

For over a decade, two similar concepts — DevOps and Site Reliability Engineering (SRE) — have been coexisting in the world of software development. At first glance, they may look like competitors. But a closer view reveals that alleged rivals are actually complementary pieces of a puzzle that fit together nicely.
This article explains how DevOps and SRE facilitate building reliable software, where they overlap, how they differ from each other, and when they can efficiently work side by side. We hope the information will be useful for DevOps specialists, product managers, CTOs, and other executives seeking ways to improve the reliability of their systems without victimizing the speed of innovations.
Learn about the role of a DevOps engineer, the tools they use, and how they collaborate with other members of the DevOps team in our dedicated article.
Google SRE vs DevOps basics: two sides of the same coin
In essence, two methodologies do the same thing: They try to bridge the gap between development and operations teams. Both aim at improving the release cycle and achieving better product reliability. But before diving deeper into the differences and similarities between them, let’s think back to when and for what reason SRE and DevOps appeared at all.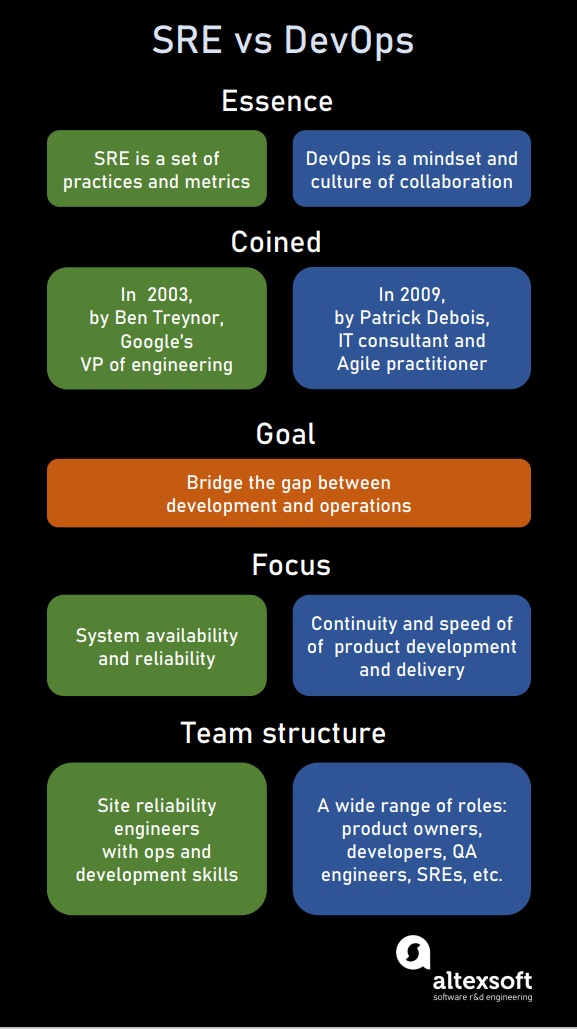
SRE vs DevOps comparison.
What is SRE?
Site Reliability Engineering or SRE is a unique, software-first approach to IT operations supported by the set of corresponding practices. It originated in the early 2000s at Google to ensure the health of a large, complex system serving over 100 billion requests per day. In the words of Ben Treynor Sloss, Google’s VP of engineering who coined the very term SRE, “It’s what happens when you ask a software engineer to design an operation function.”
The primary focus of SRE is system reliability, which is considered the most fundamental feature of any product. The pyramid below illustrates elements contributing to the reliability, from the most basic (monitoring) to the most advanced (reliable product launches).
The hierarchy of service reliability needs, according to Google's SRE book. Source: Site Reliability Engineering.
Once the system is “reliable enough.” SRE shifts efforts to adding new features or creating new products. It also puts much attention on tracking results, making measurable performance improvements, and automating operations tasks.
What is DevOps?
The term DevOps (short for development and operations) was coined in 2009 by Patrick Debois, Belgian IT consultant and Agile practitioner. Its core principles are similar to those of SRE: application of engineering practices to operations tasks, measuring results, and reliance on automation instead of manual work. But its focus is much broader.
While SRE concentrates on keeping services running and available to users, DevOps aims to cover the entire product life cycle, from design to operations, making all processes continuous after Agile methodologies. Such end-to-end continuity is paramount to reducing time to market and making rapid changes. 
A DevOps lifecycle. Source: Medium
Another difference from SRE is that DevOps emerged in the first place as a culture and mindset that didn’t specify how exactly to implement its ideas. It’s often viewed as a generalization of key SRE methods so that they can be used by a wider range of organizations. Likewise, SRE can be seen as an embodiment of DevOps visions. The next section describes the interactions between two methodologies in more detail.
