

The best trained soldiers can’t fulfill their mission empty-handed. Data scientists have their own weapons — machine learning (ML) software. There is already a cornucopia of articles listing reliable machine learning tools with in-depth descriptions of their functionality. Our goal, however, was to get the feedback of industry experts.
And that's why we interviewed data science practitioners — gurus, really —regarding the useful tools they choose for their projects. The specialists we contacted have various fields of expertise and are working in such companies as Facebook and Samsung. Some of them represent AI startups (Objection Co, NEAR.AI, and Respeecher); some teach at universities (Kharkiv National University of Radioelectronics). The AltexSoft data science team joined the discussion, too.
And if you're looking for a particular type of machine learning tools, just skip to your sector of interest:
Machine learning languages
Data analytics and visualization tools
Frameworks for general machine learning
Frameworks for neural network modeling
The most popular machine learning languages
You're in an ethnic restaurant and you're not familiar with the culture. You'll probably ask the waiter some questions about the words on the menu, what they mean, even before you find out what utensils you'll be using. So, before talking about data scientists’ favorite tools, let’s figure out what programming languages they use.
Python: a popular language with high-quality machine learning and data analysis libraries
Python, a general-purpose language favored for its readability, good structure, and a relatively mild learning curve continues gaining its popularity. According to the Annual Developer Survey by Stack Overflow conducted in January, Python can be called the fastest-growing major programming language. It’s ranked the seventh most popular language (38.8 percent), and now is one step ahead of C# (34.4 percent).
Head of research in Respeecher Grant Reaber, who specializes in deep learning applied to speech recognition, uses Python as “almost everyone currently uses it for deep learning. Swift for TensorFlow sounds like a cool project, but we will wait until it’s more mature before thinking about using it,” concludes Grant.
Co-founder of the NEAR.AI startup who previously managed a team in Google Research on deep learning for NLU Illia Polosukhin also sticks with Python: “Python was always a language of data analysis, and, over the time, became a de-facto language for deep learning with all modern libraries built for it.”
One of the use cases of Python machine learning is model development and particularly prototyping.
Data science competence leader at AltexSoft Alexander Konduforov says he uses it primarily as a language for building machine learning models.
Vitaliy Bulygin, the lead engineer at Samsung Ukraine, considers Python one of the best languages for fast prototyping. “During prototyping, I find the optimal solution and rewrite it in a language required for a project, for example, C++,” explains the specialist.
Facebook AI researcher Denis Yarats notes that this language has an amazing toolset for deep learning like PyTorch framework or NumPy library (which we’ll discuss later in the article).
C++: a middle-level language used for parallel computing on CUDA
C++ is a flexible, object-oriented, statically-typed language based on the C programming language. The language remains popular among developers thanks to its reliability, performance, and the large number of application domains it supports. C++ has both high-level and low-level language features, so it is considered a middle-level programming language. Another application of this language is the development of drivers and software that can directly interact with hardware under real-time constraints. And since C++ is clean enough for the explanation of basic concepts, it's used for research and teaching.
Data scientists use this language for diverse yet specific tasks. Andrii Babii, a senior lecturer at the Kharkiv National University of Radioelectronics (NURE), uses C++ for parallel implementations of algorithms on CUDA, an Nvidia GPU compute platform, to speed up applications based on those algorithms.
“I need C++ when I write my custom kernels for CUDA,” adds Denis Yarats.
R: a language for statistical computing and graphics
R, a language and environment for statistics, visualizations, and data analysis, is a top pick for data scientists. It’s another implementation of the S programming language.
R and libraries written in it provide numerous graphical and statistical techniques like classical statistical tests, linear and nonlinear modeling, time-series analysis, classification, clustering, and etc. You can easily extend the language with R machine learning packages. The language allows for creating high-quality plots, including formulae and mathematical symbols.
Alexander Konduforov notes machine learning with R enables fast data analysis and visualizations.
Data analytics and visualization tools
pandas: a Python data analysis library enhancing analytics and modeling
It’s time to talk a little about Python pandas, a free library with the cutest name. Data science devotee Wes McKinney developed this library to make data analysis and modeling convenient in Python. Prior to pandas, this programming language worked well only for data preparation and munging.
pandas simplifies analysis by converting CSV, JSON, and TSV data files or a SQL database into a data frame, a Python object looking like an Excel or an SPSS table with rows and columns. Even more, pandas is combined with the IPython toolkit and other libraries to enhance performance and support collaborative work.
matplotlib: a Python machine learning library for quality visualizations
matplotlib is a Python 2D plotting library. Plotting is a visualization of machine learning data. matplotlib originates from MATLAB: Its developer John D. Hunter emulated plotting commands from Mathworks’ MATLAB software.
While written mostly in Python, the library is extended with NumPy and other code, so it performs well even when used for large arrays.
matplotlib allows for generating production-quality visualizations with a few lines of code. The library developer highlighted how simple it is in use: ”If you want to see a histogram of your data, you shouldn’t need to instantiate objects, call methods, set properties, and so on; it should just work.”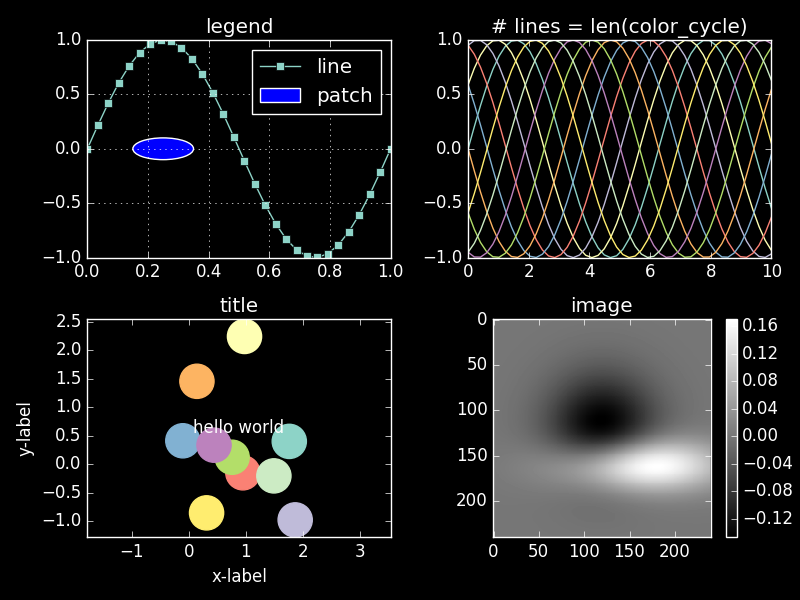
matplotlib visualization demo. Image source: matplotlib Style Gallery
The library’s functionality can be extended with third-party visualization packages like seaborn, ggplot, and HoloViews. Specialists can also add extra features using Basemap and cartopy projection and mapping toolkits.
