What do healthcare and finance have in common? Probably not too much, except for the fact that they are being disrupted by technology. The process is highly encouraged: a record sum of $3.5 billion was invested in 188 digital health companies in the first half of 2017. Yet, the key to the meaningful industry transformation lies in the use of data science for healthcare.
With about 1.2 billion clinical documents being produced in the United States annually, life scientists and doctors have a sea of data to base their research upon. Additionally, huge volumes of health-related information are made accessible through widespread adoption of wearable tech. This opens up new opportunities for better, more informed healthcare.
Being able to collect, structure and process a high volume of data and further make sense of it, to gain a deeper understanding of the human body is the key objective for thousands of data scientists and machine learning experts all over the world. It also has the strongest potential to revolutionize healthcare, based on our industry expertise. Namely, we see 7 significant advances of data science in healthcare.
1. Using wearables data to monitor and prevent health problems
The amount of data that the human body generates daily equals two terabytes. Due to advances in technology, we can now collect most of it, including info about heart rate, sleep patterns, blood glucose, stress levels and even brain activity. Equipped with such amount of health data, scientists are pushing the boundaries in health monitoring. For example, take a look at our case with SleepScore Lab.
World’s leading technology companies, such as IBM and Qualcomm, have been leading the way in health innovations. In 2015, Apple has joined the race for better healthcare with its ResearchKit. Yet, there remain plenty of opportunities on the market.
Machine learning algorithms can be used to detect and track more common conditions, like heart or respiratory diseases. Collecting and analyzing heart rate and breathing patterns, technology can detect the slightest changes in the patient’s health indicators and predict possible disorders. While 600,000 people suffer sudden heart stoppages in the US every year, having an opportunity to anticipate the problem and send out timely alerts could save thousands of lives.
Another healthcare issue that calls for special attention and routine observation is chronic disease management. With an extremely high obesity rate (30 percent and higher in 25 states), a number of potentially dangerous chronic conditions, such as diabetes and hypertension, have emerged as the major risk factors for the US population.
Targeting this particular market opportunity, Omada Health positions its flagship product as a “first digital therapeutic.” It’s a data science-aided preventive medicine program, aimed at changing patients’ lifestyle and helping them keep their weight under control and avoid dangerous impacts of the obesity on their health. Adopted by individuals as well as businesses, the product represents a complete toolset aimed at reducing the risk of preventable health issues.
Using smart devices, such as scales and pedometer, Omada sources and processes patient’s behavioral data to create highly customized programs for every patient and provide the personal health coaches with an opportunity to gain deeper insights into the patient’s health and adjust the programs along the way. Furthermore, the self-learning algorithm is constantly improved as it sources more patient data from the system.
2. Improving diagnostic accuracy and efficiency
Despite such huge amounts of health data at hand, the diagnostic failure rates are still relatively high. According to the recent research by the National Academies of Sciences, Engineering, and Medicine, about 5 percent of adult patients are misdiagnosed each year in the US. This totals over 12 million people. Moreover, the postmortem examination results research shows that diagnostic errors cause approximately 10 percent of patient deaths.
Targeting this problem, a deep learning startup, Enlitic, employs data science to increase the accuracy and efficiency of diagnostics. With $15 million funding, the startup has built a deep learning algorithm that can read imaging data (such as x-rays, CT scans, etc.), and analyze it, checking the given results against extensive database of clinical reports and laboratory studies. Therefore, the company claims to deliver up to 70 percent more accurate results, 50,000 times faster.
Take for example the Dutch startup, called Bruxlab, which applies similar data science and machine learning algorithms for diagnostic purposes. Coupled with sound recognition technologies, they help diagnose and measure Bruxism symptoms. Using a vast number of audio samples, both true and false, the data scientists taught a neural network to recognize and measure teeth grinding symptoms.
With a prevalence rate of up to 31 percent, Bruxism is quite a widespread disease, yet it is mostly overlooked due to its symptoms’ concealed nature. Thus, a mobile app, powered by data science technologies, presents a significant opportunity for better diagnosis and more efficient disease monitoring.
3. Turning patient care into precision medicine
Similar to the way scientists collect and analyze health data in order to find symptoms and identify diseases, doctors can track the clinical course of the patients with confirmed diagnosis. Personalized treatment and informed care, enabled by technology, can significantly reduce the death rate and lead to predictable medical outcomes.