Practice vs mindset: how Site Reliability Engineering implements DevOps philosophies
Broadly speaking, DevOps describes what needs to be done to unify software development and operations. Whereas SRE prescribes how this can be done. DevOps culture is based on several pillars that are covered by corresponding SRE practices.
What SRE offers to solve DevOps tasks.
Five key DevOps pillars are
- No more silos. The idea stems from the fact that a lack of collaboration and information flow across teams reduces productivity.
- Failures are normal. DevOps prescribes learning from mistakes rather than spending resources on an unattainable goal — preventing all failures.
- The change should be gradual. Changes are most effective and low-risk when they are small and frequent. This pillar combined with automated testing of small batches of code and rollback of bad ones underlies the concepts of continuous integration and continuous delivery (CI/CD).
- The more automation the better. DevOps focuses on automation to deliver updates faster and free up hours of manual effort.
- Metrics are crucial. Each change should be measured to understand whether it brings the results you expect.
Now let’s see what SRE offers to put these pillars into practice.
Treat operations as a software problem
Corresponds to “no more silos,” “the more automation the better”
SRE utilizes software engineering to solve operations problems. In other words, software solutions are created to instruct a computer how to perform IT operations automatically, without human intervention. SRE specialists apply the same tools that developers typically use and share responsibility for product success with a software development team.
Minimize toil
Corresponds to “the more automation the better,” “metrics are crucial”
In terms of SRE, toil is manual, repetitive work devoid of long-term value and related to running a production service. Examples of toil are
- regular password resets,
- manual releases,
- reviewing non-critical alerts, and
- manual scaling of infrastructure.
SRE’s rule of thumb is to keep toil below 50 percent of engineers’ work time. Once the threshold is exceeded, the team needs to identify the top source of toil. Then engineers develop a software solution to automate some tasks and achieve a healthy work balance. A good practice is to eliminate a bit of toil each week.
Measure uptime and availability of the system
Corresponds to “metrics are crucial”
According to SRE, a key precondition for a system’s success is availability. If your service is unavailable at a certain time, it can’t perform its functions. To measure the availability and thus ensure that everything goes right, SRE provides three metrics.
1. Service-Level Indicator (SLI) is a quantitative measurement of a system’s behavior. The main SLI for most services is request latency — or the time needed to respond to a request. Other commonly used SLIs are throughput of requests per second and errors per request. These metrics are usually collected within a certain period of time and then converted into rates, averages, or percentiles.
2. Service-Level Objective (SLO) is a target range of values set by stakeholders (say, the average request latency must be under 100 milliseconds). The system is supposed to be reliable if its SLIs continuously meet SLOs.
3. Service-Level Agreement (SLA) is a promise to customers that your service will meet certain SLOs over a certain period. Otherwise, a provider will pay some kind of penalty. SRE isn’t directly involved in setting SLAs. However, it helps to avoid missed SLOs and the financial losses they entail.
Set error budget
Corresponds to “failures are normal,” “changes should be gradual,” “metrics are crucial”
SRE doesn’t aim to hit 100-percent reliability as this goal is unrealistic. “...100 percent is not the right reliability target, Ben Treynor confirms, because no user can tell the difference between a system being 100 percent available and, let’s say, 99.999 percent available.” Moreover, upon achieving a certain level, a further increase in reliability doesn’t benefit the system, restricting the speed and frequency of updates.
So, the goal of SRE is to deliver sufficiently good services without sacrificing the ability to deliver new features often and fast. This approach tolerates the acceptable risk of failure called the error budget.
In Google, the error budget is defined quarterly, based on SLOs. It gives a clear vision of how much risk is allowed within a quarter. Once the agreed-upon metric is exceeded, the team shifts its focus from the development of updates to improving reliability.
Reduce the cost of failure
Corresponds to “failures are normal,” “changes should be gradual”
The later in the product life cycle the error is detected, the higher the cost of fixing it. SRE recognizes this fact and tries to solve problems as early as possible using the following practices.
Rollback early, rollback often. When an error is revealed or even suspected in a release, the team rolls back first and explores the problem second. This approach reduces the Mean Time to Recovery (MTTR) — or the average time needed to recover your service from a failure.
Canary all rollouts. Canary release is a method to make the rollout process safer. An update is introduced to a small part of users first. They test it and provide feedback. After all required changes are made, the release is made available to everybody. Canary releases cut the Mean Time to Detect (MTTD) that reflects how long it usually takes your team to detect an issue. Besides, the method reduces the number of customers affected by system failures.
