

While shaping the idea of your data science project, you probably dreamed of writing variants of algorithms, estimating model performance on training data, and discussing prediction results with colleagues . . . But before you live the dream, you not only have to get the right data, you also must check if it’s labeled according to your task. Even if you don’t need to collect specific data, you can spend a good chunk of time looking for a dataset that will work best for the project.
Thousands of public datasets on different topics – from top fitness trends and beer recipes to pesticide poisoning rates – are available online. To spend less time on the search for the right dataset, you must know where to look for it.
This article is aimed at helping you find the best publicly available dataset for your machine learning project. So, let’s deep dive into this ocean of data.
Data labeling can be costly and slow at scale. In these cases, self-supervised learning lets models learn directly from unlabeled data. Read our dedicated article to learn more.
Catalogs of data portals and aggregators
While you can find separate portals that collect datasets on various topics, there are large dataset aggregators and catalogs that mainly do two things:
1. Provide links to other specific data portals. The examples of such catalogs are DataPortals and OpenDataSoft described below. The service doesn’t directly provide access to data. Instead, it allows users to browse existing portals with datasets on the map and then use those portals to drill down to the desirable datasets.
2. Aggregate datasets from various providers. This allows users to find health, population, energy, education, and many more datasets from open providers in one place – convenient.
Let’s have a look at the most popular representatives of this group.
DataPortals: meta-database with 524 data portals
This website’s domain name says it all. DataPortals has links to 588 data portals around the globe.
Data sources are listed alphabetically based on a city or region. Each portal is briefly described with tags (level regional/local, national, EU-official, Berlin, OSM, finance, etc.)
Users can contribute to the meta-database, whether a contribution entails adding a new feature and data portal, reporting a bug on GitHub, or joining the project team as an editor.
OpenDataSoft: a map with more than 2600 data portals
The open data portals register by OpenDataSoft is impressive – the company team has gathered more than 2600 of them. The homepage contains a zoomable interactive map, allowing users to search for data from organizations located in a region of interest.
You can also visit this page to browse sources in the listing, which are grouped by countries, dataset issuers, dataset names, themes, or typology (public sector or national level).
OpenDataSoft provides data management services by building data portals. With its platform, clients publish, maintain, process, and analyze their data.
Those who want to add their portal to the registry need to submit a form.
Knoema: home to nearly 3.2-billion time series data of 1040 topics from more than 1200 sources
This search engine was specifically designed for numeric data with limited metadata – the type of data specialists need for their machine learning projects. Knoema has the biggest collection of publicly available data and statistics on the web, its representatives state. Users have access to nearly 3.2-billion time series data of 1040 topics obtained from more than 1200 sources, the information is updated daily.
Knoema offers several efficient data exploration options:
- a search panel on the homepage,
- the World Data Atlas with datasets clustered by countries, sources, indicators, as well as other data like commodities’ value change or county groups, and
- the Data Bulletin section with the latest releases of new datasets and updates of existing sources.
Datasets are also listed in alphabetical order.

Data exploration options on Knoema
Data scientists can study data online in tables and charts, download it as a CSV or Excel file, or export it as a visualization. Besides, Knoema users can access data via API. Supported languages are Python, C#, and R; the JSON format and SDMX – the standard for exchanging statistical data and metadata – are also supported.
However, the export isn’t free and available for users with professional or enterprise plans.
Government and official data
Data.gov: 261,073 sets of the US open government data
Searching for the public dataset on data.gov, “the home of the US Government’s open data,” is fast and simple. Users are free to choose the appropriate dataset among 261,073 related to 20 topics. When looking for a dataset of a specific domain, users can apply extra filters like topic category, dataset type, location, tags, file format, organizations and their types, and publishers, as well as bureaus.

Various filters are available on data.gov
Eurostat: open data from the EU statistical office
The statistics office of the EU provides high-quality stats about numerous industries and areas of life. Datasets are open and free of charge, so everyone can study them online via data explorer or downloaded in a TSV format.
The data navigation tree helps users find the way and understand the data hierarchy. Databases and tables are grouped by themes, and some have metadata. There are also tables on EU policies, the ones grouped in cross-cutting themes. New and recently updated items are located in the corresponding folders.

Data navigation tree of Eurostat database
If you want to get more data by state institutions, agencies, and bodies, you can surf such websites as the UK’s Office for National Statistics and Data.Gov.UK, European Data Portal, EU Open Data Portal, and OpenDataNI. Data portals of the Australian Bureau of Statistics, the Government of Canada, and the Queensland Government are also rich in open source datasets. Search engines at these websites are similar: Users can browse datasets by topics and use filters and tags to narrow down the search.