Data science practitioners note matplotlib flexibility and integration capabilities. Andrii Babii, for instance, prefers using matplotlib with seaborn and ggplot2.
Denis Yarats (Facebook AI Research) says he chooses matplotlib mostly because it’s integrated well into the Python toolset and can be used with the NumPy library or PyTorch machine learning framework.
Alexander Konduforov and his AltexSoft team also use matplotlib. Besides numerous Python machine learning libraries like pandas, as well as Plotly that supports both R and Python, the team chooses dplyr, ggplot2, tidyr, and Shiny R libraries. “These tools are free to use, but you have to know programming at least a little to use them, and sometimes it takes extra time.”
Jupyter notebook: collaborative work capabilities
The Jupyter Notebook is a free web application for interactive computing. With it, users can create and share documents with a live code, develop and execute code, as well as present and discuss task results. A document can be shared via Dropbox, email, GitHub, and Jupyter Notebook Viewer, and it can contain graphics and narrative text.
The notebook is rich in functionality and provides various use scenarios.
It can be integrated with numerous tools, such as Apache Spark, pandas, and TensorFlow. It supports more than 40 languages, including R, Scala, Python, and Julia. Besides these capabilities, Jupyter Notebook supports container platforms — Docker and Kubernetes.
Illia Polosukhin from NEAR.AI shares that he uses Jupyter Notebook mostly for custom ad-hoc analysis: “The application allows for doing any data or model analysis quickly, with the ability to connect to a kernel on a remote server. You can also share a resulting notebook with colleagues.”
Tableau: powerful data exploration capabilities and interactive visualization
