on the task itself, in this case, a developer can request the needed data with just one API call.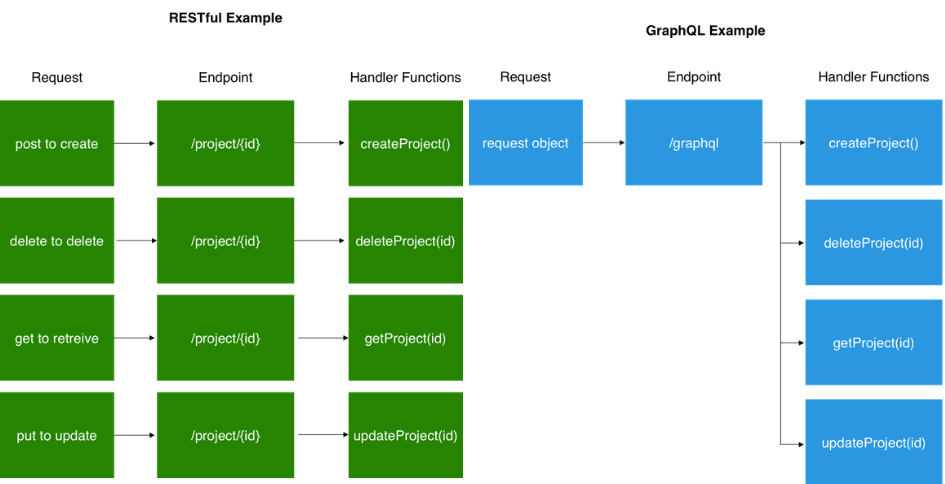
Fetching resources with multiple REST requests vs. a single GraphQL request, Source: Jeff Lombard
No over- and under-fetching problems. REST responses are known for either containing too much data or not enough of it, creating the need for another request. GraphQL solves this efficiency problem by fetching the exact data in a single request.
Tailoring requests to your needs. As it was mentioned, REST API documentation explains individual endpoints, their functions, and the parameters a developer can pass to them. Describing the data types, fields, and the interaction points between them, GraphQL API enables developers to tailor the request to get the information they need.
Validation and type checking out-of-the-box. GraphQL's introspection feature allows for navigating into the types and discovering the schema to ensure apps only ask for what’s possible and in the appropriate format. That said, developers can see what the schema can query and how the data is set up there. Based on that, they can easily add new fields to existing queries through a GraphQL IDE. There’s no need to validate the data format, as GraphQL does it for you. Developers need only to write resolvers - how the data will be received.
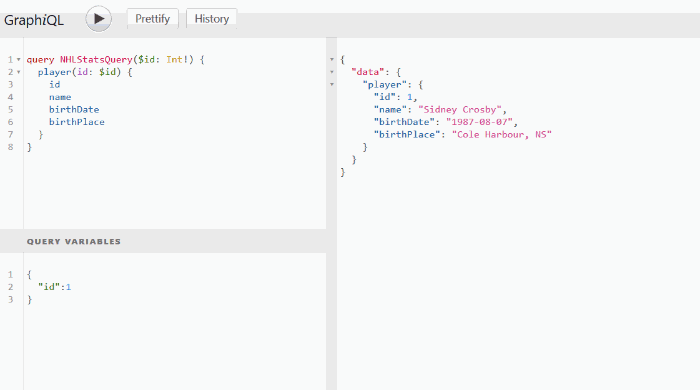 In GraphQL a developer can view the available data before making the request, Source: FullStack Mark
In GraphQL a developer can view the available data before making the request, Source: FullStack Mark
Autogenerating API documentation. GraphQL keeps documentation in sync with API changes. As the GraphQL API is tightly coupled with code, once a field, type or query changes, so do the docs. This directly benefits developers, since they have to spend less time documenting an API.
API evolution without versioning. Evolving API entails a problem of having to keep the old version around until developers make the transition to the new one. So, with REST it’s common to offer multiple API versions. However, GraphQL eliminates the need for versioning by deprecating APIs on a field level. Aging fields can be later removed from the schema without impacting the existing queries. GraphQL enables that by creating a uniform API across the entire application that isn’t limited by a specific storage engine.
By using a single, evolving version, GraphQL APIs give apps continuous access to new features and encourage cleaner, more maintainable server code.
Code-sharing. In GraphQL fields used in multiple queries can be shared at a higher component level for reuse. Referred to as fragments, this feature allows you to get different data while keeping the same schema field.