Scientific research datasets
Datasets that you can find within this source category can partly intersect with government and social data described below. However, here we focused mostly on science-related portals and datasets.
Re3data: 2000 research data repositories with flexible search
Those looking for research data may find this source useful. Re3Data contains information on more than 2,000 data repositories. The catalog developers paid attention to its usability. It allows for searching data repositories by subject, content type, country of origin, and “any combination of 41 different attributes.” Users can choose between graphical and text forms of subject search. Two search forms are also available when browsing data by country: The visual form is a map. Datasets by content type are organized in a listing. Every repository is marked with icons providing a short description of its characteristics and explaining terms of access and use.

Text and visual modes for subject search on Re3data
FAIRsharing: “resource on data and metadata standards, inter-related to databases and data policies”
FAIRsharing is another place to hunt for open research data. With 1326 databases listed on the source, specialists have a big choice. Users can search for data among catalogs of databases and data use policies, as well as collections of standards and/or databases grouped by similarities.
Users can also specify the search by clicking on checkboxes with domains, taxonomies, countries of data origin, and the organizations that created it. To speed up the process, a user can select a record type.
Harvard Dataverse: 92,839 datasets by the scientific community for the scientific community
Harvard Dataverse is an open-source data repository software that researchers and data collectors from around the globe use to share and manage research data. You can explore 92,839 datasets spanning a variety of topics: law, computer and information science, chemistry, arts and humanities, mathematic or social sciences, etc.
Sources are organized this way: Datasets containing metadata, data files, documentation, and code are stored in dataverses – virtual archives. These archives may also include other archives. As of today, 3,548 dataverses are hosted on the website.
Users can write specific archives in a search panel, browse information in datasets and dataverses simultaneously, and filter results by subject, dataverse category, metadata source, author’s name, affiliation, and year of publication.
Academic torrents: 53.52TB research data aggregated at one place
Using a torrent client for downloading copyrighted content like music or movies is illegal. But it’s not necessarily the case if we’re talking about scientific data. On Academic Torrents, you can browse or upload datasets, papers, and courses. Currently, 626 datasets are shared on the website.
Check out the collections section – many of these curated groups of entities contain large datasets on a variety of topics and suitable for different tasks. For example, the dataset with Amazon reviews from the Stanford Network Analysis Project can be used for implementing sentiment analysis. The author of the one with Minecraft skins whose author notes it could be used for training GANs or working on other image-related tasks.
We suggest ensuring that a certain content item isn’t protected by copyright. Just in case.
The Sloan Digital Sky Survey: 3D maps of the Universe
If you are an astronomy person, consider the Sloan Digital Sky Survey (SDSS). This is the source of “the most detailed three-dimensional maps of the Universe ever made, with deep multi-color images of one-third of the sky, and spectra for more than three million astronomical objects.”
The scientists have been conducting their surveys and experiments in four phases. The latest, Data release 16, is comprised of three operations with some witty titles:
- APOGEE-2 – the Milky Way exploration from both hemispheres,
- eBOSS (including SPIDERS and TDSS) – the observation of galaxies and, in particular, quasars to measure the Universe, and
- MaNGA (including MaStar) – the mapping of the inner workings of thousands of nearby galaxies.
The project participants do not only use a solid approach to documenting their research activities but also to providing access to data. SDSS provides different tools for data access, each designed for a particular need. For example, if you need to browse through sky images in the Data Release 16, use this Navigate Tool.