From a significant Electronic Health Records (EHR) adoption (currently about 95–98 percent in the US only) to the progress in genome sequencing, physicians now have enough information at hand to identify consistent patterns in symptoms and create accurate patient profiles.
Resulting from these two trends, there has been a boost in so-called precision medicine. As David Shaywitz, chief medical officer at DNAnexus, a cloud-based data analysis and management platform for DNA sequence data, wrote in his article for Forbes: “The core premise … of precision medicine … is that the integration of genetic information, EMR data, and rich dynamic phenotypic information will enable sophisticated patient segmentation, revealing biologically distinct subgroups and pointing the way to precisely targeted treatments.”
Therefore, the experts foresee an end to “one size fits all” treatments. Instead, precision medicine will open up the opportunities for personalized, thus more effective treatment. For example, instead of treating a patient for lung cancer, we will soon be able to define each specific symptom of the disease, the individual condition of the patient, his medical history, and even his genetic information in order to tailor the treatment accordingly and increase the chances for positive outcomes.
A vivid example of using data science to help physicians make informed treatment and patient care decisions is Oncora Medical. The healthcare startup uses historic data from multiple cancer treatment centers and patient’s individual EHR information to provide personalized treatment recommendations, depending on the type of cancer, the patient’s previous health records and his current condition. The company has successfully closed the second round of seed funding and currently plans to streamline its product.
4. Advancing pharmaceutical research to find cure for cancer and Ebola
Being one of the most common and most deadly diseases, cancer has been a regular subject of scientific research. The number of cancer patients keeps growing. Researchers projected that 1,735,350 new cancer cases will be diagnosed in the US in 2018. And 609,640 of them will be lethal.
A Boston healthcare startup, BERG Health, reshapes the cancer medication market through extensive use of data science. Using powerful machine learning algorithms the company extracted and analyzed biological samples from over 1,000 patients. With over 14 trillion data points contained in each sample, that was a plenty of information to feed into the AI algorithm.
As a result, the company developed BPM 31510, the drug, which detects and triggers the natural death of cells damaged by the disease. Thus, the cancer cells can be removed from the human body naturally, without extensive medication and further damage to the patient’s health.
While the drug is still being carefully tested, it gives us a clear understanding of the transformation potential that data science and machine learning technologies can provide to the pharmaceutical industry. Finding a way to push these research areas forward can lead to discoveries in AIDS, Ebola or Zika virus treatment.
As for the latter, Atomwise, an artificial intelligence technology startup, has recently shown some advances in search for the Ebola cure. The company used virtual models and neural networks to evaluate how 7,000 existing drugs interact with the virus. Being processed by an AI-based program, the experiment took only about a day instead of months to complete and resulted in potentially promising discoveries: Two of the tested drugs has proven to make human cells resistant to the virus.
While the research is still to be continued, these early results show a huge potential of such approach to pharmaceutical research. Alexander Levy, COO of Atomwise states: “If we can fight back against deadly viruses months or years faster, that represents tens of thousands of lives. Imagine how many people might survive the next pandemic because a technology like Atomwise exists.”
5. Optimizing clinic performance through actionable insights
Data science and predictive analytics are are a valuable tool which can help healthcare providers optimize the way hospital operations are managed. CognitiveScale, an Austin-based startup, applies machine learning to business processes in a number of industries, including finance, retail, and healthcare. With over 60 filed patents, the company’s Deep Cognition Engine helps businesses make better sense of their data, creating the foundation for intelligent user engagement and improved business performance.
Its cognitive engine is positioned as an “insights-as-a-service”. While the estimated 80 percent of data remains untapped, the company wants to bridge the gaps in business intelligence, providing deeper insights into the “dark data” through cognitive computing. Its two products, Amplify and Engage, are adopted mostly by the enterprise level organizations and used to interpret the data sourced both from clients and employees. Thus, the programs provide valuable recommendations and actionable insights, improving the organizations improve performance and engagement.
Similarly, data science and machine learning can be used to optimize the clinic staff scheduling and reduce the wait times, manage supplies and accounting, and even build efficient action programs for epidemics, such as seasonal flu outbreaks.