Detailed error messages. In REST, we simply check the HTTP headers for the status of a response, based on which we can determine what went wrong and how to handle it. Contrarily, if there is an error while processing GraphQL queries, the backend will provide a detailed error message including all the resolvers and referring to the exact query part at fault.
GraphQL error messages don’t have a particular standard, so you can choose - be it a stack trace, an application-specific error code, or just plain text.
Permissions. Creating a GraphQL schema, you get to choose which functions to expose and how they work. In their turn, REST views tend to be all or nothing. So, every view should have knowledge of what can and cannot be exposed in various circumstances, which isn’t that simple to do. Otherwise, if a query includes some private information, REST architecture won’t even reveal public portions of the requested data.
An additional operation. In REST, APIs perform CRUD operations with the following HTTP requests:
- CREATE: generate new records with POST
- READ: retrieve the data based on input parameters with GET
- UPDATE: modify records with PUT
- DELETE: erase the specified data with DELETE.
In that way, GraphQL brings a new operation to the table - subscriptions, - which allows clients to receive real-time messages from the server. GraphQL subscriptions can be used for automatically sending notifications to the client when a new comment or data is added, or a message is received.
Rapid application prototyping. If the goal is to provide a prototype, CRUD operations can be time-consuming. GraphQL speeds up this process by providing a single API endpoint that serves as a data proxy between the UI and the data storage. Additionally, the velocity of development is closely related to improved developer experience that GraphQL offers: easier coding with the data right next to UI, reusable fragments, less thinking of error handling, etc.
GraphQL disadvantages
Although GraphQL is a decent alternative to REST, it’s not a replacement yet. We’d like to point out that sending data-specific queries can be also implemented in REST with the help of many JSON API libraries. For using a schema and strong types in REST, JSON schemas will come in handy. On the other hand, implementing these libraries can be complicated and that’s why using GraphQL might be a better idea, as it natively supports all of these features.
Performance issues with complex queries. While enabling clients to request exactly what they need, GraphQL query can encounter performance issues if a client asks for too many nested fields at once. So, to be on the safe side, it might be worth using a REST API for complex queries: Retrieve the data by means of multiple endpoints with fine-tuned, specific queries. Although multiple network calls can also take up a lot of time, it’ll be safer from the server maintenance perspective.
If sticking to GraphQL, a way out is to use rate-limiting mechanisms for stopping inefficient requests from the other side: maximum query depths, query complexity weighting, avoiding recursion, or persistent queries.
Overkill for small applications. While GraphQL is the right solution for multiple microservices, you’d better go for REST architecture in case of a simple app. REST can be also a valuable approach for connecting resource-driven apps that don’t need the flexible queries offered by GraphQL.
Web caching complexity. GraphQL caching at the database or client level can be implemented with the Apollo or Relay clients that have caching mechanisms built in. However, GraphQL doesn't rely on the HTTP caching methods, which enable storing the content of a request. Caching helps reduce the amount of traffic to a server by keeping frequently accessed information close to the client.
By providing many endpoints, a REST API enables easy web caching configurations to match certain URL patterns, HTTP methods, or specific resources. Due to having only one endpoint with many different queries, it’s much harder to use this type of caching with a GraphQL API. The problem can be partially solved by using persisted GraphQL queries that assist in producing a JSON file for mapping queries and identifiers. Having this map, a client only sends the identifier and the parameters of a query to the server, and it just looks them up.
Alternatively, a caching issue can be solved with a batching technique that collects multiple requests for data from a backend, and then dispatches in a single request using a tool like Facebook's DataLoader.
File uploading. Since GraphQL doesn't understand files, a file uploading feature is not included in its specification. You won’t have to deal with this limitation in case of REST, as there you can POST or PUT whatever content you want to.
To allow file uploads in your GraphQL web app, there are several options:
- using Base64 encoding. But it will make the request larger and expensive to encode/decode.
- making a separate API endpoint just for this purpose.
- using a library like Apollo for implementing the GraphQL multipart request specification.
Takes a while to understand. With GraphQL, be prepared to have a lot of pre-development education like learning the Schema Definition Language. As not every project has the time and resources to get properly acquainted with GraphQL, they may go for REST as it offers less complexity. While offering nice convenience operations, understanding and implementing simple GraphQL queries can burn some time.