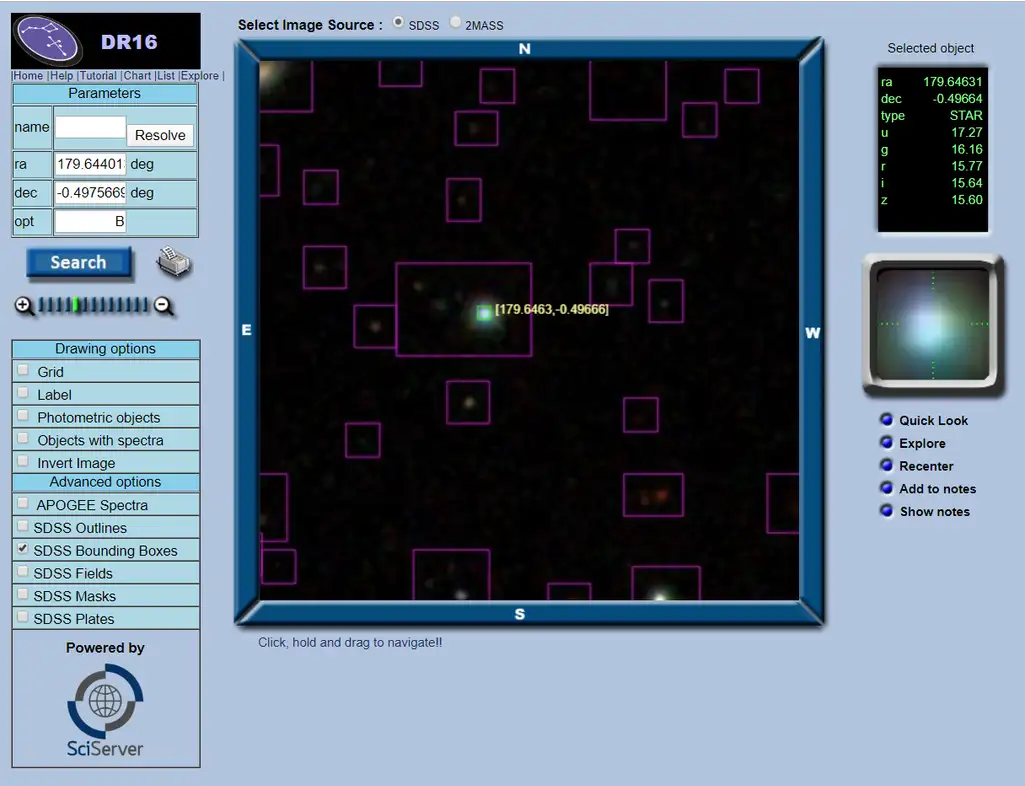
Image exploration with the SDSS navigation tool
Users can explore images online or download them as FITS files.
Verified datasets from data science communities
A really useful way to look for machine learning datasets is to apply to sources that data scientists suggest themselves. These datasets weren’t necessarily gathered by machine learning specialists, but they gained wide popularity due to their machine learning-friendly nature. Usually, data science communities share their favorite public datasets via popular engineering and data science platforms like Kaggle and GitHub.
DataHub: high-quality datasets shared by data scientists for data scientists
DataHub is not only a place where you can get an open framework and toolkit for building data systems or access data for your projects but also chat with other data scientists or data engineers.
You can look for data sources in three ways:
Browse core datasets. The team maintains 79 core datasets with information like GDP, foreign exchange rates, country codes, pharmaceutical drug spending by country, etc. Access to core datasets is free for all users.
Use a search panel. Write keywords in a search panel to check among “thousands of datasets from financial market data and population growth to cryptocurrency prices.”
Check out their dataset collections. Dataset collections are high-quality public datasets clustered by topic. Machine learning datasets, datasets about climate change, property prices, armed conflicts, distribution of income and wealth across countries, even movies and TV, and football – users have plenty of options to choose from.
Users can download data in CSV or JSON, or get all versions and metadata in a zip. It’s also possible to source data in bulk or via APIs. To ask for additional, customized data, or opt for extra features like receiving notifications on data/schema updates, users purchase the Premium Data offer.
UCI Machine Learning Repository: one of the oldest sources with 488 datasets
It’s one of the oldest collections of databases, domain theories, and test data generators on the Internet. The website (current version developed in 2007) contains 488 datasets, the oldest dated 1987 – the year when machine learning practitioner David Aha with his graduate students created the repository as an FTP archive.
UCI allows for filtering datasets by the type of machine learning task, number of attributes and their types, number of instances, data type (i.e. time-series, multivariate, text), research area, and format type (matrix and non-matrix).
Most of the datasets – clean enough not to require additional preprocessing – can be used for model training right after the download. What’s also great about UCI repository is that users don’t need to register prior upload.
data.world: open data community
data.world is the platform where data scientists can upload their data to collaborate with colleagues and other members, and search for data added by other community members (filters are also available). You can find all community partners who share public datasets here.
data.world offers tools simplifying data processing and analysis. Users can write SQL and SPARQL queries to explore numerous files at once and join multiple datasets. The platform also provides SDKs for R and Python to make it easier to upload, export, and work with data.
