Before implementing any tech-related initiative, specialists must answer many whys and hows: What might be the impact of this solution? How do we know which tech stack is optimal for solving this problem? Can we afford this experiment? What is the predicted payback period? Answers to such questions help companies decide whether building a certain solution is worth the effort.
But that’s not always the case. Netflix spent $1 million on recommendation engine improvements it never used.
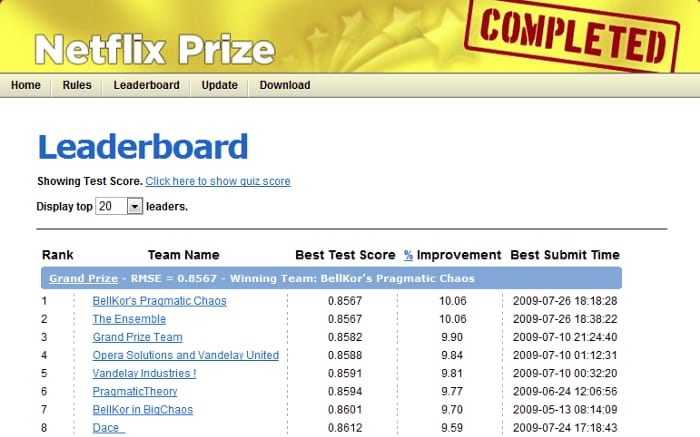
In 2006, the company announced the Netflix Prize, a machine learning and data mining competition and offered $1 million to the team that finds a way to improve the accuracy of their CineMatch movie recommendation system by 10 percent. In 2007, the KorBell developer team achieved an intermediate result of 8.43 percent accuracy increase. And two years later, in 2009, the Grand Prize goal was reached. BellKor's Pragmatic Chaos, with researchers from BellKor in BigChaos and Pragmatic Theory teams, was the first to get the job done. (Yes, we admit that the team’s name is as logically strong as their programming skills.)
Netflix decided not to deploy the $1 million algorithm for two reasons: “We evaluated some of the new methods offline, but the additional accuracy gains that we measured did not seem to justify the engineering effort needed to bring them into a production environment.” Besides the undue cost and effort, the decision not to deploy the algorithm was connected with the company's move towards “the next level” of personalization. In 2007, Netflix started working as a video streaming service instead of DVD rental one. So, it had to tailor its recommendation approach to new a customer experience.
In 2016, Netflix reported that its new content recommendation engine reduced customer churn, saving the company $1 billion annually. Keeping in mind the company's estimates that recommendations drive 80 percent of subscriber video choices, accurate movie advice is crucial for the well-being of the streaming service provider.
With the understanding of how much has to be spent to launch a new product or extend the functionality of a working system, businesses can focus on the projects with the potential financial return that justifies the risks. The feasibility study of any project is connected with the return on investment (ROI) evaluation.
We reached out to our data science specialist to learn how to mitigate risks when estimating return on investment for machine learning projects. We also discussed approaches to evaluate the use of off-the-shelf, custom non-ML, and ML-based solutions in terms of costs and gains (profits).
Also check our video on defining ROI in machine learning
What is ROI? Factors to consider when estimating and calculating it
Return on investment is the performance measurement and evaluation metric expressed as a ratio or a percentage. There are several ways to calculate ROI, but one of the most common formulas divides net income (gains – cost of investment) by the cost of investment.
The equation is applicable to various industries and looks like this:
ROI= (Gains – Cost of Investment)/Cost of Investment
The calculation is easy if you know values for this formula. In reality, it will take some time to understand if predicted gains and actual gains are the same or at least close to each other. Cost of investment is also an estimate. So, it’s about forecasting these values as accurately as possible. That’s where the brainwork begins.
Specialists must consider a lot of factors to define whether investing in a project is a good idea. Jonathan Craig, senior executive vice president of Charles Schwab, lists the factors that can influence the return:
Transaction cost. In economics, these are expenses incurred when buying or selling goods or services. Applied to software engineering, transaction costs may mean time spent on building, testing, and deploying a solution. Development costs include expenses on IT infrastructure and employee compensation, required man-hours, and maintenance costs.
Time. Determine in what time period an investment will start to pay off. The factor of time is useful when comparing two or more projects with the same expected ROI to be realized under the same circumstances.
Taxes. If you need to hire more people to develop a product in-house, for instance, take into account increased employment taxes.
Inflation. You can calculate and compare excess return over inflation or actual returns vs nominal returns – returns for which expenses aren’t factored in.
Opportunity cost. Think of how you could use the money if you didn’t invest it in a project.
It’s also important to decide what to consider as gains (revenue), so that these values, if quantifiable, can be included in the ROI calculation. To think of a gain as income earned during a specific amount of time. Someone can use revenue generated thanks to increased productivity in calculations as well.