GraphQL tools and ecosystem: getting started
The GraphQL ecosystem is growing at a high speed both horizontally by offering multiple programming languages, and vertically, with libraries on top of GraphQL. Open source communities and entrepreneuring startups alike are contributing by building and improving the tools for using GraphQL. They validate new GraphQL use cases, fill in GraphQL implementation gaps, and enable more developers to adopt GraphQL practices.
Within a basic app comprised of a client, a server, and a data layer, GraphQL comes into play four times: GraphQL client, GraphQL gateway, GraphQL server, and database-to-GraphQL server. In this section, we’ll learn the most useful tools for each of these components that make working with GraphQL much easier.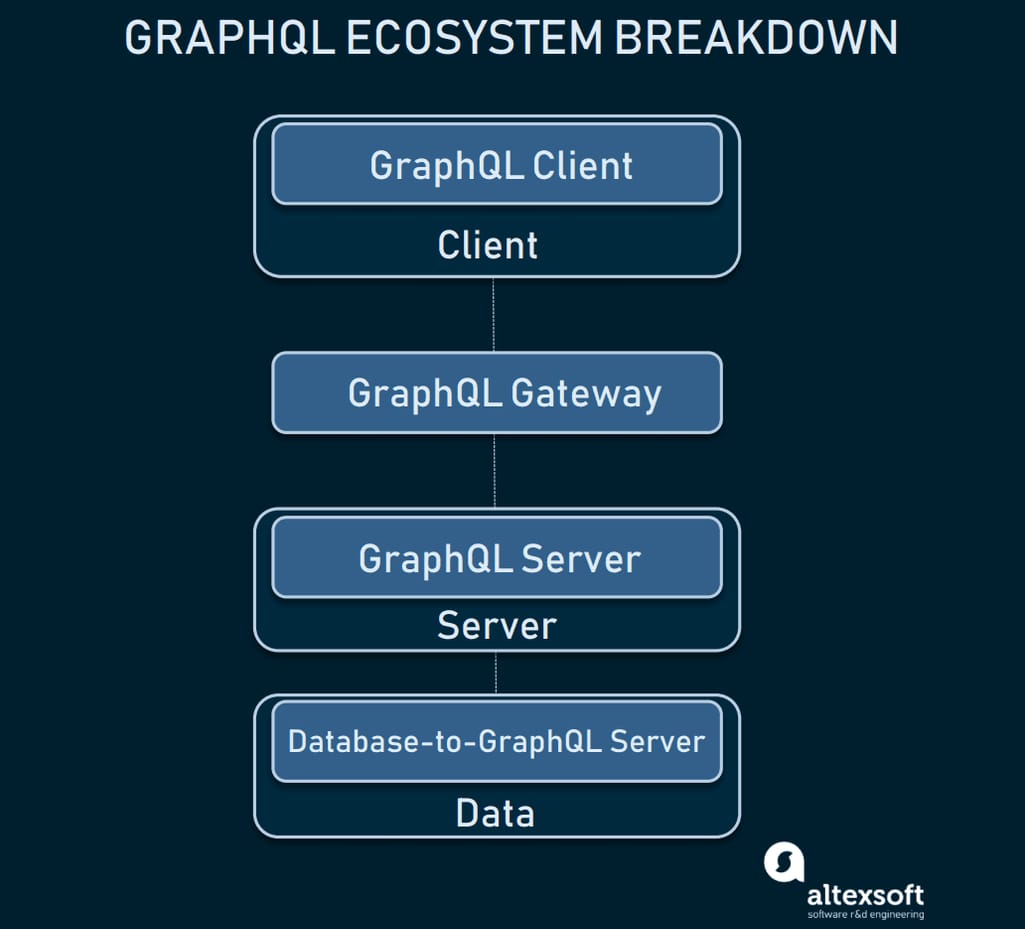
GraphQL ecosystem within an application: key components
GraphQL servers
First thing you need to get going with a GraphQL API is a server that receives queries from the client and responds with data.
Apollo Server. Apollo is one of the most popular choices for using GraphQL in JavaScript applications. Building its ecosystem on top of GraphQL, Apollo provides a large ecosystem of libraries for both client- and server-side that solve many GraphQL challenges. Apollo Server can be queried from any GraphQL client.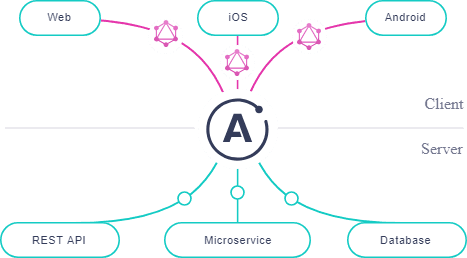
Apollo ecosystem built on top of GraphQL
GraphQL Ruby enables a Ruby implementation of GraphQL.