Create and maintain playbooks
Corresponds to “no more silos,” “automate everything”
Playbooks or runbooks are documents describing diagnostic procedures and ways to respond to automated alerts. They reduce Mean Time to Repair (MTTR), stress, and the risk of human error.
Entries in playbooks are out of date as soon as the environment changes. So, when it comes to daily releases, these guides need daily updates as well. Considering that creating good documentation is hard, some SREs advocate creating only general instructions that change slowly. Others insist on detailed, step-by-step playbooks to eliminate variability.
Google’s SRE Workbook recommends implementing automation if a playbook contains a list of commands engineers run every time in the case of a particular alert.
SRE vs DevOps jobs: a team of multitaskers or a cross-functional team
In recent years, SRE and DevOps roles have become super-important in many companies. But this doesn’t mean everyone agrees upon what exactly SRE and DevOps teams do. Likewise, there is no universal description for DevOps and Site Reliability Engineer jobs. Below, we’ll try to highlight the most essential aspects of DevOps and SRE functions.
Site Reliability Engineer role and SRE team
A typical SRE team is composed of either software developers with expertise in operations or IT operations specialists with software development skills. At Google, such teams are usually a fifty-fifty mix of those who have more of a software background and those who have more of a systems background. Other companies form SRE teams by adding software engineering skill sets and approaches to existing operations practices and personnel.
Besides operations and software engineering, areas of experience relevant to the SRE role encompass monitoring systems, production automation, and system architecture.
All members of an SRE team share responsibility for code deployment, system maintenance, automation, and change management. And functions of each individual Site Reliability Engineer may change over time, depending on the current focus of the team — the development of new features or improvement of the system’s reliability.
DevOps Engineer role and DevOps team
Unlike an SRE team where each member is a kind of jack-of-all-trades, a DevOps team contains different professionals with specific duties.
The team structure varies from company to company and usually includes (but is not limited to) the following specialists:
- a Product Owner who understands how the service should work to bring value to customers,
- a Team Lead delegating tasks across other members,
- a Cloud Architect building cloud infrastructure for smooth running of services in production,
- a Software Developer writing code and unit tests,
- a QA Engineer implementing quality methods for product development and delivery,
- a Release Manager scheduling and coordinating releases, and
- a System Administrator in charge of cloud monitoring.
Of course, this is not an exhaustive list of roles in DevOps. Quite often such a cross-functional team invites a Site Reliability Engineer to ensure the availability of services. Typically, when SREs work as a part of a DevOps team, they have a narrower range of responsibilities than in fully-committed SRE teams.
No matter the number and background of team members, obviously DevOps is not a role or person in contrast to SRE. However, as of writing this article, there were nearly 25,000 DevOps Engineer jobs posted on Glassdoor — which is comparable with almost 33,000 Site Reliability Engineers sought on the same website.
A brief examination of vacancies on Glassdoor reveals that background, responsibilities, and skills required for both jobs have a lot of overlap. It seems that employers often use these job titles interchangeably.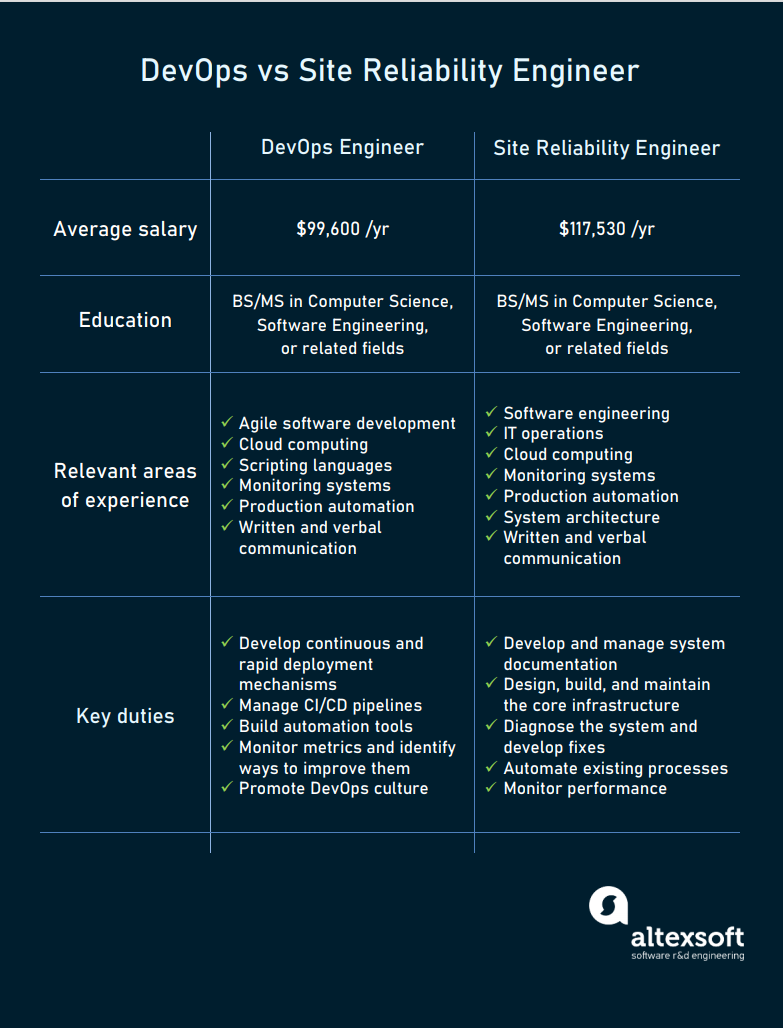
DevOps vs SRE engineer jobs comparison based on vacancies published by Glassdoor.