6. Taking the risk out of prescription medicine
One more innovative startup, MedAware, aims to eliminate prescription errors. The company claims that its tools can allow the hospitals to save up to $5.6 million, not to mention the reduced risk of lethal outcomes. A self-learning software system, provided by MedAware, checks all prescriptions against similar cases in the database and informs the doctor when the prescription contains any deviations from the typical treatment plan.
For example, if 99 percent of the patients with the same symptoms are treated with a definite dose of a drug A, prescribing a different drug or changing its dose will trigger a system alert, asking if the doctor is sure about his/her prescription. Therefore, the product has the potential to save hundreds of lives and cut the expenses, caused by unnecessary readmissions or lengthy hospital stays.
7. Reducing hospital readmissions to cut healthcare costs
As in any other industry, overall digitization and technical transformation can lead to significant cost savings. Accounting for 17.9 percent of the GDP, the US. medical expenses reached $3.3 trillion in 2016. With a projected growth up to $5.2 trillion in 2020, the cost of healthcare represents a serious problem for the US economy.
Analytics-based preventative medicine is told to contribute to an overall reduction in healthcare costs, although indirectly. For example, Clover Health, a data-driven analytics health insurance startup, reports up to 50 percent fewer hospital admissions and 34 percent fewer hospital readmissions. A smart algorithm, used by the company, identifies the most at-risk patients and helps coordinate the necessary care. Therefore, Clover Health is able to save $10,000 per every hospitalization avoided on average.
Furthermore, the use of data processing and analysis tools allows physicians to make informed decisions, which results in significant savings. As an example, data analytics, applied to optimization of the knee replacement process helped the healthcare provider save over $1.2 million within a year.
The adoption of data science strategy can bring many benefits to an organization. However, a search for professional data scientists may become one of the main challenges for its management. Health Catalyst survey respondents admitted the lack of people or skills became the major obstacles to the adoption of predictive analytics. Do you plan to open a data science department but aren’t sure about criteria for personnel selection? In the next section, you will find out about core skills for a healthcare data scientist.
Healthcare data scientist: general and domain-specific skillset
The main goal of healthcare organizations is to provide quality treatment at reasonable cost. To maintain high standards of patient service, providers must make the right medical decisions. The vast amount of unstructured healthcare data complicates decision-making.