GitHub: a list of awesome datasets made by the software development community
It would be surprising if GitHub, a large community for software developers, didn’t have a page dedicated to datasets. Its Awesome Public Datasets list contains sources with datasets of 30 topics and tasks. The GitHub community also created Complementary Collections with links to websites, articles, or even Quora answers in which users refer to other data sources.
Although most of the datasets won’t cost you a dime, be ready to pay for some of them. As contributors have to comply with format guidelines for the data they add to the Awesome list, its high quality and uniformity are guaranteed.
Kaggle datasets: 25,144 themed datasets on “Facebook for data people”
Kaggle, a place to go for data scientists who want to refine their knowledge and maybe participate in machine learning competitions, also has a dataset collection. Users can choose among 25,144 high-quality themed datasets.
A search box with filters (size, file types, licenses, tags, last update) makes it easy to find needed datasets. Developers added the usability score that shows how well documented the dataset is: whether file and column descriptions are added, the dataset has tags, cover image, it’s license and origin are specified, and other features. Users can also open a popup to glance at the dataset characteristics.
Another nifty feature – registered users can bookmark and preview the ones they liked.

Searching for datasets on Kaggle is simple
When it comes to working with data, there are two options. Users can download datasets or analyze them in Kaggle Kernels – a free platform that allows for running Jupyter notebooks in a browser – and share the results with the community.
The Kaggle team welcomes everyone to contribute to the collection by publishing their datasets.
KDnuggets: a comprehensive list of data repositories on a famous data science website
A trusted site in scientific and business communities, KDnuggets, maintains a list of links to numerous data repositories with their brief descriptions. Data from international government agencies, exchanges, and research centers, data published by users on data science community sites – this collection has it all.
Reddit: datasets and requests of data on a dedicated discussion board
Reddit is a social news site with user-contributed content and discussion boards called subreddits. These boards are organized around specific subjects. Their members communicate with each other by sharing content related to their common interests, answering questions, and leaving feedback.
Browsing Datasets subreddit is like rummaging through a treasure chest because you never know what unique dataset you may come across.
Datasets subreddit members write requests about datasets they are looking for, recommend sources of qualitative datasets, or publish the data they collected. All requests and shared datasets are filtered as hot, new, rising, and top. There is also a wiki section and a search bar.
Political and social datasets from media outlets
Media outlets generally gather a lot of social and political data for their work. Sometimes they share it with the public. We suggest looking at these two companies first.
BuzzFeed: datasets and related content by a media company
BuzzFeed media company shares public data, analytic code, libraries, and tools journalists used in their investigative articles. They advise users to read the pieces before exploring the data to understand the findings better. Datasets are available on GitHub.
FiveThirtyEight: datasets from data-driven pieces
Journalists from FiveThirtyEight, famous for its sports pieces as well as news on politics, economics, and other spheres of life, also publish data and code they gathered while they work. Like BuzzFeed, FiveThirtyEight chose GitHub as a platform for dataset sharing.
Finance and economic datasets
Quandl: Alternative Financial and Economic Data
Quandl is a source of financial and economic data. The main feature of this platform is that it also provides alternative or untapped data from “non-traditional publishers” that has “never been exposed to Wall Street.” Acquiring such data has become possible thanks to digitalization. Alternative data is generated from IoT. Analysis of transactional data can give valuable insights into consumer behavior, for example, for predictive lead scoring.
Other data groups are market, core financial, economic, and derived data. As for data formats, time-series and table data are provided. Clients can filter datasets by type, region, publisher, accessibility, and asset class.

Search filters on Quandl
While core financial data is free, the rest of the data comes at a price. Users with a Quandl account can choose a format for data they get. They can source data via API or load it directly into R, Python, Excel, and other tools.
The International Monetary Fund and The World Bank: International Economy Stats
The International Monetary Fund (IMF) and The World Bank share insights on the international economy. On the IMF website, datasets are listed alphabetically and classified by topics. The World Bank users can narrow down their search by applying such filters as license, data type, country, supported language, frequency of publication, and rating.
Healthcare datasets
This is where you can get healthcare datasets for machine learning projects.
World Health Organization: Global Health Records from 194 Countries
The World Health Organization (WHO) collects and shares data on global health for its 194-member countries under the Global Health Observatory (GHO) initiative.
Source users have options to browse for data by theme, category, indicator (i.e., the existence of national child-restraint law (Road Safety)), and by country. The metadata section allows for learning how data is organized. These healthcare datasets can be explored on the site, accessed via XML API, or downloaded in CSV, HTML, Excel, JSON, and XML formats.