Tableau is a data visualization tool used in data science and business intelligence. A number of specific features make this software efficient for solving problems in various industries and data environments.
Through data exploration and discovery, Tableau software quickly extracts insights from data and presents them in understandable formats. It doesn’t require excellent programming skills and can be easily installed on all kinds of devices. While a little script must be written, most operations are done by drag and drop.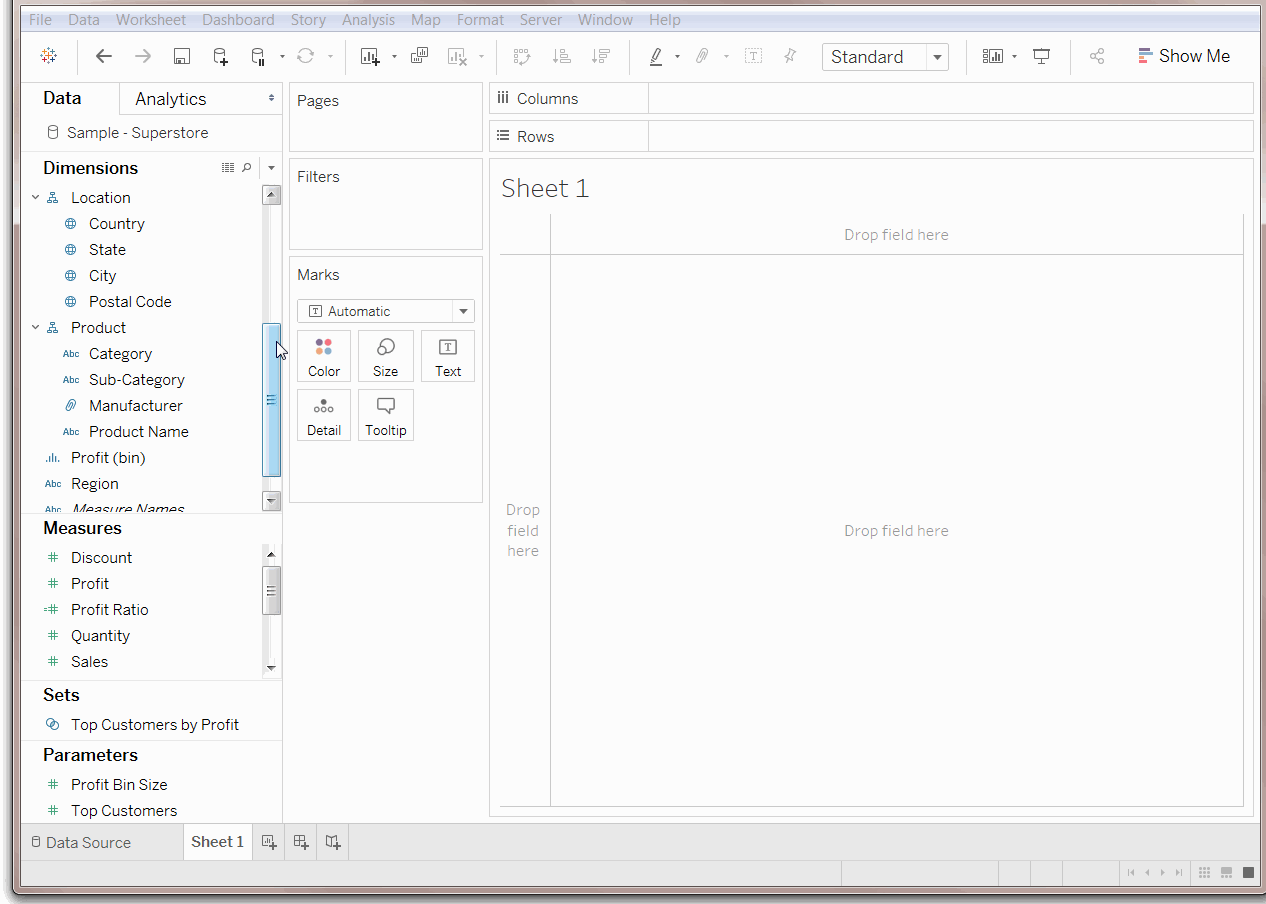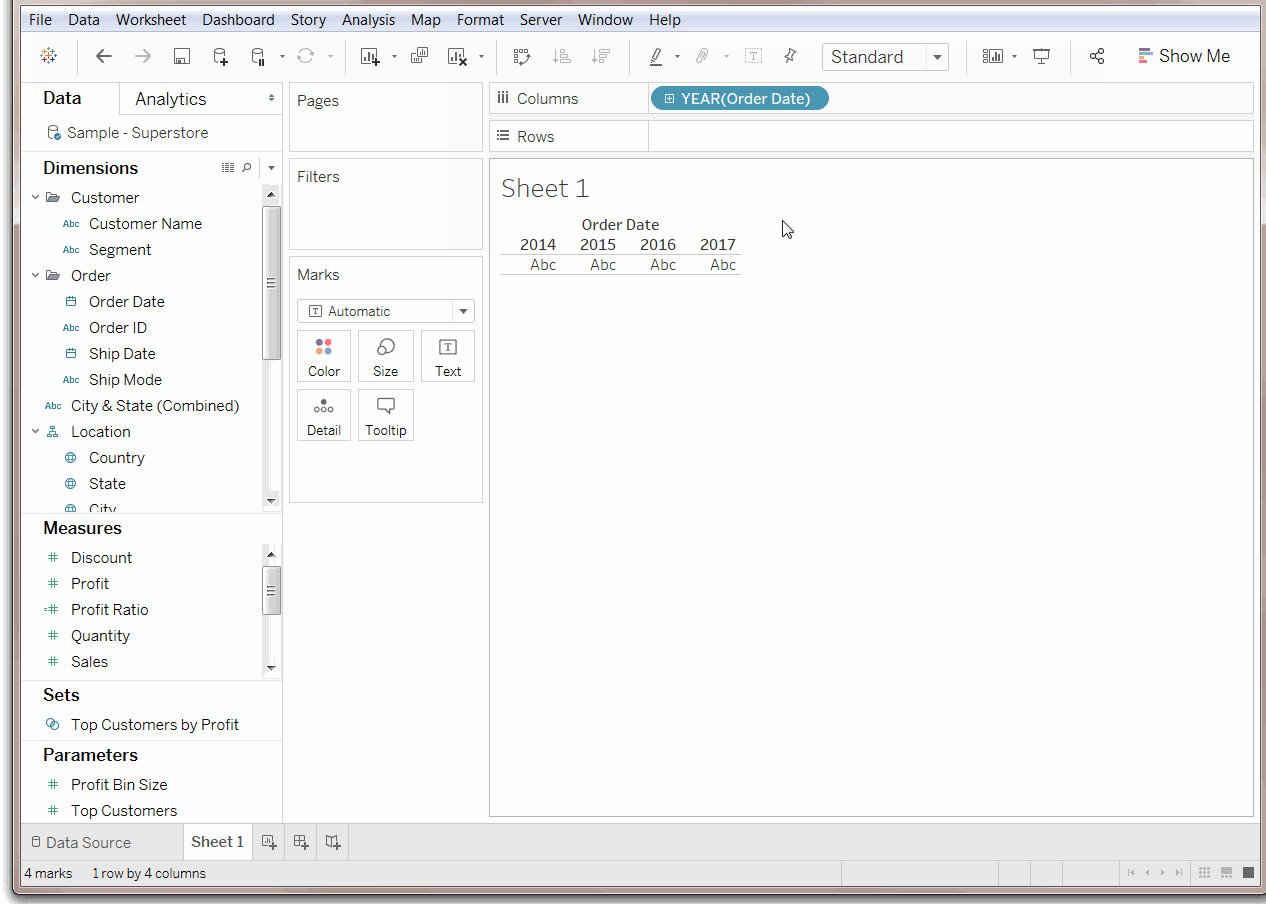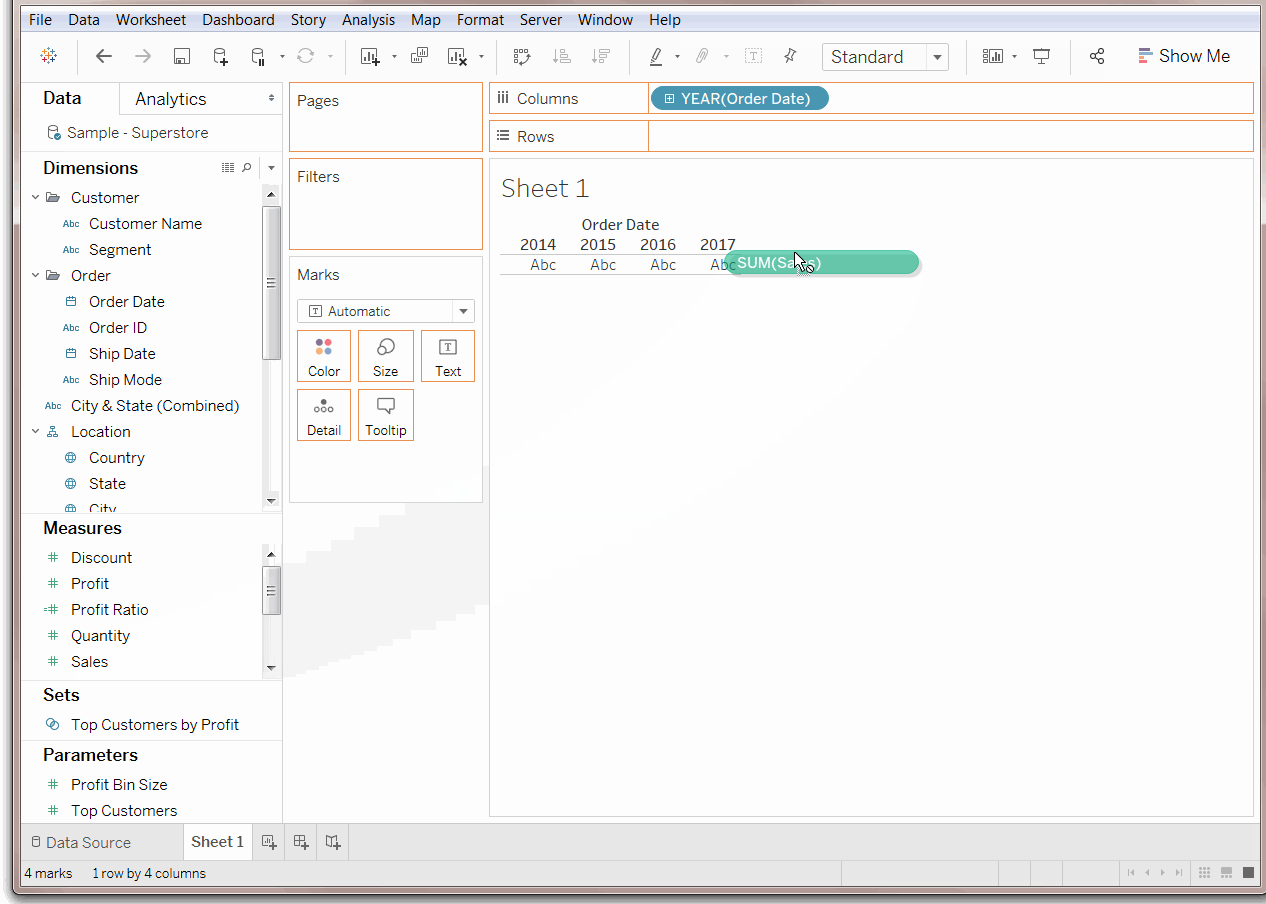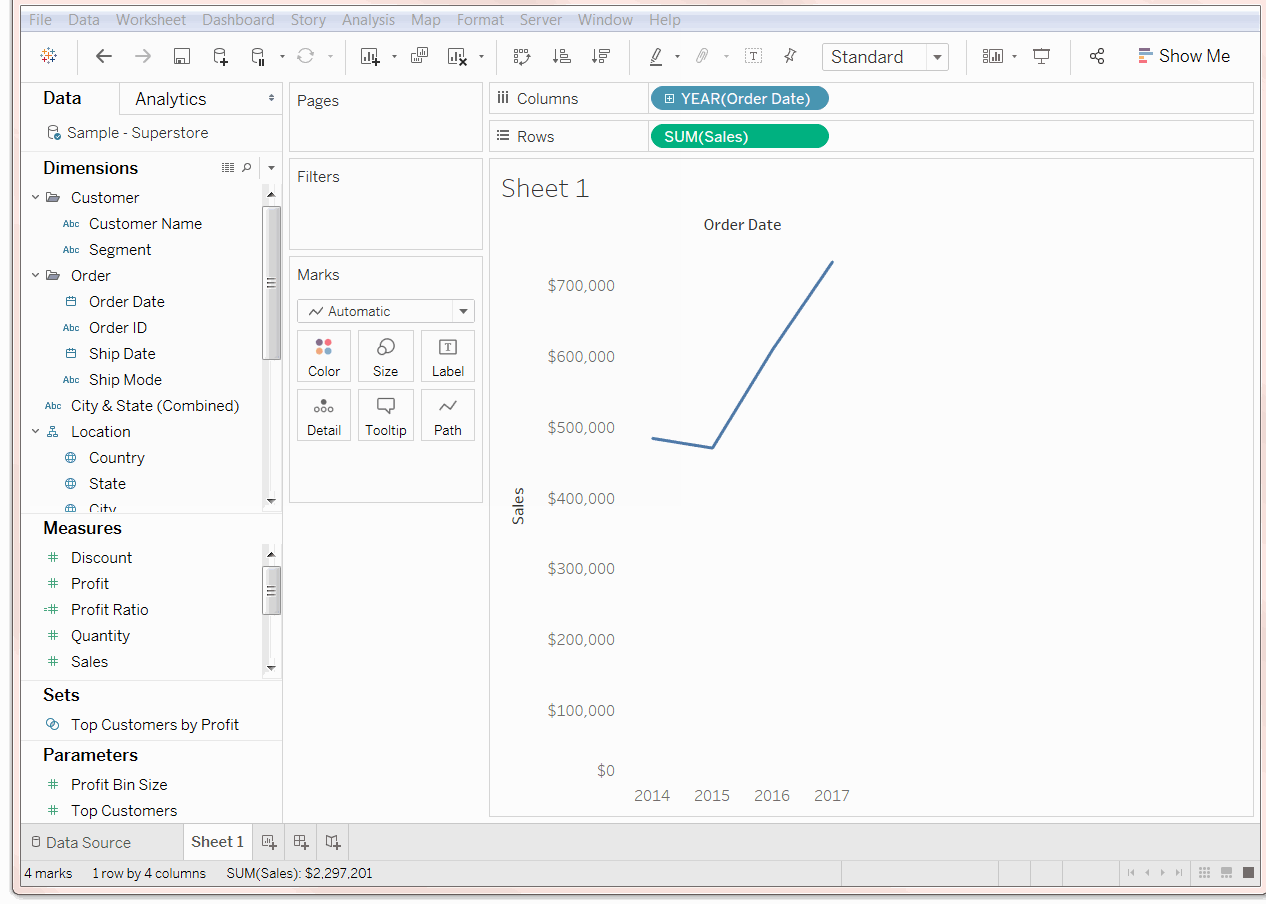
How the Tableau drag-and-drop menu works
Tableau supports real-time analytics and cloud integration (i.e. with AWS, Salesforce, or SAP), allows for combining different datasets and centralized data management.