All call center records, doctor’s notes, reports, prescriptions, lab test results, and discharge summaries need to be quickly and safely stored and so that they may be used with efficiency and ease. For these and other pressing reasons, healthcare providers must have good data scientists on board.
The job description for a healthcare data scientist barely fits on one printed page. The list of preferred, necessary skills and responsibilities is extensive. A data scientist should have mathematical, statistical, programming, visualization, and experimental design skills. They must know how to deal on the one hand with large datasets and, on the other, with individual people. Besides that, this specialist must acquire at least basic medical knowledge and in-depth understanding of the healthcare industry.
Domain knowledge will help a professional define what data is essential for the implementation of a certain project and interpret the received results of analytical and modeling work.
First, let’s take a quick look at a data scientist’s general and healthcare-related skills and how they can be applied in the healthcare industry.
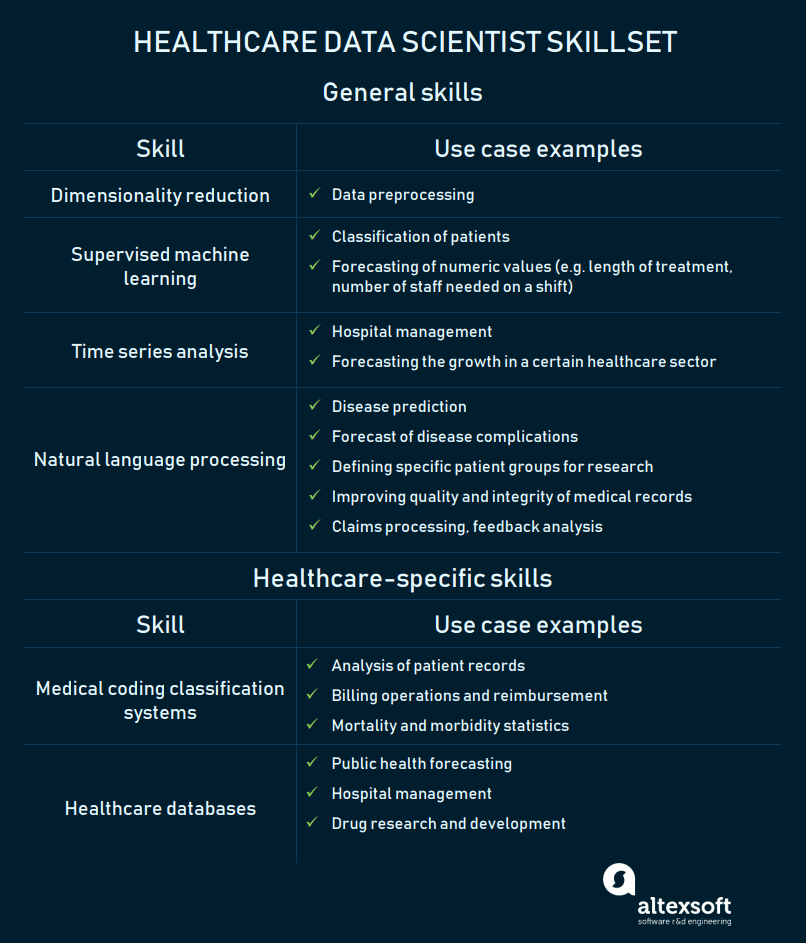
General data science skills
The application of data mining techniques over healthcare datasets may be challenging. An algorithm may not perform well due to a great number of features. That's why, a data scientist should know how to preprocess data to increase its quality and simplify modeling.
Dimensionality reduction. This approach allows a scientist to clean noisy raw data by reducing the number of irrelevant features and representing it with different and fewer ones.
There are two main methods for this operation. A specialist can either select new features from the existing ones (feature selection) or combine the existing features to extract the new ones (feature extraction).
Principal Component Analysis (PCA) is one of the most commonly used feature extraction techniques. It aims for defining a smaller number of uncorrelated variables — principal components.
Supervised machine learning. Model training is one of the stages of the machine learning workflow. As a result of model training, a data scientist develops, tests, and validates a mathematical model that can formulate a target value or attribute — an unknown value of each data object.
The choice of training style depends on whether a data scientist knows which target attributes are must be found and which are not required. In case of supervised machine learning, a specialist maps these target attributes in a training dataset to tell an algorithm what target values it should look for in future data.
Supervised learning is used to address two groups of tasks — classification and regression.
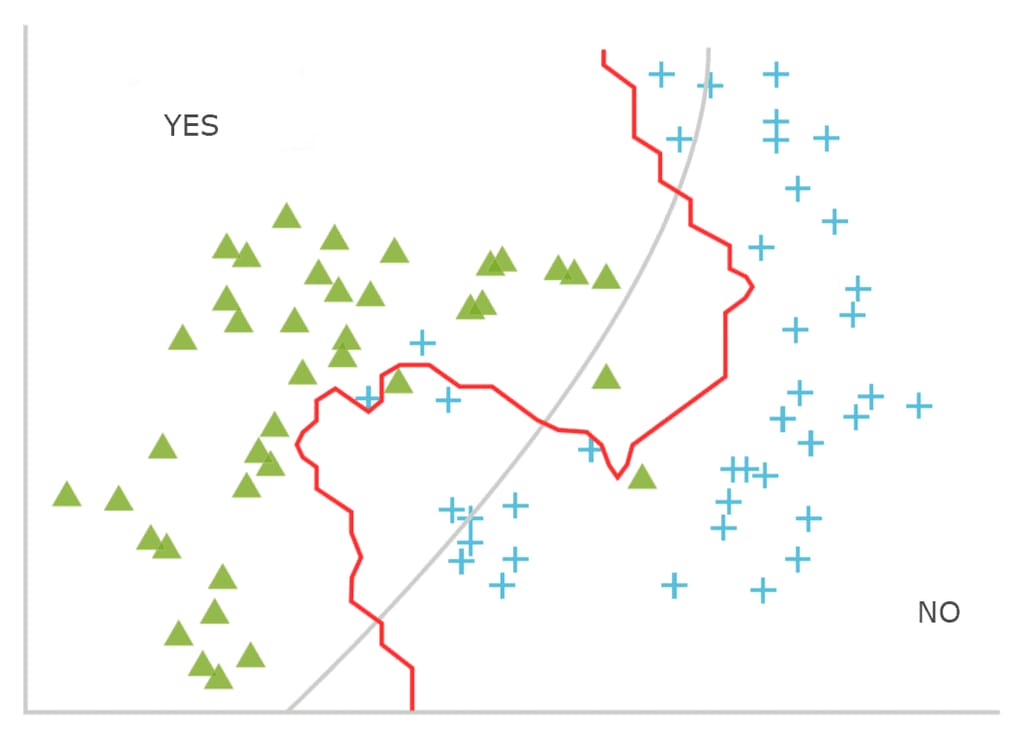
Classification. The goal of this task is to define a category of a data object. Supervised machine learning with a classification algorithm can be used to answer this question: Is there a probability that a patient will experience heart failure?