GraphQL Yoga. Developed by Prisma, this fully-featured GraphQL server has a number of configurations that improve developer experience. GraphQL Yoga was built on Express and Apollo servers, well-established node servers, and GraphQL middleware libraries.
GraphQL clients
Libraries that construct queries and send them to the server.
Apollo Client caches requests and normalizes data saving valuable network traffiс. Beyond that, Apollo Client comes with many more features like error management, support for pagination and optimistic UI, prefetching of data, and connection of the data layer to the view layer.
Relay. An alternative to Apollo Client, Relay is Facebook’s JavaScript library for consuming GraphQL to build data-driven React applications.
DataLoader is a generic utility to be used as a part of your application's data-fetching layer to provide a consistent API over various backends and reduce requests to those backends via batching and caching.
GraphQL Request. A minimal GraphQL client supporting Node and browsers for scripts or simple apps.
GraphQL gateways
Placed on top of the server or as a standalone proxy to route to the server, GraphQL gateway offers additional features to find issues with your API much faster, and improve performance.
Apollo Engine is the most popular GraphQL-specific gateway. Its features are:
- query execution tracing: provides the entire route of the query
- query caching
- error tracking
- trend analysis: tracks the performance of the API over time.
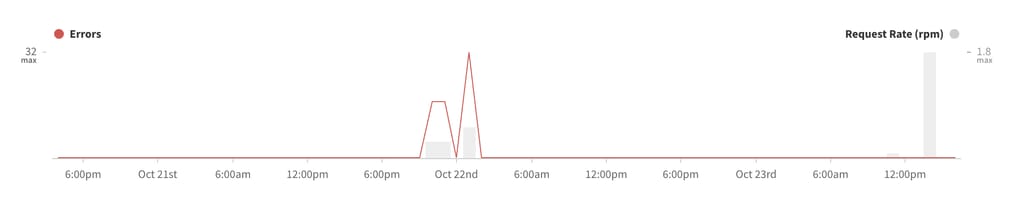 Apollo Engine’s error tracking graph
Apollo Engine’s error tracking graph
Database-to-GraphQL servers
Connecting the database and the GraphQL server, these tools provide powerful features that save time writing SQL queries in your resolvers and simplify complex database operations. Popular options are:
- Prisma
- PostGraphile
- Neo4j-GraphQL: specific for the Neo4j database.
GraphQL IDEs
An Integrated Development Environment (IDE) maximizes developer productivity with things like debugging, code completion, compiling, and interpreting abilities. A GraphQL IDE runs in the browser, where the developer can also run queries and mutations. Here are the most popular GraphQL IDEs.
GraphQL Playground. A powerful IDE for better development workflows that makes real-time requests to the schema, its features include interactive docs, an editor for GraphQL queries, tracing, sharing playgrounds, mutations and subscriptions, validation, etc.
Powered by introspection, GraphQL Playground can quickly visualize the structure of a schema. It also can display your query history or lets you work with multiple GraphQL APIs side-by-side.
GraphiQL interacts with GraphQL API calls, enables data querying and performing mutations. By enabling interactive exploration of schemas, this in-browser IDE built on React helps to figure out what query to write in a much more productive way than typical API docs. GraphiQL auto-completes queries as you type them into the editor and automatically generates documentation based on GraphQL’s type system. This directly serves developer needs while relieving the maintenance burden.
GraphQL IDE. As an extensive alternative to GraphiQL, GraphQL IDE offers additional project management features, custom and dynamic headers, import/export abilities, and the ability to store queries and view a query history.
GraphQL useful tooling
Hygraph. This API-centric Content Management System (CMS) provides tooling to manage content structures that require programmatically sharing data. Being API-equipped, Hygraph offers a more flexible management layer for end user interfaces than traditional CMSs.
GraphQL Docs quickly generates simple, functional documentation given a GraphQL endpoint URL. GraphDoc is an alternative that is good for generating and hosting GraphQL docs on your own.
GraphQL Network is a Chrome devtool with a “network”-style tab allowing for easy debugging.
GraphQL Bindings. This auto-generated software development kit enables reusing and sharing GraphQL APIs as modular building blocks.
GraphQL CLI is a command line tool for common GraphQL development workflows.