However, average yearly salaries are somewhat higher among SREs — thanks to the financial data submitted by employees working for tech giants like Google, LinkedIn, Twitter, Microsoft, Apple, and Adobe, to name a few.
SRE vs DevOps tools: the same solutions do for both
Matthew Flaming, VP of software engineering at New Relic Application Software Monitoring, describes SRE as “the purest distillation of DevOps principles into a single role.” That being said, an SRE and DevOps toolset can be very much the same and typically include the following positions.
Containers and microservices facilitate creating a scalable system. So, Docker for building and deployment containerized apps and Kubernetes for container orchestration come as integral parts of SRE/DevOps toolchains.
CI/CD tools like Jenkins or CircleCI support the idea of gradual change, enabling teams to build, test, and deploy code faster.
Infrastructure as Code (IaS) tools correspond exactly with the “automate everything” concept. Terraform, AWS CloudFormation, Puppet, Chef, and Ansible are among the most widely-used solutions to automate infrastructure deployments and configurations.
Automated functional and non-functional testing in production can be performed with the help of Selenium, Zephyr, Nexus Lifecycle, Veracode, and other tools.
Resilience testing is essential to ensure the ability of the system to withstand real-life conditions. Popular options for this task are Chaos Monkey by Netflix, ChaosIQ, and Gremlin.
Monitoring systems play a crucial role in SRE and DevOps frameworks. Services delivered by Prometheus, DataDog, Broadcom, PRGT Network Monitor, and many other platforms allow for metrics-based continuous monitoring of network and application performance across cloud environments.
When do companies need DevOps and SRE?
Despite all the confusion and overlaps, one thing is pretty sure: SRE and DevOps are not conflicting factions, but rather two relatives working towards the same goal and with the same tools — but with slightly different focuses.
While SRE culture prioritizes reliability over the speed of change, DevOps instead accentuates agility across all stages of the product development cycle. However, both approaches try to find a balance between two poles and can complement each other in terms of methods, practices, and solutions. More on that in our video:
https://www.youtube.com/watch?v=s3AU6VchZS8
Depending on their size and goals, companies may implement different scenarios of DevOps, SRE, or even their combination.
SRE teams modeled after Google fit large tech-driven companies such as Adobe, Twitter, or Amazon that handle billions of daily requests and put the availability of their services before anything else.
DevOps culture and cross-functional teams benefit any business working in a highly competitive environment, where even a slightly shorter time to market gives a huge competitive advantage. Moreover, a DevOps team can be strengthened with a Site Reliability Engineer to monitor system performance and ensure its stability.
Some organizations have two teams — SRE and DevOps. The former is responsible for the support and maintenance of existing service while the latter creates and delivers new applications.
Smaller companies typically seek a person to manage cloud infrastructure and automate operations tasks, using different job titles for the same responsibilities — DevOps Engineer, DevOps Manager, Site Reliability Engineer, or even Cloud Engineer, or CI/CD Engineer.
No matter how large your company is, somebody in your organization probably already does the SRE job, promotes collaboration between developers and IT specialists, or writes scripts to automate time-consuming tasks. If you find these people and officially recognize their work, they can form the backbone of an effective SRE or DevOps team — whichever name you like more.