The Center for Disease Control (CDC): Searching for data is easy with an online database
The CDC is a rich source of US health-related data. It maintains Wide-ranging OnLine Data for Epidemiologic Research (WONDER) – a web application system aimed at sharing healthcare information with a general audience and medical professionals.
With CDC WONDER, users access public data hosted by different state sources, sorted alphabetically and by topic. Data can be used in desktop applications and is ready for download in CSV and Excel formats.
Medicare: data from the US health insurance program
Medicare is another website with healthcare data. It hosts 153 datasets focused on a comparison of the services provided by its health institutions: hospitals, inpatient rehabilitation facilities, nursing homes, hospices, and other facilities.
Medicare allows for exploring and accessing data in various ways: viewing it online, visualizing it with a selected tool (i.e., Carto, Plotly, or Tableau Desktop), or exporting in CSV, SCV and TSV for Excel, RDF, RSS, and XML formats. Also, users can access it programmatically via the Socrata Open Data API.
The Healthcare Cost and Utilization Project (HCUP): another source with data on healthcare services
HCUP is another place where you can explore information on services provided in US hospitals, on national and state levels. Databases on emergency department visits, ambulatory surgery, inpatient stays, and readmissions are at your service. Each database comes with detailed documentation.
Travel and transportation datasets
Bureau of Transportation Statistics: the US transportation system in over 260 data tables
Bureau of Transportation Statistics of the US Department of Transportation provides information about the state of the industry, covering such aspects as modes of transport, safety records, environmental impact, fuel consumption, economic performance, employment, and many others.
You can search for datasets in a grid or list view modes and filter them by 12 topics.

Looking for datasets on the Bureau of Transportation Statistics website
Each dataset (Excel table) comes with a description, notes, sources, and the document in which it’s published. You can explore the dataset on the website, download it, or share on social media if you think your subscribers should broaden their horizons.
Federal Highway Administration: US road transportation data
The Federal Highway Administration of the US Department of Transportation researches the nation’s travel preferences under the National Household Travel Survey (NHTS) initiative. Received insights show, for example, what vehicles Americans use when traveling, the correlation between family income and a number of vehicle trips, as well as trip length, etc.
Survey data is available for online exploration and for downloading as CSV, SAS Transport files. Users can also work with it in dBase, SPSS, and SAS Windows binary applications.
Don’t forget to check the aggregators we mentioned earlier. For instance, 5089 datasets are available on data.world; Knoema united a ton of datasets under the topic.
Other sources
Amazon Web Services: free public datasets and paid machine learning tools
Amazon hosts large public datasets on its AWS platform. Specialists can practice their skills on various data, for example financial, statistical, geospatial, and environmental.
Registered users can access and download data for free. However, AWS provides cloud-based tools for data analysis and processing (Amazon EC2, Amazon EMR, Amazon Athena, and AWS Lambda). Those who prefer to analyze datasets with these tools online are charged for the computational power and storage they used.
Google Public datasets: data analysis with the BigQuery tool in the cloud
Google also shares open source datasets for data science enthusiasts. Datasets are stored in its cloud hosting service, Google Cloud Platform (GCP) and can be examined with the BigQuery tool. To start working with datasets, users must register a GCP account and create a project. While Google maintains the storage of data and gives access to it, users pay for the queries they perform on it for analysis. The first terabyte of processed data per month is free, which sounds inspirational.
Also, Google Dataset Search is in beta. So, why not give it a try?
Cloud provider Microsoft Azure has a list of public datasets adapted for testing and prototyping. As it provides descriptions and groups data by general topics, the search won’t take much time.
Advice on the dataset choice
As so many owners share their datasets on the web, you may wonder yourself how to start your search or struggle making a good dataset choice.
When looking for specific data, first browse catalogs of data portals. Then decide what continent and country information must come from. Finally, explore data portals of that geographic area to pinpoint the right dataset.
You can speed up the search by surfing websites of organizations and companies that focus on researching a certain industry. If you’re interested in governmental and official data, you can find it on numerous sources we mentioned in that section. Besides that, data science communities are good sources of qualitative user-contributed datasets and data collections from different publishers.
It’s important to consider the overall quality of published content and make extra time for dataset preparation if needed. Sources like data.gov, data.world, and Reddit contain datasets from multiple publishers, and they may lack citation and be collected according to different format rules.
At the same time, data scientists note that most of the datasets at UCI, Kaggle, and Quandl are clean.