Now let’s focus on steps that will help you choose a potential solution, decide whether you even need a machine learning product, and estimate its return on investment.
A roadmap to estimating ROI for ML and DS projects
1. Define your problem and consider it in terms of machine learning
A project roadmap starts with defining a problem. What issues, operational inefficiencies must be addressed? You have to be clear about your top goals and success criteria.
For instance, you run a chain of multi-brand sportswear stores across the country and also manage a website. Unfortunately, 40 percent of all transactions turned out to be fraudulent, and you spent one-fourth of last month’s income on chargebacks. You need to decrease or eliminate these losses and prevent suspicious transactions. The scenario of 100 percent manual transaction check (IP address, user identity, order details, etc.) isn’t considered because it’s labor intensive, slows down transaction approval, and ruins customer satisfaction. An application that identifies fraudulent activity would help.
At this point, you may start considering a solution that uses machine learning (or ML for short). Perhaps, the main thing to remember about any system that runs on ML is that all problems that these systems solve can be described as predictions. What do these systems predict? In the simplest terms (which is enough to know at this strategic point), they can predict three main things:
Class. Which of the predefined categories does this item belong to? In our example case, the item would be a transaction, and it can belong to either of these two classes: fraudulent or non-fraudulent. There may be many classes. For instance, the systems that run self-driving cars may use hundreds of classes to “predict” what they are currently seeing: other vehicles, road signs, pedestrians, trees, or animals that run or fly by. Voice assistants also predict classes by understanding what exactly you want from them: order a pizza, play a song, or discover the height of your favorite baseball player.
Number. Another major job for ML systems is to predict numeric values. Our client, Fareboom, for instance, uses an ML-driven system to predict flight fares. How much will this flight cost in a week? What about…in a month? There may be price predictions, churn rate predictions, sales predictions, etc.
Rank and recommendation. Ranking algorithms put items in order by assigning different ranks to them. The algorithm used at Netflix is a classic example of a ranking algorithm as it puts the movies that you most likely will watch first. Similarly, ranking works at Facebook's news feed, or at our other client’s system that predicts which property a user is likely to be interested in. Ranking and recommendation systems are commonly used as personalization tools.
And… well, that’s basically it. There are some exotic systems that can generate sounds, images, or speech. They have some real-life implementations (e.g., voice assistants again), but these use cases are rare in the business environment, and their ROI estimations are an entire topic on their own.
The main takeaway from this stage must be that your problem fits into these three categories of solutions. If you can fit the business problem into one of the three, you are on the right track.
The key deliverable of the stage:the problem statement and a type of solution that fits into one of the three categories
2. Estimate your expected gains and deduce the accuracy of predictions
Once you have defined the problem and the main goal, you can start considering your gains.
The main parameter that will help you further in terms of ROI calculations of an ML project is the accuracy of the system that you need to match your expected gains. You see, any ML algorithm has the accuracy metric, which defines how precise the predictions (we told you to memorize this term) are. The accuracy you look for must enable the gains that you expect. This technique is called the impact of error costs assessment.
For example, you need about $1.4 million in annual savings from your anti-fraud solution to survive on the market. Let’s assume that your average revenue with 4,000 purchase orders per month – given the average order value $83 – is $332,000.
Before you had to pay chargebacks for 40 percent of fraudulent orders (1,600). That cost you $132,800. With the solution of 95 percent accuracy, you would compensate for 5 percent of 4,000 transactions (200), which is $16,600. Your gain is decreased expenses on chargebacks, and it accounts for $116,200. That’s $1,394,400 in savings each year. So, you need a solution to detect 95 suspicious transactions out of 100 (accuracy). The tool that can reach this threshold gets a green light.
You may also consider whether false negatives and false positives have different impacts and account for them as well.
Calculating the impact of error cost. Image source: AWS
While this sounds easy in our example, it’s not always like that in reality, especially if your problem is to provide some added value to an existing product, for instance, increase customer retention. But calculating your gains this early and the required level of system accuracy is the only way to achieve a good ROI estimate.
If you’ve managed to put this out of the way, it’s time to start looking for that efficient solution.
Key deliverable of the stage: a gains estimate with the required level of system accuracy
3. Consider off-the-shelf and standard alternatives
The problem with any ML product is that it’s really hard to estimate the cost of one. While you can assume the gains you need, as with any product, the cost estimation gets quite picky compared to other types of IT projects. There are too many things that are unknown. So, to be truly faithful, we recommend first considering other options prior to embarking on your ML initiative. If you know that you can solve the problem with ML only, just skip the stage.