The simplicity of use and its set of features are the reasons data scientists choose this tool. “Tableau has many built-in features and doesn’t require coding. You can do a lot of data preprocessing, analysis, and visualization in UI, which saves a lot of effort. However, you have to buy a license since it’s not a free product,” says Alexander Konduforov.
Frameworks for general machine learning
NumPy: an extension package for scientific computing with Python
Previously mentioned NumPy is an extension package for performing numerical computing with Python that replaced NumArray and Numeric. It supports multidimensional arrays (tables) and matrices. ML data is represented in arrays. And a matrix is a two-dimensional array of numbers. NumPy contains broadcasting functions as tools for integrating C/C++ and the Fortran code. Its functionality also includes the Fourier transform, linear algebra, and random number capabilities.
Data science practitioners can use NumPy as an effective container for storage of multidimensional generic data. Through the ability to define arbitrary data types, NumPy easily and quickly integrates with numerous kinds of databases.
scikit-learn: easy-to-use machine learning framework for numerous industries
scikit-learn is an open source Python machine learning library build on top of SciPy (Scientific Python), NumPy, and matplotlib.
Initially started in 2007 by David Cournapeau as a Google Summer of Code project, scikit-learn is currently maintained by volunteers. As of today, 1,092 people have contributed to it.
The library is designed for production use. The simplicity, qualitative code, collaboration options, performance, and extensive documentation written in plain language contribute to its popularity among various specialists.
scikit-learn provides users with a number of well-established algorithms for supervised and unsupervised learning. Data science practitioner Jason Brownlee from Machine Learning Mastery notes that the library focuses on modeling data but not on its loading, manipulation, and summarization. He suggests using NumPy and pandas for these three features.
Denis Yarats uses NumPy, pandas, and scikit-learn for general machine learning: “I like their simplicity and transparency. It also helps that these tools are widely adopted and have been battle tested for many years by many people.”
"The AltexSoft data science team mostly uses Python libraries like scikit-learn and xgboost for classification and regression tasks," observes Aleksander.
Andrii Babii prefers to use scikit-learn with R language libraries and packages. “I'm using this combination because it open source, has very reach functions and complement each other,” explains the data scientist.
NLTK: Python-based human language data processing platform
NLTK is a platform for the development of Python programs to work with human language.
Aleksander Konduforov prefers this tool for NLP tasks. “NLTK is a pretty much a standard library in Python for text processing which has many useful features. For example, different types of text, sentences and words processing, part of speech tagging, sentence structure analysis, named entity recognition, text classification, sentiment analysis, and many others. All these libraries are free and provide enough functionality for solving a majority of our tasks, ” the expert notes.
ML frameworks for neural network modeling
TensorFlow: flexible framework for large-scale machine learning
TensorFlow is an open source software library for machine learning and deep neural network research developed and released by the Google Brain Team within Google’s AI organization in 2015.
A significant feature of this library is that numerical computations are done with data flow graphs consisting of nodes and edges. Nodes represent mathematical operations, and edges are multidimensional data arrays or tensors, on which these operations are performed.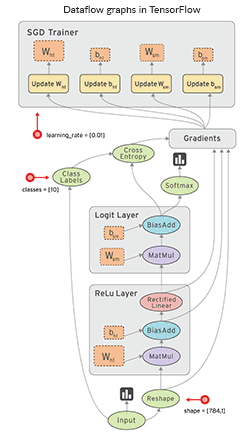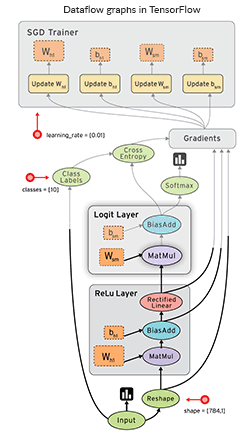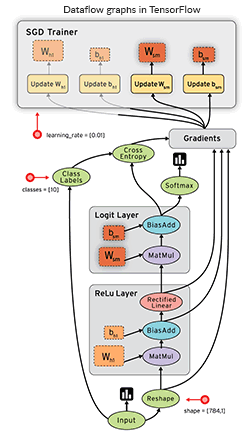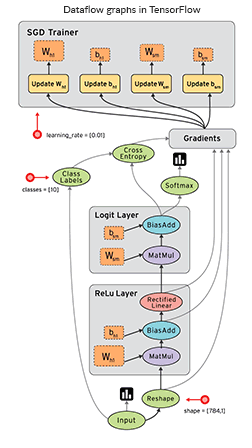
Visualization of data flow between operations in TensorFlow
TensorFlow is flexible and can be used across various computation platforms (CPUs, GPUs, and TPUs) and devices, from desktops to clusters of servers to mobile and edge systems. It runs on Mac, Windows, and Linux.
Another advantage of this framework is that it works both for research and recurring machine learning tasks.
TensorFlow is rich in development tools, particularly for Android. Samsung Ukraine's lead engineer Vitaliy Bulygin suggests, “If you need to implement something on Android, use TensorFlow.”
Curtis Boyd, CEO of Objection Co, provider of an automated bad-review removal strategy for businesses, says his team chose to do machine learning with TensorFlow because it's open sourced and very easy to integrate with.
TensorBoard: a good tool for model training visualization
TensorBoard is a suite of tools for graphical representation of different aspects and stages of machine learning in TensorFlow.
TensorBoard reads TensorFlow event files containing summary data (observations about a model’s specific operations) being generated while TensorFlow is running.