The target value here is yes or no. The model may include such attributes as patient’s medical notes, expressed symptoms, incubation period of the questioned disease, lifestyle choices, as well as behavioral, socioeconomic, and environmental data.
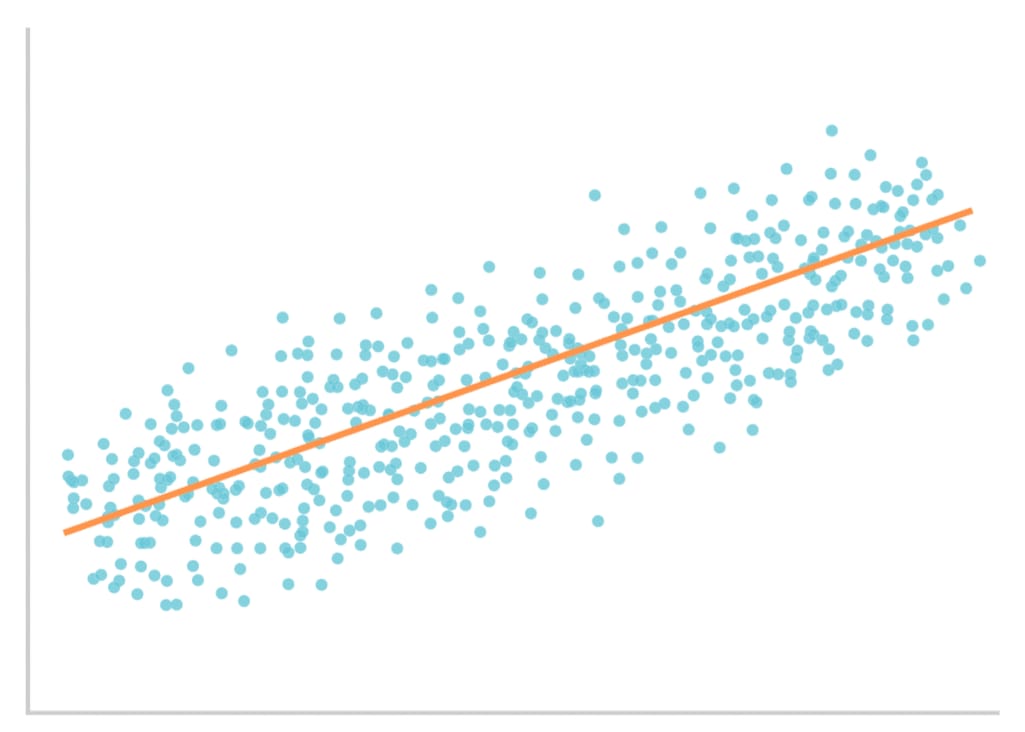
Regression. This machine learning task is aimed at modeling and forecasting numeric values. With regression algorithm, a scientist can predict, for instance, how many months will be needed to treat a patient.