Off-the-shelf software
The first thing you can do is to find out whether commercial solutions meet your accuracy requirement. It’s faster and less expensive to integrate ready-to-use software into a website than building one in-house.
Let’s stick to the example about online fraud here as well. Dozens of providers offer ready-to-use tools for combating fraudulent activity online, and many of these solutions draw customers with rich functionality. We wrote an article on how to choose fraud detection software, so check it out to learn against what features and characteristics to evaluate the options.
Traditionally, off-the-shelf tools have a trial version, so you can check how fast and efficiently they work, find out if there are limitations in their functionality, and compare the usage cost against the expected gain. If the solution accuracy and, therefore, the value doesn’t justify the investment, consider another tool or build your own.
Custom rule-based tool
You can consider building an in-house solution that uses a set of rules tailored to your operations and business needs. Well, this is traditional programming, which is way simpler to estimate in terms of cost.
The main difference between ML systems and rule-based ones is that these systems use rules – facts about a problem based on domain expert knowledge. Rules are represented in the form of if-then statements.
Cost components for software development projects are predictable and depend on the scope of work. Expenses generally include salaries/wages for the teams, fees or licenses for using a platform's APIs and SDKs (software development kits), and/or other services to analyze, import, or store data. While tech stack is solution-specific, one can estimate expenses spent on both infrastructure and development. Usually, the cost estimates of rule-based systems can be quite precise given that you have clear requirements and experienced engineers.
Let’s get back to our example with fraud prevention. You still can build a tool that evaluates user actions relying on business rules – conditions under which the action was made and attributes of this action.
These are some of the rules that a fraud detection system can use to make decisions:
If the order was made from several accounts using the same device, decline it
If the ATM cash withdrawal attempt is from an unusual location, decline the attempt
If the user registered more than X days ordered an item, allow the transaction
If the same credit card information is provided to make 5 orders every 7 minutes, review/decline a transaction.
Gains depend on the accuracy with which the tool does the transaction check.
If the tool detects fraud with a given accuracy level, and a small number of false positives or false negatives, then your team can focus on its maintenance.
However, there are many problems that can’t be solved with rule-based traditional programming. They usually require either considering too many factors and their intricate dependencies to write rules, like predicting prices, or it’s impossible to distill rules in the first place. For instance, if you want to automate apple sorting (rotten/fine), you’ll have a hard time expressing to a machine exactly how a rotten apple looks.
Machine learning allows businesses to achieve a higher level of task automation and efficiency. Imagine you must reduce the number of customer support representatives from 100 to 18 to cut payroll expenses without sacrificing the speed and quality of this service. The way to go is build a chatbot that handles basic and repetitive requests and allows customers to ask for live assistance if their problem is more complex.
When it comes to fraud detection, providers mostly follow a hybrid approach and offer tools powered by predictive machine learning models while also using a flexible rule engine. If you decide to develop a custom ML solution, you can achieve 95-98 percent of accuracy. What resources the ML project would require and whether it would lead to a positive ROI are the next questions to be answered.
So, if you must consider the bigger picture and the rules aren’t enough, you can start estimating an ML system.
The key deliverable of the stage: You are sure that your problem can’t be solved otherwise
4. Make a brief assessment of your data to consider machine learning-based software
As you’ve likely heard, machine learning needs data. This means that algorithms are usually trained on data to classify, define numbers, or rank.
We don’t recommend preparing data yourself if you don’t have enough expertise in data science. At this stage, you just must ensure that you:
If you are lucky and the data for your product isn’t business-specific and you don’t need corporate data sources, you may use open datasets.
The key deliverable of the stage: You have data to work with
5. Launch an elaboration phase for the ML project
The elaboration phase is needed to ensure that machine learning can help solve the problem with higher accuracy than other methods. In other words, specialists must define the ML project feasibility given the required accuracy that you’ve considered in the second stage.
At this point, you’ll need either external or internal data scientists to complete your research. The elaboration phase usually lasts 1-3 weeks and serves numerous purposes: feasibility study, data study, and hypothesis check (whether your problem can be solved with a machine learning system).
What happens during elaboration?
Defining the nature of ML project. An AWS whitepaper on managing ML projects suggests deciding whether this initiative is speculative and research-oriented or uses well-understood techniques. In many cases, data scientists can’t use developments from previous projects and customize them to the current one because they haven’t worked on a similar problem before. A technical approach to addressing the problem is to be found first.
Speculative data science and machine learning projects make it more challenging to predict the cost, stresses Alexander Konduforov: “If we’re talking about costs, achieving the required accuracy for say a computer vision or NLP [natural language processing] model can be quite challenging, and may require many iterations of experiments, introducing advanced architectures, or collecting additional data.”
The nature of a project is also defined by exploring reference studies and approaches.