A model structure shown with graphs allows researchers to make sure model components are located where needed and are connected correctly.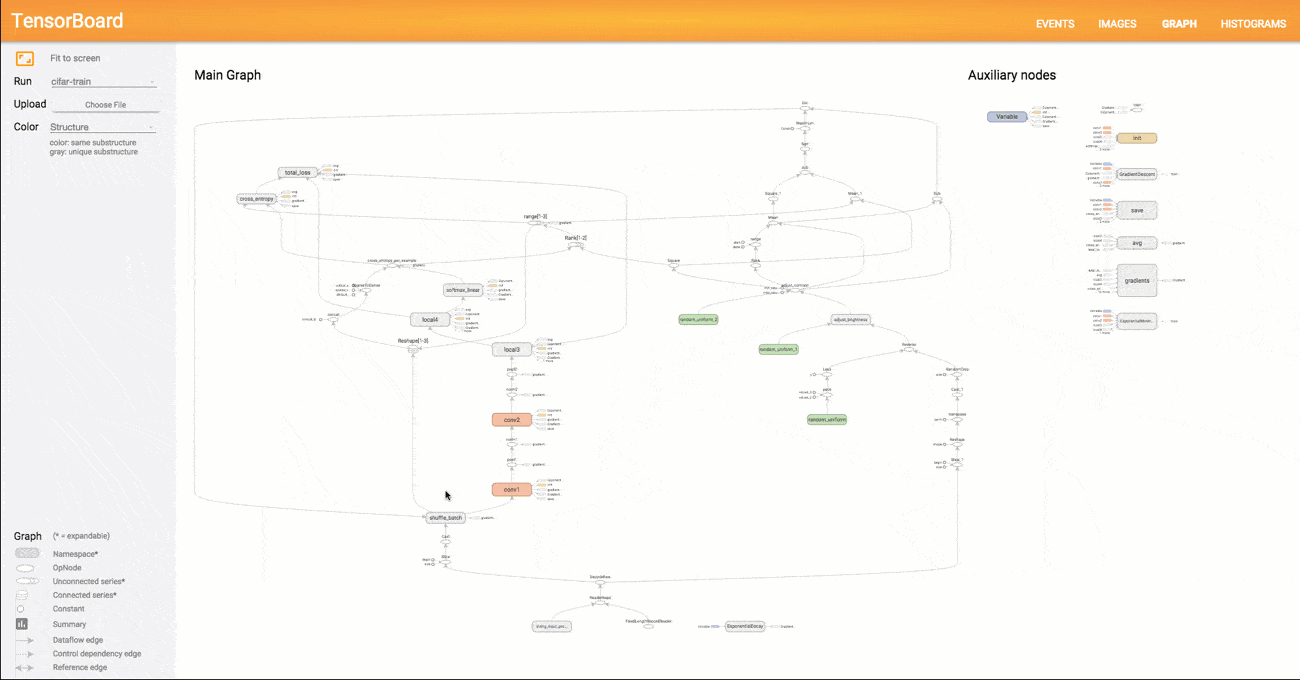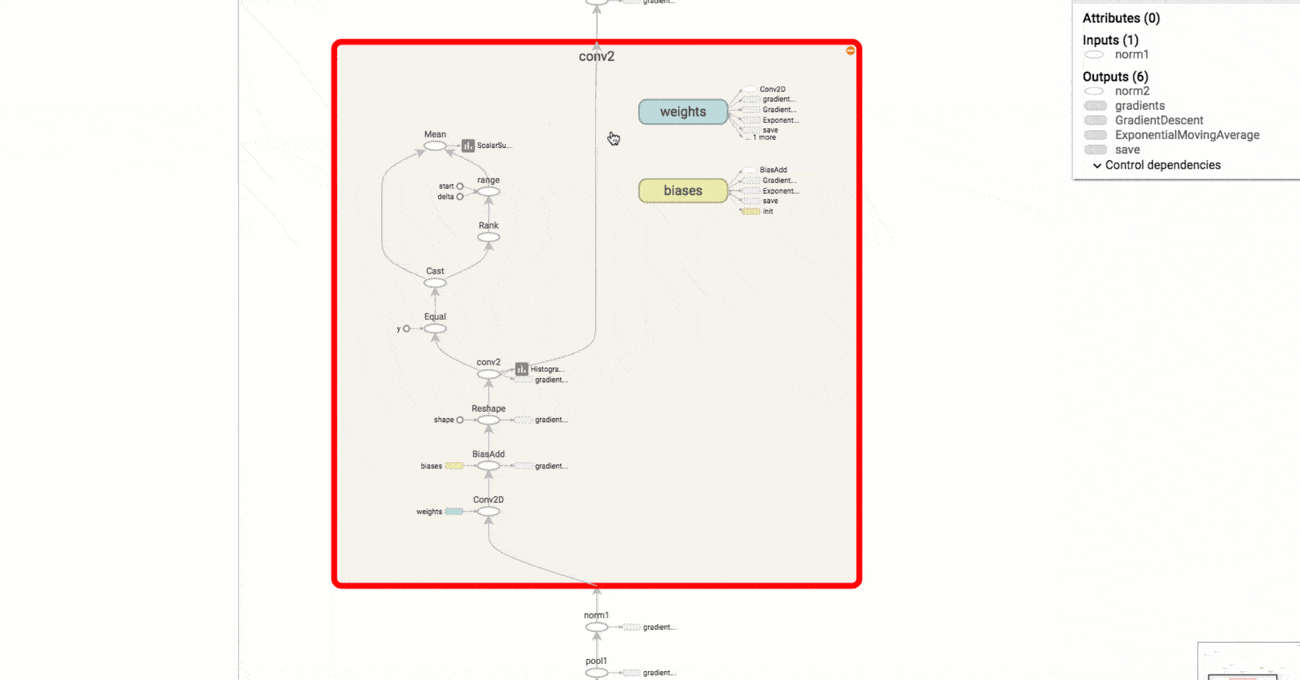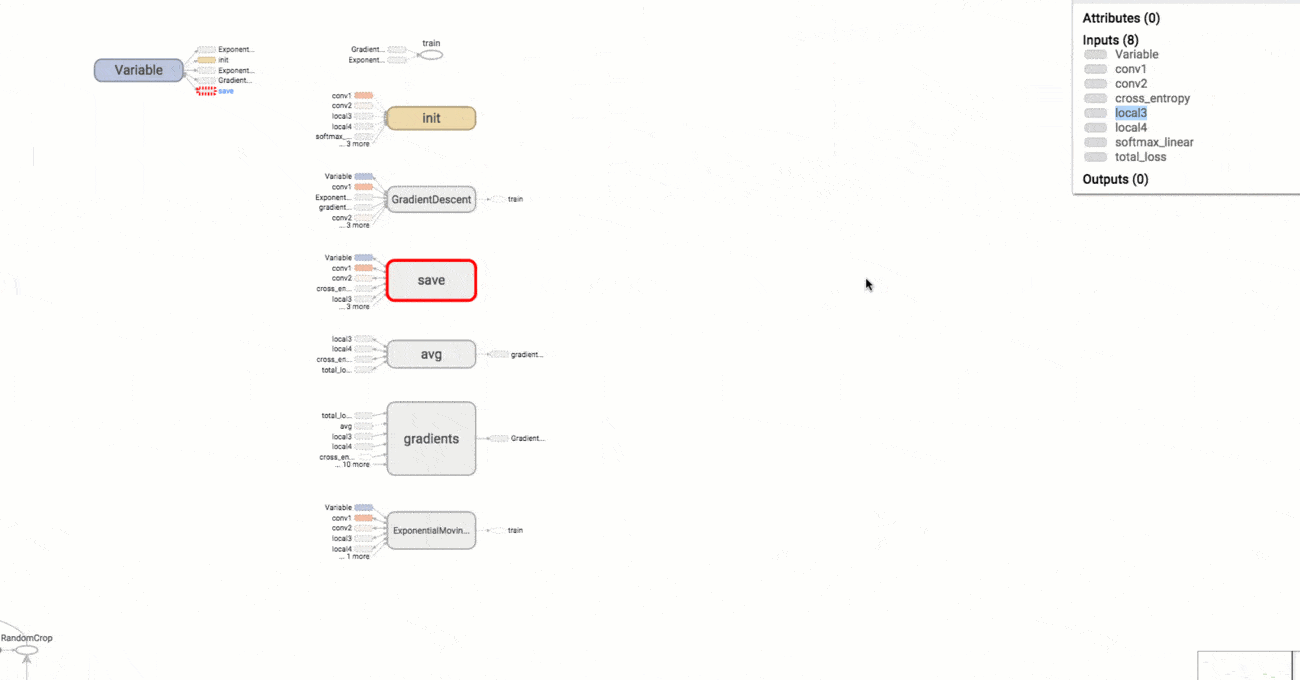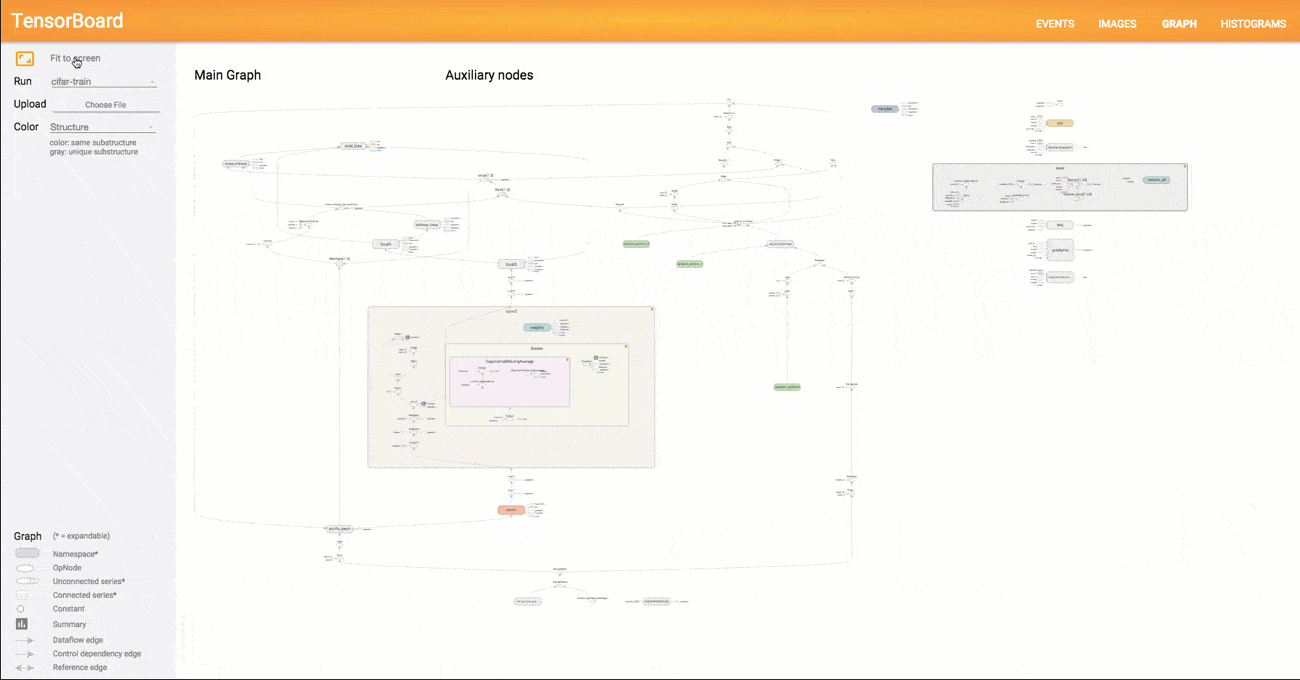
Graphical representation of a model in TensorBoard
With the graph visualizer, users can explore different layers of model abstraction, zooming in and out of any part of the schema. Another important benefit of TensorBoard visualization is that nodes of the same types and similar structures are painted with the same colors. Users can also look at coloring by device (CPU, GPU, or a combination of both), highlight a specific node with the “trace inputs” feature, and visualize one or several charts at a time.