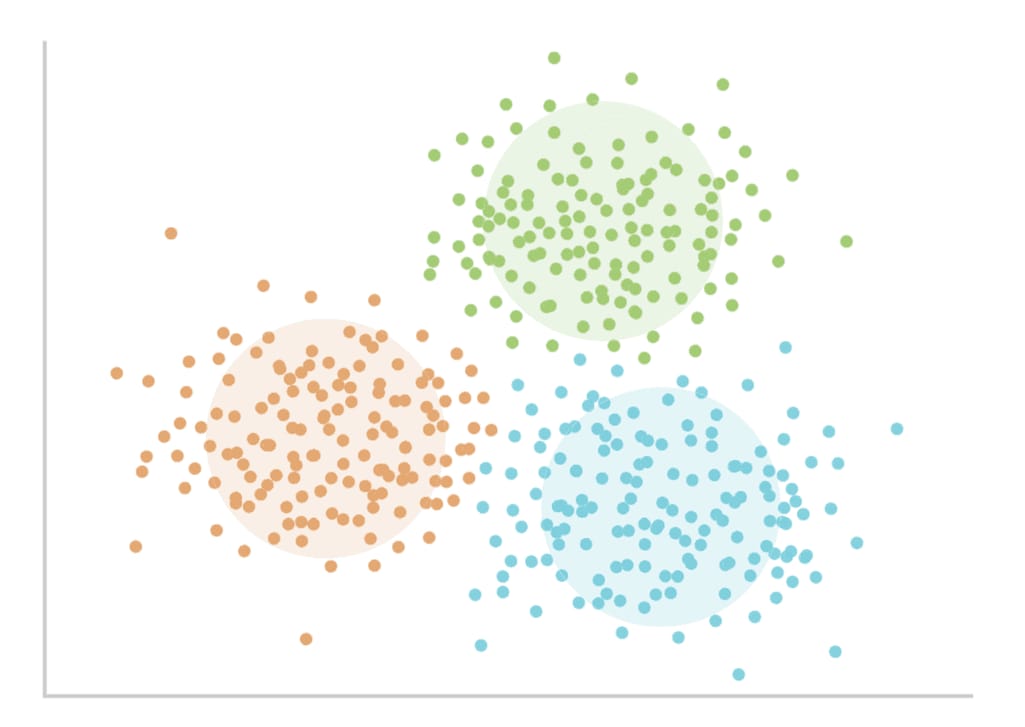
Unsupervised learning. This training style allows for processing unlabeled data. The purpose of unsupervised learning is to define principles, according to which values are arranged and to group data objects by similarities or differences.
Clustering. Clustering is the task of spotting patterns in data. Unsupervised machine learning with applied clustering algorithms allows for grouping patients’ health records by similarity and get answers to questions like What are the qualitative and quantitative similarities among high-utilizing patients?
A data science professional should understand which algorithm would work best for a particular task. The choice of algorithm may depend on the quality, size, and type of data. Project timeline also matters. Sometimes it’s worth trying out several algorithms to learn which one provides the most accurate prediction.
Time series analysis. This technique may also be useful for a healthcare data scientist. This approach assumes that data collected over time may have an internal structure. In other words, the observation of data over specific intervals allows for identifying if it has a trend or seasonal variation. The main goals of time series analysis are therefore to determine the nature of the phenomenon represented by the sequence of observations and to predict future values of the time series variable. Once the scientist finds and interprets a pattern in the time series data, he or she can extrapolate it with other data and predict future events.
Time series analysis can be applied to hospital management and research conduction. For example, it allows forecasting the number of patients in hospital waiting lists. Knowledge about how fast a waiting list is growing or declining will help hospital managers evaluate the institution’s capacity to provide treatment. Management can also rely on forecast insights before taking measures to control supply and demand.
Natural language processing (NLP). NLP is the use of computer algorithms to process text or speech through systematic analysis of the grammatical format and semantics to extract key elements in it.
Knowledge of NLP will allow a data scientist to make the best use of heterogeneous health data. Healthcare providers, in turn, will be able to deliver qualitative treatment at affordable costs.
As analysts have access to the information about patient health status from medical notes, they can develop predictive models to find out if any of the healthcare provider’s patients are at risk for certain medical conditions. After risk factors are identified, hospital management system can inform hospital staff that certain patients may need a proper treatment. Data scientist can also develop risk stratification models to predict disease complications.
Pharmaceutical companies use natural language processing to categorize and analyze feedback (side effects, drug-drug interaction, patient-reported outcomes) about a drug by transcribing customer calls.
Pharma and biotech companies together with medical institutions use NLP to define specific patient populations for research. The problem is that diagnostic codes for medical conditions these patients are diagnosed with don’t exist or are barely used. In this case, software with built-in NLP algorithms can identify patients whose EHR have conditions scientists are interested in. Patients with ANCA-associated vasculitides, for instance, belong to one of these groups.