Data quality exploration. Specialists thoroughly explore data to understand its main characteristics and check its quality. This means that they assess how many records in data are dropped, what the data issues are (i.e., duplicate records), etc.
Assessing additional data collection and labeling. If the data quality is poor at this stage, machine learning engineers must also estimate additional efforts to collect data. For instance, Homsters, a real estate service company, reached out to our team to develop a recommender system. The team evaluated existing data and suggested collecting extra types of information to power the engine. Variables included user interactions, metadata (location, device, browser, etc.), and other analytics. Sometimes, the data needs labeling, i.e., defining the variables that must be predicted and assigning them to each data item. For instance, if the model must use transactions data, each transaction must be labeled fraudulent/non-fraudulent in advance. Dataset preparation though labor- and time-intensive (it may take months to complete) is the irreplaceable stage of any machine learning project.
Basic modeling. The team does basic dataset preparation if needed and then feeds it to algorithms that are commonly used for completing a specific task. This experiment (called basic modeling) allows data scientists to learn what level of accuracy can be reached. For instance, if the team managed to achieve 60 percent of accuracy using simple algorithms, it can suppose that increasing accuracy to 70 or 80 percent is possible. There may be a situation when 60 percent is achieved with more complex methods, while the initial goal is to get 95 percent accuracy. In this case, the team concludes that they won’t achieve the required accuracy, but can estimate which accuracy is realistic. Data scientists may also look for ways of increasing accuracy by 90 percent, for example.
Risk assessment and mitigations. This step must involve both data scientists and stakeholders. The team assesses the risks and tries to mitigate them, considering four major dimensions:
Business, social, and regulatory risks
Financial risks (the impact of false gain/cost calculations)
Data quality risks (how likely is it that the quality of data is lower than estimated initially?)
Process risks (additional activities that may be needed, but are easy to oversee in the early project stages)
Preparing data analysis/feasibility report. Now, it’s possible to forecast how much effort, time, and respectively, cost would be required to complete the project knowing the accuracy estimate.
“After the elaboration phase, we should be able to prepare the data analysis/feasibility report, scope of work, budget estimation, team composition, the project plan and proposal,” says Alexander Konduforov from the AltexSoft data science department.
Knowing about the achievable level of accuracy, the team can make an estimate about the return on investment the solution may bring.
If both the team and leadership are satisfied with the results and think that the project is worth an investment of more time and money, they can proceed to the next phase of final research. The research would allow them to eliminate the uncertainty in ROI and costs forecasts.
The key deliverable of the stage: data analysis/feasibility report that provides enough information to make an initial ROI estimation, as you have gains and cost values
6. Final research
The merit of the elaboration phase is that it provides enough information to justify the ML project. In other words, you get ROI estimation and understand whether the project is feasible at all. However, you can go further to reduce any uncertainty.
“The main purpose of AltexSoft’s research phase is to build a working algorithm (train a model) that solves the requested problem with a given level of accuracy and performance," says Alexander. The research might take from several weeks to several months, depending on problem complexity.
Data preparation, model training, and evaluation consume most of the time during this phase.
An algorithm that would be the core of a future solution must be trained with clean, consistently formatted data. Dataset size, as well as the number of required data types, are individual for every case. The team may start collecting additional data if needed.
“After the algorithm is properly tested (better A/B tested), it becomes ready for production development and integration with a product, system, or business process,” concludes the specialist.
Development or integration can start if the research outcome not only allows for implementing an efficient solution but is also in line with budgeting capabilities and expected return on investment.
The key deliverable of the stage: final ROI estimation
Conclusion
Machine learning projects are more experimental by nature than the ones involving traditional software engineering. So, it’s harder for data science teams to estimate the scope of work, time frames, costs to achieve the necessary level of accuracy, as well as outcomes before the solution is implemented and goes live.
Despite challenges in assessing ROI from implementing ML and DS projects, positive return can be a reality. In fact, 82 percent of Deloitte’s State of AI in the Enterprise survey respondents said they have gained a financial return from their AI investments. The survey also found that median return on investment from cognitive technologies is 17 percent across 10 industries represented by participants.
Return on investment on AI initiatives across industries. Source: Deloitte
Companies may have their own ways to mitigate risks of getting inaccurate estimates. At AltexSoft, we conduct elaboration and research phases. These stages allow for bringing more certainty into forecasts on project feasibility, solution accuracy, budgeting, and possible gains. Estimates made during the elaboration stage are clarified during research. Using these insights, executives can make grounded investment decisions.
Elaboration and research phases contemplate bringing more certainty into forecasts on project feasibility, solution accuracy, budgeting, and possible gains. Estimates made during the elaboration stage are clarified during research.