This visualization approach makes TensorBoard a popular tool for model performance evaluation, especially for models of complex structures like deep neural networks.
Grant Reaber notes that TensorBoard makes it easy to monitor model training. Grant and his team also use this tool for custom visualizations.
Illia Polosukhin also chooses TensorBoard. “TensorBoard shows metrics during model development and allows for making a decision regarding a model. For instance, it’s very comfortable to monitor how a model performs when tweaking its hyperparameters and choosing the one that performs best,” summarizes Illia.
Besides displaying performance metrics, TensorBoard can show users a lot of other information like histograms, audio, text, and image data, distributions, embeddings, and scalars.
PyTorch: easy to use tool for research
PyTorch is an open source machine learning framework for deep neural networks that supports and accelerates GPUs. Developed by Facebook's team together with engineers from Twitter, SalesForce, NRIA, ENS, ParisTech, Nvidia, Digital Reasoning, and INRIA, the library was first released in October 2016. PyTorch is built on Torch framework, but unlike predecessor that's written in Lua, it supports commonly used Python.
PyTorch was developed with the idea of providing as fast and flexible a modeling experience as possible. It’s worth mentioning that workflow in PyTorch is similar to the one in NumPy, a Python-based scientific computing library.
A dynamic computational graph is one of the features making this library popular. In most frameworks like TensorFlow, Theano, CNTK, and Caffe, the models are built in a static way. A data scientist must change the whole structure of the neural network — rebuild it from scratch — to change the way it behaves. PyTorch makes it easier and faster. The framework allows for changing the network behavior arbitrarily without lag or overhead.
The ability to build models dynamically (during runtime) is one of the driving factors for using PyTorch, agrees Denis Yarats from Facebook AI Research. “I use PyTorch — it’s just the best. I tried many DL frameworks in the past, including TensorFlow, Torch, Keras, and Theano. None of those are as simple and powerful as PyTorch. As I work on deep learning research, I value the ability to modify and debug my models quickly.”
Illia Polosukhin and Vitaliy Bulygin also emphasize the convenience and flexibility of research made possible through the use of the dynamic computational graph, which is the reason they choose PyTorch as their deep learning tool.
Keras: lightweight, easy-to-use library for fast prototyping
Keras is a Python deep learning library capable of running on top off Theano, TensorFlow, or CNTK. The Google Brain team member Francois Chollet developed it to give data scientists the ability to run machine learning experiments fast.
The library can run on GPU and CPU and support both recurrent and convolutional networks, as well as their combinations.
Fast prototyping is possible with the help of the library’s high-level, understandable interface, the division of networks into sequences of separate modules that are easy to create and add.
According to data scientists, the speed of modeling is one of the strengths of this library. Vitaliy Bulygin from Samsung notes that Keras with TensorFlow allows for a very swift neural network implementation. He suggests sticking with Keras if its toolset is enough for a particular task. If not, it’s better to do research with PyTorch.
Caffe2: deep learning library with mobile deployment support
Caffe2, an improved version of Caffe, is an open machine learning framework build by Facebook for the streamline and flexible deep learning of complex models and support for mobile deployment.
Users have several options to organize computation with the library, which can be installed and run on a desktop, in the cloud, or at a datacenter.
The library has native Python and C++ APIs that work alternately, allowing developers to prototype on the go and optimize later.
Deployed models can run fast on mobile devices through the integration with Xcode, Visual Studio, and Android Studio IDEs. This framework also allows for quick scaling up or down without the need for design refactoring.
Fast prototyping, research, and development are the benefits of using Caffe2. “I'm using it because it has clear code infrastructure and it's easy to extend it for research of new methods,” summarizes a senior lecturer at NURE Andrii Babii.
Big data tools
Apache Spark: the tool for distributed computing
Using Apache Spark for big data processing is like driving a Ferrari: It’s faster, more convenient, and allows for exploring more within the same amount of time compared to a regular car.
Apache Spark is a distributed open-source cluster-computing framework that’s usually equipped with its in-memory data processing engine. This engine’s functionality includes ETL (Extract, Transform, and Load), machine learning, data analytics, batch processing, and stream processing of data.
The stream processing capability of Apache Spark is one the reasons the researcher from Facebook AI Denis Yarats uses it: “This tool is using the data flow/stream processing conception for distributed computing and allows for scaling solutions to large clusters.”
While being written mostly in Scala, the engine comes with high-level developer APIs for Java, Python, Clojure, and R.
A variety of running options (locally, in clusters or cloud, or on-premises) and the capability to access data from any data sources are other beneficial features of Apache Spark.
MemSQL: a database designed for real-time applications
MemSQL is the distributed in-memory SQL database platform for real-time analytics. It ingests and analyzes streaming data and runs petabyte scale queries to enable the work of real-time applications like instant messengers, online games, or community storage solutions. MemSQL supports queries for relational SQL, Geospatial, or JSON data.
Briefly said, the platform can provide database, live data processing, and data warehouse services at once, helping users to achieve data efficiency.
“MemSQL allows you to be unconcerned about the size of the data and to work like it's just a regular SQL database,” emphasizes Illia Polosukhin from NEAR.AI.
Final word
We benefitted from comparing machine learning tools and libraries, defining their use cases and requirements. So much gelled for us in the preparation. We're planning a post about AI solutions in airlines next month. So, if you are an active machine learning practitioner, please feel free to share with us which tools you prefer in the comment section or by contacting us directly. We'd be glad to share your comments as well.