Ungrammatical sentences with a lot of abbreviations, acronyms, and improperly coded claims or diseases make clinical notes ambiguous. Doctors consequently spend 49.2 percent of their time on desk work and EHR during shifts instead of taking care of patients. NLP allows data scientists to improve the integrity of clinical documents. First, these measures are necessary for qualitative and efficient processing of data. Second, useful insights received from data analysis will help medical staff organize their work and make more effective treatment decisions.
Healthcare-specific data science skills
As we mentioned before, domain knowledge is crucial for a data scientist who plans to work in healthcare. A specialist shouldn’t have to drown in an ocean of medical data. But he or she should be well-versed in healthcare databases, types of medical documents, medical coding classification systems, and the work of regulatory agencies.
Feature engineering, in particular, is impossible without domain expertise. The data scientist should understand medical variables and how they relate to a health outcome.
Medical coding classification systems. Healthcare data scientists should know the meaning of numerous terms and abbreviations. One can start building the knowledge base form learning about the two most commonly used medical coding classification systems. They are the International Classification of Diseases (ICD) and Current Procedural Terminology (CPT).
ICD is the classification system for mortality and morbidity statistics. The system was developed and is maintained by the World Health Organization and works in 117 countries. It allows for providing a detailed description of diseases, including symptoms, complaints, abnormal findings, social circumstances, and external causes of a medical condition. There are approximately 68,000 codes in the latest ICD-10 version, and each of them consists of three to seven digits and letters. The next version, ICD-11, has already been reviewed and implementation is planned after 2018.
CPT is a code set published by the American Medical Association (AMA) that represents medical procedures and services. Currently, healthcare institutions use nearly 10,000 CPT codes. These numeric or alphanumeric codes are five characters long. The knowledge of this system is useful if the analysis or research is associated with billing and reimbursement.
The purpose of the Healthcare Common Procedure Coding System (HCPCS) is the same as the CPT coding system. The difference is that this code collection is used for reporting services or procedures provided to Medicaid, Medicare, and clients of other third-party insurance programs.
There are two code levels. Level I is similar to CPT, Level II is used for classification of the equipment, out-patient services, and medication not included in CPT. These codes are alphanumeric.
Healthcare databases. It’s important to have a list of healthcare databases at hand. Although a data scientist doesn't have to remember thousands of clinical terms, he or she must know what sources to use for every case.
Medical terms and definitions. SNOMED CT (Systematized Nomenclature of Medicine — Clinical Terms) is one of those sources. It’s a standardized and structured vocabulary of medical terminology. Each described medical concept is represented by numbers, which makes it easier for healthcare providers to exchange clinical data with each other. Both international and US edition releases are updated regularly and available online.
Knowledge of the National Drug Code (NDC) would also be useful. NDC is an identifier for human drugs used in the US. All nonprescription and prescription medication inserts have this code. The code consists of 10 digits, divided into 3 segments. The first set of numbers identifies a labeler, the second one provides information on a product, and the third segment represents commercial package size.
It’s also worth mentioning RxNorm. According to its developers, RxNorm is “a normalized naming system for generic and branded drugs; and a tool for supporting semantic interoperation between drug terminologies and pharmacy knowledge base systems.”
Public health databases. These sources contain invaluable insights on citizen health status or medical services. The National Information Center on Health Services Research and Health Care Technology (NICHSR) shares links to health services resources on its website. Data scientists are welcome to study data charts, non-federal, federal, and state databases or repositories, statistics, surveys, and data tools.
Reference databases. Information about the human organism and how it functions can be found in such databases as KEGG or GenBank.
A healthcare data scientist should understand how the industry works and how it’s regulated. It’s crucial to have a grasp of clinical concepts and of the structure of terminologies, as well as to know if there are any correlations between them.
The Bright Future of Healthcare
From predicting treatment outcomes, to curing cancer and making patient care more effective, data science healthcare has proven to be an invaluable contribution to the future of the industry. Following from the examples above, the boost in health innovation is driven by the three main factors:
Advances in technology
Growth of digital consumerism
The need to fight increasing costs
While data science provides tools and methods to extract real value from unstructured patient information, it eventually contributes to making healthcare more efficient, accessible and personalized. The number of healthcare institutions making data-driven decisions increases slowly but steadily. In 2015, only 15 percent of hospitals employed data science and predictive analytics to prevent hospital readmissions. One year after, 31 percent of institutions said they have been doing so for more than a year.