GraphQL Boilerplates is a flexible starter kit for backend-only and fullstack GraphQL projects.
GraphQL Config. Supported by most tools, editors, and IDEs, GraphQL Config lets you easily configure the dev environment with your GraphQL schema.
GraphQL Voyager. By running data through this tool, you’ll be able to visualize data relations, as GraphQL Voyager represents GraphQL APIs as interactive graphs. On setting a root schema, you can view field-type connections and quickly navigate through them.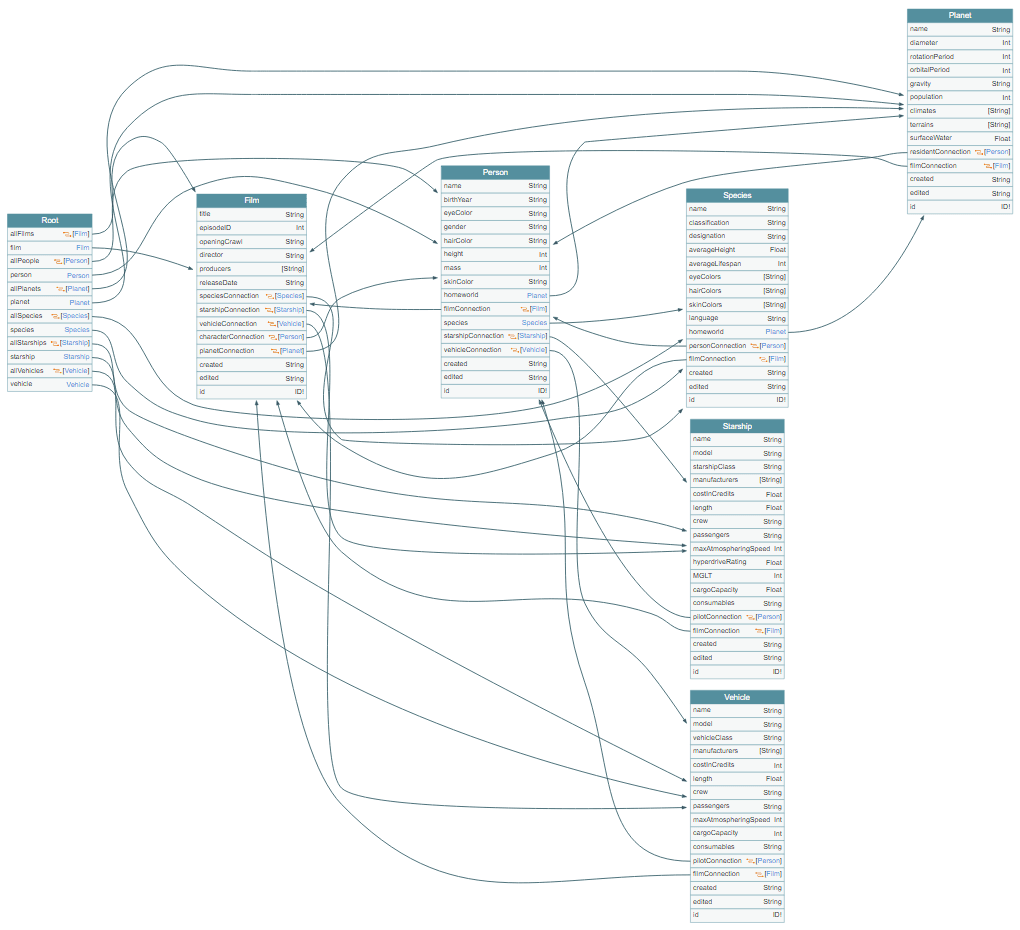
The Star Wars API (SWAPI) visually represented in GraphQL Voyager
Putting it together
As you can see, it would be very wrong to say GraphQL can replace REST, as the former is merely a tool, while the latter is an architectural pattern. Instead, there’re unique interaction scenarios in which one or the other fits better.
In situations when a requester needs the data in a specific format for a specific use, data formats and the relations between them are vitally important. In such cases, no other solution can provide the same level of interconnected provision of data as GraphQL.
Find out more about GraphQL vs RPC vs REST and SOAP architectural styles in a dedicated article.

Maryna is a passionate writer with a talent for simplifying complex topics for readers of all backgrounds. With 7 years of experience writing about travel technology, she is well-versed in the field. Outside of her professional writing, she enjoys reading, video games, and fashion.
Want to write an article for our blog? Read our requirements and guidelines to become a contributor.